Redis集群方案比较以及数据分区方式
很多年前接触Redis,还只有单机版,主要用途就是当缓存使用,主要对手就是Memcached,经过多年发展已经实现多种集群方案。
Redis集群模式通常具有高可用、可扩展性、分布式、容错 等特性。Redis 分布式方案一般有两种:
- 客户端分区方案 Redis Sharding
客户端分区方案 的代表为 Redis Sharding,Redis Sharding 是 Redis Cluster 出来之前,业界普遍使用的 Redis 多实例集群 方法。Java 的 Redis 客户端驱动库 Jedis,支持 Redis Sharding 功能,即 ShardedJedis 以及 结合缓存池 的 ShardedJedisPool。 - 服务端分区方案
Redis Cluster 是Redis的分布式解决方案,在 3.0 版本正式推出,有效地解决了 Redis 在分布式 方面的需求。当遇到单机内存、并发、流量等瓶颈时,可以采用 Cluster 架构方案达到负载均衡的目的。
数据分布方式
分布式数据库首先要解决把整个数据集按照分区规则映射到多个节点的问题,即把数据集划分到多个节点上,每个节点负责整体数据的一个子集。
单机数据库数据分布主要体现在数据索引上,通过索引快速定位数据,索引方式分为BTREE和HASH。
数据分布通常有哈希分区和顺序分区两种方式:
| 方式 | 特点 | 相关产品 |
| 哈希分区 | 离散程度好,数据分布与业务无关,无法顺序访问 | Redis Cluster,Cassandra,Dynamo |
| 顺序分区 | 离散程度易倾斜,数据分布与业务相关,可以顺序访问 | BigTable,HBase,Hypertable |
Oracel数据库中分区表提供这2种分区方式,当存储日志数据时,可以按时间顺序作为分区键;当存储统计数据,如姓名等,可以使用哈希分区。顺序分区有利于范围范围查询,哈希分区有利于点查询。
1.节点取余分区
使用特定的数据,如 Redis的键 或 用户 ID,再根据节点数量N使用公式:hash(key)% N 计算出哈希值,用来决定数据映射 到哪一个节点上。

- 优点
这种方式的突出优点是简单性,常用于数据库的分库分表规则。一般采用预分区的方式,提前根据数据量规划好分区数,比如划分为512或1024张表,保证可支撑未来一段时间的 数据容量,再根据负载情况将表 迁移到其他数据库中。扩容时通常采用翻倍扩容,避免数据映射全部被打乱,导致全量迁移的情况。
- 缺点
当 节点数量 变化时,如 扩容 或 收缩 节点,数据节点 映射关系 需要重新计算,会导致数据的 重新迁移。
2.一致性哈希分区
一致性哈希可以很好的解决稳定性问题,可以将所有的存储节点排列在收尾相接的Hash环上,每个key 在计算Hash后会顺时针找到临接的存储节点存放。而当有节点加入或退出时,仅影响该节点在Hash 环上顺时针相邻的后续节点。
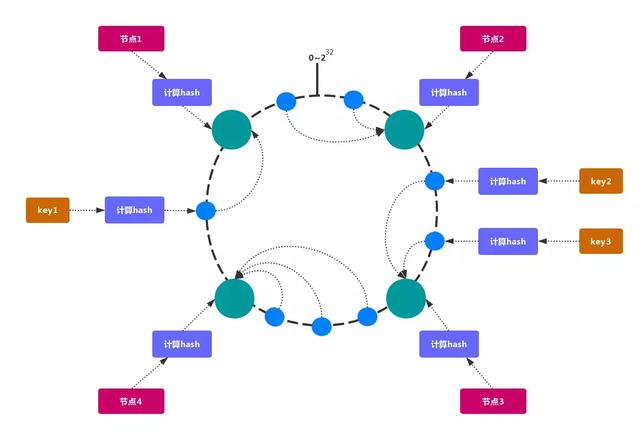

- 优点
加入 和 删除 节点只影响 哈希环 中 顺时针方向 的 相邻的节点,对其他节点无影响。
- 缺点
加减节点 会造成 哈希环 中部分数据 无法命中。当使用 少量节点 时,节点变化 将大范围影响 哈希环 中 数据映射,不适合 少量数据节点 的分布式方案。普通 的 一致性哈希分区 在增减节点时需要 增加一倍 或 减去一半 节点才能保证 数据 和 负载的均衡。
注意:因为 一致性哈希分区的这些缺点,一些分布式系统采用虚拟槽对 一致性哈希进行改进,比如 Dynamo 系统。
3.虚拟槽分区
虚拟槽分区 巧妙地使用了 哈希空间,使用 分散度良好 的 哈希函数 把所有数据 映射 到一个 固定范围 的 整数集合 中,整数定义为 槽(slot)。这个范围一般 远远大于 节点数,比如 Redis Cluster 槽范围是 0 ~ 16383。槽 是集群内 数据管理 和 迁移 的 基本单位。采用 大范围槽 的主要目的是为了方便 数据拆分 和 集群扩展。每个节点会负责 一定数量的槽
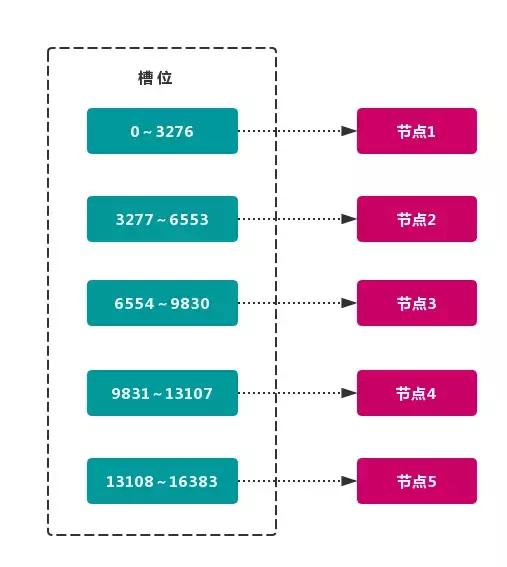

这种结构很容易 添加 或者 删除 节点。如果 增加 一个节点 6,就需要从节点 1 ~ 5 获得部分 槽 分配到节点 6 上。如果想 移除 节点 1,需要将节点 1 中的 槽 移到节点 2 ~ 5 上,然后将 没有任何槽 的节点 1 从集群中 移除 即可。
由于从一个节点将 哈希槽 移动到另一个节点并不会 停止服务,所以无论 添加删除 或者 改变 某个节点的 哈希槽的数量都不会造成 集群不可用 的状态.
Redis集群
Redis Cluster 采用虚拟槽分区,所有的 键 根据 哈希函数 映射到 0~16383 整数槽内,计算公式:slot = CRC16(key)& 16383,每个节点负责维护一部分槽以及槽所映射的 键值数据。
Redis集群的功能限制
- key 批量操作 支持有限。
类似 mset、mget 操作,目前只支持对具有相同 slot 值的 key 执行 批量操作。对于映射为不同 slot 值的 key 由于执行 mget、mget 等操作可能存在于多个节点上,因此不被支持。
- key 事务操作支持有限。
只支持 多key在同一节点上的事务操作,当多个 key分布在不同的节点上时无法使用事务功能。
- key 作为数据分区的最小粒度
不能将一个大的键值对象如hash、list 等映射到不同的节点。
- 不支持多数据库空间
单机下的Redis可以支持16个数据库(db0 ~ db15),集群模式下只能使用一个数据库空间,即db0。
- 复制结构只支持一层
从节点只能复制主节点,不支持嵌套树状复制结构。
Multi-Key 限制的处理
对于多key场景,需要做好数据空间的设计,Redis Cluster 提供了一个 hash tag 的机制,可以让我们把一组 key 映射到同一个 slot。
例如:user1000.following 这个 key 保存用户 user1000 关注的用户;user1000.followers 保存用户 user1000 的粉丝。
这两个 key 有一个共同的部分 user1000,可以指定对这个共同的部分做 slot 映射计算,这样他们就可以在同一个槽中了。
使用方式:
{user1000}.following 和 {user1000}.followers就是把共同的部分使用 { } 包起来,计算 slot 值时,如果发现了花括号,就会只对其中的部分进行计算。
Redis集群搭建
Redis集群一般由多个节点组成,节点数量至少为 6 个,才能保证组成完整高可用的集群。
配置
必选配置:
port 700X
bind 192.168.23.*
cluster-enabled yes
建议配置:
daemonized yes
logfile /usr/local/redis/redis-cluster/700X/node.log
启动每个结点redis服务
redis-server /etc/redis.conf
Redis4执行创建集群命令:
进入到redis源码存放目录redis/redis-4.10.3/src下,执行redis-trib.rb,此脚本是ruby脚本,它依赖ruby环境。
redis-trib.rb 是 redis 作者用 ruby 完成的,redis-trib.rb 命令行工具的具体功能如下:
Redis5 集群创建命令:
redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 --cluster-replicas 1
查询集群信息:
./redis-cli -c -h 192.168.56.3 -p 7001
参考:
深入剖析Redis - Redis集群模式搭建与原理详解
深入剖析Redis系列: Redis集群模式搭建与原理详解
https://xie.infoq.cn/article/aa7f0c4c6538cf966a4cdac79
Redis-cluster集群搭建
Redis-5.0.5集群配置
Redis单机和集群配置(版本在5.0后)
springboot2.x 整合redis集群的几种方式