空间抽样与统计推断_推断统计学基本概念
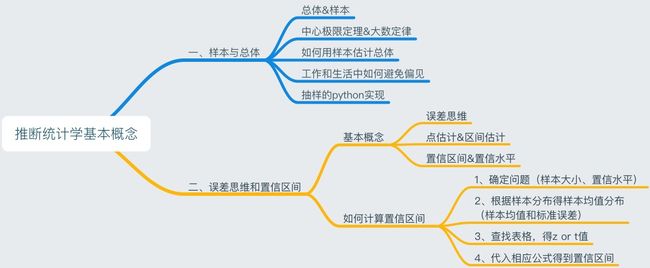
推断统计学(inferential statistic):是研究如何根据样本数据推断总体数量特征的方法,是在对样本数据进行描述的基础上,对统计总体的未知数量特征做出概率形式表述的推断。
对比:描述统计学(descriptive statistic):是研究数据反映客观现象的特点,并通过图表形式对所搜集的数据进行加工处理和显示,进而通过综合概况与分析得出分析客观现象的规律性数量特征的学科。(以下链接为如何用Python进行描述性统计)
https://blog.csdn.net/MsSpark/article/details/86188032blog.csdn.net一、总体与样本
1.1总体(population)与样本(sample)
- 总体:研究对象的整个群体
- 样本:从总体中选取的一部分数据
- 样本数量:有多少个样本
- 样本大小(样本容量):每个样本包含多少个体
- 抽样分布:将样本平均值的分布可视化
1.2中心极限定理与大数定律
1)中心极限定理(central limit theorem)
中心极限定理说明了:
- 样本均值约等于总体均值
- 不管总体呈何种分布,任意一个总体的样本平均值都会围绕在总体均值周围,并呈正态分布
中心极限定理作用:
- 在无法获取数据总体情况下,用样本(平均值)来估计总体(平均值),例如民意调查。
- 根据总体信息(平均值和标准差),判断某个样本属于该总体的概率大小。
打开链接,点击左上角的begin按钮,开始理解中心极限定理:
Sampling Distributionsonlinestatbook.com2)大数定律(law of large numbers)
大数定律说明了:
n个独立同分布的随机变量的观察值的均值依概率收敛于这些随机变量所属分布的总体均值。
1.3如何用样本估计总体
1)选用正确的抽样方法,得到样本数据
在实际情况中,通常我们无法对所有数据进行调查,此时一般采用从整体中抽取样本的方法进行调研,具体选用的抽样方法依数据本身特点而异。 常用的抽样方法有:简单随机抽样、分层抽样、整群抽样、系统抽样等。
1. 简单随机抽样
即从总体N个单位中任意抽取n个单位作为样本,使每个样本被抽中的可能性相等的一种抽样方式。
简单随机抽样有两种具体做法:重复抽样和不重复抽样。
- 重复抽样:有放回的抽样,即在选取一个抽样单位并记录下这个抽样单位的相关信息后,再将其放回总体中。
- 不重复抽样:无放回的抽样,即选取抽样单位后不再将其放回总体中。
2. 分层抽样
在抽样时,将总体分成互不相交的层,然后按照一定的比例,从各层独立地抽取一定数量的个体,将各层取出的个体合在一起作为样本的方法。
3. 整群抽样
亦称聚类抽样,是将总体中各单位归并成若干个互不交叉、互不重复的集合,称之为群,然后以群为抽样单位抽取样本的一种抽样方式。应用整群抽样时,要求各群有较好的代表性,即群内各单位差异大,但群间差异小。
4. 系统抽样
亦称机械抽样、等距抽样,当总体中个体数量较多时,可将总体均衡地分为几个部分,按照预先定出的规则,从每一部分抽取一个 个体,得到所需样本的方法。(如按照100或50的间隔进行取数)
整群抽样与分层抽样的区别
- 分成抽样要求各层之间的差异很大,层内个体或单元差异小,而整群抽样要求群与群之间的差异比较小,群内个体或单元差异大;
- 分层抽样的样本使从每个层内抽取若干单元或个体构成,而整群抽样则是或整群抽取,或整群不被抽取。
2)利用样本平均值约等于总体平均值(依据中心极限定理)3)利用样本标准差估计总体标准差
1.数据标准差:

2.用样本标准差估计总体标准差(因为样本数量少,有可能将极端的数值排除在外):

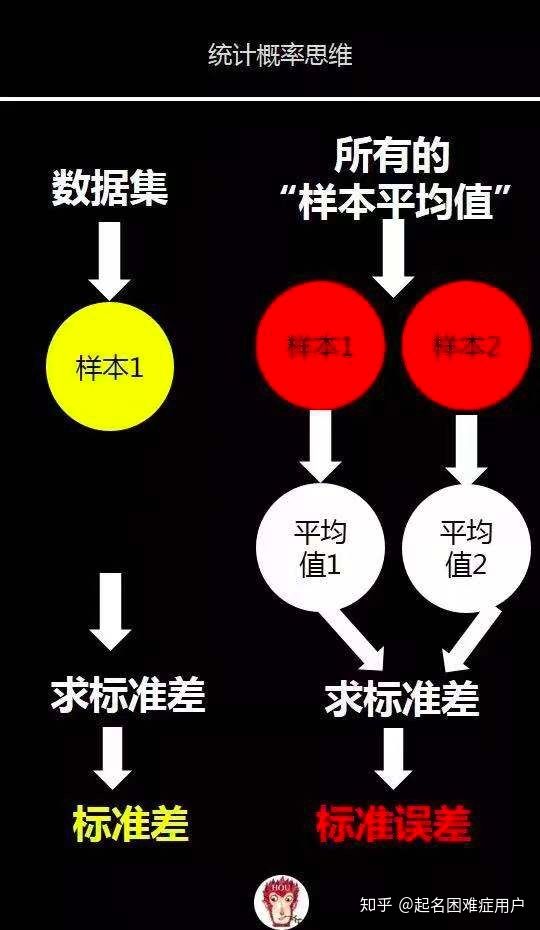
3.标准误差(样本平均值的标准差):

4.标准差和标准误差的差别
1.4工作和生活中如何避免偏见
常见的四种偏差情况及其避免措施:
- 样本偏差:抽样空间中数据不齐全,因此未包含目标总体中的所有对象,俗称以偏概全。 措施:增大样本数量,样本越大越可靠。
- 幸存者偏差:指只看到经过某种筛选而产生的结果,而未意识到筛选的过程,因此忽略了被筛选掉的关键信息。 措施:多个角度全面观察问题。(正面思考及反面思考)
- 概率偏见:心理概率(人们自以为的概率)与客观概率的偏差。 措施:学好概率统计,用数学方法去验证客观概率,对于不能验证客观概率的应多咨询其他人看法,降低概率偏见的可能性。
- 信息茧房:在信息传播中,公众自身的信息需求并非面面俱到,而是仅注意自己选择的东西和使自己愉悦的资讯领域,久而久之,将自身桎梏于蚕茧一般的“茧房”中。 措施:个人应乐于扩宽信息认知范围,避免仅局限于自己感兴趣的资讯中。
1.5抽样的python实现
#导入随机数(random)模块
import random
#random.randint(a,b) 随机生成[a,b]间的随机数
a=random.randint(0,9)
print('生成一个[0,9]之间的随机数为',a)
>>>生成一个[0,9]之间的随机数为 0案例:从395人中随机抽取10个人作为中奖者
#案例:从395人中随机抽取10个人作为中奖者
#range()生成整数列表:range(a,b,[,step])即生成[a,b)的整数列表
#random.randint()生成随机数:random.randint(a,b)即生成[a,b]间随机数
#循环变量 i
for i in range(1,11):
userId=random.randint(1,395)
print('第 %i 位中奖者是 %i 号用户'%(i,userId))
>>>
第 1 位中奖者是 296 号用户
第 2 位中奖者是 118 号用户
第 3 位中奖者是 324 号用户
第 4 位中奖者是 170 号用户
第 5 位中奖者是 230 号用户
第 6 位中奖者是 265 号用户
第 7 位中奖者是 109 号用户
第 8 位中奖者是 384 号用户
第 9 位中奖者是 255 号用户
第 10 位中奖者是 254 号用户pandas数据框中抽样方法
#pandas数据框中抽样方法
#导入包
import pandas as pd #数据包
import numpy as np #数组包
#生成二维数组
df=pd.DataFrame(np.arange(5*4).reshape(5,4))
df
>>>
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
3 12 13 14 15
4 16 17 18 19
#从二维数组df中抽取样本
df.sample(n=2,axis=1) #从二维数组df中,按列随机抽取两列
>>>
3 1
0 3 1
1 7 5
2 11 9
3 15 13
4 19 17二、误差思维与置信区间
2.1基本概念2.1.1误差思维
在测量、计算或观察某个值的过程中,由于某些错误或者某些不可控因素影响,造成预估值偏离标准值或规定值的数量,误差是不可避免的。只要有估计,就会有误差。
2.1.2 点估计&区间估计&假设检验
- 点估计(point estimate):即根据样本数据确定一个统计量,用它来估计总体的未知参数。
- 区间估计(interval estimate):给定置信水平,根据估计值确定真实值可能出现的区间范围,该区间通常以估计值为中心。
- 假设检验:给定置信水平,根据假设值确定估计值可能出现的区间范围,该区间通常以假设值为中心。这里的假设值是指真实值的假设值,若计算得到的估计值在此区间范围内则接受原假设,否则拒绝原假设。
2.1.3 置信区间&置信度(置信水平)&显著性水平
- 置信区间(Confidence interval):在统计学中,一个概率样本的置信区间(Confidence interval)是对这个样本的某个总体参数的区间估计,展现的是这个参数的真实值有一定概率落在测量结果周围的程度。
- 置信度或置信水平:置信区间给出的是被测量参数的测量值的可信程度,即前面所要求的“一定概率”,这个概率即为置信度,亦称置信水平。
- 显著性水平α:100%*(1-α)即为置信水平
2.2如何计算置信区间2.2.1大样本如何计算置信区间
大样本:抽样调查的样本数量大于30。 此时可近似认为样本抽样分布趋近于正态分布,符合中心极限定理,并利用样本的均值和标准差来估计总体。
举例: 糖果公司用一个100粒糖球的样本得出口味持续时间均值的点估计量为62.7分钟,同时总体方差的点估计量为25分钟,设定置信水平为95%,求糖果总体均值的置信区间。
1.求其抽样的分布(根据样本分布得到样本均值的分布):
100粒糖球为一个抽样,求抽样均值的分布,我们知道当n足够大时,样本均值服从正态分布,即:

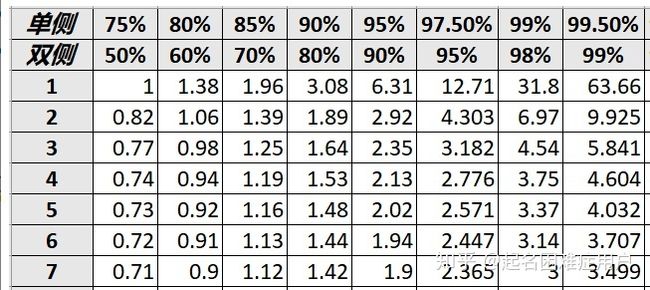
2.求置信区间(对样本均值分布进行标准化即Z所属分布,根据置信水平得到z值相应上下限 代入P(Za 2.1 根据置信水平,确定概率上下限: 2.2 对估计只进行标准化: 2.3 根据P(Z < Za) = 0.025, P(Z > Zb) = 0.025,分别算出Za和Zb分别为-1.96和1.96(查z table可得): 2.4 由于已有样本均值,因此可以得到总体均值的置信区间: 2.2.2小样本如何计算置信区间 举例:7名学生在使用了新研制的钙片3个月后,他们的血液中的钙含量分别上升了1.5, 2.9, 0.9, 3.9, 3.2, 2.1, 1.9。设定置信水平为95%,求所有使用新钙片的学生的钙含量增加平均值的置信区间。 1.求其抽样的分布(根据样本的分布得到样本均值及标准误差): 抽样样本的容量为7,自由度为(n-1)=6,均值为:2.34,无偏方差为1.04(根据样本方差及自由度求得)。因为样本的无偏方差可认为是总体方差,所以总体方差为1.04,则抽样样本均值的方差为1.04/7=0.149,故抽样样本均值的标准差(即标准误差)为0.385。 (此处应注意区别:样本的无偏方差、抽样样本均值的方差) 2.1 此时自由度为6,按双侧检验置信水平95%查t table可得t=2.447 2.2 求出置信区间上下限a,b及置信区间: a=样本平均值-t*标准误差=2.34-2.447*0.385 b=样本平均值+t*标准误差=2.34+2.447*0.385 即当我们选用置信水平为95%时,总体均值的置信区间为[ 1.39,3.28 ]。
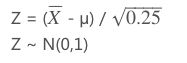
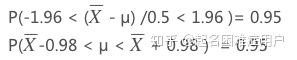

2.求置信区间(根据自由度及置信水平查表得t值,代入 样本均值±t*标准误差 求上下限):