Selenium自动化测试基于Python
目录
-
- 简介
- 第一个Selenium例子
- unitt-基本认识
- unitt增加测试用例
- unitt设置同一个开头和结尾
- unitt断言
- unitt测试套件
- unitt生成HTML格式的测试报告
- unitt定位
- WebDriver功能(一)
- WebDriver方法(一)
- WebElement接口
- WebElement接口实战(已失效)
- WebDriver操作下拉菜单
- WebDriver操作警告和弹窗框
- selenium隐式等待
- selenium显示等待
- selenium预期条件判断等待
- selenium使用ddt执行数据驱动测试(内部自定义,CSV,excel,数据库)
- selenium的PageObject模式
- selenium的PageObject模式-仿写测试百度
- Selenium WebDriver的高级特性-键盘与鼠标事件
- Selenium WebDriver的高级特性-调用JavaScript
- Selenium WebDriver的高级特性-屏幕截图
- Selenium WebDriver的高级特性-屏幕录制(有问题,待解决)
- Selenium WebDriver的高级特性-弹出窗处理
- Selenium WebDriver的高级特性-操作cookie
- 移动端测试
-
- adb 的使用
简介
Selenium是一个主要用于Web应用程序自动化测试的工具集合,在行业内已经得到广泛的应用。介绍如何用Python语言调用Selenium WebDriver接口进行自动化测试。主要内容为:基于Python 的 SeleniumWebDriver 入门知识、第一个Selenium Python脚本、使用unittest 编写单元测试、生成HTML格式的测试报告、元素定位、Selenium Python API 介绍、元素等待机制、跨浏览器测试、移动端测试、编写一个iOS测试脚本、编写一个Android测试脚本、Page Object与数据驱动测试、Selenium WebDriver的高级特性、第三方工具与框架集成等核心技术。
第一个Selenium例子
"""
我们需要从Selenium包中导入WebDriver才能使用
Selenium WebDriver方法.
from selenium import webdriver
"""
from selenium import webdriver
"""
我们使用的是Chrom浏览器。我们可以通
过下方命令来创建一个Chrom浏览器驱动实例.
browser=webdriver.Chrome()
"""
browser=webdriver.Chrome()
"""
我们使用30秒隐式等待时间来定义Selenium执行步
骤的超时时间,并且调用Selenium API来最大化浏览器
窗口。
"""
browser.implicitly_wait(30)
browser.maximize_window()
"""
我们使用示例程序的URL作为参数,通过调
用browser.get()方法访问该应用程序。在get()方法被调用
后,WebDriver会等待,一直到页面加载完成才继续控
制脚本。在加载页面后,Selenium会像用户真实使用那样,
和页面上各种各样的元素交互。
browser.get('https://www.baidu.com/')
"""
browser.get('https://www.baidu.com/')
"""
我们使用find_element_by_name方
法来定位搜索输入框。这个方法会返回第一个name属
性值与输入参数匹配的元素。HTML元素是用标签和属
性来定义的,我们可以使用这些信息来定位一个元素,
步骤如下。
search_field = browser.find_element_by_name("wd")
"""
search_field = browser.find_element_by_name("wd")
"""
一旦找到这个搜索输入框,我们可以使用
clear()方法来清理之前的值(如果搜索输入框已经有值
的话),并且通过send_keys()方法输入新的特定的值。
"""
search_field.clear()
search_field.send_keys("Selenium")
"""
接着我们通过调用submit()方法提交搜索请求。(对于输入框这些可以直接提交)
"""
search_field.submit()
"""
在脚本的最后,我们使用browser.quit()方法来
关闭Chrom浏览器。
"""
browser.quit()
unitt-基本认识
# 引入unittest模块
import unittest
from selenium import webdriver
"""
定义一个继承于
TestCase 类的子类,具体如下
"""
class SearchTest(unittest.TestCase):
"""
setUp()方法
一个测试用例是从setUp()方法开始执行的,我们可
以用这个方法在每个测试开始前去执行一些初始化的任
务。可以是这样的初始化准备:比如创建浏览器实例,
访问URL,加载测试数据和打开日志文件等。
此方法没有参数,而且不返回任何值。当定义了一
个setUp()方法,测试执行器在每次执行测试方法之前优
先执行该方法。在下面的例子里,我们将用setUp()方法
来创建Firefox的实例,设置properties,而且在测试开始
执行之前访问到被测程序的主页。例子如下。
"""
def setUp(self):
self.browser = webdriver.Chrome()
self.browser.implicitly_wait(30)
self.browser.maximize_window()
self.browser.get("http://demo.magentocommerce.com")
"""
编写测试
有了setUp()方法,现在可以写一些测试用来验证我
们想要测试的程序的功能。在这个例子里,我们将搜索
一个产品,然后检查是否返回一些相应的结果。与
setUp()方法相似,test方法也是在TestCase类中实现。
重要的一点是我们需要给测试方法命名为test开头。这
种命名约定通知test runner哪个方法代表测试方法。
对于test runner能找到的每个测试方法,都会在执
行测试方法之前先执行setUp()方法。这样做有助于确保
每个测试方法都能够依赖相同的环境,无论类中有多少
测试方法。我们将使用简单的assertEqual()方法来验证
用程序搜索该术语返回的结果是否和预期结果相匹配。
我们将在本章后面内容探讨更多关于断言的内容。
添加一个新的测试方法test_search_by_category(),
通过分类来搜索产品,然后校验返回的产品的数量是否
正确,具体如下。
"""
def test_search_by_category(self):
# get the search textbox
self.search_field = self.browser.find_element_by_name("q")
self.search_field.clear()
# enter search keyword and submit
self.search_field.send_keys("phones")
self.search_field.submit()
# get all the anchor elements which have product names
# displayed currently on result page using
# find_elements_by_xpath method
products = self.browser.find_elements_by_xpath("//h2[@class='product-name']/a")
self.assertEqual(2, len(products))
"""
代码清理
类似于setUp()方法在每个测试方法之前被调用,
TestCase类也会在测试执行完成之后调用tearDown()方法
来清理所有的初始化值。一旦测试被执行,在setUp()
方法中定义的值将不再需要,所以最好的做法是在测试
执行完成的时候清理掉由setUp()方法初始化的数值。在
我们的例子里,在测试执行完成后,就不再需要Firefox
的实例。我们将在tearDown()方法中关闭Firefox实例,
如下代码所示。
"""
def tearDown(self):
self.browser.quit()
"""
运行测试
为了通过命令行运行测试,我们可以在测试用例中
添加对main方法的调用。我们将传递verbosity参数以便
使详细的测试总量展示在控制台
"""
if __name__ == '__main__':
unittest.main(verbosity=2)
unitt增加测试用例
# 引入unittest模块
import unittest
from selenium import webdriver
"""
定义一个继承于
TestCase 类的子类,具体如下
"""
class SearchTest(unittest.TestCase):
"""
setUp()方法
一个测试用例是从setUp()方法开始执行的,我们可
以用这个方法在每个测试开始前去执行一些初始化的任
务。可以是这样的初始化准备:比如创建浏览器实例,
访问URL,加载测试数据和打开日志文件等。
此方法没有参数,而且不返回任何值。当定义了一
个setUp()方法,测试执行器在每次执行测试方法之前优
先执行该方法。在下面的例子里,我们将用setUp()方法
来创建Firefox的实例,设置properties,而且在测试开始
执行之前访问到被测程序的主页。例子如下。
"""
def setUp(self):
self.browser = webdriver.Chrome()
self.browser.implicitly_wait(30)
self.browser.maximize_window()
self.browser.get("http://demo.magentocommerce.com")
"""
编写测试
有了setUp()方法,现在可以写一些测试用来验证我
们想要测试的程序的功能。在这个例子里,我们将搜索
一个产品,然后检查是否返回一些相应的结果。与
setUp()方法相似,test方法也是在TestCase类中实现。
重要的一点是我们需要给测试方法命名为test开头。这
种命名约定通知test runner哪个方法代表测试方法。
对于test runner能找到的每个测试方法,都会在执
行测试方法之前先执行setUp()方法。这样做有助于确保
每个测试方法都能够依赖相同的环境,无论类中有多少
测试方法。我们将使用简单的assertEqual()方法来验证
用程序搜索该术语返回的结果是否和预期结果相匹配。
我们将在本章后面内容探讨更多关于断言的内容。
添加一个新的测试方法test_search_by_category(),
通过分类来搜索产品,然后校验返回的产品的数量是否
正确,具体如下。
"""
def test_search_by_category(self):
# get the search textbox
self.search_field = self.browser.find_element_by_name("q")
self.search_field.clear()
# enter search keyword and submit
self.search_field.send_keys("phones")
self.search_field.submit()
# get all the anchor elements which have product names
# displayed currently on result page using
# find_elements_by_xpath method
products = self.browser.find_elements_by_xpath("//h2[@class='product-name']/a")
self.assertEqual(2, len(products))
"""
添加其他测试
我们可以用一组测试来构建一个测试类,这样有助
于为一个特定功能创建一组更合乎逻辑的测试。下面为
测试类添加其他的测试。规则很简单,新的测试方法命
名也要以test开头,如下列代码。
"""
def test_search_by_name(self):
# get the search textbox
self.search_field = self.browser.find_element_by_name("q")
self.search_field.clear()
# enter search keyword and submit
self.search_field.send_keys("salt shaker")
self.search_field.submit()
# get all the anchor elements which have
# product names displayed
# currently on result page using
# find_elements_by_xpath method
products = self.browser.find_elements_by_xpath("//h2[@class='product-name']/a")
self.assertEqual(1, len(products))
"""
代码清理
类似于setUp()方法在每个测试方法之前被调用,
TestCase类也会在测试执行完成之后调用tearDown()方法
来清理所有的初始化值。一旦测试被执行,在setUp()
方法中定义的值将不再需要,所以最好的做法是在测试
执行完成的时候清理掉由setUp()方法初始化的数值。在
我们的例子里,在测试执行完成后,就不再需要Firefox
的实例。我们将在tearDown()方法中关闭Firefox实例,
如下代码所示。
"""
def tearDown(self):
self.browser.quit()
"""
运行测试
为了通过命令行运行测试,我们可以在测试用例中
添加对main方法的调用。我们将传递verbosity参数以便
使详细的测试总量展示在控制台
"""
if __name__ == '__main__':
unittest.main(verbosity=2)
unitt设置同一个开头和结尾
# 引入unittest模块
import unittest
from selenium import webdriver
"""
定义一个继承于
TestCase 类的子类,具体如下
"""
class SearchTest(unittest.TestCase):
@classmethod
def setUpClass(cls):
cls.browser = webdriver.Chrome()
cls.browser.implicitly_wait(30)
cls.browser.maximize_window()
cls.browser.get("http://demo.magentocommerce.com")
def test_search_by_category(self):
# get the search textbox
self.search_field = self.browser.find_element_by_name("q")
self.search_field.clear()
# enter search keyword and submit
self.search_field.send_keys("phones")
self.search_field.submit()
# get all the anchor elements which have product names
# displayed currently on result page using
# find_elements_by_xpath method
products = self.browser.find_elements_by_xpath("//h2[@class='product-name']/a")
self.assertEqual(2, len(products))
def test_search_by_name(self):
# get the search textbox
self.search_field = self.browser.find_element_by_name("q")
self.search_field.clear()
# enter search keyword and submit
self.search_field.send_keys("salt shaker")
self.search_field.submit()
products = self.browser.find_elements_by_xpath("//h2[@class='product-name']/a")
self.assertEqual(1, len(products))
@classmethod
def tearDownClass(cls):
cls.browser.quit()
"""
运行测试
为了通过命令行运行测试,我们可以在测试用例中
添加对main方法的调用。我们将传递verbosity参数以便
使详细的测试总量展示在控制台
"""
if __name__ == '__main__':
unittest.main(verbosity=2)
unitt断言
import unittest
from selenium import webdriver
browers = webdriver.Chrome()
class SearchTest(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Chrome()
self.browser.implicitly_wait(30)
self.browser.maximize_window()
self.browser.get("https:www.baidu.com")
def test_search_by_category(self):
# get the search textbox
self.search_field = self.browser.find_element_by_name("wd")
self.search_field.clear()
# enter search keyword and submit
self.search_field.send_keys("phones")
self.search_field.submit()
"""
断言
unittest的TestCase类提供了很多实用的方法来校验
预期结果和程序返回的实际结果是否一致。这些方法要
求必须满足某些条件才能继续执行接下来的测试。大致
有3种这样的方法,各覆盖一个特定类型的条件,例如
等价校验、逻辑校验和异常校验。如果给定的断言通过
了,接下来的测试代码将会执行;相反,将会导致测试
立即停止并且给出异常信息。
"""
products = self.browser.find_elements_by_xpath("//h2[@class='product-name']/a")
self.assertEqual(2, len(products))
"""
这些方法校验a和b是否相等,msg对象
是用来说明失败原因的消息。
这对于验证元素的值和属性等是非常
有用的。例如:
assertEqual(element.text, "10"
"""
#self.assertEqual(a,b[,msg]) 相等 a = b
#self.assertNotEquals(a,b[,msg]) 不相等 a != b
# ps:判断值
"""
这些方法校验给出的表达式是True还
是False。
例如,校验一个元素是否出现在页
面,我们可以用下面的方法:
assertTrue(element.is_displayed())
"""
# self.assertTrue(x[,msg]) bool(x) is True
# self.assertFalse(x[,msg]) bool(x) is False
# self.assertIsNot(a,b[,msg]) a is not b
# ps:判断对象
"""
这些方法校验特定的异常是否被具体
的测试步骤抛出,用到该方法的一种
可能情况是:
NoSuchElementFoundexception
"""
#self.assertRaises(exc,fun,*args,**kwds)
#self.assertRaisesRegexp(exc,fun,*args,**kwds)
"""
这些方法用于检查数值,在检查之前
会按照给定的精度把数字四舍五入。
这有助于统计由于四舍五入产生的错
误和其他由于浮点运算产生的问题
"""
# self.assertAlmostEqual() round(a-b, 7) == 0
# self.assertNotAlmostEqual() round(a-b, 7) != 0
"""
这些方法类似于assertEqual()方法,是
为逻辑判定条件设计的
"""
# self.assertGreater() 大于
# self.assertGreaterEqual() 大于等于
# self.assertLess() 小于
# self.assertLessEqual() 小于等于
"""
这些方法检查文本是否符合正则匹配
"""
# self.assertRegexpMatches() r.search(s)
"""
此方法是assertEqual()的一种特殊形
式,为多行字符串设计。等值校验和
其他单行字符串校验一样,但是默认
失败信息经过优化以后可以展示具体
值之间的差别
"""
# self.assertMultiLineEqual(a, b)
"""
此方法校验两个list是否相等,对于下
拉列表选项字段的校验是非常有用的
"""
# assertListEqual(a, b)
"""此方法是无条件的失败。在别的assert
方法不好用的时候,也可用此方法来
创建定制的条件块
"""
# self.fail()
def tearDown(self):
self.browser.quit()
unitt测试套件
import unittest
import searchtests
"""
测试套件
应用unittest的TestSuites特性,可以将不同的测试
组成一个逻辑组,然后设置统一的测试套件,并通过一
个命令来执行测试。这都是通过TestSuites、TestLoader
和TestRunner类来实现的。
"""
#手工添加案例到套件(一),
# def createsuite():
# suite = unittest.TestSuite()
# # 将测试用例加入到测试容器(套件)中
# suite.addTest(searchtests.SearchTest("test_search_by_name")) #文件名.类名(方法名)
# suite.addTest(searchtests.SearchTest("test_search_by_name")) #文件名.类名(方法名)
# suite.addTest(searchtests.SearchTest("test_search_by_name")) #文件名.类名(方法名)
# return suite
#手工添加案例到套件(二)
def createsuite():
suite = unittest.TestSuite()
suite1 = unittest.TestLoader().loadTestsFromTestCase(searchtests.SearchTest)
# suite1 = unittest.TestLoader().loadTestsFromTestCase(searchtests.SearchTest.test_search_by_category()) #添加某一个测试用例
# suite2 = unittest.TestLoader().loadTestsFromTestCase(testbaidu2.Baidu2)
# suite = unittest.TestSuite([suite1, suite2])
suite = unittest.TestSuite(suite1)
return suite
"""
使用TestLoader类,我们将得到指定测试文件中的
所有测试方法且用于创建测试套件。TestRunner类将通
过调用测试套件来执行文件中所有的测试。
"""
if __name__=="__main__":
suite=createsuite()
runner = unittest.TextTestRunner(verbosity=2)
runner.run(suite)
unitt生成HTML格式的测试报告
就是HTMLTestRunner是Python标准库的unittest模块的扩展,无法通过pip安装。
那么我们要怎么使用和下载HTMLTestRunner呢?
其实解决方法很简单,需要通过手动下载HTMLTestRunner.py文件,放在python目录Lib文件夹下即可:
参考:https://www.cnblogs.com/mengjinxiang/archive/2020/04/08/12657371.html
import unittest
import HTMLTestRunner
import searchtests
import os
"""
unittest在命令行输出测试结果。你可能需要生成一
个所有测试的执行结果作为报告或者把测试结果发给相
关人员。给相关人员发送命令行日志不是一个明智的选
择。他们需要格式更加友好的测试报告,既能够查看测
试结果的概况,也能够深入查看报告细节。unittest没有
相应的内置模块可以生成格式友好的报告,我们可以应
用Wai Yip Tung编写的unittest的扩展HTMLTestRunner
来实现。
"""
dir = os.getcwd()
def createsuite():
suite = unittest.TestSuite()
suite1 = unittest.TestLoader().loadTestsFromTestCase(searchtests.SearchTest)
# suite1 = unittest.TestLoader().loadTestsFromTestCase(searchtests.SearchTest.test_search_by_category()) #添加某一个测试用例
# suite2 = unittest.TestLoader().loadTestsFromTestCase(testbaidu2.Baidu2)
# suite = unittest.TestSuite([suite1, suite2])
suite = unittest.TestSuite(suite1)
outfile = open(dir + "\SmokeTestReport.html", "w")
runner = HTMLTestRunner.HTMLTestRunner(stream=outfile,title='Test Report',description='Smoke Tests')
runner.run(suite)
if __name__=="__main__":
createsuite()
报错了(待解决):
File "E:\localCodecloudwarehouse\python_learn\HTMLTestRunner.py", line 692, in generateReport
self.stream.write(output.encode('utf8'))
TypeError: write() argument must be str, not bytes
unitt定位
import unittest
from selenium import webdriver
browser = webdriver.Chrome()
# 如果element加了s代表有一组
# browser.get("https:www.baidu.com")
# browser.find_element_by_name('name属性名')
# browser.find_element_by_xpath('xpath值')
# browser.find_element_by_class_name('class名')
# browser.find_element_by_id('id值')
WebDriver功能(一)
import unittest
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https:www.baidu.com')
"""
WebDriver功能
WebDriver通过下表的功能来操纵浏览器
current_url 获取当前页面的URL地址
current_window_handle 获取当前窗口的句柄
name 获取该实例底层的浏览器名称
orientation 获取当前设备的方位
page_source 获取当前页面的源代码
title 获取当前页面的标题
window_handles 获取当前session里所有窗口的句柄
"""
print(browser.current_url)
print('-------------------------------------------------------')
print(browser.current_window_handle)
print('-------------------------------------------------------')
print(browser.name)
print('-------------------------------------------------------')
# print(browser.orientation)
# print('-------------------------------------------------------')
print(browser.page_source)
print('-------------------------------------------------------')
print(browser.title)
print('-------------------------------------------------------')
print(browser.window_handles)
print('-------------------------------------------------------')
browser.quit()
WebDriver方法(一)
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https:www.baidu.com')
"""
WebDriver方法
WebDirver通过一些方法来实现与浏览器窗口、网页和页面元素的交互。下表是一些重要的方法。
back() 后退一步到当前会话的浏览器历史记录中最后一步操作前的页面
close() 关闭当前浏览器窗口
forward() 前进一步到当前会话的浏览器历史记录中前一步操作后的页面
get(url) 访问目标URL并加载网页到当前的浏览器会话
maximize_window() 最大化当前浏览器窗口
quit() 退出当前driver并且关闭所有的相关窗口
refresh() 刷新当前页面
switch_to_active_element() 返回当前页面唯一焦点所在的元素或者元素体
switch_to_alert() 把焦点切换至当前页面弹出的警告
switch_to_default_content() 切换焦点至默认框架内
switch_to-frame(frame_reference) 通过索引、名称和网页元素将焦点切换到指定的框架,这种方法也适用于IFRAMES
switch_to_window(window_name) 切换焦点到指定的窗口
implicitly_wait(time_to_wait) 超时设置等待目标元素被找到,或者目标指令执行完成。该方法在每个session只需要调用一次。execute_async_script的超时设置,请参阅set_script_timeout方法
set_page_load_timeout(time_to_wait) 设置一个页面完全加载完成的超时等待时间
set_script_timeout(time_to_wait) 设置脚本执行的超时时间,应该在execute_async_script抛出错误之前
"""
WebElement接口
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https:www.baidu.com')
"""
我们可以通过WebElement实现与网站页面上的元
素的交互。这些元素包含文本框、文本域、按钮、单选
框、多选框、表格、行、列和div等。
WebElement提供了一些功能、属性和方法来实现
与网页元素的交互。本节的表格中将列出后面章节会用
到的一些重要的功能和方法。如果想查看完整的功能和
方法详情,请访问以下网站。
http://selenium.googlecode.com/git/docs/api/py/webdriver_remote/selenium.webdriver.remote.webelement.html#module-
selenium.webdriver.remote.webelement
WebElement功能
下面是WebElement功能列表。
针对的是element
size 获取元素的大小 element.size
tag_name 获取元素的HTML标签名称
text 获取元素的文本值
"""
"""
WebElement方法
下面是WebElement方法列表。
针对的是element
clear() 清除文本框或者文本域中的内容
click() 单击元素
get_attribute(name) 获取元素的属性值
is_displayed() 检查元素对于用户是否可见
is_enabled() 检查元素是否可用
is_selected() 检查元素是否被选中。该方法应用于复选框和单选按钮
send_keys(*value) 模拟输入文本
submit() 用于提交表单。如果对一个元素应用此方法,将会提交该元素所属的表单
value_of_css_property(property_name) 获取CSS属性的值 element.value_of_css_property
("backgroundcolor")
"""
WebElement接口实战(已失效)
"""
我们将使用WebElement及其功能和
方法实现在样例程序中创建账户功能的自动化。接下
来我们创建一个测试脚本,来验证被测程序是否能正确
创建一个新的账户。我们将按照下图来填写表单信息并
且提交请求,系统收到请求后应该创建一个新的账户。
"""
import unittest
from selenium import webdriver
"""
(1)首先,创建一个新的测试类RegisterNewUser,下面是实例代码。
"""
class RegisterNewUser(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(30)
self.driver.get("http://demo.magentocommerce.com/")
self.driver.minimize_window()
"""
(2)添加一个测试方法test_register_new_user(self) 到RegisterNewUser类中。
(3)为了打开登录页面,我们需要单击主页的登录链接。用于登录的代码如下。
"""
def test_register_new_user(self):
driver = self.driver
driver.find_element_by_link_text("Log In").click()
"""检查元素是否启用或显示
当元素在屏幕上可见的时候(visible属性设置为TRUE),调用is_displayed() 方法返回为TRUE,反之
就会返回FALSE。类似地,当元素是可用的时候,调用is_enabled() 方法返回为TRUE,这时用户就可以执行
点击和输入文本等操作。当元素是不可用的时候,该方法返回FALSE。
用户登录页面提供了使用已有账户登录和创建新用
户的选项。我们可以通过调用is_displayed()方法和
is_enabled()方法检查创建新账户按钮对于用户是否可见
并且可用。添加下面的代码到测试类中。
"""
create_account_button = driver.find_element_by_xpath("//button[ @ title = 'Create an Account']")
self.assertTrue(create_account_button.is_displayed() and create_account_button.is_enabled())
"""
我们要测试创建账户功能,因此要单击创建账户按
钮,然后将会展示创建新账户的页面。我们可以通过检
查WebDriver 的 title 属性来校验打开的页面是否符合预
期结果,代码如下。
"""
create_account_button.click()
self.assertEquals("Create New Customer Account -Magento Commerce Demo Store", driver.title)
"""
在创建新账户页面,可以通过调用find_element_by_* 方法来查找定位所有的元素。
"""
first_name = driver.find_element_by_id("firstname")
last_name = driver.find_element_by_id("lastname")
email_address = driver.find_element_by_id("email_address")
news_letter_subscription = driver.find_element_by_id("is_subscribed")
password = driver.find_element_by_id("password")
confirm_password = driver.find_element_by_id("confirmation")
submit_button = driver.find_element_by_xpath("//button[@title='Submit']")
"""
获取元素对应的值
get_attribute()方法可以用来获取元素的属性值。例
如,单个测试是用来验证输入姓和名字的文本框的最大
字符限制是255,字符限制就是通过maxlength属性来实
现的,如下代码所示设置值为255。
我们可以通过调用get_attribute()方法来校验
maxlength 属性是否正确。
(1)需要把属性名称作为参数传递给
get_attribute()方法。
"""
self.assertEqual("255", first_name.get_attribute("maxlength"))
self.assertEqual("255", last_name.get_attribute("maxlength"))
"""
(2)添加以下代码到测试脚本中,以确保所有的字段对于用户都是可见和可用的。
"""
self.assertTrue(first_name.is_enabled()
and last_name.is_enabled()
and email_address.is_enabled()
and news_letter_subscription.is_enabled()
and password.is_enabled()
and confirm_password.is_enabled()
and submit_button.is_enabled())
"""
is_selected()方法
is_selected() 方法是针对单选按钮和复选框的。我们可以通过调用该方法来得知一个单选按钮或复选框是否被选中。
单选按钮或复选框可以通过WebElement 的 click()方法来执行点击操作,从而选中该元素。如下面的例子,
检查Sign UP for Newsletter 复选框是否默认为不被选中的,示例代码如下。
"""
self.assertFalse(news_letter_subscription.is_selected())
"""
clear()与send_keys()方法
clear() 和 send_keys()方法适用于文本框和文本域,
分别用于清除元素的文本内容和模拟用户操作键盘来输
入文本信息。待输入的文本作为send_keys() 方法的参
数。
(1)添加下面的代码,通过send_keys() 方法来给对应的字段填写值。
"""
# fill out all the fields
first_name.send_keys("Test")
last_name.send_keys("User1")
news_letter_subscription.click()
email_address.send_keys("[email protected]")
password.send_keys("tester")
confirm_password.send_keys("tester")
"""(2)最终通过校验欢迎信息来检查用户是否创建成功。
我们可以通过text属性来获取元素的文本内容。
"""
# check new user is registered
self.assertEqual("Hello, Test User1!", driver.find_element_by_css_selector("p.hello > strong").text)
self.assertTrue(driver.find_element_by_link_text("LogOut").is_displayed())
"""
(3)运行这个测试脚本将看到在 Create An Account 页面的所有操作。"""
def tearDown(self):
self.driver.quit()
if __name__ == '__main__':
unittest.main(verbosity=2)
WebDriver操作下拉菜单
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https:www.baidu.com')
"""
Selenium WebDriver提供了特定的Select类实现与网
页上的列表和下拉菜单的交互。例如下面的样例程序,
可以看到一个为店铺选择语言的下拉菜单
下拉菜单和列表是通过HTML的
"""
Select原理
Select 类是Selenium的一个特定的类,用于与下拉
菜单和列表交互。它提供了丰富的功能和方法来实现与
用户交互。
下面两小节的表格列出来Select类中所有的功能和方法。你也可以在下面网址获取类似信息。
http://selenium.googlecode.com/git/docs/api/py/webdriselenium.webdriver.support.select
"""
"""
Select功能
Select类实现的功能见下表。
针对对象select_element
all_selected_options 获取下拉菜单和列表中被选中的所有选项内容 select_element.all_selected_options
first_selected_option 获取下拉菜单和列表的第一个选项/当前选择项
options 获取下拉菜单和列表的所有选项
"""
"""
Select方法
Select类实现的方法见下表。
针对对象select_element
deselect_all() 清除多选下拉菜单和列表的所有选择项
deselect_by_index(index) 根据索引清除下拉菜单和列表的选择项
deselect_by_value(value) 清除所有选项值和给定参数匹配的下拉菜单和列表的选择项 value:要清除的目标选择项的value属性
deselect_by_visible_text(text) 清除所有展示的文本和给定参数匹配的下拉菜单和列表 text:要清除的目标选择项的文本值
select_by_index(index) 根据索引选择下拉菜单和列表的选择项
select_by_value(value) 选择所有选项值和给定参数匹配的下拉菜单和列表的选择项 value:要选择的目标选择项的value属性
select_by_visible_text(text) 选择所有展示的文本和给定参数匹配的下拉菜单和列表的选择项 text:要选择的目标选择项的文本值
"""
WebDriver操作警告和弹窗框
```handlebars
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https:www.baidu.com')
"""
开发人员使用JavaScript 警告或者模态对话框来提
示校验错误信息、报警信息、执行操作后的返回信息,
甚至用来接收输入值等。本节我们将了解如何使用
Selenium来操控警告和弹出框。
"""
"""
Alert 原理
Selenium WebDriver 通过Alert 类来操控 JavaScript警告。
Alert 包含的方法有接受、驳回、输入和获取警告的文本。
Alert功能
Alert 实现了下表的功能。
text 获取警告窗口的文本 alert.text
Alert方法
Alert实现了下表的方法。
accept() 接受JavaScript 警告信息,单击OK 按钮
dismiss() 驳回JavaScript 警告信息,单击取消按钮
send_keys(*value) 模拟给元素输入信息 value:待输入目标字段的字符串
"""
"""
我们可以通过Alert来操控这个警告。调用
WebDirver 的Switch_to_alert() 方法可以返回一个Alert
的实例。我们可以利用这个Alert 实例来获取警告信
息,并通过单击OK按钮来接受这个警告信息,或者通
过单击Cancel 按钮来拒绝这个警告。
"""
# alert = self.driver.switch_to_alert()
# alert_text = alert.text
# self.assertEqual("Are you sure you would like toremove all products from your comparison?", alert_text)
# alert.accept()
selenium隐式等待
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
import unittest
"""
隐式等待
隐式等待为WebDriver中的完整的一个测试用例或
者一组测试的同步,提供了通用的方法。隐式等待对于
解决由于网络延迟或利用Ajax动态加载元素所导致的程
序响应时间不一致,是非常有效的。
当设置了隐式等待时间后,WebDriver会在一定的
时间内持续检测和搜寻DOM,以便于查找一个或多个
不是立即加载成功并可用的元素。一般情况下,隐式等
待的默认超时时间设置为0。
一旦设置,隐式等待时间就会作用于这个
WebDriver实例的整个生命周期或者一次完整测试的执
行期间,并且WebDriver会使其对所有测试步骤中包含
整个页面的元素的查找时都有效,除非把默认超时时间
设置回0。
WebDriver类提供了implicitly_wait()方法来配置超
时时间。
在setUp() 方法中加入隐式等待时间并且设置为
10秒,代码如下面的例子所示。当一个测试用例执行的
时候,WebDirver在找不到一个元素的时候,将会等待
10秒。当达到10秒超时时间后,将会抛出一个
NoSuchElementException 的异常。
"""
class SearchTest(unittest.TestCase):
def setUp(self):
self.browser = webdriver.Chrome()
self.browser.implicitly_wait(30)
self.browser.maximize_window()
self.browser.get("https:www.baidu.com")
"""
应尽量避免在测试中隐式等待与显式等待混合使
用,来处理同步问题。相比隐式等待,显式等待能提
供更好的可操控性
"""
selenium显示等待
"""
显式等待
显式等待是WebDriver中用于同步测试的另外一种
等待机制。显式等待比隐式等待具备更好的操控性。与
隐式等待不同,我们可以为脚本设置一些预置或定制化
的条件,等待条件满足后再进行下一步测试。
显式等待可以只作用于仅有同步需求的测试用例。
WebDriver提供了WebDriverWait类和
expected_conditions类来实现显式等待。
expected_conditions类提供了一些预置条件,来作
为测试脚本进行下一步测试的判断依据。让我们创建一
个包含显式等待的简单的测试,条件是等待一个元素可
见,代码如下。
"""
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
import unittest
class ExplicitWaitTests(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.get("http://demo.magentocommerce.com/ ")
def test_account_link(self):
# WebDriverWait(self.driver,10).until('条件')
WebDriverWait(self.driver, 10).until(lambda s: s.find_element_by_id("select -language").get_attribute("length") == "3")
account = WebDriverWait(self.driver, 10).until(expected_conditions.visibility_of_element_located((By.LINK_TEXT, "ACCOUNT")))
account.click()
"""
在上面的测试中,显式等待条件是等到Log In链接
在DOM中可见。
使用visibility_of_element_located方法来判断预期条
件是否满足。该条件判断方法需要设置符合要求的定位
策略和位置详细信息。脚本将一直查找目标元素是否可
见,直到达到最大等待时间10秒。一旦根据指定的定位
器找到了元素,预期条件判定方法将会把定位到的元素
返回给测试脚本。
如果在设定的超时时间内,仍然没有通过定位器找
到可见的目标元素,将会抛出TimeoutException异常。
"""
"""
expected_conditions类
下表是expected_conditions类支持的在执行网页浏览器自动化操作时常常用到的一些通用的等待条件。
element_to_be_clickable(locator) 等待通过定位器查找的元素可见并且可用,以便确定元素是可点击的。此方法返回定位到的元素 locator:一组(by,locator)
element_to_be_selected(element) 等待直到指定的元素被选中 element:是个WebElement
invisibility_of_element_located(locator) 等待一个元素在DOM中不可见或不存在 locator:一组(by,locator)
presence_of_all_elements_located(locator) 等待直到至少有一个定位器查找匹配到的目标元素出现在网页中。该方法返回定位到的一组WebElement locator:一组(by,locator)
presence_of_element_located(locator) 等待直到定位器查找匹配到的目标元素出现在网页中或可以在DOM中找到。 该方法返回一个被定位到的元素 locator:一组(by,locator)
text_to_be_present_in_element(locator,text_) 等待直到元素能被定位到并且带有相应的文本信息 locator:一组(by,locator)text:需要被校验的文本内容
title_contains(title) 等待网页标的大小写敏感的字符串。该方法在匹配成功时返回True,否则返回False
title_is(title) 等待网页标题与预期的标题相一致。该方法在匹配成功时返回True,否则返回False
visibility_of(element) 等待直到元素出现在DOM中,是可见的,并且宽和高都大于0。一旦其变成可见的,该方法将返回(同一个)WebElement element :目标WebElement
visibility_of_element_located(locator) 等待直到根据定位器查找的目标元素出现在DOM中,是可见的,并且宽和高都大于0。一旦其变成可见的,该方法将返回WebElement locator:一组(by,locator)
"""
"""
在下面的网址可看到预期条件判断的完整列表:
http://selenium.googlecode.com/git/docs/api/py/webdriver_support/selenium.webdriver.support.expected_conditions.html#module-selenium.webdriver.support. expected_conditions。
"""
def tearDown(self):
self.driver.quit()
if __name__ == '__main__':
unittest.main(verbosity=2)
selenium预期条件判断等待
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
import unittest
"""
正如在前面章节所了解到的,expected_conditions
类提供了多种定义好的预期等待条件。我们也可以通过
WebDriverWait 来自定义预期等待条件。当没有合适的
预期等待条件可用的时候,自定义的预期等待条件也是
非常有效的。
让我们来修改一个前面章节中创建好的测试脚本,
实现一个自定义的预期条件判断,来检测下拉列表中可
选项的数量。
"""
def testLoginLink(self):
WebDriverWait(self.driver, 10).until(lambda s: s.find_element_by_id("select-language").get_attribute("length") == "3")
login_link = WebDriverWait(self.driver, 10).until(expected_conditions.visibility_of_element_located((By.LINK_TEXT,"Log In")))
login_link.click();
"""
我们可以使用Python的lambda表达式,并且基于WebDriverWait来实现自定义的预期条件判断。
上面的例子中,脚本将会等待10秒,直到Select Language下拉
列表中有8个可选项。当下拉列表是通过Ajax调用来实
现,并且脚本需要等待下拉列表中的所有选项都是可选
择时,该预期条件判断是非常有用的。
"""
selenium使用ddt执行数据驱动测试(内部自定义,CSV,excel,数据库)
"""
使用ddt执行数据驱动测试
dt的库可以将测试中的变量进行参数化。例如,
我们可以通过定义一个数组来实现数据驱动测试。
ddt的库包含一组类和方法用于实现数据驱动测试。
安装ddt
可以使用下面的命令来下载与安装ddt。
pip install ddt
"""
"""
设计一个简单的数据驱动测试
我们将一个之前使用数据硬编码的搜索场景测试,
转换成用数据驱动模式进行测试,并且使得脚本可以搜
索多种类别的商品。
为了创建数据驱动测试,我们需要在测试类上使用
@ddt装饰符,在测试方法上使用@data装饰符。@data
装饰符把参数当作测试数据,参数可以是单个值、列
表、元组、字典。对于列表,需要用@unpack装饰符把
元组和列表解析成多个参数。
接下来实现这个搜索测试,传入搜索关键词和期望
结果,代码如下。
"""
#
# import unittest
# from ddt import ddt, data, unpack
# from selenium import webdriver
#
# @ddt
# class SearchDDT(unittest.TestCase):
# def setUp(self):
# self.driver = webdriver.Chrome()
# self.driver.implicitly_wait(30)
# self.driver.maximize_window()
# self.driver.get("http://demo.magentocommerce.com/")
# @data(("phones", 2), ("music", 5))
# @unpack
# def test_search(self, search_value, expected_count):
# print(search_value)
# print(expected_count)
# self.search_field = self.driver.find_element_by_name("q")
# self.search_field.clear()
# self.search_field.send_keys(search_value)
# self.search_field.submit()
# products = self.driver.find_elements_by_xpath("//h2[@class='product-name']/a")
# self.assertEqual(expected_count, len(products))
# def tearDown(self):
# self.driver.quit()
#
# if __name__ == '__main__':
# unittest.main(verbosity=2)
"""
使用外部数据的数据驱动测试
在先前的例子里,我们在脚本中直接提供了测试数
据。然而,有时你会发现所需要的测试数据在测试脚本
外部已经存在了,诸如一个文本文件、电子表格或是数
据库。这可以使得我们的测试脚本与测试数据分离开
来,可以方便我们每次更新与维护测试脚本,而不用担
心测试数据。
下面我们一起学习如何借助外部的CSV(逗号分隔
值)文件或是Excle表格数据来实现ddt。
通过CSV获取数据
结合前面的测试脚本,我们在@data装饰符中使用
解析的外部的CSV(testdata.csv)来换掉之前的测试数
据。其中CSV数据文件如下图所示。
接下来,我们在@data装饰符中实现get_data()方
法,其中包括路径、CSV文件名。这个方法调用CSV库
去读取文件并且返回一行数据。
如果出现这个错误:_csv.Error: iterator should return strings, not bytes (did you open the file in text mode?)
问题分析
因为此csv文件并非二进制文件, 只是一个文本文件。
问题解决
with open("fer2013.csv", "rt", encoding="utf-8") as vsvfile:
reader = csv.reader(vsvfile)
rows = [row for row in reader]
print(rows)
或者
# 因为open()默认打开文本文件
with open("fer2013.csv", "r", encoding="utf-8") as vsvfile:
reader = csv.reader(vsvfile)
rows = [row for row in reader]
print(rows)
就是rb 改成 rt 或 r
"""
# import csv
# import unittest
# from ddt import ddt, data, unpack
# from selenium import webdriver
#
#
# def get_data(file_name):
# rows = []
# data_file = open(file_name, "rt")
# reader = csv.reader(data_file)
# a= next(reader, None)
# for row in reader:
# rows.append(row)
# return rows
#
# get_data('C:/Users/hanson/Desktop/work/testdata.csv')
# @ddt
# class SearchDDT(unittest.TestCase):
# def setUp(self):
# self.driver = webdriver.Chrome()
# self.driver.implicitly_wait(30)
# self.driver.maximize_window()
# self.driver.get("http://demo.magentocommerce.com/")
# @data(*get_data("C:/Users/hanson/Desktop/work/testdata.csv"))
# @unpack
# def test_search(self, search_value, expected_count):
# print(search_value)
# print(expected_count)
# self.search_field = self.driver.find_element_by_name("q")
# self.search_field.clear()
# self.search_field.send_keys(search_value)
# self.search_field.submit()
# products = self.driver.find_elements_by_xpath("//h2[@class='product-name']/a")
# self.assertEqual(expected_count, len(products))
# def tearDown(self):
# self.driver.quit()
#
# if __name__ == '__main__':
# unittest.main(verbosity=2)
"""
通过Excel获取数据
用Excel来维护测试数据是最常用的做法。这还可
以帮助非技术人员很轻松地添加一行需要的测试数据。
结合上面的例子,我们把数据整理到Excel中,如下图
所示。
读取Excel文件,我们需要用到另外一个叫xlrd的
库,其安装命令如下。
pip install xlrd
xlrd库提供了读取工作簿、工作表以及单元格的
方法。如果需要往表格中写数据,则需要用到xlwt
库。另外,openpyxl提供了对电子表格可读可写的功
能。
接下来我们修改get_data()方法,试着从外部的电
子表格获取测试数据,代码如下。
"""
# import xlrd, unittest
# from ddt import ddt, data, unpack
# from selenium import webdriver
#
# def get_data(file_name):
# rows = []
# book = xlrd.open_workbook(file_name)
# sheet = book.sheet_by_index(0)
# for row_idx in range(1, sheet.nrows):
# rows.append(list(sheet.row_values(row_idx, 0, sheet.ncols)))
# print(rows)
# return rows
#
# get_data('C:/Users/hanson/Desktop/work/testdata02.xlsx')
# @ddt
# class SearchDDT(unittest.TestCase):
# def setUp(self):
# self.driver = webdriver.Chrome()
# self.driver.implicitly_wait(30)
# self.driver.maximize_window()
# self.driver.get("http://demo.magentocommerce.com/")
#
# @data(*get_data("C:/Users/hanson/Desktop/work/testdata02.xlsx"))
# @unpack
# def test_search(self, search_value, expected_count):
# print(search_value)
# print(expected_count)
# self.search_field = self.driver.find_element_by_name("q")
# self.search_field.clear()
# self.search_field.send_keys(search_value)
# self.search_field.submit()
# products = self.driver.find_elements_by_xpath("//h2[@class='product-name']/a")
# self.assertEqual(expected_count, len(products))
# def tearDown(self):
# self.driver.quit()
#
# if __name__ == '__main__':
# unittest.main(verbosity=2)
"""
通过数据库获取数据
如果你想要从数据库的库表中获取数据,那么你
同样需要修改get_data()方法,并且通过DB相关的库
来连接数据库、SQL查询来获取测试数据。
"""
selenium的PageObject模式
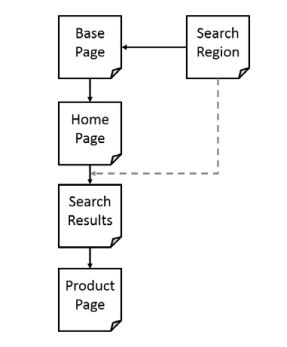
步骤一: 创建名为basetestcase.py的脚本,实现一个名为BaseTestCase的类,用于给我们提供
setUp()和tearDown()两种方法,以便后续我们写每个类都可以拿来复用。
basetestcase.py
import unittest
from selenium import webdriver
class BaseTestCase(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrom()
self.driver.implicitly_wait(30)
self.driver.maximize_window()
self.driver.get('http://demo.magentocommerce.com/')
def tearDown(self):
self.driver.quit()
步骤二:创建名为base.py的脚本,实现一个名为BasePage 对象,BasePage 对象相当于所有页面对象中的父对象,同时可以提供公共部分的代码。
解析:我们增加了一个名为_validate_page()的抽象方法,继承BasePage的page对象将实现这个方法,目的是在能够使用属性和操作之前,验证页面是否已经加载到浏览器。
另外,我们还创建了search属性用于返回SearchRegion对象。类似于一个页面对象,SearchRegion相当于每个页面都用到的搜索框。所以接下来其他页面对象都可以共享这个BasePage类。
最后,我们也实现了_validate_page()方法中用到的invalidPageException,如果页面验证失败,InvalidPageException将会被抛出。
base.py
from abc import abstractmethod
class BasePage(object):
def __init__(self, driver):
self._validate_page(driver)
self.driver = driver
@abstractmethod
def _validate_page(self, driver):
return
@property
def search(self):
from search import SearchRegion
return SearchRegion(self.driver)
class InvalidPageException(Exception):
pass
**步骤三:**前面基础做完后就可以实现pageobject了,首先,我们定义HomePage,创建
homepage.py,
解析:我们要遵循的一点是将定位器字符串与它们的使用
位置分离开。我们可以创建一个“_”前缀的私有变量,
例如,用_home_page_slideshow_locator变量来保存应用
程序首页的slideshow组件的定位器字符串。我们可以利
用这个来确认浏览器是否正常加载了首页
_home_page_slideshow_locator = ‘div.slideshow-container’
然后,我们可以创建_validate_page()方法,通过判
断slideshow元素是否已经显示在首页上了,来判断首页
是否被加载。
homepage.py
from base import BasePage
from base import InvalidPageException
class HomePage(BasePage):
_home_page_slideshow_locator = 'div.slideshow-container'
def __init__(self, driver):
super(HomePage, self).__init__(driver)
def _validate_page(self, driver):
try:
driver.find_element_by_class_name(self._home_page_slideshow_locator)
except:
raise InvalidPageException("Home Page not loaded")
步骤四:接下来,我们实现SearchRegion 类,包括searchFor()方法,该方法用于返回SearchResults类对应
的搜索结果页面。创建一个新的脚本search.py,并且实现这两个类
search.py
from base import BasePage
from base import InvalidPageException
from product import ProductPage
class SearchRegion(BasePage):
_search_box_locator = 'q'
def __init__(self, driver):
super(SearchRegion, self).__init__(driver)
def searchFor(self, term):
self.search_field = self.driver.find_element_by_name (self._search_box_locator)
self.search_field.clear()
self.search_field.send_keys(term)
self.search_field.submit()
return SearchResults(self.driver)
class SearchResults(BasePage):
_product_list_locator = 'ul.products-grid > li'
_product_name_locator = 'h2.product-name a'
_product_image_link = 'a.product-image'
_page_title_locator = 'div.page-title'
_products_count = 0
_products = {
}
def __init__(self, driver):
super(SearchResults, self).__init__(driver)
results = self.driver.find_elements_by_css_selector(self._product_list_locator)
for product in results:
name = product.find_element_by_css_selector(self._product_name_locator).text
self._products[name] = product.find_element_by_css_selector(self._product_image_link)
def _validate_page(self, driver):
if 'Search results for' not in driver.title:
raise InvalidPageException('Search results not loaded')
@ property
def product_count(self):
return len(self._products)
def get_products(self):
return self._products
def open_product_page(self, product_name):
self._products[product_name].click()
return ProductPage(self.driver)
**步骤五:**最后,我们要实现ProductPage类,这个类包括了很多有关商品的一些属性。访问一个商品的详细页
面,可以通过SearchResults类,打开搜索结果中一个具体的产品。创建product.py脚本文件实现ProductPage
类
product.py
from base import BasePage
from base import InvalidPageException
class ProductPage(BasePage):
_product_view_locator = 'div.product-view'
_product_name_locator = 'div.product-name span'
_product_description_locator = 'div.tab-content div.std'
_product_stock_status_locator = 'p.availability span.value'
_product_price_locator = 'span.price'
def __init__(self, driver):
super(ProductPage, self).__init__(driver)\
@property
def name(self):
return self.driver.find_element_by_css_selector(self._product_name_locator).text.strip()
@property
def description(self):
return self.driver.find_element_by_css_selector (self._product_description_locator).text.strip()
@property
def stock_status(self):
return self.driver.find_element_by_css_selector (self._product_stock_status_locator).text.strip()
# @property
# def price(self):
# return self.driver.find_element_by_css_selector(self._product_price_locator).text.strip()
def _validate_page(self, driver):
try:
driver.find_element_by_css_selector(self._product_view_locator)
except:
raise InvalidPageException('Product page not loaded')
selenium的PageObject模式-仿写测试百度
步骤一:创建basetestcase.py,实现一个名为BaseTestCase的类,用于给我们提供setUp()和tearDown()两种方法,以便后续我们每个类都可以拿来复用
basetestcase.py
import unittest
from selenium import webdriver
class BaseTestCase(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.maximize_window()
self.driver.get('https:www.baidu.com')
self.driver.implicitly_wait(30)
def tearDown(self):
self.driver.quit()
**步骤二:**创建名为base.py的脚本,实现一个名为BasePage对象,BasePage对象相当于所有页面对象中的父对象,同时提供公共部分的代码
base.py
from abc import abstractmethod
class BasePage(object):
def __init__(self, driver):
self._validate_page(driver)
self.driver = driver
@abstractmethod
def _validate_page(self, driver):
return
@property
def search(self):
from search import SearchRegion
return SearchRegion(self.driver)
class InvalidPageException(Exception):
pass
Selenium WebDriver的高级特性-键盘与鼠标事件
"""
键盘与鼠标事件
WebDriver高级应用的API,允许我们模拟简单到
复杂的键盘和鼠标事件,如拖拽操作、快捷键组合、长
按以及鼠标右键操作。这些都是通过使用WebDriver的
Python API中ActionChains类实现的。
下表列出ActionChains类中一些关于键盘和鼠标事
件的重要方法。
click(on_element=None) 单击元素操作 on_element:指被单击的元素。如果该参数为None,将单击当前鼠标位置
click_and_hold(on_element=None) 对元素按住鼠标左键 on_element:指被单击且按住鼠标左键的元素。如果该参数为None,将单击当前鼠标位置
double_click(on_element=None) 双击元素操作 on_element:指被双击的元素。如果该参数为None,将双击当前鼠标位置
drag_and_drop(source, target) 鼠标拖动 source:鼠标拖动的源元素。 target:鼠标释放的目标元素
key_down(value, element=None) 仅按下某个键,而不释放。这个方法用于修饰键(如Ctrl、Alt与Shift键) key:指修饰键。Key的值在Keys类中定义。target:按键触发的目标元素,如果为None,则按键在当前鼠标聚焦的元素上触发
key_up(value, element=None) 用于释放修饰键 key:指修饰键。Key的值在Keys类中定义。target:按键触发的目标元素,如果为None,则按键在当前鼠标聚焦的元素上触发
move_by_offset(xoffset, yoffset) ——鼠标从当前位置移动到某个坐标
move_to_element(to_element) ——鼠标移动到某个元素
move_to_element_with_offset(to_element, xoffset, yoffset) ——移动到距某个元素(左上角坐标)多少距离的位置
perform() ——执行链中的所有动作
release(on_element=None) ——在某个元素位置松开鼠标左键
send_keys(*keys_to_send) ——发送某个键到当前焦点的元素
send_keys_to_element(element, *keys_to_send) ——发送某个键到指定元素
move_to_element(to_element) 将鼠标移动至指定元素的中央 to_element: 指定的元素
perform() 提交(重放)已保存的动作
release(on_element=None) 释放鼠标
send_keys(keys_to_send) 对当前焦点元素的键盘操作 keys_to_send:键盘的输入值
send_keys_to_element(element,keys_to_send) 对指定元素的键盘操作 element:指定的元素。keys_to_send:键盘的输入值
"""
"""
键盘事件
接下来我们创建一个测试脚本,用来模拟一个组合键的操作。在这个简单的场景中,
当我们按下Shift+N组合键时,label标签会改变颜色。代码如下。
"""
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions
# 引入的包
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
import unittest
ActionChains(driver).key_down(Keys.SHIFT).send_keys('n').key_up(Keys.SHIFT).perform()
"""
通过使用ActionChains类,我们可以实现组合键操作。在上面的示例中,我们联合key_down()、
send_key()与key_up()三个方法模拟真人操作Shift+N组合键。
当调用ActionChains类的方法时,它不会立即执行,而是会将所有的操作按顺序存放在一个队列里,
当调用perform()方法时,队列中的事件会依次执行。
"""
"""
鼠标事件
面演示一个调用ActionChains类中的
move_to_element()方法实现鼠标移动的示例。这个方法
类似于onMouseOver事件。move_to_element()方法是将
光标从当前位置移动到指定的元素。
"""
from selenium.webdriver.common.action_chains import ActionChains
age_field = driver.find_element_by_id("age")
ActionChains(self.driver).move_to_element(age_field).perform()
"""
双击操作
调用ActionChains类中的double_click()方法实现鼠标对元素的双击操作
"""
ActionChains(driver).move_to_element( driver.find_element_by_tag_name("span")).perform()
ActionChains(driver).double_click(box).perform()
"""
鼠标拖动
调用ActionChains类中的drag_and_drop()方法实现
鼠标的拖放操作。这个方法拖动源元素,然后在目标元
素的位置释放源元素。
"""
source = driver.find_element_by_id("draggable")
target = driver.find_element_by_id("droppable")
ActionChains(self.driver).drag_and_drop(source, target).perform()
Selenium WebDriver的高级特性-调用JavaScript
"""
在执行某些特殊操作或测试JavaScript代码时,
WebDriver还提供了调用JavaScript的方法。WebDriver
类包含的相关方法见下表。
execute_async_script(script,*args) 异步执行JS代码 script:被执行的JS代码。args:JS代码中的任意参数 driver.execute_async_script("returndocument.title")
execute_ script(script,*args) 同步执行JS代码 script:被执行的JS代码。args:JS代码中的任意参数 driver.execute_ script("returndocument.title")
"""
"""
接下来创建的测试用到了工具方法,该工具方法在
使用JavaScript方法对元素执行操作之前,先对它们进
行高亮显示。
"""
def test_search_by_category(self):
search_field = self.driver.find_element_by_name("q")
self.highlightElement(search_field)
search_field.clear()
self.highlightElement(search_field)
search_field.send_keys("phones")
search_field.submit()
products = self.driver.find_elements_by_xpath("//h2[@ class='product-name']/a")
# check count of products shown in results
self.assertEqual(2, len(products))
def highlightElement(self, element):
self.driver.execute_script("arguments[0].setAttribute('style',arguments[1]);",element, "color: green;border: 2px;solid green;")
self.driver.execute_script("arguments[0].setAttribute('style',arguments[1]);",element, "")
Selenium WebDriver的高级特性-屏幕截图
"""
自动测试执行过程中,在出错时捕获屏幕截图,是
我们在跟开发人员探讨错误时的重要依据。WebDriver
内置了一些在测试执行过程中捕获屏幕并保存的方法,
如下表所示。
save_ screenshot(filename) 获取当前屏幕截图并保存为指定文件 filename:指定保存的路径/图片文件名 Driver.save_ screenshot("homepage.png")
get_screenshot_as_base64() 获取当前屏幕截图base64编码字符串(用于HTML页面直接嵌入base64编码图片) driver.get_screenshot_as_base64()
get_screenshot_as_file(filename) 获取当前的屏幕截图,使用完整的路径。如果有任何IOError,返回False,否则返回True filename:指保存的路径/图片文件名
get_screenshot_as_png() 获取当前屏幕截图的二进制文件数据
"""
"""
接下来,我们通过屏幕截图来捕获一个测试执行出
错的场景。场景中,我们定位一个本来应该显示在主页
的元素。如果测试脚本没有发现对应元素,则立即抛出
NoSuchElement Exception异常,同时截取当前浏览器窗
口截图,我们可以把它作为bug的依据发给开发人员定
位问题。
"""
from selenium.common.exceptions import NoSuchElementException
def test_screen_shot(self):
driver = self.driver
try:
promo_banner_elem = driver.find_element_by_id("promo_ banner")
self.assertEqual("Promotions", promo_banner_elem.text)
except NoSuchElementException:
st = datetime.datetime.fromtimestamp(time.time()).strftime('%Ym%d_%H%M%S')
file_name = "main_page_missing_banner" + st + ".png"
driver.save_screenshot(file_name)
raise
"""
当我们使用上述截屏方法时,推荐使用包含唯一
标识(例如时间戳)的名称,并且保存为PNG图片等
高压缩图片格式,来控制图片的大小。
"""
Selenium WebDriver的高级特性-屏幕录制(有问题,待解决)
"""
屏幕录制
类似屏幕截图,屏幕录制能够更好地帮助我们记录
测试过程中到底发生了什么。录像材料可以作为提交问
题时的依据发送给项目相关人员,也可以作为产品的功
能演示。
然而,Selenium WebDriver没有内置录制的功能,
所以要依赖Python类库中名为Castro的工具。这是由
Selenium创始人Jason Huggin设计的。Castro是基于跨平
台屏幕录制工具Pyvnc2swf开发的。它使用VNC协议录
制屏幕并生成SWF视频文件。
由于符合VNC协议,所以我们还可以实现对远程
机器(预装VNC相关程序包)的屏幕录制。先安装
PyGame,然后安装Castro,pip命令如下。
pip install Castro
如果Server和Viewer端都是Windows的环境,我们
可以选择安装TightVNC工具。
"""
"""
如果在Ubuntu操作系统上,可以依次操作Settings |
Preference | Remote Desktop,然后选中Allow other
users to view your desktop复选框。在Mac上,我们可
以安装Vine VNC Server或者在System Preferences中打
开Remote Desktop。
"""
"""
添加屏幕录
制功能,代码如下
"""
import unittest
from selenium import webdriver
from castro import Castro
class SearchProductTest(unittest.TestCase):
def setUp(self):
self.screenCapture = Castro(filename="testSearchByCategory.swf")
self.screenCapture.start()
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(30)
self.driver.maximize_window()
self.driver.get("http://demo.magentocommerce.com/ ")
def test_search_by_category(self):
search_field = self.driver.find_element_by_name("q")
search_field.clear()
search_field.send_keys("phones")
search_field.submit()
products = self.driver.find_elements_by_xpath("//h2[@class='product-name']/a")
self.assertEqual(2, len(products))
def tearDown(self):
self.driver.quit()
self.screenCapture.stop()
if __name__ == '__main__':
unittest.main(verbosity=2)
Selenium WebDriver的高级特性-弹出窗处理
"""
弹出窗的处理
弹出窗的处理过程包括:通过弹出窗的名称或句柄
来定位,切换Driver Context至所需的弹出窗,在弹出
窗上执行相关操作步骤,最后跳转回到上级窗口(页
面)。
结合我们的测试,创建一个基于浏览器的实例,基
于父窗口随后弹出新的窗口,我们统称为子窗口或弹出
窗。只要该弹出窗属于当前WebDriver Context,我们都
可以对它进行操作。
下图展示一个弹出窗的例子。
创建一个新的测试类PopupWindowTest,其中包
括test_popup_window()方法,代码如下
"""
def test_popup_window(self):
driver = self.driver
parent_window_id = driver.current_window_handle
help_button = driver.find_element_by_id("helpbutton")
help_button.click()
driver.switch_to.window("HelpWindow")
driver.close()
driver.switch_to.window(parent_window_id)
"""
在Context调用弹出窗口显示之前,我们先通过
current_window_handle属性将父窗口的句柄信息保存下
来(稍后我们将使用这个信息从弹出窗返回到父窗
口)。接着使用WebDriver下的switch_to.window()方法
获取弹出窗的名称或句柄信息,切换到我们要操作的那
个弹出窗(子窗口)。下面我们演示通过名称定
我们操作完Help窗口之后,通过close()方法关闭窗口,并且返回至父窗口
"""
Selenium WebDriver的高级特性-操作cookie
"""
了更好的用户体验,cookies作为Web应用一项很
重要的手段,将一些诸如用户偏好、登录信息以及各种
客户端细节信息,记录并保存在用户计算机本地。
WebDriver提供了一组操作cookies的方法,包括读取、
添加和删除cookies信息。这些方法可以帮助我们操作
cookies,来校验Web应用程序对应的响应。具体方法见
下表。
add_cookie(cookie_dict) 在当前会话中添加cookie信息 cookie_ dict:字典对象,包含name与value值 driver.add_cookie({"foo","bar"}) 用双引号
delete_all_cookies() 在当前会话中删除所有cookie信息 driver.delete_all_cookies()
delete_cookie(name) 删除单个名为name的cookie信息 name:要删除的cookie的名称 driver.delete_cookie("foo")
get_cookie(name) 返回单个名为name的cookie信息。如果没有找到,返回none name:要查找的cookie的名称 driver.get_ cookie("foo")
get_cookies() 返回当前会话所有的cookie信息 driver.get_cookies()
"""
from selenium.webdriver.support.ui import Select
def test_store_cookie(self):
driver = self.driver
select_language = Select(self.driver.find_element_by_id("select-language"))
self.assertEqual("ENGLISH", select_language.first_selected_option.text)
store_cookie = driver.get_cookie("store")
self.assertEqual(None, store_cookie)
select_language.select_by_visible_text("French")
store_cookie = driver.get_cookie("store")['value']
self.assertEqual("french", store_cookie)
"""
上述代码中,我们传递一个cookie的名称,就可以
通过get_cookie()方法获取到对应cookie的值。
"""
移动端测试
adb 的使用
更多信息:https://www.jianshu.com/p/65e80c60f656
更多信息:https://blog.csdn.net/zhonglunshun/article/details/78362439?utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2allsobaiduend~default-1-78362439.nonecase&utm_term=adb%E8%8E%B7%E5%8F%96%E7%95%8C%E9%9D%A2%E6%96%87%E6%9C%AC&spm=1000.2123.3001.4430
- 首先,查看安卓手机是否已经连接上电脑(这是由电脑自动获取的,获取在adb devices 获取不了后才需要人公获取)
adb devices
- 让adb一直查找安卓设备,找到后才停止
adb wait-for-device
- 连接到夜神模拟器
进行adb连接操作,以下两种操作均可:
进入夜神目录下bin文件夹,运行CMD,输入:
nox_adb.exe connect 127.0.0.1:62026
即可以连接到adb
直接win+R,打开CMD,输入:
adb connect 127.0.0.1:62026
即可连接到adb
注:此处需要注意,端口号不能弄错
- 获取包名
adb shell pm list package
- 获取所在地址
adb shell pm list package -f
- 获取Activity类名
aapt dump badging "C:\Users\hanson\Desktop\120_4a01f4ccc6d932a7743fc51ce2adb493.apk"

- 启动应用
adb shell am start -n com.UCMobile/com.UCMobile.main.UCMobile
- 模拟鼠标操作
adb shell input mouse tap 100 500
100是x,500是y。
原点在屏幕左上角。