无论是XGBoost还是其他的Boosting Tree,使用的Tree都是cart回归树,这也就意味着该类提升树算法只接受数值特征输入,不直接支持类别特征,默认情况下,xgboost会把类别型的特征当成数值型。事实上,对于类别特征的处理,参考XGBoost PPT如下:

xgboost 树模型其实是不建议使用one-hot编码,在xgboost上面的 issue 也提到过,相关的说明如下
I do not know what you mean by vector. xgboost treat every input feature as numerical, with support for missing values and sparsity. The decision is at the user So if you want ordered variables, you can transform the variables into numerical levels(say age). Or if you prefer treat it as categorical variable, do one hot encoding.
在另一个issues上也提到过(tqchen commented on 8 May 2015):
One-hot encoding could be helpful when the number of categories are small( in level of 10 to 100). In such case one-hot encoding can discover interesting interactions like (gender=male) AND (job = teacher). While ordering them makes it harder to be discovered(need two split on job). However, indeed there is not a unified way handling categorical features in trees, and usually what tree was really good at was ordered continuous features anyway..
总结起来的结论,大至两条:
- 对于类别有序的类别型变量,比如 age 等,当成数值型变量处理可以的。对于非类别有序的类别型变量,推荐 one-hot。但是 one-hot 会增加内存开销以及训练时间开销。
- 类别型变量在范围较小时(tqchen 给出的是[10,100]范围内)推荐使用
Label encoding与 One-Hot encoding
xgboost是不支持category特征的,在训练模型之前,需要我们进行预处理,可以根据特征的具体形式来选择:
- 无序特征:one-hot encoding,比如城市
- 有序特征:label encoding,比如版本号
Label encoding
Label encoding是使用字典的方式,将每个类别标签与不断增加的整数相关联,即生成一个名为class_的实例数组的索引。
from sklearn.preprocessing import LabelEncoder le = LabelEncoder() city_list = ["paris", "paris", "tokyo", "amsterdam"] le.fit(city_list) print(le.classes_) # 输出为:['amsterdam' 'paris' 'tokyo'] city_list_le = le.transform(city_list) # 进行Encode print(city_list_le) # 输出为:[1 1 2 0] city_list_new = le.inverse_transform(city_list_le) # 进行decode print(city_list_new) # 输出为:['paris' 'paris' 'tokyo' 'amsterdam']
如果是多列数据如何进行方便的编码。
方案一:
from sklearn.preprocessing import LabelEncoder
from collections import defaultdict
import pandas as pd
d = defaultdict(LabelEncoder)
df = pd.DataFrame({
'pets': ['cat', 'dog', 'cat', 'monkey', 'dog', 'dog'],
'owner': ['Champ', 'Ron', 'Brick', 'Champ', 'Veronica', 'Ron'],
'location': ['San_Diego', 'New_York', 'New_York', 'San_Diego', 'San_Diego',
'New_York']
})
# Encoding the variable
fit = df.apply(lambda x: d[x.name].fit_transform(x))
# Inverse the encoded
fit.apply(lambda x: d[x.name].inverse_transform(x))
# Using the dictionary to label future data
df.apply(lambda x: d[x.name].transform(x))
方案2:
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.pipeline import Pipeline
# Create some toy data in a Pandas dataframe
fruit_data = pd.DataFrame({
'fruit': ['apple','orange','pear','orange'],
'color': ['red','orange','green','green'],
'weight': [5,6,3,4]
})
class MultiColumnLabelEncoder:
def __init__(self,columns = None):
self.columns = columns # array of column names to encode
def fit(self,X,y=None):
return self # not relevant here
def transform(self,X):
'''
Transforms columns of X specified in self.columns using
LabelEncoder(). If no columns specified, transforms all
columns in X.
'''
output = X.copy()
if self.columns is not None:
for col in self.columns:
output[col] = LabelEncoder().fit_transform(output[col])
else:
for colname,col in output.iteritems():
output[colname] = LabelEncoder().fit_transform(col)
return output
def fit_transform(self,X,y=None):
return self.fit(X,y).transform(X)
参考链接: https://stackoverflow.com/questions/24458645/label-encoding-across-multiple-columns-in-scikit-learn
LabelBinarizer
这种方法很简单,在许多情况下效果很好,但他有一个缺点:所有的标签都变成了数字,然后算法模型直接将根据其距离来考虑相似的数字,而不考虑标签的具体含义。因此,通常优选独热编码(one-hot encoding)将数据二进制化。
from sklearn.preprocessing import LabelBinarizer lb = LabelBinarizer() city_list = ["paris", "paris", "tokyo", "amsterdam"] lb.fit(city_list) print(lb.classes_) # 输出为:['amsterdam' 'paris' 'tokyo'] city_list_le = lb.transform(city_list) # 进行Encode print(city_list_le) # 输出为: # [[0 1 0] # [0 1 0] # [0 0 1] # [1 0 0]] city_list_new = lb.inverse_transform(city_list_le) # 进行decode print(city_list_new) # 输出为:['paris' 'paris' 'tokyo' 'amsterdam']
DictVectorizer
当类别的特征被构造成类似于字典的列表时,列表中的值仅仅需要时几个特征的值而不需要很密集,此时可采用另一种分类方法。DictVectorizer可以用于将各列使用标准的Python dict对象表示的特征数组,转换成sklearn中的estimators可用的NumPy/SciPy表示的对象。Python的dict的优点是,很方便使用,稀疏,可以存储feature名和值。DictVectorizer实现了一个称为one-of-K或者”one-hot”编码的类别特征。类别特征是“属性-值”对,它的值严格对应于一列无序的离散概率(比如:topic id, 对象类型,tags, names…)
下例中,”city”是类别的属性,而”temperature”是一个传统的数值型feature:
from sklearn.feature_extraction import DictVectorizer
measurements = [
{'city': 'Dubai', 'temperature': 33.},
{'city': 'London', 'temperature': 12.},
{'city': 'San Fransisco', 'temperature': 18.},
]
vec = DictVectorizer()
measurements_vec = vec.fit_transform(measurements)
print(measurements_vec)
# 输出内容:
# (0, 0) 1.0
# (0, 3) 33.0
# (1, 1) 1.0
# (1, 3) 12.0
# (2, 2) 1.0
# (2, 3) 18.0
print(measurements_vec.toarray())
# 输出内容
# [[ 1. 0. 0. 33.]
# [ 0. 1. 0. 12.]
# [ 0. 0. 1. 18.]]
feature_names = vec.get_feature_names()
print(feature_names) # 输出:['city=Dubai', 'city=London', 'city=San Fransisco', 'temperature']
FeatureHasher
一般的vectorizer是为训练过程中遇到的特征构建一个hash table,而FeatureHasher类则直接对特征应用一个hash函数来决定特征在样本矩阵中的列索引。这样的做法使得计算速度提升并且节省了内存,the hasher无法记住输入特征的样子,而且不逊在你想变换操作:inverse_transform。
因为哈希函数可能会导致本来不相关的特征之间发生冲突,所以使用了有符号的hash函数。对一个特征,其hash值的符号决定了被存储到输出矩阵中的值的符号。通过这种方式就能够消除特征hash映射时发生的冲突而不是累计冲突。而且任意输出的值的期望均值是0。sklearn中的FeatureHasher使用了MurmurHash 3作为其Hash算法。
FeatureHasher的输出通常是CSR格式的scipy.sparse matrix。Feature hashing 可被用于文档分类中去,但是与text.CountVectorizer不同,FeatureHasher不做单词切分或其他的预处理操作,除了Unicode-to-UTF-8编码以外。
one-hot encoding
什么是one-hot encoding
在实际的机器学习的应用任务中,特征有时候并不总是连续值,有可能是一些分类值,如性别可分为“male”和“female”。在机器学习任务中,对于这样的特征,通常我们需要对其进行特征数字化,比如有如下三个特征属性:
- 性别:[“male”,”female”]
- 地区:[“Europe”,”US”,”Asia”]
- 浏览器:[“Firefox”,”Chrome”,”Safari”,”Internet Explorer”]
对于某一个样本,如[“male”,”US”,”Internet Explorer”],我们需要将这个分类值的特征数字化,最直接的方法,我们可以采用序列化的方式:[0,1,3]。但是,即使转化为数字表示后,上述数据也不能直接用在我们的分类器中。因为,分类器往往默认数据是连续的,并且是有序的。按照上述的表示,数字并不是有序的,而是随机分配的。这样的特征处理并不能直接放入机器学习算法中。
为了解决上述问题,其中一种可能的解决方法是采用独热编码(One-Hot Encoding)。独热编码,又称为一位有效编码。其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候,其中只有一位有效。可以这样理解,对于每一个特征,如果它有m个可能值,那么经过独热编码后,就变成了m个二元特征。并且,这些特征互斥,每次只有一个激活。因此,数据会变成稀疏的。
对于上述的问题,性别的属性是二维的,同理,地区是三维的,浏览器则是四维的,这样,我们可以采用One-Hot编码的方式对上述的样本“[“male”,”US”,”Internet Explorer”]”编码,“male”则对应着[1,0],同理“US”对应着[0,1,0],“Internet Explorer”对应着[0,0,0,1]。则完整的特征数字化的结果为:[1,0,0,1,0,0,0,0,1]。
为什么能使用One-Hot Encoding?
- 使用one-hot编码,将离散特征的取值扩展到了欧式空间,离散特征的某个取值就对应欧式空间的某个点。在回归,分类,聚类等机器学习算法中,特征之间距离的计算或相似度的计算是非常重要的,而我们常用的距离或相似度的计算都是在欧式空间的相似度计算,计算余弦相似性,也是基于的欧式空间。
- 将离散型特征使用one-hot编码,可以会让特征之间的距离计算更加合理。比如,有一个离散型特征,代表工作类型,该离散型特征,共有三个取值,不使用one-hot编码,计算出来的特征的距离是不合理。那如果使用one-hot编码,显得更合理。
独热编码优缺点
- 优点:独热编码解决了分类器不好处理属性数据的问题,在一定程度上也起到了扩充特征的作用。它的值只有0和1,不同的类型存储在垂直的空间。
- 缺点:当类别的数量很多时,特征空间会变得非常大。在这种情况下,一般可以用PCA(主成分分析)来减少维度。而且One-Hot Encoding+PCA这种组合在实际中也非常有用。
One-Hot Encoding的使用场景
- 独热编码用来解决类别型数据的离散值问题。将离散型特征进行one-hot编码的作用,是为了让距离计算更合理,但如果特征是离散的,并且不用one-hot编码就可以很合理的计算出距离,那么就没必要进行one-hot编码,比如,该离散特征共有1000个取值,我们分成两组,分别是400和600,两个小组之间的距离有合适的定义,组内的距离也有合适的定义,那就没必要用one-hot 编码。
- 基于树的方法是不需要进行特征的归一化,例如随机森林,bagging 和 boosting等。对于决策树来说,one-hot的本质是增加树的深度,决策树是没有特征大小的概念的,只有特征处于他分布的哪一部分的概念。
One-Hot使用示例
1、基于sklearn 的one hot encoding:
import pandas as pd from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import OneHotEncoder df = pd.DataFrame([ ['green', 'Chevrolet', 2017], ['blue', 'BMW', 2015], ['yellow', 'Lexus', 2018], ]) df.columns = ['color', 'make', 'year'] le_color = LabelEncoder() le_make = LabelEncoder() df['color_encoded'] = le_color.fit_transform(df.color) df['make_encoded'] = le_make.fit_transform(df.make) color_ohe = OneHotEncoder() make_ohe = OneHotEncoder() X = color_ohe.fit_transform(df.color_encoded.values.reshape(-1, 1)).toarray() Xm = make_ohe.fit_transform(df.make_encoded.values.reshape(-1, 1)).toarray() dfOneHot = pd.DataFrame(X, columns=["Color_" + str(int(i)) for i in range(X.shape[1])]) df = pd.concat([df, dfOneHot], axis=1) dfOneHot = pd.DataFrame(Xm, columns=["Make" + str(int(i)) for i in range(X.shape[1])]) df = pd.concat([df, dfOneHot], axis=1)

参考链接: http://www.insightsbot.com/blog/McTKK/python-one-hot-encoding-with-scikit-learn
2、基于pandas的one hot encoding:
其实如果我们跳出 scikit-learn, 在 pandas 中可以很好地解决这个问题,用 pandas 自带的get_dummies函数即可
import pandas as pd df = pd.DataFrame([ ['green', 'Chevrolet', 2017], ['blue', 'BMW', 2015], ['yellow', 'Lexus', 2018], ]) df.columns = ['color', 'make', 'year'] df_processed = pd.get_dummies(df, prefix_sep="_", columns=df.columns[:-1]) print(df_processed)
get_dummies的优势在于:
- 本身就是 pandas 的模块,所以对 DataFrame 类型兼容很好
- 不管你列是数值型还是字符串型,都可以进行二值化编码
- 能够根据指令,自动生成二值化编码后的变量名
get_dummies虽然有这么多优点,但毕竟不是 sklearn 里的transformer类型,所以得到的结果得手动输入到 sklearn 里的相应模块,也无法像 sklearn 的transformer一样可以输入到pipeline中进行流程化地机器学习过程。
参考链接: https://blog.cambridgespark.com/robust-one-hot-encoding-in-python-3e29bfcec77e
利用神经网络的Embedding层处理类别特征
Embedding简介
Embedding的起源和火爆都是在NLP中的,经典的word2vec都是在做word embedding这件事情,而真正首先在结构数据探索embedding的是在kaggle上的《Rossmann Store Sales》中的rank 3的解决方案,作者在比赛完后为此方法整理一篇论文放在了arXiv,文章名:《 Entity Embeddings of Categorical Variables 》。
Embedding也被称为嵌套,是将大型稀疏矢量映射到一个保留语义关系的低维空间。在此模块的随后几个部分中,我们将从直观角度、概念角度和编程角度来详细探讨嵌套。
要解决稀疏输入数据的核心问题,您可以将高维度数据映射到低维度空间。即便是小型多维空间,也能自由地将语义上相似的项归到一起,并将相异项分开。矢量空间中的位置(距离和方向)可对良好的嵌套中的语义进行编码。例如,下面的真实嵌套可视化图所展示的几何关系图捕获了国家与其首都之间的语义关系。
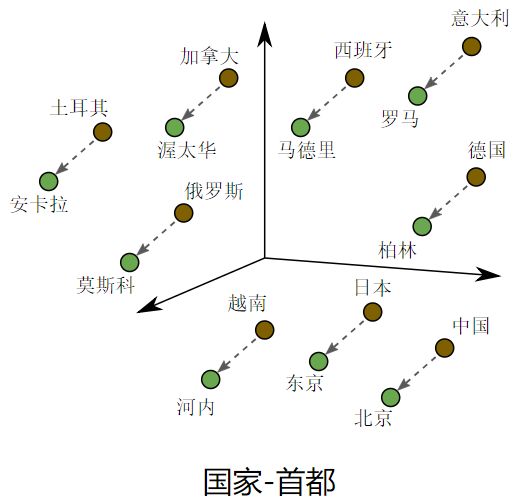
嵌套充当查询表
嵌套是一个矩阵,每列表示您词汇中的一项所对应的矢量。要获得某个词汇项的密集矢量,您可以检索该项所对应的列。但是,如何转换字词矢量的稀疏包呢?要获得表示多个词汇项(例如,一句或一段中的所有字词)的稀疏矢量的密集矢量,您可以检索各项的嵌套,然后将它们相加。如果稀疏矢量包含词汇项的计数,则您可以将每项嵌套与其对应项的计数相乘,然后再求和。这些运算可能看起来很眼熟吧。
嵌套查询充当矩阵乘法
我们刚刚阐述的查询、乘法和加法程序等效于矩阵乘法。假设有一个的稀疏表示 S 和一个的嵌套表 E,矩阵乘法可以得出密集矢量。这个概念用神经网络图来表示如下:
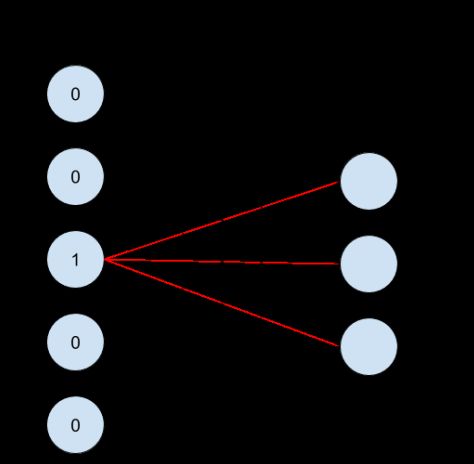
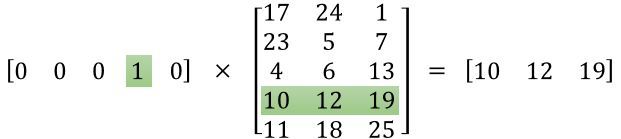
但首要问题是,如何获取 E 呢?我们将在下一部分介绍如何获取嵌套。
Network Embedding,即将网络节点、community投影到低维向量空间,用于node classification、link prediction、community detection、visualization等任务。
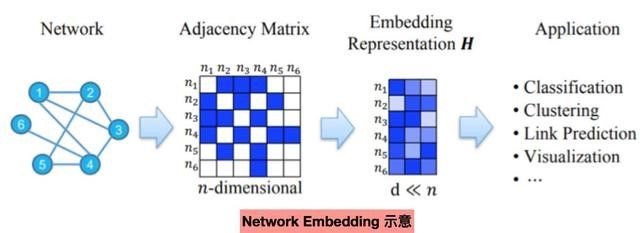
核心假设:节点间距离越近,embedding向量越接近,定义LOSS为:
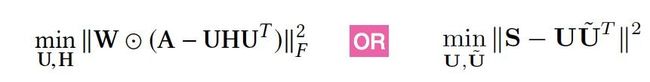
Network Embedding算法分类
基于矩阵特征向量计算(谱聚类)
目标是将相似性高的两个节点,映射到低维空间后依然保持距离相近,其损失函数定义为:

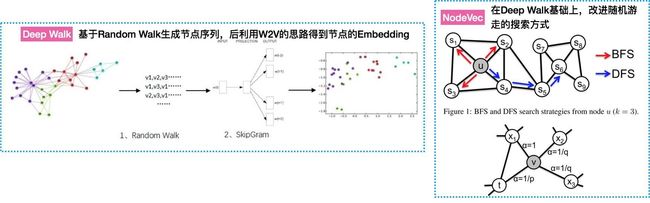
基于random walk框架计算(Deep Walk & Node2Vec)
基于Deep Learning框架计算 SDNE(Structural Deep Network Embeddings)
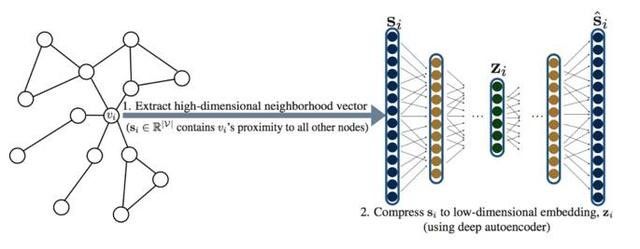
主要思想:将节点的相似性向量直接作为模型的输入,通过 Auto-encoder 对这个向量进行降维压缩,得到其向量化后的结果 $Z_i#。其损失函数定义为:
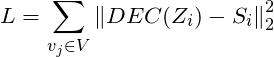
模型框架为:
GCN(Graph Convolutional Networks)
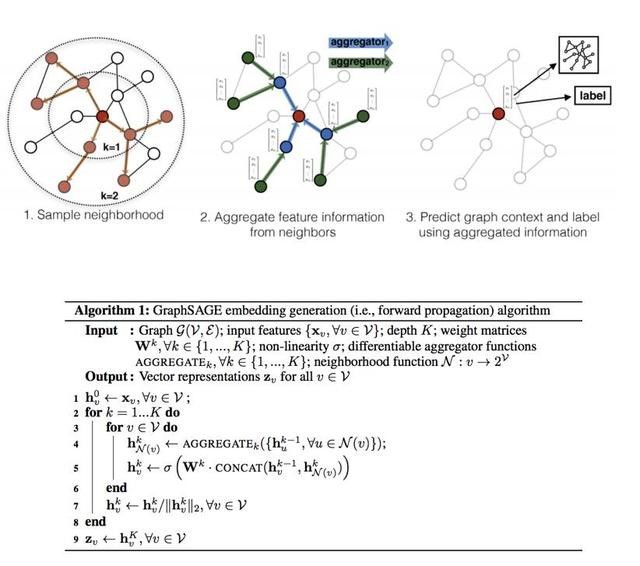
主要思想:将节点本身及其邻居节点的属性(比如文本信息)或特征(比如统计信息)编码进向量中,引入了更多特征信息,并且在邻居节点间共享了一些特征或参数,基于最终的目标(如节点分类)做整体优化。
模型框架示意和计算流程:
更多参考:
- https://yq.aliyun.com/articles/294450
- https://blog.csdn.net/dark_scope/article/details/74279582
Embedding实战
使用Keras进行Embedding
Keras对Tensorflow又进行了一层封装,操作简单,功能强大。
# 构造输入数据
# 输入数据是320*6,320个样本,6个类别特征,且类别特征的可能值是0到36之间(37个)。
# 对这6个特征做one-hot的话,应该为37*6,
# embedding就是使1个特征原本应该one-hot的37维变为3维(手动设定,也可以是其它),因为有36个类别特征
# 这样输出的结果就应该是3*6
# 参考链接:https://keras.io/zh/layers/embeddings/
# 建议降维的维度为 math.ceil(category_count ** 0.25)
import numpy as np
np.random.seed(42)
input_array = np.random.randint(37, size=(320, 6))
print(input_array)
import tensorflow as tf
from keras import backend as K
from keras.models import Sequential
from keras.layers.embeddings import Embedding
with tf.Session() as sess:
K.set_session(sess)
model = Sequential()
model.add(Embedding(37, 3, input_length=6))
model.compile('rmsprop', 'mse')
output_array = model.predict(input_array)
print(output_array)
# weight = model.get_weights()
# print(weight)
在上述的代码中,我们可以看到6个类别特征的值都在0到37,并且我们没有对模型进行训练,而是直接就搭建了一个网络,就输出结果了。在真实的应用中,不是这样。有2点需要改进:
- 对每一个类别特征构建一个embedding层。对embedding层进行拼接。
- 训练网络,得到训练后的embedding层的输出作为类别特征one-hot的替换,这样的embedding的输出更精确
为了解决上述的2个问题,我们这里还是人工构建训练集,我们搭建的模型如图:
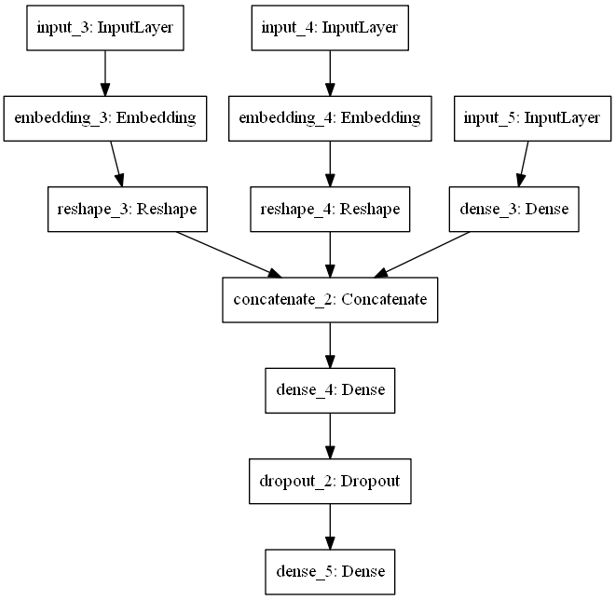
从模型中,我们可以看到,这是符合现实世界的数据集的:即既有分类特征,又有连续特征。我们先训练一个网络,embedding_3和embedding_4层的输出结果就是用embedding处理类别特征后的结果。
import numpy as np
import tensorflow as tf
from keras.models import Model
from keras.layers import Input, Dense, Concatenate, Reshape, Dropout
from keras.layers.embeddings import Embedding
from keras import backend as K
from keras.utils import plot_model
session_conf = tf.ConfigProto(intra_op_parallelism_threads=1, inter_op_parallelism_threads=1)
sess = tf.Session(graph=tf.get_default_graph(), config=session_conf)
K.set_session(sess)
def build_embedding_network():
"""
以网络结构embeddding层在前,dense层在后。即训练集的X必须以分类特征在前,连续特征在后。
"""
inputs = []
embeddings = []
input_cate_feature_1 = Input(shape=(1,))
embedding = Embedding(10, 3, input_length=1)(input_cate_feature_1)
embedding = Reshape(target_shape=(3,))(embedding) # embedding后是10*1*3,为了后续计算方便,因此使用Reshape转为10*3
inputs.append(input_cate_feature_1)
embeddings.append(embedding)
input_cate_feature_2 = Input(shape=(1,))
embedding = Embedding(4, 2, input_length=1)(input_cate_feature_2)
embedding = Reshape(target_shape=(2,))(embedding)
inputs.append(input_cate_feature_2)
embeddings.append(embedding)
input_numeric = Input(shape=(1,))
embedding_numeric = Dense(16)(input_numeric)
inputs.append(input_numeric)
embeddings.append(embedding_numeric)
x = Concatenate()(embeddings)
x = Dense(10, activation='relu')(x)
x = Dropout(.15)(x)
output = Dense(1, activation='sigmoid')(x)
model = Model(inputs, output)
model.compile(loss='binary_crossentropy', optimizer='adam')
return model
"""
构造训练数据
输入数据是320*3,320个样本,2个类别特征,1个连续特征。
对类别特征做entity embedding,第一个类别特征10个,第二个类别特征4个。对这2个特征做one-hot的话,应该为10+4,
对第一个类别特征做embedding使其为3维,对第二个类别特征做embedding使其为2维。3对连续特征不做处理。这样理想输出的结果就应该是3+2+1。
维和2维的设定是根据实验效果和交叉验证设定。
"""
sample_num = 320 # 样本数为32
cate_feature_num = 2 # 类别特征为2
contious_feature_num = 1 # 连续特征为1
rng = np.random.RandomState(0) # 保证了训练集的复现
cate_feature_1 = rng.randint(10, size=(sample_num, 1))
cate_feature_2 = rng.randint(4, size=(sample_num, 1))
contious_feature = rng.rand(sample_num, 1)
X = [cate_feature_1, cate_feature_2, contious_feature]
Y = np.random.randint(2, size=(sample_num, 1)) # 二分类
cate_embedding_dimension = {'0': 3, '1': 2} # 记录类别特征embedding后的维度。key为类别特征索引,value为embedding后的维度
"""
训练和预测
"""
NN = build_embedding_network()
plot_model(NN, to_file='NN.png') # 画出模型,需要GraphViz包。另外需要安装 pip install pydot
NN.fit(X, Y, epochs=3, batch_size=4, verbose=0)
y_preds = NN.predict(X)[:, 0]
"""
读embedding层的输出结果
"""
model = NN # 创建原始模型
for i in range(cate_feature_num):
layer_name = NN.get_config()['layers'][cate_feature_num + i]['name'] # cate_feature_num+i就是所有embedding层
intermediate_layer_model = Model(inputs=NN.input, outputs=model.get_layer(layer_name).output)
intermediate_output = intermediate_layer_model.predict(X)
intermediate_output.resize([sample_num, cate_embedding_dimension[str(i)]])
if i == 0:
X_embedding_trans = intermediate_output
else:
X_embedding_trans = np.hstack((X_embedding_trans, intermediate_output)) # 水平拼接
for i in range(contious_feature_num):
if i == 0:
X_contious = X[cate_feature_num + i]
else:
X_contious = np.hstack((X_contious, X[cate_feature_num + i]))
X_trans = np.hstack((X_embedding_trans, X_contious)) # 在类别特征做embedding后的基础上,拼接连续特征,形成最终矩阵,也就是其它学习器的输入。
print(X_trans[:5]) # 其中,类别特征维度为5(前5个),连续特征维度为1(最后1个)
weight = NN.trainable_weights[0].eval(session=sess) # embedding_1层的参数。
print(weight[:5])
参考链接: https://blog.csdn.net/h4565445654/article/details/78998444