课程学习:让神经机器翻译模型像人类一样学习
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
近些年来,神经机器翻译得到了迅速发展,在特定翻译场景下甚至可以媲美人类翻译的水平。但是,在难以收集双语数据的语言方向和专业领域的情况下,神经机器翻译模型面临着低资源问题,模型难以达到良好的性能。目前解决低资源问题的常用方法如预训练、迁移学习和数据增强,都比较依赖辅助数据。而在面临低资源问题时,辅助数据依然是较难获取的。人类在学习时所需的数据远少于神经机器翻译模型,那么神经机器翻译是否可以像人类一样学习?课程学习就是模仿人类的学习策略,有组织地利用有限的训练数据,从而达到更高的模型性能。

许晨:东北大学自然语言处理实验室博士二年级学生,导师是朱靖波教授和肖桐教授。研究方向主要包括低资源机器翻译、语音翻译。

一、背景介绍
1.1 机器翻译
机器翻译是利用计算机将句子从一种语言自动翻译为另外一种语言的技术。随着深度学习技术的发展,机器翻译模型也在不断改进。从一开始的基于循环神经网络的模型发展到基于卷积神经网络的模型,再到目前比较火热的基于自注意力机制的机器翻译模型,机器翻译模型的能力已经有了非常大的提升。

图1:机器翻译的发展
在特定的语言方向和数据集上,机器翻译甚至可以达到人类翻译水平,在诸多场景下都发挥了巨大的作用。

图2:机器翻译的应用场景
1.2 低资源问题
但目前神经机器翻译模型的性能与双语数据的数据量十分相关,这导致在无法获取充分数据量的情况下,神经机器翻译模型无法达到理想水平。
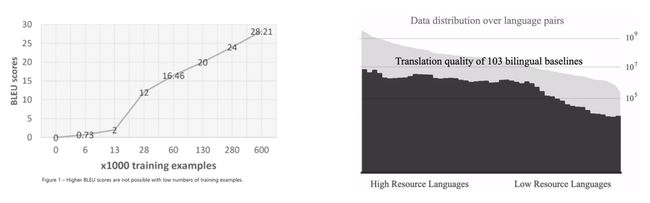
图3:数据量与模型性能的关系
除了一些常用的语言,如汉语、英语和西班牙语等,世界上大多数语言的使用人数都是非常少的。这些语言对应的翻译数据也就难以获取,导致了严重的低资源问题。
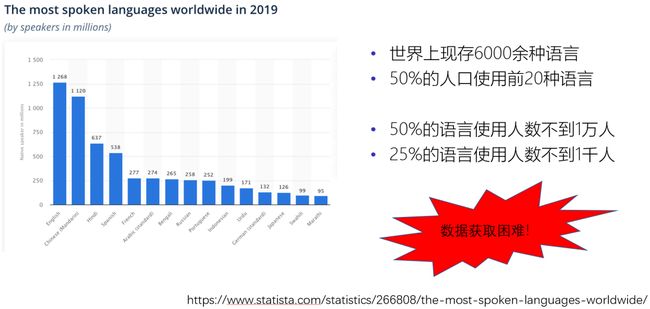
图4:各个语言的使用人数
低资源问题不仅仅会出现在小语种翻译上,在一些非小语种的专业领域翻译中也会出现。比如在中英翻译中,医学、化学等领域的双语数据也是相对难以获取的。

图5:富资源领域与低资源领域
1.3 目前的低资源翻译方法
目前解决低资源问题的常用方法包括预训练、迁移学习和数据增强等。其中,预训练和迁移学习的核心思想是通过辅助数据来预先训练模型的一部分参数,再使用这些参数初始化目标翻译模型(图6左边所示)。数据增强则是通过辅助数据生成一些伪双语数据来增加训练数据的规模(图6右边所示)。

图6:目前解决低资源问题的方法
然而,上述方法过度地依赖辅助数据。预训练通常需要大量的单语数据,迁移学习需要和目标语言对比较相似的训练数据,数据增强也同样需要大量的单语数据。对于低资源语言来说,这些辅助数据通常也是难以获取的。那么,我们是否可以在不使用辅助数据的前提下,通过更高效地利用有限的双语数据,来获得更好的神经机器翻译模型呢?
二、动态课程学习方法
人类在学习过程中,仅利用少量的数据就可以学习到很好的水平。受到人类学习策略的启发,我们使用课程学习方法来解决低资源问题。
2.1 课程学习
课程学习受人类的学习策略启发,是一种从易到难的学习方式。比如,人类在学习翻译的过程中,一般会从简单的单词翻译开始学习,然后再学习一些短语翻译和简单句子翻译,最后学习一些困难的长句翻译。通过这种循序渐进的方式,我们可以学习地更快更好。

图7:循序渐进的学习方式
2.2 神经机器翻译中的课程学习
课程学习将神经机器翻译模型的训练过程分成多个阶段,每个阶段都使用不同难度的训练数据来训练模型。
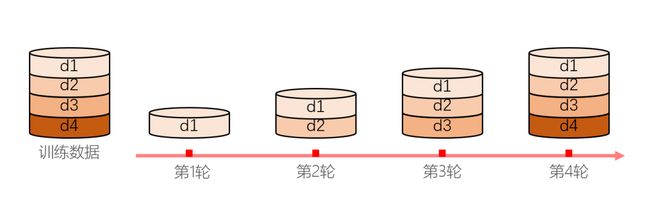
图8:神经机器翻译中的课程学习
在每个阶段,模型的训练目标是通过当前的训练数据优化神经机器翻译模型的负对数似然。

图9:神经机器翻译的训练目标
那么课程学习如何选择每个阶段的训练数据呢?一般是基于两个准则,分别是样本难度和模型能力。我们定量地衡量每个样本的难度值,然后基于当前模型的能力,来选择一定比例的简单样本进行训练。
在之前的工作中,样本难度可以通过句子长度或单词词频来衡量。一个句子越长或者包含的单词词频越低,那么这个句子的样本难度就越高。对于模型能力,则是假设它的提升过程符合简单的线性函数或平方根函数。

图10:每阶段训练样本的选择与模型能力的关系
基于以上方法,可以看出,样本难度在训练过程中不会发生变化,所以只需要在训练开始之前计算一次。这种方法被称为静态课程学习,好处在于比较方便,计算代价较小,但是存在两个主要问题:
简单的准则无法准确衡量样本对于模型的难度。使用词频或句长来衡量难度的方式,对于人类来说比较直观,但对于模型来说却不一定适用。
模型训练过程是一个动态过程,样本难度和模型能力都随着训练阶段变化而变化。
2.3 动态课程学习
为了解决以上两个问题,我们提出了动态课程学习,模型在每个阶段都要根据当前状态重新衡量样本难度。
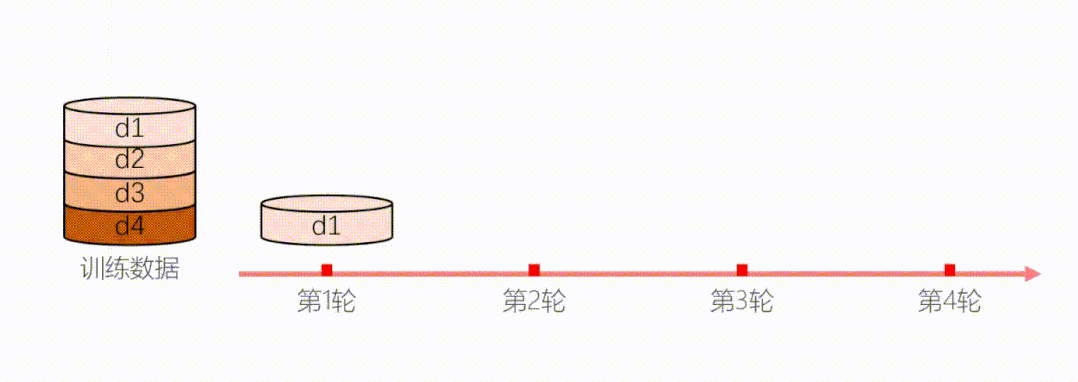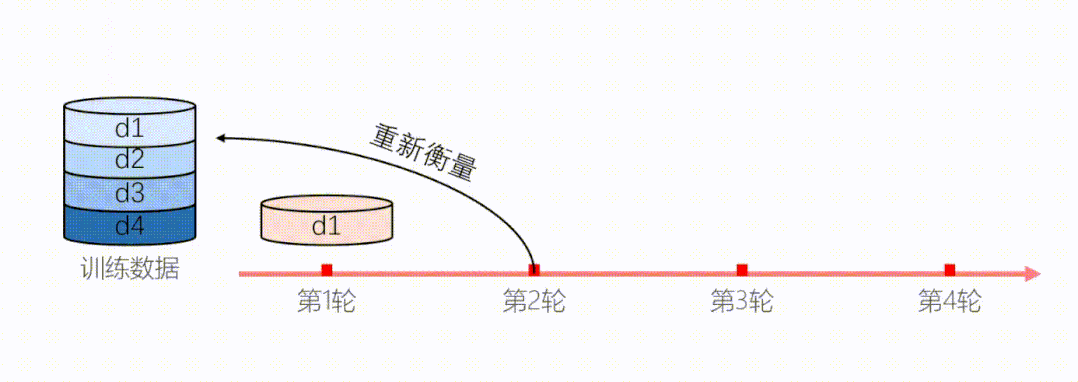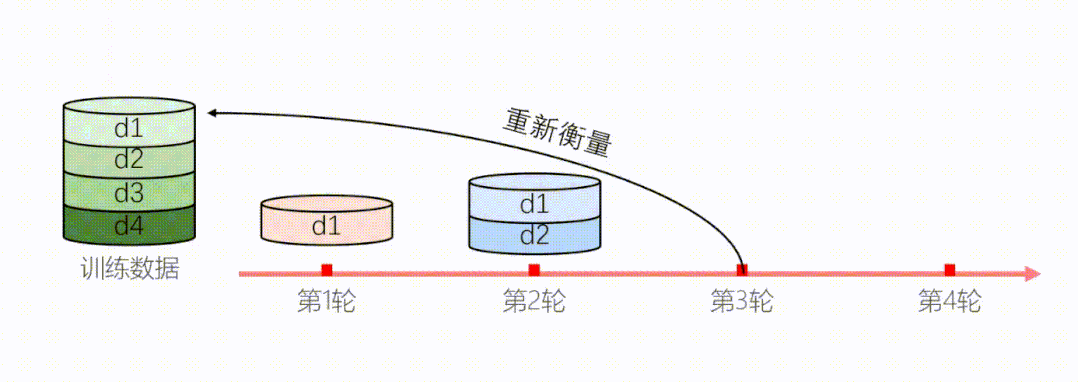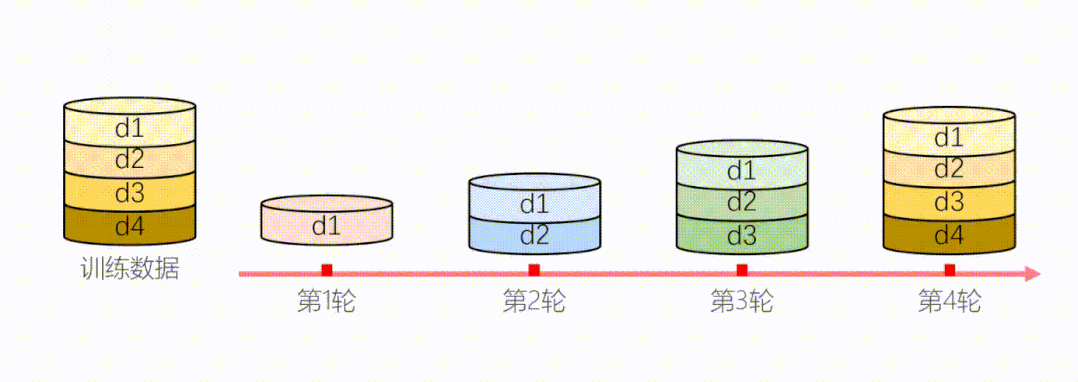
图11:动态衡量模型难度
我们希望样本难度的计算方法满足以下两个条件:
和模型训练相关。
在训练过程中动态计算。
之前提到,每个阶段的训练目标是优化模型在训练数据上的负对数似然。那么是否可以直接使用负对数似然(预测损失)来衡量样本难度?
虽然这种衡量方法是模型相关的,但是存在着一个问题,即预测损失只考虑到模型当前阶段的绝对值。如果存在某个样本在初始阶段时的预测损失就比较大,那么这个样本可能一直得不到训练。而对于预测损失比较小的样本,则没有进一步的下降空间。如果一直重复训练预测损失较小的样本,容易造成模型过拟合。

图12:预测损失
为了避免以上问题,我们认为样本的选择需要同时考虑历史训练过程和模型当前的状态,以此选择能够使模型在未来表现得更好的数据。为了满足上面提出的需要,我们使用损失下降速度作为衡量样本难度的标准。
如果一个样本经过一轮的训练,预测损失得到了明显下降,那么模型有可能在下一轮将它学习更好。而下降较慢的样本,表明模型当前没有充分的能力对其进行学习或者已经学习地很好,不需要再重复进行训练。

图13:损失下降速度
对于模型能力,我们同样在训练过程中动态地进行计算。这里我们使用机器翻译中常用的评价指标BLEU值来动态地计算模型能力。

图14:动态模型能力计算
三、实验结果
实验使用Transformer模型,并将模型能力计算公式中的c0设为0.2,β设为0.9。以下为实验使用的数据集。
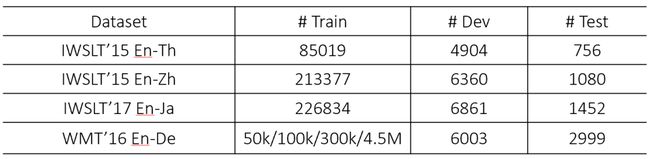
表1:数据集
首先,我们实验了静态课程学习的方法。从表2中可以看出,无论是使用句长还是词频来衡量样本难度,都无法提升模型水平。这可能是由于这些计算方法无法准确测量样本难度和模型能力导致的。

表2:静态课程学习的实验结果
而动态课程学习的实验结果表明,只通过预测损失加基于BLEU动态衡量模型能力的方法并没有提升模型能力(表3 Loss+DMC),这和我们前面的猜测是一致的。在使用预测损失速度衡量样本难度时,模型性能得到了明显提升(表3 Decline+DMC)。
此外,我们考虑到,训练过程中模型是基于batch的方法进行训练的,这意味着样本更新是基于batch中所有样本的梯度。那么,如果batch中的样本难度相似,是否会使得梯度更稳定进而使模型更容易学习?实验结果如表3最后一行,模型性能得到了显著提升,尤其在数据量较少的集合上。
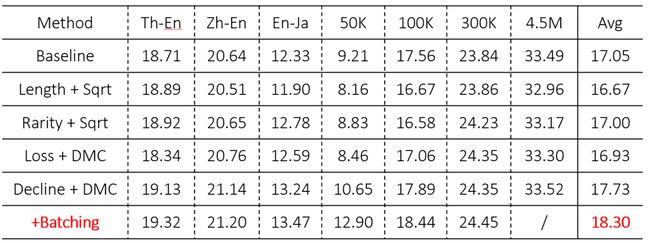
表3:所有实验结果对比
从图15可以看出,在不同大小的数据集上,动态课程学习的收敛速度明显更快。在富资源场景下,动态课程学习方法可以加快模型收敛速度,但是随着训练次数增加,它们之间的性能差距也在逐渐减小。如何在更大规模的数据集上表现更好,也是我们未来工作的一个方向。
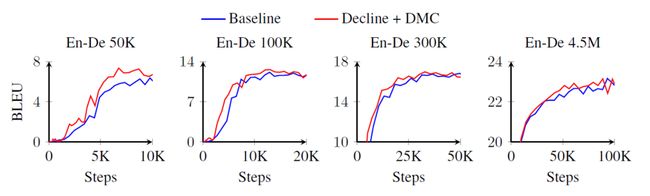
图15:训练次数与BLEU曲线
除此之外,动态课程学习虽然减少了困难样本上的训练次数(图16左),但是其翻译质量也得到了显著提升(图16右)。这表明,训练次数并不是决定模型学习质量的关键因素,而是在于如何进行高效地学习。
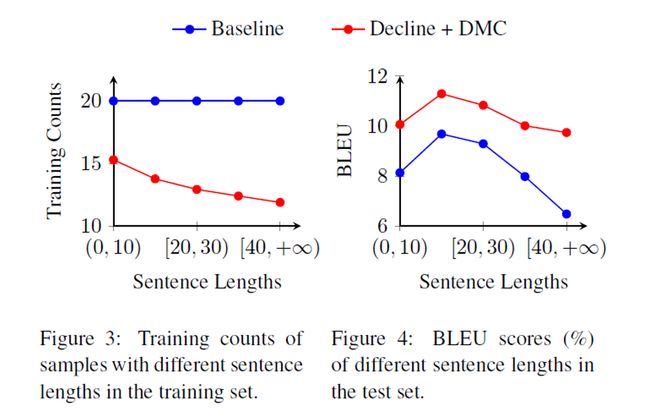
图16:不同长度句子的训练次数与翻译质量
e m t
往期精彩
AI i

整理:蒋予捷
审稿:许 晨
排版:岳白雪
AI TIME欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你!
请将简历等信息发至[email protected]!
微信联系:AITIME_HY
AI TIME是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注

(直播回放:https://b23.tv/cwjt8W)
(点击“阅读原文”下载本次报告ppt)