基于sklearn的决策树实现
sklearn
本文基于菜菜的机器学习教程。
文章目录
- sklearn
-
- 决策树
-
- 参数表示
- 数据预处理
- 分离特征(x)与标签(y)
- 划分训练集与测试集
- 建立模型
-
- 基础代码
- 交叉验证
- 调参
- 可视化
决策树
参数表示
决策树中有参数如下:
DecisionTreeClassifier(criterion="gini"
, splitter="best"
, max_depth=None
, min_samples_split=2
, min_samples_leaf=1
, min_weight_fraction_leaf=0.
, max_features=None
, random_state=None
, max_leaf_nodes=None
, min_impurity_decrease=0.
, min_impurity_split=None
, class_weight=None,
presort=False)
以下几个参数较为重要
- criterion : string, optional (default=“gini”)
用以设置用信息熵还是基尼系数计算。
(1).criterion=‘gini’,分裂节点时评价准则是Gini指数。
(2).criterion=‘entropy’,分裂节点时的评价指标是信息增益(模型欠拟合时使用)。- max_depth : int or None, optional (default=None)。
指定树的最大深度。 如果为None,表示树的深度不限。直到所有的叶子节点都是纯净的,即叶子节点 中所有的样本点都属于同一个类别。或者每个叶子节点包含的样本数小于min_samples_split。- splitter : string, optional (default=“best”)。
指定分裂节点时的策略。
(1).splitter=‘best’,表示选择最优的分裂策略。
(2).splitter=‘random’,表示选择最好的随机切分策略。- min_samples_leaf : int, float, optional (default=1)
限定每个节点分枝后子节点至少有多少个数据,否则就不分枝。
(1).如果为整数,则min_samples_split就是最少样本数。
(2).如果为浮点数(0到1之间),则每个叶子节点最少样本数为ceil(min_samples_leaf * n_samples)
数据预处理
在编写代码时,对数据的预处理主要包括对数据的导入,补全与删减,x与y的选取,将字典变量转化为虚拟变量等
- 导入数据
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from matplotlib.pyplot as plt
from sklearn.model_selection import GridsearchCV
data = pd.read_csv("your_ducument")
#查看数据信息
data.info()
#显示表的前10行
data.head(10)
- 删除特征
对于一些不需要的特征,例如明显与因变量关系不大的特征或是缺失值实在太多难以填补的特征可以适当性的直接拿掉。
data.drop(["被拿掉的特征名1,被拿掉特征名2"], inplace = True, axis = 1)
这里
inplace = True指的是将替换原有的data,即等价于data = data.drop(["被拿掉的特诊名1,被拿掉特诊名2"],axis = 1)。
关于axis = 1,只的是对列操作,即对每一行操作.
- 填充缺失值
假设我们有一特征为年龄(age)
#使用平均值来填补缺失值
data["age"] = data["age"].fillna(data["age"].mean())
当某特征仅缺失较少的值时,把缺失的那个数据所在行删掉即可
#默认有axis = 0,即对整行进行操作
data = data.dropna()
- 类型转换
假设我们有一特征楼层(floor):有first,second,third 三个string值,将其转化为0,1,2。
#可以得到["first","second",third]
labels = data["floor"].unique().tolist()
#index可以返回元素x在列表中的位置
data["floor"] = data["floor"].apply( lambda x : labels.index(x))
- 关于apply()的具体用法见此
- 语法补充
上述我们一直在使用的data是pandas特有的DataFrame类型,关于取出其中的某一列特征进行操作可以使用data["age"],但最好使用data.loc[:,"age"]或是data.iloc[:,3]。
分离特征(x)与标签(y)
假设我们要取出的标签是楼层(floor)
x = data.iloc[:, data.colums !="floor"]
y = data.iloc[:, data.colums == "floor"]
划分训练集与测试集
#选取30%为测试集,70%为训练集
from sklearn.model_selection import train_test_split
Xtrain, Xtext, Ytrain, Ytest = train_test_split(x, y, test_size = 0.3)
此函数随机选取训练集与测试集,会将索引打乱,为了以防万一对后续造成额外影响,有必要纠正索引.
- 所谓”索引“,是pandas在导入时DataFrame对每一行数据按顺序产生的索引,当输入
Xtrain.index时会返回被打乱的索引列表。
#恢复索引
for i in [Xtrain, Xtext, Ytrain, Ytest] :
i.index = range(i.shape[0])
建立模型
基础代码
clf = DecisionTreeClassifier(random_state = 25)#random_state为随机数种子
clf = clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, Ytest)#R方
交叉验证
- 交叉验证 : 指不断随机改变训练集与测试集
#10次交叉验证均值
cross_score = cross_val_score(clf, x, y, cv = 10).mean()
调参
- 基础方法
tr = []#训练集拟合程度
te = []#测试集拟合程度
for i in range(10) :
#调整max_depth,即剪枝
clf = DecisionTreeClassifier(random_state = 25, max_depth = i + 1)#random_state为随机数种子
clf = clf.fit(Xtrain, Ytrain)
score_tr = clf.score(Xtest, Ytest)
score_te = cross_val_score(clf, x, y, cv = 10).mean()
tr.append(score_tr)
te.append(score_te)
plt.plot(range(1,11), tr, color = "red", label = "train")
plt.plot(range(1,11), te, color = "blue",label = "test")
plt.xticks(range(1,11))
plt.yticks(range(1,11))
plt.legend()
ply.show()
- 网格搜索
事实上就是暴力枚举,速度特别慢
(而且算了半天说不定还没一开始简简单单的好)
parameters = {
"criterion":("gini","entropy"),
"spliter":("best","random"),
"max_depth": [*range(1,10)],
"min_samples_leaf" = [*range(1,50,5)],
"min_impurity_decrease" = np.linspace(0,0.5,50) }
clf = DecisionTreeClassifier(random = 25)
GS = GridSearchCV(clf, parameters, cv = 10)
GS = GS.fit(Xtrain, Ytrain)
GS.best_params_#最佳参数组合
GS.best_score_#最佳结果r方
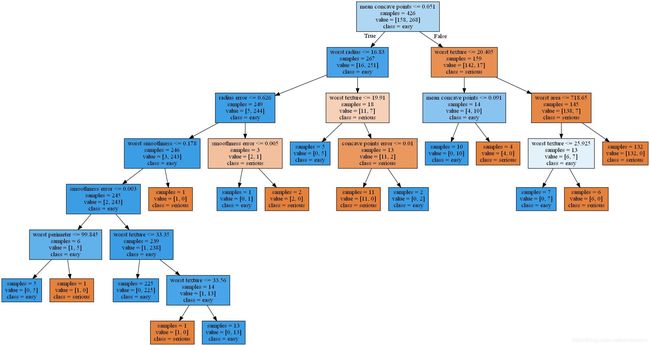
可视化
生成可视化图,在这里仅仅只能输出一个dot文件。
dot_data = export_graphviz(tree,out_file= "result.dot",class_names['serious','easy'],feature_names=cancer.feature_names,impurity=False,filled=True)
将.dot文件转为jpg文件,展示可视化图(不知道为啥不可用,要用cmd来转换 dot result.dot -T jpg -o result.jpg)
(graph,)= pydot.graph_from_dot_file('result.dot')
graph.write_png('tree.png')