python网络编程基础(连载)9 静态web实现
github链接:https://github.com/ScrappyZhang/python_web_Crawler_DA_ML_DL
9 基于socket的静态web服务器
前面8章我们学习了网络编程最基础的概念和在python中的使用方法。为了更充分的体现这些基础概念的重要性,本节综合所有基础知识带大家一同使用学习到的知识来实践编写一个静态web服务器——python web server,简称PWB。
9.1 显示固定页面的web服务器
这一节为了更好的理解静态web服务器的搭建过程,我们先来搭建一个只能显示固定页面内容的web服务器。如何实现呢?通过面向对象的思维,我们可以先创建一个web服务器类HTTPServer,然后实例化调用运行即可。一般情况下web服务器都是一直在运行并处理客户端请求,因此我们的这个web服务器类除了初始化__init__方法外,还需要一个永久运行监听客户端(浏览器)连接的方法serve_forever和一个连接成功后向客户端(浏览器)发送响应数据的方法handlerequest。代码框架如下:
import socket
SERVER_ADDR = (HOST, PORT) = '', 8888 # 服务器地址
VERSION = 1.0 # web服务器版本号
class HTTPServer():
def __init__(self, server_address):
"""初始化服务器TCP套接字"""
pass
def serve_forever(self):
"""永久运行监听接收连接"""
pass
def handlerequest(self, client_socket):
"""客户端请求处理,发送响应数据"""
pass
def run():
"""运行服务器"""
pwb = HTTPServer(SERVER_ADDR)
print('web server:PWB %s on port %d...\n' % (VERSION, PORT))
pwb.serve_forever()
if __name__ == '__main__':
run()
运行一下,可以看到终端输出一下信息提示web服务器在8888端口运行,由于它并没有任何功能,所以仅仅是提示信息。
web server:PWB 1.0 on port 8888...
接下来我们需要做的就是将代码框架中的空缺部分一一填满。
根据TCP服务器的搭建过程,我们知道,HTTPServer类的初始化方法中应当实现这些功能:TCP服务套接字的创建、地址绑定并启动监听。
def __init__(self, server_address):
"""初始化服务器TCP套接字"""
self.tcp_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.tcp_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
self.tcp_socket.bind(server_address)
self.tcp_socket.listen(128)
永久运行监听接收连接的方法serve_forevet主要功能是实现连接上客户端,并调用客户端请求处理方法self.handlerequest。
def serve_forever(self):
"""永久运行监听接收连接"""
while True:
client_socket, client_address = self.tcp_socket.accept()
print(client_address, '向服务器发起了请求')
self.handlerequest(client_socket)
客户端请求处理方法handlerequest则需要获取客户端(浏览器)发送来的请求数据,并经过解析后向浏览器发送一组包括响应头和响应体的数据。这里由于我们是返回一个固定的内容hello PWB,因此我们只要接收到了浏览器的请求,便可以发送固定的响应成功头和固定的响应体hello PWB给浏览器。
def handlerequest(self, client_socket):
"""客户端请求处理,发送响应数据"""
# 收取浏览器请求信息,并在服务器端打印显示
request_data = client_socket.recv(2048).decode('utf-8')
request_header_lines = request_data.splitlines()
for line in request_header_lines:
print(line)
# 响应信息:本例显示固定内容:响应成功 + hello PWB
resp_headers = "HTTP/1.1 200 OK\r\n" # 200代表响应成功并找到资源
resp_headers += "Server: PWB" + str(VERSION) + '\r\n' # 告诉浏览器服务器
resp_headers += '\r\n' # 空行隔开body
resp_body = 'hello PWB\r\n' # 固定的显示内容
resp_data = resp_headers + resp_body
# 发送相应数据至浏览器
client_socket.send(resp_data.encode('utf-8'))
client_socket.close() # HTTP短连接,请求完即关闭TCP连接
这样子,我们的代码框架就根据需求功能填充完毕了。
完整代码如下:
'''net09_web_PWB1.py'''
import socket
SERVER_ADDR = (HOST, PORT) = '', 8888 # 服务器地址
VERSION = 1.0 # web服务器版本号
class HTTPServer():
def __init__(self, server_address):
"""初始化服务器TCP套接字"""
self.tcp_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.tcp_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
self.tcp_socket.bind(server_address)
self.tcp_socket.listen(128)
def serve_forever(self):
"""永久运行监听接收连接"""
while True:
client_socket, client_address = self.tcp_socket.accept()
print(client_address, '向服务器发起了请求')
self.handlerequest(client_socket)
def handlerequest(self, client_socket):
"""客户端请求处理,发送响应数据"""
# 收取浏览器请求信息,并在服务器端打印显示
request_data = client_socket.recv(2048).decode('utf-8')
request_header_lines = request_data.splitlines()
for line in request_header_lines:
print(line)
# 响应信息:本例显示固定内容:响应成功 + hello PWB
resp_headers = "HTTP/1.1 200 OK\r\n" # 200代表响应成功并找到资源
resp_headers += "Server: PWB" + str(VERSION) + '\r\n' # 告诉浏览器服务器
resp_headers += '\r\n' # 空行隔开body
resp_body = 'hello PWB' # 固定的显示内容
resp_data = resp_headers + resp_body
# 发送相应数据至浏览器
client_socket.send(resp_data.encode('utf-8'))
client_socket.close() # HTTP短连接,请求完即关闭TCP连接
def run():
"""运行服务器"""
pwb = HTTPServer(SERVER_ADDR)
print('web server:PWB %s on port %d...\n' % (VERSION, PORT))
pwb.serve_forever()
if __name__ == '__main__':
run()
运行服务器程序,并在浏览器中输入localhost:8888来访问web服务器,我们可以看到显示的内容为hello PWB。打开检查,我们可以对比查看浏览器中显示的各项请求响应信息和我们web服务器打印显示的请求信息,完全一致。
由于我们的请求处理中无论接收到什么信息,都是向浏览器发送hello PWB,因此当我们输入localhost:8888/11时也是显示hello PWB。这就是固定内容显示的web服务器。
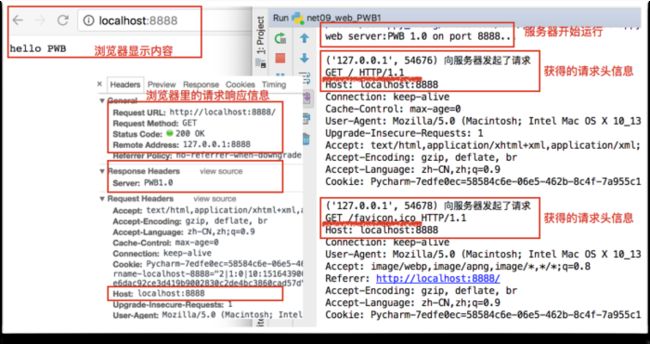
细心的读者可能会发现,浏览器还请求了一个名叫favicon.ico的文件。这个文件一般为网站标识图片,即网页标签页顶部显示的图片,如下图所示。
9.2 显示指定需要内容的web服务器
一个WEB服务器不可能只显示一个页面,肯定有特定需求的特定页面显示,怎么实现呢?。读者在上一节很清楚的看到GET 后的信息类似我们常见的资源文件夹那样的路径一样。是的,这就是静态资源的路径。我们可以通过判断这里来识别浏览器请求的是哪个静态资源。那我们就需要在HTTPServer类中的handlerequest方法修改代码来解析浏览器请求头并返回不同的响应体。
注:在讲解演示之前,我们在代码同文件夹目录下创建了一个static文件夹,里面有baidu.html、oschina.html和gitee.html三个html文件。它们分别是百度、开源中国和码云三个网站的首页源码。读者可以通过我们之前的并发下载网页的源码经过适当调整来下载生成这三个html文件;也可以直接在浏览器中分别打开相应的主页,将网页源码拷贝在本地建立三个html文件。本节将讲解根据浏览器输入URL的不同来请求获取这三个html,就像访问真正的三个网站一样。
首先我们需要解析请求信息。请求信息的第一行get内容为请求文件的路径,通过正则表达式便可以将其抓取出来。代码如下:
pattern = r'[^/]+(/[^ ]*)'
request_html_name = re.match(pattern, request_header_lines[0]).group(1)
一般web服务器都会在静态资源URL的基础之上来添加一些路径来实现避免被用户访问到不该访问的内容。后面我们会看到本例中URL为localhost:8888/baidu.html,实际上调用的是./static/baidu.html文件。假如我们作为web服务器放一个非常机密的文件password.txt,这种常见的文件名称和类型,很容易会被黑客等直接通过localhost:8888/password.txt获取到并造成数据泄露。所以一般web服务器内部都会对静态资源路径有一套编码解码机制来加密。这里我们假设我们的默认页面就是baidu.html。即localhost:8888、localhost:8888/、localhost:8888/baidu.html显示的内容一致。
if request_html_name == '/':
request_html_name = STATIC_PATH + 'baidu.html'
else:
request_html_name = STATIC_PATH + request_html_name
至此,我们就已经获悉了用户请求的具体文件情况,我们只需根据相应文件名来读取相应文件并设置为响应体发送给浏览器即可。
html_file = open(request_html_name, 'rb')
resp_body = html_file.read() # 显示内容为读取的文件内容
html_file.close()
完整的代码如下:
'''net09_web_PWB2.py'''
import socket
import re
SERVER_ADDR = (HOST, PORT) = '', 8888 # 服务器地址
VERSION = 2.0 # web服务器版本号
STATIC_PATH = './static/'
class HTTPServer():
def __init__(self, server_address):
"""初始化服务器TCP套接字"""
self.tcp_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.tcp_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
self.tcp_socket.bind(server_address)
self.tcp_socket.listen(128)
def serve_forever(self):
"""永久运行监听接收连接"""
while True:
client_socket, client_address = self.tcp_socket.accept()
print(client_address, '向服务器发起了请求')
self.handlerequest(client_socket)
def handlerequest(self, client_socket):
"""客户端请求处理,发送响应数据"""
# 收取浏览器请求头,并在服务器端打印显示
request_data = client_socket.recv(2048).decode('utf-8')
request_header_lines = request_data.splitlines()
# print(request_header_lines[0]) # 第一行为请求头信息
# 解析请求头,获取具体请求信息
pattern = r'[^/]+(/[^ ]*)'
request_html_name = re.match(pattern, request_header_lines[0]).group(1)
# 根据解析到的内容补全将要读取文件的路径
if request_html_name == '/':
request_html_name = STATIC_PATH + 'baidu.html'
else:
request_html_name = STATIC_PATH + request_html_name
# 根据文件情况来返回相应的信息
try:
html_file = open(request_html_name, 'rb')
except FileNotFoundError:
# 文件不存在,则返回文件不存在,并返回状态码404
resp_headers = 'HTTP/1.1 404 not found\r\n'
resp_headers += "Server: PWB" + str(VERSION) + '\r\n'
resp_headers += '\r\n'
resp_body = '==== 404 file not found===='.encode('utf-8')
else:
# 文件存在,则读取文件内容,并返回状态码200
resp_headers = "HTTP/1.1 200 OK\r\n" # 200代表响应成功并找到资源
resp_headers += "Server: PWB" + str(VERSION) + '\r\n' # 告诉浏览器服务器
resp_headers += '\r\n' # 空行隔开body
resp_body = html_file.read() # 显示内容为读取的文件内容
html_file.close()
finally:
resp_data = resp_headers.encode('utf-8') + resp_body # 结合响应头和响应体
# 发送相应数据至浏览器
client_socket.send(resp_data)
client_socket.close() # HTTP短连接,请求完即关闭TCP连接
def run():
"""运行服务器"""
pwb = HTTPServer(SERVER_ADDR)
print('web server:PWB %s on port %d...\n' % (VERSION, PORT))
pwb.serve_forever()
if __name__ == '__main__':
run()
可以看到,当输入localhost:8888时,返回的是我们本地的baidu.html 。同样可以在浏览器里看到我们设置的web服务器版本PWB2.0了。

当输入localhost:8888/gitee.html时,返回的是我们本地的gitee.html。
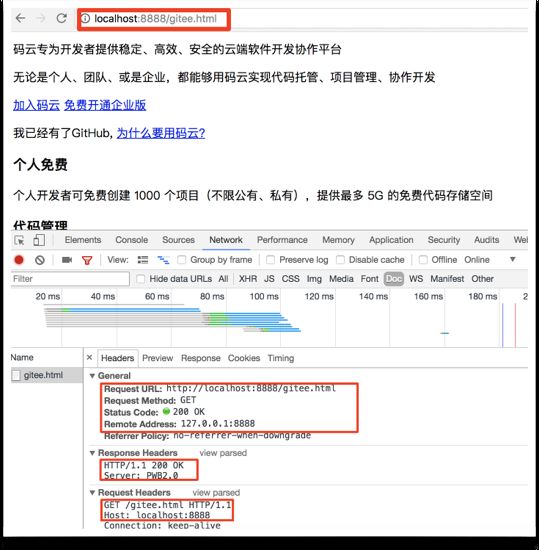
当输入localhost:8888/22时,返回的是404错误信息。

9.3 多线程、多进程、协程实现web服务器
和第7章的斗鱼照片爬取类似,我们只需要修改TCP连接客户服务套接字的启动方式就可以实现9.2节的内容了,也就是修改HTTPServer类的serve_forver方法。限于篇幅,本节只列举被修改的部分,完整源代码请参考net09_web_PWB3.py、net09_web_PWB4.py和net09_web_PWB5.py
9.3.1 多线程web服务器
def serve_forever(self):
"""永久运行监听接收连接"""
while True:
client_socket, client_address = self.tcp_socket.accept()
print(client_address, '向服务器发起了请求')
td1 = threading.Thread(target=self.handlerequest, args=(client_socket,))
td1.start()
9.3.2 多进程web服务器
def serve_forever(self):
"""永久运行监听接收连接"""
while True:
client_socket, client_address = self.tcp_socket.accept()
print(client_address, '向服务器发起了请求')
processes = multiprocessing.Process(target=self.handlerequest, args=(client_socket,))
processes.start()
client_socket.close()
9.3.3 协程web服务器
def serve_forever(self):
"""永久运行监听接收连接"""
while True:
client_socket, client_address = self.tcp_socket.accept()
print(client_address, '向服务器发起了请求')
gevent.spawn(self.handlerequest, client_socket)
9.4 拓展epoll非阻塞IO的web服务器
在9.3节,我们在serve_forever方法中通过while True来实现死循环运行实现并发web服务器,不会出错是因为我们的服务端套接字默认是阻塞型的,即无连接时,会停在accept()那里。这样的工作模式在海量连接工作时效率很低。
要向工作效率高,就可以I/O多路复用。多路IO好处就在于单个process就可以同时处理多个网络连接的IO。对于多路IO模型在很多操作系统上都有一些实现,比如多数BSD平台都支持的kqueue(),或者Windows支持的IOCP,而Linux 平台(内核版本2.5+)上就有一个著名的模型epoll。在epoll模型中 由操作系统负责监听的所有socket,当某个socket有数据到达了,操作系统就通知用户进程。这样比 在用户层面实现的 for 、while不断死循环去检测每个socket的通信状态 的代码高效太多 ,也称轮询。如果用户层面的轮询 , 某短时间段内没有用户访问,则CPU执行流程属于无用功(while死循环中) 产出效率低 浪费资源。并且执行效率和轮询的socket数量息息相关, 一般在1024-2048左右。随着需要轮询的数量增加,轮询效率越低。
I/O 多路复用的特点:
通过一种机制使一个进程能同时等待多个文件描述符,而这些文件描述符(套接字描述符)其中的任意一个进入读就绪状态,epoll()函数就可以返回。所以, I/O多路复用,本质上在 任何时候 监视任务都是单进程(单线程)模式 进行工作,它之所以能提高效率是因为select / epoll 把进来的socket放到他们的 '监视' 列表里面,当任何socket有可读可写数据立马处理,那如果select\epoll 手里同时检测着很多socket, 一有动静马上返回给进程处理,比一个一个socket过来,恢复阻塞等待前的情况开始执行处理请求 效率高。
要I/O多路复用就需要把服务套接字设置为非阻塞,但是会出错。怎么办呢?
self.tcp_socket.setblocking(False) # 将套接字设置为非阻塞模式
epoll是Linux内核为处理大批量文件描述符而作了改进的poll,是Linux下多路复用IO接口select/poll的增强版本,它能显著提高程序在大量并发连接中只有少量活跃的情况下的系统CPU利用率。另一点原因就是获取事件的时候,它无须遍历整个被侦听的描述符集,只要遍历那些被内核IO事件异步唤醒而加入Ready队列的描述符集合就行了。
python中有个select模块可以实现epoll。一般的使用方式为:
- 创建epoll对象
self.epoll = select.epoll() # 创建一个epoll对象 - 注册事件文件描述符,监听epoll.poll列表并执行相应操作
self.epoll.register(self.tcp_socket.fileno(), select.EPOLLIN | select.EPOLLET) # 将服务套接字注册
self.epoll.register(new_client_socket.fileno(), select.EPOLLIN | select.EPOLLET)
EPOLLIN (可读)
EPOLLOUT (可写)
EPOLLET (ET模式)EPOLLLT(LT模式)
LT模式:当epoll检测到描述符事件发生并将此事件通知应用程序,应用程序可以不立即处理该事件。下次调用epoll时,
会再次响应应用程序并通知此事件。
ET模式:当epoll检测到描述符事件发生并将此事件通知应用程序,应用程序必须立即处理该事件。
如果不处理,下次调用epoll时,不会再次响应应用程序并通知此事件
epoll_list = self.epoll.poll()
for fd, events in epoll_list:
do something
**单进程单线程采用epoll实现静态web服务器完整代码**
"""linux平台 epoll 实现web服务器"""
'''net09_web_PWB6.py'''
import socket
import select
import re
SERVER_ADDR = (HOST, PORT) = '', 8888 # 服务器地址
VERSION = 6.0 # web服务器版本号
STATIC_PATH = './static/'
class HTTPServer():
def __init__(self, server_address):
"""初始化服务器TCP套接字"""
self.tcp_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.tcp_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
self.tcp_socket.bind(server_address)
self.tcp_socket.listen(128)
self.tcp_socket.setblocking(False) # 将套接字设置为非阻塞模式
self.epoll = select.epoll() # 创建一个epoll对象
self.epoll.register(self.tcp_socket.fileno(), select.EPOLLIN | select.EPOLLET) # 将服务套接字注册
self.connections = {}
self.addresses = {}
def serve_forever(self):
"""永久运行监听接收连接"""
while True:
epoll_list = self.epoll.poll()
for fd, events in epoll_list:
if fd == self.tcp_socket.fileno():
new_client_socket, new_client_address = self.tcp_socket.accept()
print(new_client_address, '向服务器发起了请求')
self.connections[new_client_socket.fileno()] = new_client_socket # 存入客户连接事件文件描述符
self.addresses[new_client_socket.fileno()] = new_client_address
# 向epoll中则侧新socket的可读事件
self.epoll.register(new_client_socket.fileno(), select.EPOLLIN | select.EPOLLET)
elif events == select.EPOLLIN:
self.handlerequest(fd)
def handlerequest(self, fd):
"""客户端请求处理,发送响应数据"""
# 收取浏览器请求信息,并在服务器端打印显示
request_data = self.connections[fd].recv(2048).decode('utf-8')
# 数据为空代表客户端关闭了连接,则在监听中除去响应的文件描述符
if not request_data:
self.epoll.unregister(fd)
self.connections[fd].close() # server侧主动关闭连接fd
print("%s---offline---" % str(self.addresses[fd]))
del self.connections[fd]
del self.addresses[fd]
# 若存在数据,则按照正常的事件处理
else:
request_header_lines = request_data.splitlines()
# for line in request_header_lines:
# print(line)
# 解析请求头,获取具体请求信息
pattern = r'[^/]+(/[^ ]*)'
request_html_name = re.match(pattern, request_header_lines[0]).group(1)
# 根据解析到的内容补全将要读取文件的路径
if request_html_name == '/':
request_html_name = STATIC_PATH + 'baidu.html'
else:
request_html_name = STATIC_PATH + request_html_name
# 根据文件情况来返回相应的信息
try:
html_file = open(request_html_name, 'rb')
except FileNotFoundError:
# 文件不存在,则返回文件不存在,并返回状态码404
resp_headers = 'HTTP/1.1 404 not found\r\n'
resp_headers += "Server: PWB" + str(VERSION) + '\r\n'
resp_headers += '\r\n'
resp_body = '==== 404 file not found===='.encode('utf-8')
else:
# 文件存在,则读取文件内容,并返回状态码200
resp_headers = "HTTP/1.1 200 OK\r\n" # 200代表响应成功并找到资源
resp_headers += "Server: PWB" + str(VERSION) + '\r\n' # 告诉浏览器服务器
resp_headers += '\r\n' # 空行隔开body
resp_body = html_file.read() # 显示内容为读取的文件内容
html_file.close()
finally:
resp_data = resp_headers.encode('utf-8') + resp_body # 结合响应头和响应体
# 发送相应数据至浏览器
self.connections[fd].send(resp_data)
# HTTP短连接,请求完即关闭TCP连接,并除去相应事件的文件描述符
self.epoll.unregister(fd)
self.connections[fd].close() # server侧主动关闭连接fd
print("%s--web请求响应完毕-offline---" % str(self.addresses[fd]))
del self.connections[fd]
del self.addresses[fd]
def run():
"""运行服务器"""
pwb = HTTPServer(SERVER_ADDR)
print('web server:PWB %s on port %d...\n' % (VERSION, PORT))
pwb.serve_forever()
if __name__ == '__main__':
run()
当然也可以像9.3节那样多线程 方式,一个连接过来开一个 线程处理,这样消耗的内存和线程 切换页会耗掉更多的系统资源。所以, 我们可以结合I/O多路复用和多线程 来提高性能并发,I/O复用负责提高接受socket的通知效率,收到请求后,交给 多线程 来处理逻辑。完整源码见net09_web_PWB7.py。
'''net09_web_PWB7.py'''
def serve_forever(self):
"""永久运行监听接收连接"""
while True:
epoll_list = self.epoll.poll()
for fd, events in epoll_list:
if fd == self.tcp_socket.fileno():
new_client_socket, new_client_address = self.tcp_socket.accept()
print(new_client_address, '向服务器发起了请求')
self.connections[new_client_socket.fileno()] = new_client_socket # 存入客户连接事件文件描述符
self.addresses[new_client_socket.fileno()] = new_client_address
# 向epoll中则侧新socket的可读事件
self.epoll.register(new_client_socket.fileno(), select.EPOLLIN | select.EPOLLET)
elif events == select.EPOLLIN:
td = threading.Thread(target=self.handlerequest, args=(fd,))
td.start()