Python3 不解压直接解析xml文件,并进行csv出力
现在有一个zip文件,里面有多个类型的文件,想要在不解压zip包的情况下筛选并解析其中的xml文件,并且将解析的数据出力到csv文件中。(利用Python提供的zipfile库)
宜人宜己,方便自己以后查找,也给大家提供一个思路吧。
Python环境:Python 3.7
IDE:JetBrains PyCharm
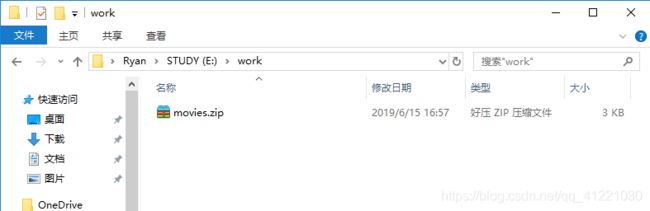
条件准备:在任意路径下放入需要进行读取的zip文件:
eg:在 E:\work 下有一个文件:E:\work\movies.zip
在zip文件中有一个movies文件夹,在\movies里面有多个文件,它们类型五花八门:
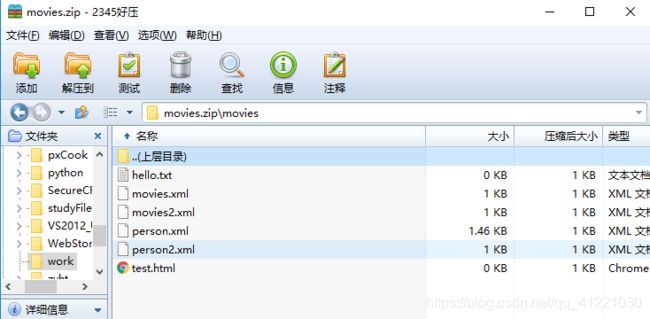
我们的目标就是要在不解压movies.zip的情况下,直接读取里面的person.xml和person2.xml,并将文件里面的数据进行csv出力。
person.xml文件:
张三
男
25
178
140
1994-07-22
13689457821
成都
李四
男
27
164
110
1992-12-25
13683645821
上海
王倩
女
21
170
100
1998-05-02
13689489461
北京
陈宇
男
24
171
120
1995-04-25
13689489471
成都
何希美
女
23
166
92
1996-06-12
13684857856
西安
杨俊
男
28
175
142
1998-08-31
13656197821
重庆
person2.xml文件:
陈思南
男
26
170
120
1993-03-25
13689659821
贵州
李若白
男
36
172
130
1986-10-21
13684695821
邯郸
张晓玲
女
25
165
96
1994-06-19
13689479161
成都
林韵
女
27
168
98
1992-05-15
13688940471
贵州
打开JetBrains PyCharm,点击【File -> New Project...】新建一个工程,接着在建好的工程中新建一个Python File(eg:zipFileParse.py)。
打开刚刚建好的Python File,首先我们需要在文件的开始位置导入我们需要的Python库(模块):
①zipfile:用于zip文件读取
②csv:用于进行csv文件出力
③xml.dom.minidom:用于解析xml文件
④io:主要是利用其中的StingIO()函数
⑤fnmatch:用于从工作空间中取出指定类型的文件名列表
⑥os:操作系统
⑦re:正则表达式
好了,下面上代码:
import zipfile, csv, xml.dom.minidom, io, fnmatch, os, re
# 获取指定工作空间下的所有指定类型的文件名
# path 工作空间
# fnexp 文件类型
# 返回所有指定类型文件名列表
def iterFindFiles(path, fnexp):
for root, dirs, files in os.walk(path):
for fileName in fnmatch.filter(files, fnexp):
# yield的作用是把一个函数变成一个generator(返回一个iterable对象)
yield os.path.join(root, fileName)
# 电影详细信息取得
# data DOMTree
# 返回电影信息data
def getMoviesDetail(data):
# 返回data定义
rtnData = []
# data编集
for movie in data:
# 行编集
row = []
# 名称
if movie.hasAttribute("title"):
row.append(movie.getAttribute("title"))
# 类型
type = movie.getElementsByTagName("type")[0]
row.append(type.childNodes[0].data)
# 格式
format = movie.getElementsByTagName("format")[0]
row.append(format.childNodes[0].data)
# 年份
year = movie.getElementsByTagName("year")[0]
row.append(year.childNodes[0].data)
# 地区
rating = movie.getElementsByTagName("rating")[0]
row.append(rating.childNodes[0].data)
# 明星数
stars = movie.getElementsByTagName("stars")[0]
row.append(stars.childNodes[0].data)
# 描述
description = movie.getElementsByTagName("description")[0]
row.append(description.childNodes[0].data)
# 返回data追加
rtnData.append(row)
return rtnData
# 人员信息取得
# data DOMTree
# 返回人员信息data
def getPersonData(data):
# 返回data定义
rtnData = []
# 返回data编集
for person in data:
# 行编集
row = []
# 项目
if person.hasAttribute("project"):
row.append(person.getAttribute("project"))
# 姓名
name = person.getElementsByTagName("name")[0]
row.append(name.childNodes[0].data)
# 性别
sex = person.getElementsByTagName("sex")[0]
row.append(sex.childNodes[0].data)
# 年龄
age = person.getElementsByTagName("age")[0]
row.append(age.childNodes[0].data)
# 身高
height = person.getElementsByTagName("height")[0]
row.append(height.childNodes[0].data)
# 体重
weight = person.getElementsByTagName("weight")[0]
row.append(weight.childNodes[0].data)
# 生日
birthday = person.getElementsByTagName("birthday")[0]
row.append(birthday.childNodes[0].data)
# 电话
phone = person.getElementsByTagName("phone")[0]
row.append(phone.childNodes[0].data)
# 住址
home = person.getElementsByTagName("home")[0]
row.append(home.childNodes[0].data)
# 返回data追加
rtnData.append(row)
return rtnData
# csv出力data取得
# data DOMTree
# type 类型
# 返回csv出力data
def getCsvData(data, type):
# csv出力data定义
csvData = []
if type == "person":
# 类型为 person 的场合,取得人员信息
csvData = getPersonData(data)
elif type == "movie":
# 类型为 movie 的场合,取得电影信息
csvData = getMoviesDetail(data)
return csvData
# csv出力
# file csv出力文件
# header csv出力Header
# dataList csv出力dataList
def csvOut(file, header, dataList):
# 打开文件
with open(file, "w", encoding="utf-8", newline="") as csvFile:
# 通过 csv.writer() 获取一个写对象
writer = csv.writer(csvFile, dialect="excel")
# Header写入
writer.writerow(header)
# data写入
for data in dataList:
for row in data:
writer.writerow(row)
# xml 文件解析
# filePath zip文件路径
# type 类型
# 返回csv出力data
def xmlFileParse(filePath, type):
# 打开 zip文件
with zipfile.ZipFile(os.path.join(os.getcwd(), filePath)) as zFile:
# csv出力data定义
rtnData = []
if zFile.namelist() == None or zFile.namelist() == []:
print("包内没有文件!")
else:
# .namelist():取得 zip文件内的所有文件(包括文件夹)
for fileName in zFile.namelist():
# 第一列
row_0 = ""
# dataBody
dataBody = []
# 从 zip文件中取得所有 .xml文件名
if re.search(r"([\w]*.xml)+$", fileName, re.S):
print("读取文件:", fileName)
# 通过io.SringIO()获取文件流(file对象)
fileSource = io.StringIO(zFile.read(fileName).decode("utf-8"))
# 利用 xml.dom.minidom.parse() 将文件(file对象转为DOM)
DomTree = xml.dom.minidom.parse(fileSource)
# 获取 DOM 上的所有节点
allElement = DomTree.documentElement
# 用 '/' 将文件名分割
subFileName = fileName.split(r"/")
# 获取指定类型的 data
if re.search(type, subFileName[len(subFileName) - 1]):
# 第一列data编集
if type == "person" and allElement.hasAttribute("company"):
row_0 = allElement.getAttribute("company")
elif type == "movie" and allElement.hasAttribute("shelf"):
row_0 = allElement.getAttribute("shelf")
# 根据 TagName 获取DOMTree
dataTree = allElement.getElementsByTagName(type)
# dataBody 取得
dataBody = getCsvData(dataTree, type)
else:
pass
for row in dataBody:
# 将第一列data插入行
row.insert(0, row_0)
# csv出力data追加
rtnData.append(row)
# 文件流关闭
fileSource.close()
return rtnData
# 主程序入口
if __name__ == "__main__":
p_cnt = 30
print("*"*p_cnt, " Start ", "*"*p_cnt)
# csv出力dataList
csvDataList = []
# 取得工作空间内的所有 zip文件
for zFile in iterFindFiles(r"E:\work", r"*.zip"):
print(zFile)
# csv出力data追加
csvDataList.append(xmlFileParse(zFile, "person"))
# csv出力文件名
csvFile = r"E:\work\person.csv"
# Header
csvHeader = ["company", "person", "name", "sex", "age", "height", "weight", "birthday",
"phone", "home"]
# csv文件出力
csvOut(csvFile, csvHeader, csvDataList)
print("*"*p_cnt, " Success ", "*"*p_cnt)现在运行一下,看看是否正确:
执行成功:
回到我们指定的路径下面查看一下,是否生成了csv文件:person.csv
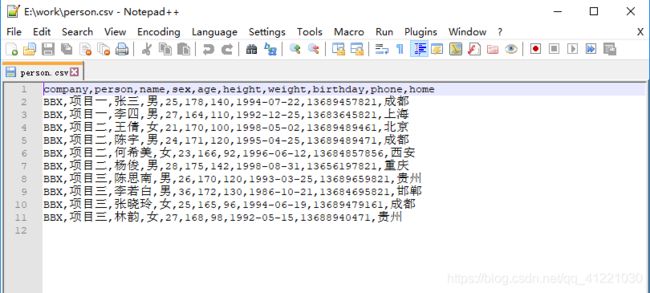
打开已经生成的person.csv文件,看看是否已经写入了我们需要的数据:
OK,到这里就已经成功实现了在不解压zip文件的情况下直接读取里面的xml文件,并解析数据写入到csv文件中。
注:
①由于各种压缩方式不一致,zip不支持固实压缩,因此可以不解压直接读取其中的文件内容;其他常用的压缩方式如rar、7z等都是采用的固实压缩,将要压缩的所有文件作为一块数据进行压缩,所以要读取其中的文件内容,但是如果是一个文件单独进行压缩的倒是可以实现。
②关于出力的csv文件中中文乱码的问题:
在csv出力的代码中:
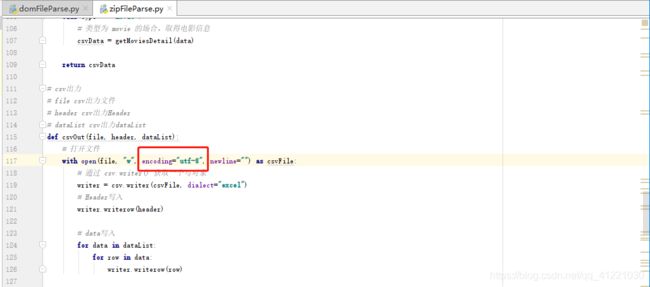
在这里,我们设置了打开文件的编码格式为utf-8,在出力的csv文件中,使用文本编集工具打开时,里面的中文正常显示;但是用Excel打开时,里面的中文出现乱码:
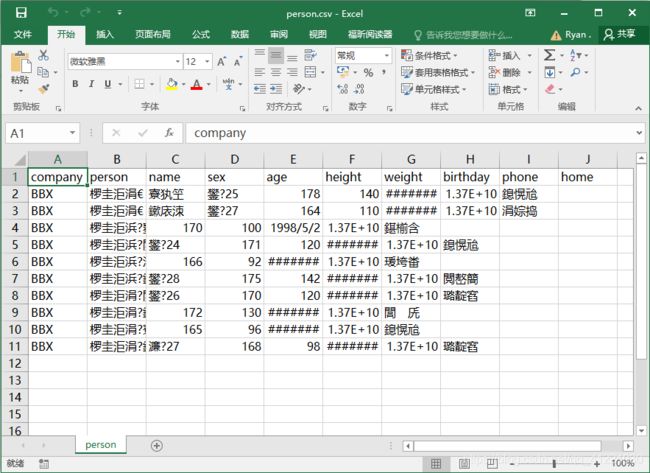
这是因为中文的编码一般使用的是GBK,而Excel对中文的默认编码格式也是如此,如果在写入的时候使用utf-8的编码格式写入,Excel在自动解析的时候就会出现中文乱码的情况。
如果想要使用Excel打开时中文不出现乱码现象,很简单,代码中只需在csv出力中不要设置编码格式,即:
def csvOut(file, header, dataList):
# 打开文件
with open(file, "w", newline="") as csvFile:
# 通过 csv.writer() 获取一个写对象
writer = csv.writer(csvFile, dialect="excel")
# Header写入
writer.writerow(header)
# data写入
for data in dataList:
for row in data:
writer.writerow(row)这样就解决了使用Excel打开csv文件时中文显示乱码的问题。
大家有问题欢迎批评指正。