1. 前言。
1.1. 需求背景。
- 每天抓取的是同一份商品的数据,用来做趋势分析。
- 要求每天都需要抓一份,也仅限抓取一份数据。
- 但是整个爬取数据的过程在时间上并不确定,受本地网络,代理速度,抓取数据量有关,一般情况下在20小时左右,极少情况下会超过24小时。
1.2. 实现功能。
通过以下三步,保证爬虫能自动隔天抓取数据:
每天凌晨00:01启动监控脚本,监控爬虫的运行状态,一旦爬虫进入空闲状态,启动爬虫。
一旦爬虫执行完毕,自动退出脚本,结束今天的任务。
一旦脚本距离启动时间超过24小时,自动退出脚本,等待第二天的监控脚本启动,重复这三步。
2. 环境。
python 3.6.1
系统:win7
IDE:pycharm
安装过scrapy
3. 设计思路。
3.1. 前提:
目前爬虫是通过scrapy模块自带的cmdline.execute来启动的。
from scrapy import cmdline
cmdline.execute('scrapy crawl mySpider'.split())
3.2. 将自动执行脚本做到scrapy爬虫的外部
(1)每天凌晨00:01启动脚本(控制脚本的存活时间为24小时),监测爬虫的运行状态(需要用一个标记信息来表示爬虫的状态:运行还是停止)。
- 如果爬虫处于运行状态(前一天爬取数据尚未结束),进入第(2)步;
- 如果爬虫处于非运行状态(前一天的爬取任务已完成,今天的尚未开始),进入第(3)步;
(2)脚本进入等待阶段,每隔10分钟,检查一下爬虫的运行状态,如(1)。但是一旦发现,脚本的等待时间超过了24小时,则自动退出脚本,因为第二天的监测脚本已经开始运行了,接替了它的任务。
(3)做一些爬虫启动前的准备工作(删除用来续爬的文件,防止爬虫不运行了),启动爬虫爬取数据,待爬虫正常结束后,退出脚本,完成当天的爬取任务。
4. 准备工作。
4.1. 标记爬虫的运行状态。
通过判断文件是否存在的方式来判断爬虫是否处于运行状态:
- 在爬虫启动时,创建一个isRunning.txt文件。
- 在爬虫结束时,删除这个isRunning.txt文件。
那么isRunning.txt存在,就说明爬虫正在运行;文件不存在,就说明爬虫不在运行。
# 文件pipelines.py
# 爬虫启动时
checkFile = "isRunning.txt"
class myPipeline:
def open_spider(self, spider):
self.client = MongoClient('localhost:27017') # 连接Mongodb
self.db = self.client['mydata'] # 待存储数据的数据库mydata
f = open(checkFile, "w") # 创建一个文件,代表爬虫在运行中
f.close()
# 文件pipelines.py
# 爬虫正常结束时
checkFile = "isRunning.txt"
class myPipeline:
def close_spider(self, spider):
self.client.close()
isFileExsit = os.path.isfile(checkFile)
if isFileExsit:
os.remove(checkFile)
4.2. 爬虫支持续爬,能随时暂停,方便调试。
# 在scrapy项目中添加start.py文件,用于启动爬虫
from scrapy import cmdline
# 在爬虫运行过程中,会自动将状态信息存储在crawls/storeMyRequest目录下,支持续爬
cmdline.execute('scrapy crawl mySpider -s JOBDIR=crawls/storeMyRequest'.split())
# Note:若想支持续爬,在ctrl+c终止爬虫时,只能按一次,爬虫在终止时需要进行善后工作,切勿连续多次按ctrl+c

4.3. Log按照每天的日期命名,方便查看和调试
设置Log等级:
# 文件mySpider.py
class mySpider(CrawlSpider):
name = "mySpider"
allowed_domains = ['http://photo.poco.cn/']
custom_settings = {
'LOG_LEVEL':'INFO', # 减少Log输出量,仅保留必要的信息
# ...... 在爬虫内部用custom_setting可以让这个配置信息仅对这一个爬虫生效
}
以日期为Log文件命名
# 文件settings.py
import datetime
BOT_NAME = 'mySpider'
ROBOTSTXT_OBEY = False
startDate = datetime.datetime.now().strftime('%Y%m%d')
LOG_FILE=f"mySpiderlog{startDate}.txt"
4.4. 为数据按日期存储到不同的表(mongodb的集合)中
# 文件pipelines.py
import datetime
GALANCE=f'galance{datetime.datetime.now().strftime("%Y%m%d")}' # 表名
class myPipeline:
def open_spider(self, spider):
self.client = MongoClient('localhost:27017') # 连接Mongodb
self.db = self.client['mydata'] # 待存储数据的数据库mydata
self.db[GALANCE].insert(dict(item))

4.5. 编写批处理文件启动爬虫
# 文件run.bat cd /d F:/newClawer20170831/mySpider call python main.py pause
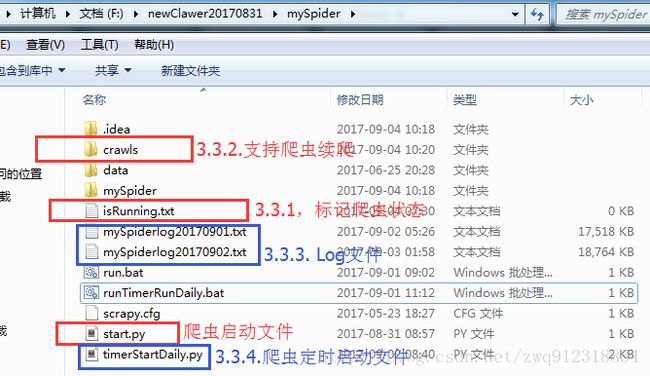
5. 实现代码
5.1. 编写python脚本
# 文件timerStartDaily.py
from scrapy import cmdline
import datetime
import time
import shutil
import os
recoderDir = r"crawls" # 这是为了爬虫能够续爬而创建的目录,存储续爬需要的数据
checkFile = "isRunning.txt" # 爬虫是否在运行的标志
startTime = datetime.datetime.now()
print(f"startTime = {startTime}")
i = 0
miniter = 0
while True:
isRunning = os.path.isfile(checkFile)
if not isRunning: # 爬虫不在执行,开始启动爬虫
# 在爬虫启动之前处理一些事情,清掉JOBDIR = crawls
isExsit = os.path.isdir(recoderDir) # 检查JOBDIR目录crawls是否存在
print(f"mySpider not running, ready to start. isExsit:{isExsit}")
if isExsit:
removeRes = shutil.rmtree(recoderDir) # 删除续爬目录crawls及目录下所有文件
print(f"At time:{datetime.datetime.now()}, delete res:{removeRes}")
else:
print(f"At time:{datetime.datetime.now()}, Dir:{recoderDir} is not exsit.")
time.sleep(20)
clawerTime = datetime.datetime.now()
waitTime = clawerTime - startTime
print(f"At time:{clawerTime}, start clawer: mySpider !!!, waitTime:{waitTime}")
cmdline.execute('scrapy crawl mySpider -s JOBDIR=crawls/storeMyRequest'.split())
break #爬虫结束之后,退出脚本
else:
print(f"At time:{datetime.datetime.now()}, mySpider is running, sleep to wait.")
i += 1
time.sleep(600) # 每10分钟检查一次
miniter += 10
if miniter >= 1440: # 等待满24小时,自动退出监控脚本
break
5.2. 编写bat批处理文件
# 文件runTimerRunDaily.bat cd /d F:/newClawer20170831/mySpider call python timerStartDaily.py pause
6. 部署。
6.1. 添加计划任务。
参考以下这篇博客部署windows计划任务:
https://www.jb51.net/article/204879.htm
有关windows计划任务相关设置的详细说明如下:
https://technet.microsoft.com/zh-cn/library/cc722178.aspx
6.2. 注意事项。
(1)在添加计划任务时,要按照如下图进行勾选(只在用户登录时运行),才能弹出下面的cmd任务界面,方便观察和调试。


(2)由于爬虫运行时间很长,如果按照默认设置,在凌晨运行实例时,上一次启动尚未结束,会导致这次启动失败,所以要更改默认设置为(如果此任务已经运行:并行运行新实例。保护机制在于每个启动脚本在等待24小时候会自动退出,来保证不会重复启动)。

(3)如果想支持续传,只能按一次 ctrl + c 来停止爬虫运行。因为终止爬虫时,爬虫需要做一些善后工作,如果连续按多次ctrl + c来停止爬虫,爬虫将来不及善后,会导致无法续爬。 6.3. 效果展示。
正常执行完成:
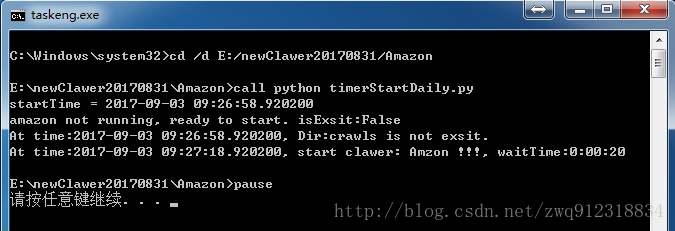
正在执行中:

到此这篇关于python实现scrapy爬虫每天定时抓取数据的示例代码的文章就介绍到这了,更多相关python scrapy定时抓取内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!