用Python分析豆瓣电影Top250
开场白:本文中使用的语言为 Python 3 ,其中主要用了 BeautifulSoup、Numpy、Pandas、Matplotlib和WordCloud 等几个数据分析常用库,过程尽量写的详(luo)细(suo)些,希望能给和我一样的数据分析初学者一些思路,如果文中有错误请告诉我。同时欢迎各种关于代码、分析思路、语言组织、排版等等的意见建议。非常感谢!文章很长,如果只看部分内容请戳目录。
豆瓣电影Top250数据分析
不知道看什么电影时,就会习惯性的看看豆瓣,但落伍的我直到最近才发现还有个神奇的豆瓣电影Top250榜单!它是根据每部影片看过的人数以及该影片所得的评论等综合数据排名的,同时还考虑了人群的广泛适应性和持续关注度。好高大上的算法!
那么得出的这个排行榜和电影评分及评论人数有怎样的关系?
和上映时间关系大不大?
哪种类型的电影上榜最多呢?
哪些国家、导演、主演最受欢迎?
片长多长时间最合适?
带着这些疑问,不妨进行一下数据分析。
数据收集
先来看一下页面:
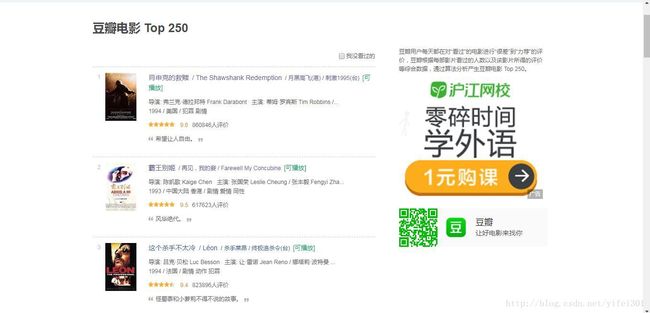
我们抓取排名、电影名、导演、主演、上映日期、制片国家/地区、类型,评分、评论数量、一句话评价以及电影链接,其中导演和主演分别取一位。
用开发者工具看一下源代码:
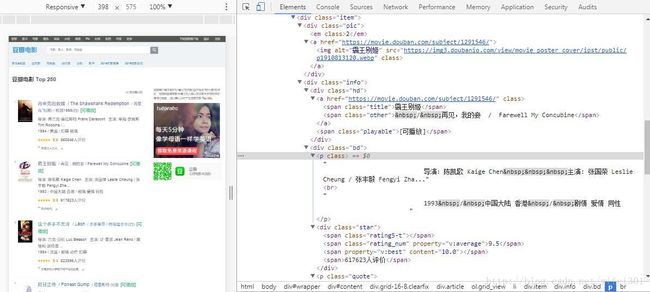
大部分信息比较好抓取,只有电影信息在标签 中都写在了一起,可通过 strip() 函数去除两侧空格, split()函数分裂字符串来取得具体信息。
选用Python 3,引入 url.request 和 BeautifulSoup 库来抓取页面信息。代码如下:
import urllib.request as urlrequest
from bs4 import BeautifulSoup
top250_url = "https://movie.douban.com/top250?start={}&filter="
with open('top250_f1.csv','w',encoding='utf8') as outputfile:
outputfile.write("num#title#director#role#init_year#area#genre#rating_num#comment_num#comment#url\n")
for i in range(10):
start = i*25
url_visit = top250_url.format(start)
crawl_content = urlrequest.urlopen(url_visit).read()
http_content = crawl_content.decode('utf8')
soup = BeautifulSoup(http_content,'html.parser')
all_item_divs = soup.find_all(class_='item')
for each_item_div in all_item_divs:
pic_div = each_item_div.find(class_='pic')
num = pic_div.find('em').get_text() #排名
href = pic_div.find('a')['href'] #电影链接
title = pic_div.find('img')['alt'] #电影名称
bd_div = each_item_div.find(class_='bd')
infos = bd_div.find('p').get_text().strip().split('\n')
infos_1 = infos[0].split('\xa0\xa0\xa0')
director = infos_1[0][4:].rstrip('...').rstrip('/').split('/')[0] #导演
role = str(infos_1[1:])[6:].split('/')[0] #主演
infos_2 = infos[1].lstrip().split('\xa0/\xa0')
year = infos_2[0] #上映时间
area = infos_2[1] #国家/地区
genre = infos_2[2:] #电影类型
star_div = each_item_div.find(class_='star')
rating_num = star_div.find(class_='rating_num').get_text() #评分
comment_num = star_div.find_all('span')[3].get_text()[:-3] #评价数量
quote = each_item_div.find(class_='quote')
inq = quote.find(class_='inq').get_text() #一句话评价
outputfile.write('{}#{}#{}#{}#{}#{}#{}#{}#{}#{}#{}\n'.format(num,title,director,role,year,area,
genre,rating_num,comment_num,inq,href))
import urllib
import urllib.request as urlrequest
import json
import time
import random
import pandas as pd
df = pd.read_csv("top250_f1.csv",sep = "#", encoding = 'utf8')
urlsplit = df.url.str.split('/').apply(pd.Series)
id_list = list(urlsplit[4])
num=0
IP_list = [ ] #这里写几个可用的IP地址和端口号,只抓250个页面,有两三个IP就够了。
IP = random.chioce(IP_list)
with open('top250_f2.csv', 'w',encoding='utf8') as outputfile:
outputfile.write("num#rank#alt_title#title#pubdate#language#writer#director#cast#movie_duration#year#movie_type#tags#image\n")
proxy = urlrequest.ProxyHandler({
'https': 'IP'})
opener = urlrequest.build_opener(proxy)
opener.addheaders = [('User-Agent', 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_4)
AppleWebKit/603.1.30 (KHTML, like Gecko) Version/10.1 Safari/603.1.30')]
urlrequest.install_opener(opener)
for id in id_list:
url_visit = 'https://api.douban.com/v2/movie/{}'.format(id)
crawl_content = urlrequest.urlopen(url_visit).read()
json_content = json.loads(crawl_content.decode('utf-8'))
rank = json_content['rating']['average']
alt_title = json_content['alt_title']
image = json_content['image']
title = json_content['title']
pubdate = json_content['attrs']['pubdate']
language = json_content['attrs']['language']
try:
writer = json_content['attrs']['writer']
except:
writer = 'None'
director = json_content['attrs']['director']
cast = json_content['attrs']['cast']
movie_duration = json_content['attrs']['movie_duration']
year = json_content['attrs']['year']
movie_type = json_content['attrs']['movie_type']
tags = json_content['tags']
num = num +1
outputfile.write("{}#{}#{}#{}#{}#{}#{}#{}#{}#{}#{}#{}#{}#{}\n".format(num,rank,alt_title,title,pubdate,language,writer,
director,cast,movie_duration,year,movie_type,tags,image))
time.sleep(1)import numpy as ny
import pandas as pd
df_1 = pd.read_csv("top250_f1.csv",sep = "#", encoding = 'utf8')
df_1.head()| num | title | director | role | init_year | area | genre | rating_num | comment_num | comment | url | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 肖申克的救赎 | 弗兰克·德拉邦特 Frank Darabont | 蒂姆·罗宾斯 Tim Robbins | 1994 | 美国 | [‘犯罪 剧情’] | 9.6 | 861343 | 希望让人自由。 | https://movie.douban.com/subject/1292052/ |
| 1 | 2 | 霸王别姬 | 陈凯歌 Kaige Chen | 张国荣 Leslie Cheung | 1993 | 中国大陆 香港 | [‘剧情 爱情 同性’] | 9.5 | 618349 | 风华绝代。 | https://movie.douban.com/subject/1291546/ |
| 2 | 3 | 这个杀手不太冷 | 吕克·贝松 Luc Besson | 让·雷诺 Jean Reno | 1994 | 法国 | [‘剧情 动作 犯罪’] | 9.4 | 824694 | 怪蜀黍和小萝莉不得不说的故事。 | https://movie.douban.com/subject/1295644/ |
| 3 | 4 | 阿甘正传 | Robert Zemeckis | Tom Hanks | 1994 | 美国 | [‘剧情 爱情’] | 9.4 | 703838 | 一部美国近现代史。 | https://movie.douban.com/subject/1292720/ |
| 4 | 5 | 美丽人生 | 罗伯托·贝尼尼 Roberto Benigni | 罗伯托·贝尼尼 Roberto Beni…’] | 1997 | 意大利 | [‘剧情 喜剧 爱情 战争’] | 9.5 | 410615 | 最美的谎言。 | https://movie.douban.com/subject/1292063/ |
再看一下抓取单个页面的信息:
df_2 = pd.read_csv("top250_f2.csv",sep = "#", encoding = 'utf8')
df_2.head()| num | rank | alt_title | title | pubdate | language | writer | director | cast | movie_duration | year | movie_type | tags | image | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 9.6 | 肖申克的救赎 / 月黑高飞(港) | The Shawshank Redemption | [‘1994-09-10(多伦多电影节)’, ‘1994-10-14(美国)’] | [‘英语’] | [‘弗兰克·德拉邦特 Frank Darabont’, ‘斯蒂芬·金 Stephen King’] | [‘弗兰克·德拉邦特 Frank Darabont’] | [‘蒂姆·罗宾斯 Tim Robbins’, ‘摩根·弗里曼 Morgan Freeman’… | [‘142 分钟’] | [‘1994’] | [‘犯罪’, ‘剧情’] | [{‘count’: 178370, ‘name’: ‘经典’}, {‘count’: 15… | https://img3.doubanio.com/view/movie_poster_co… |
| 1 | 2 | 9.5 | 再见,我的妾 | 霸王别姬 | [‘1993-01-01(香港)’] | [‘汉语普通话’] | [‘芦苇 Wei Lu’, ‘李碧华 Lillian Lee’] | [‘陈凯歌 Kaige Chen’] | [‘张国荣 Leslie Cheung’, ‘张丰毅 Fengyi Zhang’, ‘巩俐 … | [‘171 分钟’] | [‘1993’] | [‘剧情’, ‘爱情’, ‘同性’] | [{‘count’: 109302, ‘name’: ‘经典’}, {‘count’: 54… | https://img3.doubanio.com/view/movie_poster_co… |
| 2 | 3 | 9.4 | 这个杀手不太冷 / 杀手莱昂 | Léon | [‘1994-09-14(法国)’] | [‘英语’, ‘意大利语’, ‘法语’] | [‘吕克·贝松 Luc Besson’] | [‘吕克·贝松 Luc Besson’] | [‘让·雷诺 Jean Reno’, ‘娜塔莉·波特曼 Natalie Portman’, … | [‘110分钟(剧场版)’, ‘133分钟(国际版)’] | [‘1994’] | [‘剧情’, ‘动作’, ‘犯罪’] | [{‘count’: 136989, ‘name’: ‘经典’}, {‘count’: 75… | https://img3.doubanio.com/view/movie_poster_co… |
| 3 | 4 | 9.4 | 阿甘正传 / 福雷斯特·冈普 | Forrest Gump | [‘1994-06-23(洛杉矶首映)’, ‘1994-07-06(美国)’] | [‘英语’] | [‘Eric Roth’, ‘Winston Groom’] | [‘Robert Zemeckis’] | [‘Tom Hanks’, ‘Robin Wright Penn’, ‘Gary Sinis… | [‘142 分钟’] | [‘1994’] | [‘剧情’, ‘爱情’] | [{‘count’: 165677, ‘name’: ‘励志’}, {‘count’: 12… | https://img1.doubanio.com/view/movie_poster_co… |
| 4 | 5 | 9.5 | 美丽人生 / 一个快乐的传说(港) | La vita è bella | [‘1997-12-20(意大利)’] | [‘意大利语’, ‘德语’, ‘英语’] | [‘文森佐·克拉米 Vincenzo Cerami’, ‘罗伯托·贝尼尼 Roberto B… | [‘罗伯托·贝尼尼 Roberto Benigni’] | [‘罗伯托·贝尼尼 Roberto Benigni’, ‘尼可莱塔·布拉斯基 Nicolet… | [‘116分钟’] | [‘1997’] | [‘剧情’, ‘喜剧’, ‘爱情’, ‘战争’] | [{‘count’: 66790, ‘name’: ‘意大利’}, {‘count’: 61… | https://img3.doubanio.com/view/movie_poster_co… |
都是250行信息。下面进行的数据清洗。
数据清洗
一般我们得到的数据是不可以直接使用的,里面可能存在重复值、缺失值、空值、
无效值、异常值、错误值,以及逻辑、格式不正确等的数据不一致问题。网上抓取来的数据更容易有这些问题,我们需要处理这些脏数据,转化成可供分析的数据。
数据分布在两个文件中,我们选取 top250_f1.csv 文件中的 num(排名)、 title(电影名)、 init_year(上映时间)、 area(国家/地区)、 genre(类型)、 rating_num(评分)、 comment_num(评价人数),和 top250_f2.csv 文件中的 language(语言)、 director(导演)、 cast(主演)、 movie_duration(时长)、 tags(标签)这些列进行分析,因此只对这些列中的脏数据做清洗工作。
先将这些列放到同一个DataFrame中:
df_1_cut = df_1[['num','title','init_year','area','genre','rating_num','comment_num']]
df_2_cut = df_2[['num','language','director','cast','movie_duration','tags']]
df = pd.merge(df_1_cut,df_2_cut,how = 'outer', on = 'num')
df.head()| num | title | init_year | area | genre | rating_num | comment_num | language | director | cast | movie_duration | tags | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 肖申克的救赎 | 1994 | 美国 | [‘犯罪 剧情’] | 9.6 | 861343 | [‘英语’] | [‘弗兰克·德拉邦特 Frank Darabont’] | [‘蒂姆·罗宾斯 Tim Robbins’, ‘摩根·弗里曼 Morgan Freeman’… | [‘142 分钟’] | [{‘count’: 178370, ‘name’: ‘经典’}, {‘count’: 15… |
| 1 | 2 | 霸王别姬 | 1993 | 中国大陆 香港 | [‘剧情 爱情 同性’] | 9.5 | 618349 | [‘汉语普通话’] | [‘陈凯歌 Kaige Chen’] | [‘张国荣 Leslie Cheung’, ‘张丰毅 Fengyi Zhang’, ‘巩俐 … | [‘171 分钟’] | [{‘count’: 109302, ‘name’: ‘经典’}, {‘count’: 54… |
| 2 | 3 | 这个杀手不太冷 | 1994 | 法国 | [‘剧情 动作 犯罪’] | 9.4 | 824694 | [‘英语’, ‘意大利语’, ‘法语’] | [‘吕克·贝松 Luc Besson’] | [‘让·雷诺 Jean Reno’, ‘娜塔莉·波特曼 Natalie Portman’, … | [‘110分钟(剧场版)’, ‘133分钟(国际版)’] | [{‘count’: 136989, ‘name’: ‘经典’}, {‘count’: 75… |
| 3 | 4 | 阿甘正传 | 1994 | 美国 | [‘剧情 爱情’] | 9.4 | 703838 | [‘英语’] | [‘Robert Zemeckis’] | [‘Tom Hanks’, ‘Robin Wright Penn’, ‘Gary Sinis… | [‘142 分钟’] | [{‘count’: 165677, ‘name’: ‘励志’}, {‘count’: 12… |
| 4 | 5 | 美丽人生 | 1997 | 意大利 | [‘剧情 喜剧 爱情 战争’] | 9.5 | 410615 | [‘意大利语’, ‘德语’, ‘英语’] | [‘罗伯托·贝尼尼 Roberto Benigni’] | [‘罗伯托·贝尼尼 Roberto Benigni’, ‘尼可莱塔·布拉斯基 Nicolet… | [‘116分钟’] | [{‘count’: 66790, ‘name’: ‘意大利’}, {‘count’: 61… |
通过 pd.merge()函数选出的 df_1_cut 和 df_2_cut 两张表,取并集,链接键为num。
看一下数据基本信息:
df.info()重复值检查
检查重复值可以用 duplicated() 函数,若返回值为“True”,则含有重复项,返回值为“False”,则不含重复项。 pd.Series.value_counts() 函数可以用来对series计数。
df.duplicated().value_counts()len(df.title.unique())len(df.num.unique())清洗数据格式、数据分列
粗略看一下,可以发现 genre,language,director,cast,movie_duration,tags列方括号、花括号和英文省略号等无效信息,需要去掉。
对于两侧的 [' '] 或 {[' ']} 形式,可以用str分割字符串。
df['genre'] = df['genre'].str[2:-2]
df['language'] = df['language'].str[2:-2]
df['director'] = df['director'].str[2:-2]
df['cast'] = df['cast'].str[2:-2]
df['movie_duration'] = df['movie_duration'].str[2:-2]
df['tags'] = df['tags'].str[3:-3]df.head()| num | title | init_year | area | genre | rating_num | comment_num | language | director | cast | movie_duration | tags | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 肖申克的救赎 | 1994 | 美国 | 犯罪 剧情 | 9.6 | 861343 | 英语 | 弗兰克·德拉邦特 Frank Darabont | 蒂姆·罗宾斯 Tim Robbins’, ‘摩根·弗里曼 Morgan Freeman’, … | 142 分钟 | count’: 178370, ‘name’: ‘经典’}, {‘count’: 15001… |
| 1 | 2 | 霸王别姬 | 1993 | 中国大陆 香港 | 剧情 爱情 同性 | 9.5 | 618349 | 汉语普通话 | 陈凯歌 Kaige Chen | 张国荣 Leslie Cheung’, ‘张丰毅 Fengyi Zhang’, ‘巩俐 Li… | 171 分钟 | count’: 109302, ‘name’: ‘经典’}, {‘count’: 54458… |
| 2 | 3 | 这个杀手不太冷 | 1994 | 法国 | 剧情 动作 犯罪 | 9.4 | 824694 | 英语’, ‘意大利语’, ‘法语 | 吕克·贝松 Luc Besson | 让·雷诺 Jean Reno’, ‘娜塔莉·波特曼 Natalie Portman’, ‘加… | 110分钟(剧场版)’, ‘133分钟(国际版) | count’: 136989, ‘name’: ‘经典’}, {‘count’: 75963… |
| 3 | 4 | 阿甘正传 | 1994 | 美国 | 剧情 爱情 | 9.4 | 703838 | 英语 | Robert Zemeckis | Tom Hanks’, ‘Robin Wright Penn’, ‘Gary Sinise’… | 142 分钟 | count’: 165677, ‘name’: ‘励志’}, {‘count’: 12412… |
| 4 | 5 | 美丽人生 | 1997 | 意大利 | 剧情 喜剧 爱情 战争 | 9.5 | 410615 | 意大利语’, ‘德语’, ‘英语 | 罗伯托·贝尼尼 Roberto Benigni | 罗伯托·贝尼尼 Roberto Benigni’, ‘尼可莱塔·布拉斯基 Nicoletta… | 116分钟 | count’: 66790, ‘name’: ‘意大利’}, {‘count’: 61289… |
对于 area 列,有些电影由多个国家或地区联合制作,例如《霸王别姬》电影:
df['area'][1]area_split = df['area'].str.split(' ').apply(pd.Series)
area_split.head()| 0 | 1 | 2 | 3 | 4 | |
|---|---|---|---|---|---|
| 0 | 美国 | NaN | NaN | NaN | NaN |
| 1 | 中国大陆 | 香港 | NaN | NaN | NaN |
| 2 | 法国 | NaN | NaN | NaN | NaN |
| 3 | 美国 | NaN | NaN | NaN | NaN |
| 4 | 意大利 | NaN | NaN | NaN | NaN |
可以看到最多为5个制作国家/地区,当然,大多数只有一个制片国家/地区。要了解哪个国家/地区的电影最受欢迎,就需要对国家进行统计。
对于这么多的空值,可以通过先按列计数,将空值 NaN 替换为“0”,再按行汇总。
a = area_split.apply(pd.value_counts).fillna('0')
a.columns = ['area_1','area_2','area_3','area_4','area_5']
a['area_1'] = a['area_1'].astype(int)
a['area_2'] = a['area_2'].astype(int)
a['area_3'] = a['area_3'].astype(int)
a['area_4'] = a['area_4'].astype(int)
a['area_5'] = a['area_5'].astype(int)
a = a.apply(lambda x: x.sum(),axis = 1)
area_c = pd.DataFrame(a, columns = ['counts'])area_c.head()| counts | |
|---|---|
| 中国大陆 | 15 |
| 丹麦 | 1 |
| 伊朗 | 2 |
| 加拿大 | 7 |
| 南非 | 2 |
以上过程也可以通过 unstack() 函数和 groupby() 函数来完成。 对 genre 列,我们使用这一方法。
genre_split = df['genre'].str.split(' ').apply(pd.Series)
genre_split.head()| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| 0 | 犯罪 | 剧情 | NaN | NaN | NaN | NaN |
| 1 | 剧情 | 爱情 | 同性 | NaN | NaN | NaN |
| 2 | 剧情 | 动作 | 犯罪 | NaN | NaN | NaN |
| 3 | 剧情 | 爱情 | NaN | NaN | NaN | NaN |
| 4 | 剧情 | 喜剧 | 爱情 | 战争 | NaN | NaN |
g = genre_split.apply(pd.value_counts)
g.head()| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| 传记 | 2.0 | 9.0 | NaN | NaN | 1.0 | NaN |
| 儿童 | 1.0 | 3.0 | 2.0 | NaN | NaN | NaN |
| 冒险 | 7.0 | 6.0 | 13.0 | 11.0 | 4.0 | 1.0 |
| 剧情 | 163.0 | 26.0 | 5.0 | NaN | NaN | NaN |
| 动作 | 16.0 | 16.0 | 2.0 | NaN | NaN | NaN |
通过 unstack 函数将行“旋转”为列,重排数据:
g.unstack().head()g = g.unstack().dropna().reset_index()
g.head()| level_0 | level_1 | 0 | |
|---|---|---|---|
| 0 | 0 | 传记 | 2.0 |
| 1 | 0 | 儿童 | 1.0 |
| 2 | 0 | 冒险 | 7.0 |
| 3 | 0 | 剧情 | 163.0 |
| 4 | 0 | 动作 | 16.0 |
g.columns = ['level_0','level_1', 'counts']
genre_c = g.drop(['level_0'],axis = 1).groupby('level_1').sum()genre_c.head()| counts | |
|---|---|
| level_1 | |
| 传记 | 12.0 |
| 儿童 | 6.0 |
| 冒险 | 42.0 |
| 剧情 | 194.0 |
| 动作 | 34.0 |
此时 counts 列即为电影类型的统计计数。
类似的方法来处理以下几项。
language 列:
language_split = df['language'].str.replace('\', \'',' ').str.split(' ').apply(pd.Series)
l = language_split.apply(pd.value_counts).stack().dropna().reset_index()
l.columns = ['level_0','level_1', 'counts']
language_c = l.groupby('level_0').sum()
language_c = language_c.drop(['level_1'],axis = 1)
language_c.head()| counts | |
|---|---|
| level_0 | |
| Ungwatsi | 1.0 |
| 上海话 | 4.0 |
| 世界语 | 1.0 |
| 丹麦语 | 3.0 |
| 乌克兰语 | 1.0 |
director 列:
director_split = df['director'].str.replace('\', \'','#').str.split('#').apply(pd.Series)
director_split.head()| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 弗兰克·德拉邦特 Frank Darabont | NaN | NaN |
| 1 | 陈凯歌 Kaige Chen | NaN | NaN |
| 2 | 吕克·贝松 Luc Besson | NaN | NaN |
| 3 | Robert Zemeckis | NaN | NaN |
| 4 | 罗伯托·贝尼尼 Roberto Benigni | NaN | NaN |
选取第一位导演作为分析对象:
director = director_split[0].str.strip()
df['director'] = directorcast_split = df['cast'].str.replace('\', \'','#').str.split('#').apply(pd.Series) #[[0,1,2,3]].columns=['performer_1','performer_2','performer_3','performer_4']
cast_split.head()| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | … | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 蒂姆·罗宾斯 Tim Robbins | 摩根·弗里曼 Morgan Freeman | 鲍勃·冈顿 Bob Gunton | 威廉姆·赛德勒 William Sadler | 克兰西·布朗 Clancy Brown | 吉尔·贝罗斯 Gil Bellows | 马克·罗斯顿 Mark Rolston | 詹姆斯·惠特摩 James Whitmore | 杰弗里·德曼 Jeffrey DeMunn | 拉里·布兰登伯格 Larry Brandenburg | … | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | 张国荣 Leslie Cheung | 张丰毅 Fengyi Zhang | 巩俐 Li Gong | 葛优 You Ge | 英达 Da Ying | 蒋雯丽 Wenli Jiang | 吴大维 David Wu | 吕齐 Qi Lü | 雷汉 Han Lei | 尹治 Zhi Yin | … | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 让·雷诺 Jean Reno | 娜塔莉·波特曼 Natalie Portman | 加里·奥德曼 Gary Oldman | 丹尼·爱罗 Danny Aiello | 彼得·阿佩尔 Peter Appel | 迈克尔·巴达鲁科 Michael Badalucco | 艾伦·格里尼 Ellen Greene | 伊丽莎白·瑞根 Elizabeth Regen | 卡尔·马图斯维奇 Carl J. Matusovich | 弗兰克·赛格 Frank Senger | … | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | Tom Hanks | Robin Wright Penn | Gary Sinise | Mykelti Williamson | Sally Field | Michael Conner Humphreys | Haley Joel Osment | NaN | NaN | NaN | … | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | 罗伯托·贝尼尼 Roberto Benigni | 尼可莱塔·布拉斯基 Nicoletta Braschi | 乔治·坎塔里尼 Giorgio Cantarini | 朱斯蒂诺·杜拉诺 Giustino Durano | 塞尔吉奥·比尼·布斯特里克 Sergio Bini Bustric | 玛丽莎·佩雷德斯 Marisa Paredes | 豪斯特·巴奇霍兹 Horst Buchholz | 利迪娅·阿方西 Lidia Alfonsi | 朱利亚娜·洛约迪切 Giuliana Lojodice | 亚美利哥·丰塔尼 Amerigo Fontani | … | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
5 rows × 44 columns
选取前六位演员作为分析对象。
c = cast_split[[0,1,2,3,4,5]] #.columns=['performer_1','performer_2','performer_3','performer_4','performer_5','performer_6']
c.columns=['performer_1','performer_2','performer_3','performer_4','performer_5','performer_6']
c = cast_split.unstack().dropna().reset_index()
c.head()| level_0 | level_1 | 0 | |
|---|---|---|---|
| 0 | 0 | 0 | 蒂姆·罗宾斯 Tim Robbins |
| 1 | 0 | 1 | 张国荣 Leslie Cheung |
| 2 | 0 | 2 | 让·雷诺 Jean Reno |
| 3 | 0 | 3 | Tom Hanks |
| 4 | 0 | 4 | 罗伯托·贝尼尼 Roberto Benigni |
c.columns=['level_0','level_1','performers']
c['performers'] = c['performers'].str.strip()
c.head()| level_0 | level_1 | performers | |
|---|---|---|---|
| 0 | 0 | 0 | 蒂姆·罗宾斯 Tim Robbins |
| 1 | 0 | 1 | 张国荣 Leslie Cheung |
| 2 | 0 | 2 | 让·雷诺 Jean Reno |
| 3 | 0 | 3 | Tom Hanks |
| 4 | 0 | 4 | 罗伯托·贝尼尼 Roberto Benigni |
演员表中有些人名中英文都标注了,有些只写了中文或英文名,例如“Tom Hanks”和“汤姆·汉克斯 Tom Hanks”是指一个人。下面的步骤是找出单独的中文或英文名,补全为中英两种语言的名字。
for i in c['performers']:
for j in c[c['performers'].str.contains(i)]['performers']:
if (len(j) > len(i)):
c[c['performers']==i] = j
else:
continuec['performers'].head()c = c.groupby('performers').count()c = c.drop(['level_0'], axis = 1)
c.columns = ['counts']
cast_c = c
cast_c.head()| counts | |
|---|---|
| performers | |
| 1326270 | 1 |
| 1976 (乐团) | 1 |
| Agnese Nano | 1 |
| Aldo Giuffrè | 1 |
| Alexandre Rodrigues | 1 |
movie_duration 列:
movie_duration_split = df['movie_duration'].str.strip().str.replace('\', \'','#').str.split('#').apply(pd.Series)
movie_duration_split.head()| 0 | 1 | 2 | 3 | 4 | 5 | |
|---|---|---|---|---|---|---|
| 0 | 142 分钟 | NaN | NaN | NaN | NaN | NaN |
| 1 | 171 分钟 | NaN | NaN | NaN | NaN | NaN |
| 2 | 110分钟(剧场版) | 133分钟(国际版) | NaN | NaN | NaN | NaN |
| 3 | 142 分钟 | NaN | NaN | NaN | NaN | NaN |
| 4 | 116分钟 | NaN | NaN | NaN | NaN | NaN |
有些电影时长存在多种版本,一般情况下第一个时长为国内最普通、观看数量较多的版本,因此仅取第一个时长。
duration = movie_duration_split[0].str.split('分').apply(pd.Series)[0].str.strip()
duration.head()duration.str.len().value_counts()duration[duration.str.len() > 3]duration[74] = duration[74].split(' ')[1]
duration[226] = duration[226].split(' ')[1]duration = duration.astype(int)
duration.dtypesdf['movie_duration'] = duration
df['movie_duration'].head()df.tags[0]tags_split = df['tags'].str.replace('count\': ',' ').str.replace(', \'name\': \'',' ').str.replace('\'}, {\'','').str.split(' ').apply(pd.Series)
tags_split.head()| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 178370 | 经典 | 150016 | 励志 | 131943 | 信念 | 117510 | 自由 | 90200 | 美国 | 82546 | 人性 | 61162 | 人生 | 53244 | 剧情 | |
| 1 | 109302 | 经典 | 54458 | 中国电影 | 53522 | 爱情 | 49358 | 文艺 | 46339 | 人性 | 45374 | 同志 | 37368 | 人生 | 28356 | 剧情 | |
| 2 | 136989 | 经典 | 75963 | 爱情 | 73361 | 温情 | 51532 | 人性 | 47454 | 剧情 | 36808 | 动作 | 31271 | 犯罪 | 19390 | 1994 | |
| 3 | 165677 | 励志 | 124126 | 经典 | 94060 | 美国 | 82929 | 人生 | 61445 | 信念 | 59325 | 成长 | 34048 | 剧情 | 24545 | 人性 | |
| 4 | 66790 | 意大利 | 61289 | 经典 | 60683 | 二战 | 58827 | 亲情 | 36662 | 战争 | 21463 | 温情 | 18881 | 爱情 | 18695 | 人性 |
删除“0”列:
del tags_split[0]
tags_split.head(2)| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 178370 | 经典 | 150016 | 励志 | 131943 | 信念 | 117510 | 自由 | 90200 | 美国 | 82546 | 人性 | 61162 | 人生 | 53244 | 剧情 |
| 1 | 109302 | 经典 | 54458 | 中国电影 | 53522 | 爱情 | 49358 | 文艺 | 46339 | 人性 | 45374 | 同志 | 37368 | 人生 | 28356 | 剧情 |
一般阅读习惯是先看标签类别,再看标签数量,调整一下位置比较便于阅读:
tags_split = tags_split.reindex(columns = [2,1,4,3,6,5,8,7,10,9,12,11,14,13,16,15])
tags_split.head(2)| 2 | 1 | 4 | 3 | 6 | 5 | 8 | 7 | 10 | 9 | 12 | 11 | 14 | 13 | 16 | 15 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 经典 | 178370 | 励志 | 150016 | 信念 | 131943 | 自由 | 117510 | 美国 | 90200 | 人性 | 82546 | 人生 | 61162 | 剧情 | 53244 |
| 1 | 经典 | 109302 | 中国电影 | 54458 | 爱情 | 53522 | 文艺 | 49358 | 人性 | 46339 | 同志 | 45374 | 人生 | 37368 | 剧情 | 28356 |
更改列名:
tags_split.columns = ['tags_1','tags_counts_1','tags_2','tags_counts_2','tags_3','tags_counts_3','tags_4','tags_counts_4','tags_5','tags_counts_5','tags_6','tags_counts_6','tags_7','tags_counts_7','tags_8','tags_counts_8']tags_split.head()| tags_1 | tags_counts_1 | tags_2 | tags_counts_2 | tags_3 | tags_counts_3 | tags_4 | tags_counts_4 | tags_5 | tags_counts_5 | tags_6 | tags_counts_6 | tags_7 | tags_counts_7 | tags_8 | tags_counts_8 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 经典 | 178370 | 励志 | 150016 | 信念 | 131943 | 自由 | 117510 | 美国 | 90200 | 人性 | 82546 | 人生 | 61162 | 剧情 | 53244 |
| 1 | 经典 | 109302 | 中国电影 | 54458 | 爱情 | 53522 | 文艺 | 49358 | 人性 | 46339 | 同志 | 45374 | 人生 | 37368 | 剧情 | 28356 |
| 2 | 经典 | 136989 | 爱情 | 75963 | 温情 | 73361 | 人性 | 51532 | 剧情 | 47454 | 动作 | 36808 | 犯罪 | 31271 | 1994 | 19390 |
| 3 | 励志 | 165677 | 经典 | 124126 | 美国 | 94060 | 人生 | 82929 | 信念 | 61445 | 成长 | 59325 | 剧情 | 34048 | 人性 | 24545 |
| 4 | 意大利 | 66790 | 经典 | 61289 | 二战 | 60683 | 亲情 | 58827 | 战争 | 36662 | 温情 | 21463 | 爱情 | 18881 | 人性 | 18695 |
有的电影给出了不同多家上映的时间,其中第一个最早,因此对于好几个年份的情况取第一个值。
year_split = df['init_year'].str.split('/').apply(pd.Series)[0].str.strip()
year_split = pd.to_datetime(year_split).dt.year
df['init_year'] = year_split
df['init_year'].head()缺失值检查
df[df.isnull().values == True]| num | title | init_year | area | genre | rating_num | comment_num | language | director | cast | movie_duration | tags |
|---|
没有缺失值。
关于 area_c 、 genre_c 、 language_c 、cast_c 、 tags_c 都经过缺失值处理,也不存在缺失值。
现在再来看一下基本信息:
df.info()数据分析
用 describe() 函数看一下数值型数据的统计信息:
df.describe()| num | init_year | rating_num | comment_num | movie_duration | |
|---|---|---|---|---|---|
| count | 250.000000 | 250.000000 | 250.00000 | 250.000000 | 250.00000 |
| mean | 125.500000 | 1998.248000 | 8.76360 | 240455.728000 | 121.61200 |
| std | 72.312977 | 15.491237 | 0.27637 | 146992.725348 | 29.96178 |
| min | 1.000000 | 1931.000000 | 8.20000 | 40150.000000 | 45.00000 |
| 25% | 63.250000 | 1994.000000 | 8.60000 | 133187.000000 | 99.25000 |
| 50% | 125.500000 | 2002.000000 | 8.70000 | 206992.000000 | 118.00000 |
| 75% | 187.750000 | 2009.000000 | 8.90000 | 305383.750000 | 136.00000 |
| max | 250.000000 | 2016.000000 | 9.60000 | 861343.000000 | 238.00000 |
在“豆瓣电影Top250”榜单中,上映时间最早为1931年,最晚为2016年;评分最低为8.2分,最高9.6分,平均分为8.76分;评论数量最低40150条,最高861343条;电影时长最短为45分钟,最长238分,平均时长121.61分钟,第一四分位书为99.25分钟,看来绝多数电影时长还是大于90分钟的。
总排名、按评分排名、按评价数量排名Top10
df[['num','title']].head(10)| num | title | |
|---|---|---|
| 0 | 1 | 肖申克的救赎 |
| 1 | 2 | 霸王别姬 |
| 2 | 3 | 这个杀手不太冷 |
| 3 | 4 | 阿甘正传 |
| 4 | 5 | 美丽人生 |
| 5 | 6 | 千与千寻 |
| 6 | 7 | 辛德勒的名单 |
| 7 | 8 | 泰坦尼克号 |
| 8 | 9 | 盗梦空间 |
| 9 | 10 | 机器人总动员 |
Top10_rating_num = df[['rating_num','title']].sort_values(by = ['rating_num'],ascending = False).head(10).reset_index()
Top10_rating_num.index = [1,2,3,4,5,6,7,8,9,10]
Top10_rating_num| index | rating_num | title | |
|---|---|---|---|
| 1 | 0 | 9.6 | 肖申克的救赎 |
| 2 | 51 | 9.6 | 控方证人 |
| 3 | 4 | 9.5 | 美丽人生 |
| 4 | 1 | 9.5 | 霸王别姬 |
| 5 | 2 | 9.4 | 这个杀手不太冷 |
| 6 | 3 | 9.4 | 阿甘正传 |
| 7 | 6 | 9.4 | 辛德勒的名单 |
| 8 | 25 | 9.4 | 十二怒汉 |
| 9 | 9 | 9.3 | 机器人总动员 |
| 10 | 40 | 9.3 | 海豚湾 |
Top10_comment_num = df[['comment_num','title']].sort_values(by = ['comment_num'],ascending = False).head(10).reset_index()
Top10_comment_num.index = [1,2,3,4,5,6,7,8,9,10]
Top10_comment_num| index | comment_num | title | |
|---|---|---|---|
| 1 | 0 | 861343 | 肖申克的救赎 |
| 2 | 2 | 824694 | 这个杀手不太冷 |
| 3 | 8 | 755328 | 盗梦空间 |
| 4 | 3 | 703838 | 阿甘正传 |
| 5 | 11 | 667516 | 三傻大闹宝莱坞 |
| 6 | 5 | 655541 | 千与千寻 |
| 7 | 7 | 647165 | 泰坦尼克号 |
| 8 | 1 | 618349 | 霸王别姬 |
| 9 | 78 | 605629 | 让子弹飞 |
| 10 | 10 | 594740 | 海上钢琴师 |
《申肖克的救赎》无论评分、评论人数还是总排名稳居榜首,居于第二位的《霸王别姬》的评分排名并列第三,评论数排名第8位,可见,总排名还有其他因素有关。
上榜次数最多导演
df['director'].value_counts().head()cast_c.sort_values(by = ['counts'], ascending = False).head(10)| counts | |
|---|---|
| performers | |
| 张国荣 Leslie Cheung | 8 |
| 汤姆·汉克斯 Tom Hanks | 7 |
| 梁朝伟 Tony Leung Chiu Wai | 7 |
| 布拉德·皮特 Brad Pitt | 7 |
| 张曼玉 Maggie Cheung | 7 |
| 莱昂纳多·迪卡普里奥 Leonardo DiCaprio | 7 |
| 琼·艾伦 Joan Allen | 6 |
| 雨果·维文 Hugo Weaving | 6 |
| 马特·达蒙 Matt Damon | 6 |
| 拉尔夫·费因斯 Ralph Fiennes | 5 |
上榜次数最多的演员是“张国荣 Leslie Cheung”,高达8次,这也是每年大家对他纪念的一个原因吧,这么多经典的作品,永远被铭记。
排名与评分的关系
import matplotlib.pyplot as plt
import matplotlib
%matplotlib inline
matplotlib.rcParams['font.family'] = 'SimHei' #配置中文字体
matplotlib.rcParams['font.size'] = 15 # 更改默认字体大小 plt.scatter(df['rating_num'], df['num']) #绘制散点图
plt.xlabel('rating_num') #x轴标签
plt.ylabel('ranking list') #y轴标签

排名越靠前,即num越小,分数越高,但看着有些别扭,因为我们习惯了排名靠前的在 y 轴的上方,可以用 invert_yaxis() 函数来改变 y 轴标签的顺序。
plt.figure(figsize=(14,6))
plt.subplot(1,2,1)
plt.scatter(df['rating_num'], df['num'])
plt.xlabel('rating_num')
plt.ylabel('ranking list')
plt.gca().invert_yaxis()
plt.subplot(1,2,2)
plt.hist(df['rating_num'],bins = 15)
plt.xlabel('rating_num')
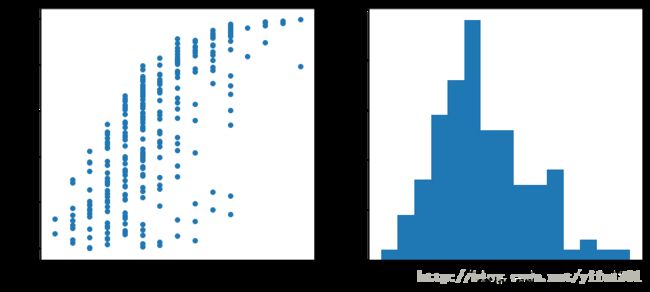
df['num'].corr(df['rating_num'])-0.69514425033437766
豆瓣评分大多是集中在 8.3 - 9.2 之间,随评分的升高,豆瓣Top250排名名次大致提前,Pearson相关系数为 -0.6951 ,呈强相关性。
排名与评论人数的关系
plt.figure(figsize=(14,6))
plt.subplot(1,2,1)
plt.scatter(df['comment_num'], df['num'])
plt.xlabel('comment_num')
plt.ylabel('ranking list')
plt.gca().invert_yaxis()
plt.subplot(1,2,2)
plt.hist(df['comment_num'])
plt.xlabel('comment_num')

df['num'].corr(df['comment_num'])-0.66233823687751237
评价人数呈右偏分布,随评价人数的增多,豆瓣Top250排名名次有提前趋势,Pearson相关系数为 -0.6623 ,呈强相关性。
排名与电影时长的关系
plt.figure(1)
plt.figure(figsize=(14,6))
plt.subplot(1,2,1)
plt.scatter(df['movie_duration'], df['num'])
plt.xlabel('movie_duration')
plt.ylabel('ranking list')
plt.gca().invert_yaxis()
plt.subplot(1,2,2)
plt.hist(df['movie_duration'],bins = 50)
plt.xlabel('movie_duration')
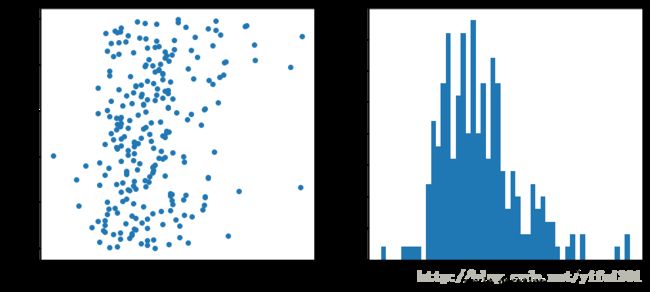
df['num'].corr(df['movie_duration'])-0.24202220203968391
电影时长多数集中在 80-120 分钟之间,与豆瓣电影Top250之间关系不大,Pearson相关系数为 -0.2420 ,为弱相关性。
排名与上映年份的关系
plt.figure(1)
plt.figure(figsize=(14,6))
plt.subplot(1,2,1)
plt.scatter(df['init_year'], df['num'])
plt.xlabel('init_year')
plt.ylabel('ranking list')
plt.gca().invert_yaxis()
plt.subplot(1,2,2)
plt.hist(df['init_year'],bins = 30)
plt.xlabel('init_year')
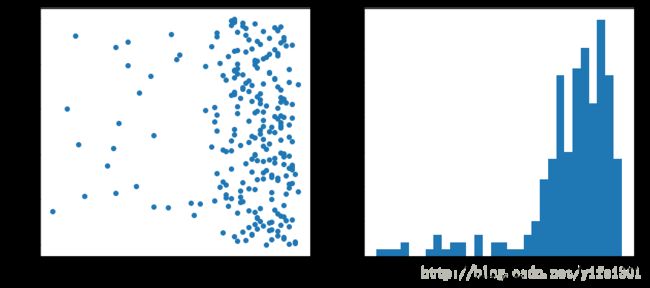
df['num'].corr(df['init_year'])0.086228239751655111
上映年份多数其中在1990年之后,pearson相关系数为0.0862,与豆瓣电影Top250没有相关性。
国家/地区
area_c.sort_values(by = 'counts',ascending = False).plot(kind ='bar', figsize = (6,6))
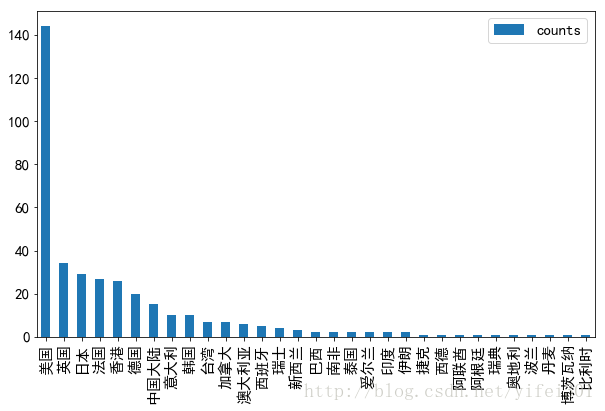
上榜电影中,美国电影数量最多,中国大陆排第七位。
语言
language_c.sort_values(by = 'counts',ascending = False)[:30].plot(kind ='bar', figsize = (10,6))
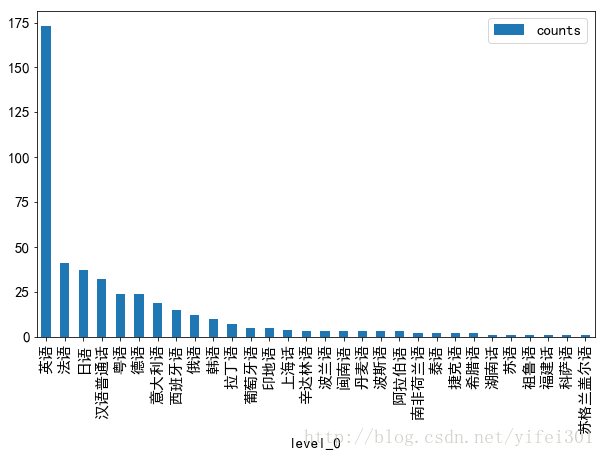
上榜电影使用最多的语言为英语,汉语普通话排第四位。
电影类型
genre_c.sort_values(by = 'counts',ascending = False).plot(kind ='bar', figsize = (6,6))
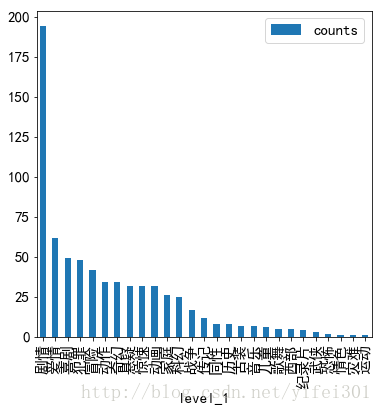
最多的电影类型是剧情,其次是爱情。
电影标签
标签比较多,用WordCloud制作词云:
from wordcloud import WordCloud
text = tags_split[['tags_1','tags_2','tags_3','tags_4','tags_5','tags_6','tags_7','tags_8']].to_string(header=False, index=False )
wordcloud = WordCloud(font_path='msyh.ttf',background_color='white',width=5000, height=3000, margin=2).generate(text)
plt.figure(figsize=(16,8))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
结论
豆瓣电影Top250排行榜和电影评分及评论人数有强相关性,和上映时间无相关性。
剧情、爱情、喜剧、犯罪、冒险类型的电影上榜较多。常用标签为“美国”、“剧情”、“经典”、“人性”、“爱情”。
美国的电影最受欢迎,用的最多的语言是英语。
上榜次数最多的导演是“克里斯托弗·诺兰 Christopher Nolan”和“宫崎骏 Hayao Miyazaki ”,同为7次。
上榜次数最多的主演是“张国荣 Leslie Cheung”,高达8次。
片长和排名关系不大,多数集中在80-120之间。
—————————————————————————————————————————————————————————————————————
后记:
本文只做了初步的分析,如果您感兴趣,还可以继续深挖,例如抓一下标注“看过”的人数,用机器学习的方法看一下评分、评价人数、“看过”人数与Top250的排名关系,等等等等。
本文从头到尾只用了Python语言,其实完全可以选择其他工具,或者多种工具同时使用,所谓“黑猫白猫,抓到老鼠就是好猫”。