IPFS星际文件系统(中文白皮书)
IPFS - 可快速索引的版本化的点对点文件系统
作者: Juan Benet ([email protected])
译者: 郭光华([email protected])
摘要
星际文件系统是一种点对点的分布式文件系统, 旨在连接所有有相同的文件系统的计算机设备。在某些方面, IPFS类似于web, 但web 是中心化的,而IPFS是一个单一的Bittorrent 群集, 用git 仓库分布式存储。换句话说, IPFS 提供了高吞吐量的内容寻址块存储模型, 具有内容寻址的超链接。这形成了一个广义的Merkle DAG 数据结构,可以用这个数据结构构建版本文件系统,区块链,甚至是永久性网站。。IPFS 结合了分布式哈希表, 带有激励机制的块交换和自我认证命名空间。IPFS 没有单故障点, 节点不需要相互信任。
1. 介绍
在全球分布式文件系统这领域, 已经有许多人的尝试。一些系统已经取得了重大的成功, 而很多却完全失败了。在学术尝试中, AFS【6】就是成功的例子,如今已经得到广泛的应用, 然而,其他的【7, ?】却没有得到相同的结果。在学术界之外,应用最广泛的是面向音视频媒体的点对点文件共享系统。 最值得注意的是, Napster, KaZaA 和BitTorrent[2]部署的文件分发系统支持1亿用户的同时在线。即使在今天, BitTorrent 也维持着每天千万节点的活跃数。 基于这些学术文件系统理论而实现的应用程序有很多的用户量, 然而,这些系统理论是在应用层,而没有放在基础层。以致没有出现通用的文件系统基础框架, 给全球提供低延迟的分发。
也许是因为HTTP这样“足够好“的系统已经存在。到目前为止,HTTP已经作为“分布式文件系统“的协议,并且已经大量部署,再与浏览器相结合,具有巨大的技术和社会影响力。在现在, 它已经成为互联网传输文件的事实标准。然而,他没有采用最近15年的发明的数十种先进的文件分发技术。 从一方面讲, 由于向后兼容的限制 和 当前新模式的投入, 不断发展http web 的基础设施几乎是不可能的。但从一个角度看, 从http 出现以来, 已经有许多新协议出现并被广泛使用。升级http协议虽然能引入新功能和加强当前http协议,但会降低用户的体验。
有些行业已经摆脱使用HTTP 这么久, 因为移动小文件相对便宜,即使对拥有大流量的小组织也是如此。但是,随着新的挑战,我们正在进入数据分发的新纪元。
- (a)托管和分发PB级数据集,
- (b)跨组织的大数据计算,
- (c)大批量的高清晰度按需或实时媒体流,
- (d)大规模数据集的版本化和链接,
- (e)防止意外丢失重要文件等。其中许多可以归结为“大量数据,无处不在”。由于关键功能和带宽问题,我们已经为不同的数据放弃了HTTP 分销协议。下一步是使它们成为web自己的一部分。
正交于有效的数据分发,版本控制系统,已经设法开发重要的数据协作工作流程。Git是分布式源代码版本控制系统,开发了许多有用的方法来建模和实现分布式数据操作。Git工具链提供了灵活的版本控制功能,这正是大量的文件分发系统所严重缺乏的。由Git启发的新解决方案正在出现,如Camlistore [?],个人文件存储系统,Dat [?]数据协作工具链和数据集包管理器。Git已经影响了分布式文件系统设计[9],因为其内容涉及到Merkle DAG数据模型,能够实现强大的文件分发策略。还有待探讨的是,这种数据结构如何影响面向高吞吐量的文件系统的设计,以及如何升级Web本身。
本文介绍了IPFS,一种新颖的对等版本控制的文件系统,旨在调和这些问题。 IPFS综合了许多以前成功的系统的优点。 IPFS产生了突出的效果, 甚至比参考的这些系统的总和还要好。IPFS的核心原则是将所有数据建模为同一Merkle DAG的一部分。
2.1 分布式哈希表(DHT)
分布式散列表(DHT)被广泛用于协调和维护关于对等系统的元数据。比如,MainlineDHT 是一个去中心化哈希表,他可追踪查找所有的对等节点。
2.1.1 Kademlia DHT
Kademlia[10] 是受欢迎的DHT, 它提供:
- 1.通过大量网络进行高效查询:查询平均联系人O(log2N)节点。 (例如,20跳10万个节点的网络)
- 2.低协调开销:优化数量的控制消息发送到其他节点。
- 3.抵抗各种攻击,喜欢长寿节点。
- 4.在对等应用中广泛使用,包括Gnutella和BitTorrent,形成了超过2000万个节点的网络[16]。
2.1.2 Coral DSHT
虽然一些对等文件系统直接在DHT中存储数据块,这种“数据存储在不需要的节点会乱费存储和带宽”[5]。Coral DSHT扩展了Kademlia三个特别重要的方式:
- 1.Kademlia在ids为“最近”(使用XOR-distance)的关键节点中存储值。这不考 虑应用程序数据的局部性,忽略“远”可能已经拥有数据的节点,并强制“最近”节点存储它,无论它们是否需要。这浪费了大量的存储和带宽。相反,Coral 存储了地址, 该地址的对等节点可以提供相应的数据块。
- 2.Coral将DHT API从get_value(key)换成了get_any_values(key)(DSHT中的“sloppy”)中。这仍然是因为Coral用户只需要一个(工作)的对等体,而不是完整的列表。作为回报,Coral可以仅将子集分配到“最近”的节点,避免热点(当密钥变得流行时,重载所有最近的节点)。
- 3.另外,Coral根据区域和大小组织了一个称为群集的独立DSHT层次结构。这使得节点首先查询其区域中的对等体,“查找附近的数据而不查询远程节点”[5]并大大减少查找的延迟。
2.1.3 S/Kademlia DHT
S/Kademlia[1] 扩展了Kademlia, 用于防止恶意的攻击。有如下两方面的方法:
1.S/Kad 提供了方案来保证NodeId的生成已经防止Sybill攻击。它需要节点产生PKI公私钥对。从中导出他们的身份,并彼此间签名。一个方案使用POW工作量证明,使得生成Sybills成本高昂。
2.S/Kad 节点在不相交的路径上查找直, 即使网络中存在大量的不诚实节点,也能确保诚实节点可以互相链接。即使网络中存在一半的不诚实节点,S/Kad 也能达到85%的成功率。
2.2 块交换 - BitTorrent
BitTorrent[3] 是一个广泛成功应用的点对点共享文件系统,它可以在存在不信任的对等节点(群集)的协作网络中分发各自的文件数据片。从BitTorrent和它的生态系统的关键特征, IPFS得到启示如下:
- 1.BitTorrent的数据交换协议使用了一种bit-for-tat的激励策略, 可以奖励对其他方面做贡献的节点,惩罚只榨取对方资源的节点。
- 2.BitTorrent对等体跟踪文件的可用性,优先发送稀有片段。这减轻了seeds节点的负担, 让non-seeds节点有能力互相交易。
- 3.对于一些剥削带宽共享策略, BitTorrent的标准tit-for-tat策略是非常脆弱的。 然而,PropShare[8]是一种不同的对等带宽分配策略, 可以更好的抵制剥削战略, 提高群集的表现。
2.3. 版本控制系统- Git
版本控制系统提供了对随时间变化的文件进行建模的设施,并有效地分发不同的版本。流行版本控制系统Git提供了强大的Merkle DAG对象模型,以分布式友好的方式捕获对文件系统树的更改。
- 1.不可更改的对象表示文件(blob),目录(树)和更改(提交)。
- 2.通过加密hash对象的内容,让对象可寻址。
- 3.链接到其他对象是嵌入的,形成一个Merkle DAG。这提供了很多有用的完整和work-flow属性。
- 4.很多版本元数据(分支,标示等等)都只是指针引用,因此创建和更新的代价都小。
- 5.版本改变只是更新引用或者添加对象。
- 6.分布式版本改变对其他用户而言只是转移对象和更新远程引用。
2.4 自我认证认文件系统-SFS
SFS [ 12,11 ]提出了两个引人注目的实现(a)分布式信任链,和(b)平等共享的全局命名空间。SFS引入了一种自我建构技术—注册文件:寻址远程文件系统使用以下格式:
| 1 2 3 |
/sfs/ Location:代表的是服务网络地方 HostID = hash(public_key || Location) |
因此SFS文件系统的名字认证了它的服务,用户可以通过服务提供的公钥来验证,协商一个共享的私钥,保证所有的通信。所有的SFS实例都共享了一个全局的命名空间,这个命名空间的名称分配是加密的,不被任何中心化的body控制。
3. IPFS设计
IPFS是一个分布式文件系统,它综合了以前的对等系统的成功想法,包括DHT,BitTorrent,Git和SFS。 IPFS的贡献是简化,发展和将成熟的技术连接成一个单一的内聚系统,大于其部分的总和。 IPFS提供了编写和部署应用程序的新平台,以及一个新的分发系统版本化大数据。 IPFS甚至可以演进网络本身。
IPFS是点对点的;没有节点是特权的。 IPFS节点将IPFS对象存储在本地存储中。节点彼此连接并传输对象。这些对象表示文件和其他数据结构。 IPFS协议分为一组负责不同功能的子协议:
1. 身份 - 管理节点身份生成和验证。描述在3.1节。
2.网络 - 管理与其他对等体的连接,使用各种底层网络协议。可配置的。详见3.2节。
3.路由 - 维护信息以定位特定的对等体和对象。响应本地和远程查询。默认为DHT,但可更换。在3.3节描述。
4.交换 - 一种支持有效块分配的新型块交换协议(BitSwap)。模拟市场,弱化数据复制。贸易策略可替换。描述在3.4节。
5.对象 - 具有链接的内容寻址不可更改对象的Merkle DAG。用于表示任意数据结构,例如文件层次和通信系统。详见第3.5节。
6.文件 - 由Git启发的版本化文件系统层次结构。详见3.6节。
7.命名 - 自我认证的可变名称系统。详见3.7节。
这些子系统不是独立的;它们是集成在一起,互相利用各自的属性。但是,分开描述它们是有用的,从下到上构建协议栈。符号:Go语言中指定了以下数据结构和功能
3.1 身份
节点由NodeId标识,这是使用S / Kademlia的静态加密难题[1]创建的公钥的密码散列。节点存储其公私钥(用密码加密)。用户可以在每次启动时自由地设置一个“新”节点身份,尽管这会损失积累的网络利益。激励节点保持不变。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
type NodeId Multihash type Multihash []byte // 自描述加密哈希摘要 type PublicKey []byte type PrivateKey []byte // 自描述的私钥 type Node struct { NodeId NodeID PubKey PublicKey PriKey PrivateKey } 基于S / Kademlia的IPFS身份生成: difficulty = n = Node{} do { n.PubKey, n.PrivKey = PKI.genKeyPair() n.NodeId = hash(n.PubKey) p = count_preceding_zero_bits(hash(n.NodeId)) } while (p < difficulty) |
首次连接时,对等体交换公钥,并检查:hash(other.PublicKey)等于other.NodeId。如果没有,则连接被终止
关于加密函数的注意事项:
IPFS不是将系统锁定到一组特定的功能选择,而是支持自我描述的值。哈希摘要值以多重哈希格式存储,其包括指定使用的哈希函数的头和以字节为单位的摘要长度。例如:
| 1 |
|
这允许系统
- (a)选择最佳功能用例(例如,更强的安全性与更快的性能),
- (b)随着功能选择的变化而演变。自描述值允许兼容使用不同的参数选择。
3.2 网络
IPFS节点与数百个其他节点进行定期通信网络中的节点,可能跨越广域网络。IPFS网络堆栈功能:
- 传输层: IPFS可以使用任何传输协议,并且最适合WebRTC DataChannels [?](用于浏览器连接)或uTP(LEDBAT [14])。
- 可靠性: 如果底层网络不提供可靠性,IPFS可使用uTP(LEDBAT [14])或SCTP [15]来提供可靠性。
- 可连接性:IPFS还可以使用ICE NAT穿墙打洞技术[13]。
- 完整性:可以使用哈希校验和来检查邮件的完整性。
- 可验证性:可以使用发送者的公钥使用HMAC来检查消息的真实性。
3.2.1对等节点寻址注意事项:
IPFS可以使用任何网络; 但它不承担对IP的获取以及不直接依赖于ip层。这允许在覆盖网络中使用IPFS。
IPFS将地址存储为多层地址,这个多层地址是由字节字符串组成的, 以便于给底层网络使用。多层地址提供了一种方式来表示地址及其协议,可以封装成好解析的格式。例如:
| 1 2 3 4 |
# an SCTP/IPv4 connection /ip4/10.20.30.40/sctp/1234/ # an SCTP/IPv4 connection proxied over TCP/IPv4 /ip4/5.6.7.8/tcp/5678/ip4/1.2.3.4/sctp/1234/ |
3.3 路由
IPFS节点需要一个路由系统, 这个路由系统可用于查找:
- (a)其他同伴的网络地址,
- (b)专门用于服务特定对象的对等节点。
IPFS使用基于S / Kademlia和Coral的DSHT,在2.1节中具体介绍过。在对象大小和使用模式方面, IPFS 类似于Coral[5] 和Mainline[16], 因此,IPFS DHT根据其大小对存储的值进行区分。小的值(等于或小于1KB)直接存储在DHT上。对于更大的值,DHT只存储值索引,这个索引就是一个对等节点的NodeId, 该对等节点可以提供對该类型的值的具体服务。
DSHT的接口如下:
| 1 2 3 4 5 6 7 |
type IPFSRouting interface { FindPeer(node NodeId) // 获取特定NodeId的网络地址。 SetValue(key []bytes, value []bytes) // 往DHT存储一个小的元数据。 GetValue(key []bytes) // 从DHT获取元数据。 ProvideValue(key Multihash) // 声明这个节点可一个提供一个大的数据。 FindValuePeers(key Multihash, min int) // 获取服务于该大数据的节点。 } |
注意:不同的用例将要求基本不同的路由系统(例如广域网中使用DHT,局域网中使用静态HT)。因此,IPFS路由系统可以根据用户的需求替换的。只要使用上面的接口就可以了,系统都能继续正常运行。
3.4块交换 - BitSwap协议
IPFS 中的BitSwap协议受到BitTorrent 的启发,通过对等节点间交换数据块来分发数据的。像BT一样, 每个对等节点在下载的同时不断向其他对等节点上传已下载的数据。和BT协议不同的是, BitSwap 不局限于一个torrent文件中的数据块。BitSwap 协议中存在一个永久的市场。 这个市场包括各个节点想要获取的所有块数据。而不管这些块是哪些如.torrent文件中的一部分。这些快数据可能来自文件系统中完全不相关的文件。 这个市场是由所有的节点组成的。
虽然易货系统的概念意味着可以创建虚拟货币,但这将需要一个全局分类账本来跟踪货币的所有权和转移。这可以实施为BitSwap策略,并将在未来的论文中探讨。
在基本情况下,BitSwap节点必须以块的形式彼此提供直接的值。只有当跨节点的块的分布是互补的时候,各取所需的时候,这才会工作的很好。 通常情况并非如此,在某些情况下,节点必须为自己的块而工作。 在节点没有其对等节点所需的(或根本没有的)情况下,它会更低的优先级去寻找对等节点想要的块。这会激励节点去缓存和传播稀有片段, 即使节点对这些片段不感兴趣。
3.4.1 - BitSwap 信用
这个协议必须带有激励机制, 去激励节点去seed 其他节点所需要的块,而它们本身是不需要这些块的。 因此, BitSwap的节点很积极去给对端节点发送块,期待获得报酬。但必须防止水蛭攻击(空负载节点从不共享块),一个简单的类似信用的系统解决了这些问题:
- 1, 对等节点间会追踪他们的平衡(通过字节认证的方式)。
- 2, 随着债务增加而概率降低,对等者概率的向债务人发送块。
注意的是,如果节点决定不发送到对等体,节点随后忽略对等体的ignore_cooldown超时。 这样可以防止发送者尝试多次发送(洪水攻击) (BitSwap默认是10秒)。
3.4.2 BitSwap的策略
BitSwap 对等节点采用很多不同的策略,这些策略对整个数据块的交换执行力产生了不同的巨大影响。在BT 中, 标准策略是明确规定的(tit-for-tat),其他不同的策略也已经被实施,从BitTyrant [8](尽可能分享)到BitThief [8](利用一个漏洞,从不共享),到PropShare [8](按比例分享)。BitSwap 对等体可以类似地实现一系列的策略(良好和恶意)。对于功能的选择,应该瞄准:
- 1.为整个交易和节点最大化交易能力。
- 2.为了防止空负载节点利用和损害交易。
- 3.高效抵制未知策略。
- 4.对可信任的对等节点更宽容。
探索这些策略的空白是未来的事情。在实践中使用的一个选择性功能是sigmoid,根据负债比例进行缩放:
让负债比例在一个节点和它对等节点之间:
| 1 |
r = bytes_sent / bytes_recv + 1 |
根据r,发送到负债节点的概率为:
| 1 |
P(send | r ) = 1 − ( 1/ ( 1 + exp(6 − 3r) ) ) |
正如你看到的图片1,当节点负债比例超过节点已建立信贷的两倍,发送到负债节点的概率就会急速下降。
图片1 当r增加时发送的概率
负债比是信任的衡量标准:对于之前成功的互换过很多数据的节点会宽容债务,而对不信任不了解的节点会严格很多。这个(a)给与那些创造很多节点的攻击者(sybill 攻击)一个障碍。(b)保护了之前成功交易节点之间的关系,即使这个节点暂时无法提供数据。(c)最终阻塞那些关系已经恶化的节点之间的通信,直到他们被再次证明。
3.4.3 BitSwap 账本
BitSwap节点保存了一个记录与所有其他节点之间交易的账本。这个可以让节点追踪历史记录以及避免被篡改。当激活了一个链接,BitSwap节点就会互换它们账本信息。如果这些账本信息并不完全相同,分类账本将会重新初始化, 那些应计信贷和债务会丢失。 恶意节点会有意去失去“这些“账本, 从而期望清除自己的债务。节点是不太可能在失去了应计信托的情况下还能累积足够的债务去授权认证。伙伴节点可以自由的将其视为不当行为, 拒绝交易。
| 1 2 3 4 5 6 7 |
type Ledger struct { owner NodeId partner NodeId bytes_sent int bytes_recv int timestamp Timestamp } |
节点可以自由的保留分布式账本历史,这不需要正确的操作,因为只有当前的分类账本条目是有用的。节点也可以根据需要自由收集分布式帐本,从不太有用的分布式帐开始:老(其他对等节点可能不存在)和小。
3.4.4 BitSwap 详解
BitSwap 节点有以下简单的协议。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
// Additional state kept type BitSwap struct { ledgers map[NodeId]Ledger // Ledgers known to this node, inc inactive active map[NodeId]Peer // currently open connections to other nodes need_list []Multihash // checksums of blocks this node needs have_list []Multihash // checksums of blocks this node has } type Peer struct { nodeid NodeId ledger Ledger // Ledger between the node and this peer last_seen Timestamp // timestamp of last received message want_list []Multihash // checksums of all blocks wanted by peer // includes blocks wanted by peer's peers } // Protocol interface: interface Peer { open (nodeid : NodeId, ledger : Ledger); send_want_list (want_list : WantList); send_block(block: Block) -> (complete:Bool); close(final: Bool); } |
对等连接的生命周期草图:
- 1.Open: 对等节点间发送ledgers 直到他们同意。
- 2.Sending: 对等节点间交换want_lists 和blocks。
- 3.Close: 对等节点断开链接。
- 4.Ignored: (特殊)对等体被忽略(等待时间的超时)如果节点采用防止发送策略。
Peer.open(NodeId, Ledger).
当发生链接的时候,节点会初始化链接的账本,要么保存一个份链接过去的账本,要么创建一个新的被清零的账本。然后,发送一个携带账本的open信息给对等节点。
接收到一个open信息之后,对等节点可以选择是否接受此链接。如果,根据接收者的账本,发送者是一个不可信的代理(传输低于零或者有很大的未偿还的债务),接收者可能会选择忽略这个请求。忽略请求是ignore_cooldown超时来概率性实现的,为了让错误能够有时间改正和攻击者被挫败。
如果链接成功,接收者用本地账本来初始化一个Peer对象以及设置last_seen时间戳。然后,它会将接受到的账本与自己的账本进行比较。如果两个账本完全一样,那么这个链接就被Open,如果账本并不完全一致,那么此节点会创建一个新的被清零的账本并且会发送此账本。
Peer.send_want_list(WantList)
当链接已经Open的时候,节点会广发它们的want_list给所有已经链接的对等节点。这个是在(a)open链接后(b)随机间歇超时后(c)want_list改变后(d)接收到一个新的块之后完成的。
当接收到一个want_list之后,节点会存储它。然后,会检查自己是否拥有任何它想要的块。如果有,会根据上面提到的BitSwap策略来将want_list所需要的块发送出去。
Peer.send_block(Block)
发送一个块是直接了当的。节点只是传输数据块。当接收到了所有数据的时候,接收者会计算多重hash校验和来验证它是否是自己所需数据,然后发送确认信息。
在完成一个正确的块传输之后,接受者会将此块从need_list一到have_list,最后接收者和发送者都会更新它们的账本来反映出传输的额外数据字节数。
如果一个传输验证失败了,发送者要么会出故障要么会攻击接收者,接收者可以选择拒绝后面的交易。注意,BitSwap是期望能够在一个可靠的传输通道上进行操作的,所以传输错误(可能会引起一个对诚实发送者错误的惩罚)是期望在数据发送给BitSwap之前能够被捕捉到。
Peer.close(Bool)
传给close最后的一个参数,代表close链接是否是发送者的意愿。如果参数值为false,接收者可能会立即重新open链接,这避免链过早的close链接。
一个对等节点close链接发生在下面两种情况下: - silence_wait超时已经过期,并且没有接收到来自于对等节点的任何信息(BitSwap默认使用30秒),节点会发送Peer.close(false)。
在节点退出和BitSwap关闭的时候,节点会发送Peer.close(true).
接收到close消息之后,接收者和发送者会断开链接,清除所有被存储的状态。账本可能会被保存下来为了以后的便利,当然,只有在被认为账本以后会有用时才会被保存下来。
注意点:
非open信息在一个不活跃的连接上应该是被忽略的。在发送send_block信息时,接收者应该检查这个块,看它是否是自己所需的,并且是否是正确的,如果是,就使用此块。总之,所有不规则的信息都会让接收者触发一个close(false)信息并且强制性的重初始化此链接。
3.5 Merkle DAG对象
DHT和BitSwap允许IPFS构造一个庞大的点对点系统用来快速稳定的分发和存储。最主要的是,IPFS建造了一个Merkle DAG,一个无回路有向图,对象之间的links都是hash加密嵌入在源目标中。这是Git数据结构的一种推广。Merkle DAGS给IPFS提供了很多有用的属性,包括:
- 1.内容可寻址:所有内容都是被多重hash校验和来唯一识别的,包括links。
- 2.防止篡改:所有的内容都用它的校验和来验证。如果数据被篡改或损坏,IPFS会检测到。
- 3.重复数据删除:所有的对象都拥有相同的内容并只存储一次。这对于索引对象非常有用,比如git的tree和commits,或者数据的公共部分。
IPFS对象的格式是:
| 1 2 3 4 5 6 7 8 9 10 |
type IPFSLink struct { Name string // 此link的别名 Hash Multihash // 目标的加密hash Size int // 目标总大小 } type IPFSObject struct { links []IPFSLink //links数组 data []byte //不透明内容数据 } |
IPFS Merkle DAG是存储数据非常灵活的一种方式。只要求对象引用是(a)内容可寻址的,(b)用上面的格式编码。IPFS允许应用完全的掌控数据域;应用可以使用任何自定义格式的数据,即使数据IPFS都无法理解。单独的内部对象link表允许IPFS做:
- 用对象的形式列出所有对象引用,例如:
1
2
3
4
5
6
> ipfs ls /XLZ1625Jjn7SubMDgEyeaynFuR84ginqvzb
XLYkgq61DYaQ8NhkcqyU7rLcnSa7dSHQ16x 189458 less
XLHBNmRQ5sJJrdMPuu48pzeyTtRo39tNDR5 19441 script
XLF4hwVHsVuZ78FZK6fozf8Jj9WEURMbCX4 5286 template
- 解决字符串路经查找,例如foo/bar/baz。给出一个对象,IPFS会解析第一个路经成分进行hash放入到对象的link表中,再获取路径的第二个组成部分,一直如此重复下去。因此,任何数据格式的字符串路经都可以在Merkle DAG中使用。
*递归性的解决所有对象引用:1
2
3
4
5
6
> ipfs refs --recursive \
/XLZ1625Jjn7SubMDgEyeaynFuR84ginqvzb
XLLxhdgJcXzLbtsLRL1twCHA2NrURp4H38s
XLYkgq61DYaQ8NhkcqyU7rLcnSa7dSHQ16x
XLHBNmRQ5sJJrdMPuu48pzeyTtRo39tNDR5
XLWVQDqxo9Km9zLyquoC9gAP8CL1gWnHZ7z
原始数据结构公共link结构是IPFS构建任意数据结构的必要组成部分。可以很容易看出Git的对象模型是如何套用DAG的。一些其他潜在的数据结构:
- (a)键值存储
- (b)传统关系型数据
- (c)数据三倍存储
- (d) 文档发布系统
- (e)通信平台
- (f)加密货币区块。
这些系统都可以套用IPFS Merkle DAG,这使这些系统更复杂的应用可以使用IPFS作为传输协议。
3.5.1 路经
IPFS对象可以遍历一个字符串路经。路经格式与传统UNIX文件系统以及Web一致。Merkle DAG的links使遍历变得很容易。全称路经在IPFS中的格式是:
| 1 2 3 4 |
*# 格式 /ipfs/ *# 例子 /ipfs/XLYkgq61DYaQ8NhkcqyU7rLcnSa7dSHQ16x/foo.txt |
/ipfs前缀允许只要在挂载点不冲突(挂载点名称当然是可配置的)的情况下挂载到一个已存在的系统上。第二个路经组成部分(第一个是IPFS)是一个对象的hash。通常都是这种情况,因为没有全局的根。一个根对象可能会有一个不可能完成的任务,就是在分布式环境(可能还断开链接)中处理百万对象的一致性。因此,我们用地址可寻址来模拟根。通过的hash所有的对象都是可访问的。这意思是说,给一个路经对象/bar/baz,最后一个对象可以可以被所有的访问的:
| 1 2 3 |
/ipfs/ /ipfs/ /ipfs/ |
3.5.2 本地对象
IPFS客户端需要一个本地存储器,一个外部系统可以为IPFS管理的对象存储以及检索本地原始数据。存储器的类型根据节点使用案例不同而不同。在大多数情况下,这个存储器只是硬盘空间的一部分(不是被本地的文件系统使用键值存储如leveldb来管理,就是直接被IPFS客户端管理),在其他的情况下,例如非持久性缓存,存储器就是RAM的一部分。
最终,所有的块在IPFS中都是能够获取的到的,块都存储在了一些节点的本地存储器中。当用户请求一个对象时,这个对象会被查找到并下载下来存储到本地,至少也是暂时的存储在本地。这为一些可配置时间量提供了快速的查找。
3.5.3对象锁定
希望确保特定对象生存的节点可以锁定此对象。这保证此特定对象被保存在了节点的本地存储器上。也可以递归的进行锁定所有相关的派生对象。这使所有被指定的对象都保存在本地存储器上。这对长久保存文件特别有用,包括引用。这也同样让IPFS成为一个links是永久的Web,且对象可以确保其他被指定对象的生存。
3.5.4 发布对象
IPFS是全球分布的。它设计为允许成千上万的用户文件可以共同的存在的。DHT使用内容哈希寻址技术,使发布对象是公平的,安全的,完全分布式的。任何人都可以发布对象,只需要将对象的key加入到DHT中,并且以对象是对等节点的方式加入进去,然后把路径给其他的用户。要注意的是,对象本质上是不可改变的,就像在Git中一样。新版本的哈希值不同,因此是新对象。跟踪版本则是额外版本对象的工作。
3.5.5 对象级别的加密
IPFS是具备可以处理对象级别加密操作的。一个已加密的或者已签名的对象包装在一个特殊的框架里,此框架允许加密和验证原始字节。
| 1 2 3 4 5 6 7 8 |
type EncryptedObject struct { Object []bytes // 已加密的原始对象数据 Tag []bytes // 可选择的加密标识 type SignedObject struct { Object []bytes // 已签名的原始对象数据 Signature []bytes // HMAC签名 PublicKey []multihash // 多重哈希身份键值 } |
加密操作改变了对象的哈希值,定义一个不同的新的对象。IPFS自动的验证签名以及使用用户指定的钥匙链解密数据。加密数据的links也同样的被保护着,没有解密秘钥就无法遍历对象。也存在着一种现象,可能父对象使用了一个秘钥进行了加密,而子对象使用了另一个秘钥进行加密或者根本没有加密。这可以保证links共享对象安全。
3.6 文件
IPFS在Merkle DAG上还为模型化版本文件系统定义了一组对象。这个对象模型与Git比较相似:
Block:一个可变大小的数据块
List:块或者其他链表的集合
Tree:块,链表,或者其他树的集合
Commit:树在版本历史记录中的一个快照
我原本希望使用与Git对象格式一致的模型,但那就必须要分开来引进在分布式文件系统中有用的某些特征,如
- (a)快速大小查找(总字节大小已经加入到对象中)
- (b)大文件的重复删除(添加到list对象)
- (c)commits嵌入到trees中。不过,IPFS文件对象与Git还是非常相近的,两者之间进行交流都是有可能的。而且,Git的一个系列的对象可以被引进过来转换都不会丢失任何的信息。(UNIX文件权限等等)。
标记:下面的文件对象格式使用JSON。注意,虽然IPFS包含了JSON的互相转换,但是文件对象的结构体还是使用protobufs的二进制编码。
3.6.1 文件对象:BLOB
blob对象代表一个文件且包含一个可寻址的数据单元,IPFS的blobs就像Git的blobs或者文件系统数据块。它们存储用户的数据。需要留意的是IPFS文件可以使用lists或者blobs来表示。Blobs没有links。
| 1 2 3 |
{ "data": "some data here", // blobs无links } |
3.6.2 文件对象: list
List对象代表着由几个IPFS的blobs连接成的大文件或者重复数据删除文件。Lists包含着有序的blob序列或list对象。从某种程度上而言,IPFS的list函数就像一个间接块的文件系统。由于lists可以包含其他的lists,那么包含linked的链表和平衡树的拓扑结构是有可能的。有向图中相同的节点出现在多个不同地方允许在文件中重复数据删除。当然,循环是不可以能的,因为是被哈希寻址强制实行的。
| 1 2 3 4 5 6 7 8 9 10 11 |
{ "data": ["blob", "list", "blob"], //lists有一个对象类型的数组作为数据 "links": [ { "hash": "XLYkgq61DYaQ8NhkcqyU7rLcnSa7dSHQ16x", "size": 189458 }, { "hash": "XLHBNmRQ5sJJrdMPuu48pzeyTtRo39tNDR5", "size": 19441 }, { "hash": "XLWVQDqxo9Km9zLyquoC9gAP8CL1gWnHZ7z", "size": 5286 } //在links中lists是没有名字的 ] } |
3.6.3 文件对象:tree
IPFS中的tree对象与Git中相似,它代表着一个目录,一个名字到哈希值的映射。哈希值则表示着blobs,lists,其他的trees,或者commits。注意,传统路径的命名早已经被Merkle DAG实现了。
| 1 2 3 4 5 6 7 8 9 10 11 |
{ "data": ["blob", "list", "blob"],//trees有一个对象类型的数组作为数据 "links": [ { "hash": "XLYkgq61DYaQ8NhkcqyU7rLcnSa7dSHQ16x", "name": "less", "size": 189458 }, { "hash": "XLHBNmRQ5sJJrdMPuu48pzeyTtRo39tNDR5", "name": "script", "size": 19441 }, { "hash": "XLWVQDqxo9Km9zLyquoC9gAP8CL1gWnHZ7z", "name": "template", "size": 5286 }//trees是有名字的 ] } |
3.6.4 文件对象:commit
IPFS中的commit对象代表任何对象在版本历史记录中的一个快照。与Git中类似,但是它能够表示任何类型的对象。它同样link着发起对象。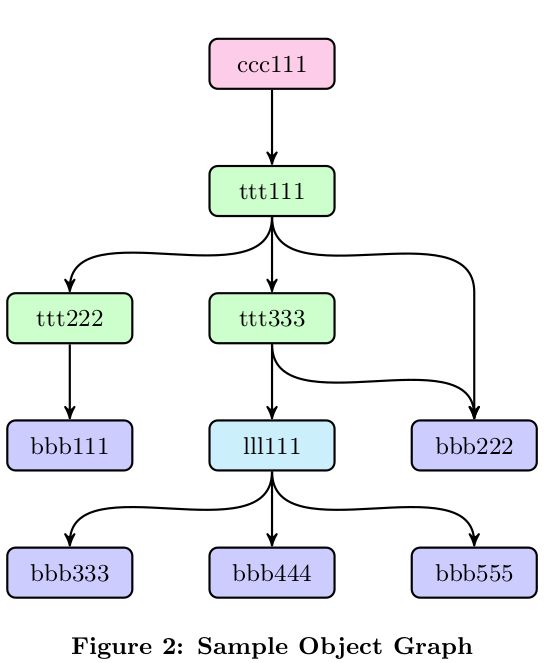

3.6.5 版本控制
Commit对象代表着一个对象在历史版本中的一个特定快照。在两个不同的commit中比较对象(和子对象)可以揭露出两个不同版本文件系统的区别。只要commit和它所有子对象的引用是能够被访问的,所有前版本是可获取的,所有文件系统改变的全部历史是可访问的,这就与Merkle DAG对象模型脱离开来了。
Git版本控制工具的所有功能对于IPFS的用户是可用的。对象模型不完全一致,但也是可兼容的。这可能
- (a)构建一个Git工具版本改造成使用IPFS对象图,
- (b)构建一个挂载FUSE文件系统,挂载一个IPFS的tree作为Git的仓库,把Git文件系统的读/写转换为IPFS的格式。
3.6.6 文件系统路径
如我们在Merkle DAG中看到的一样,IPFS对象可以使用字符串路径API来遍历。IPFS文件对象是特意设计的,为了让挂载IPFS到UNIX文件系统更加简单。文件对象限制trees没有数据,为了使它们可以表示目录。Commits可以以代表目录的形式出现,也可以完全的隐藏在文件系统中。
3.6.7 将文件分隔成LISTS和BLOBS
版本控制和分发大文件其中一个最主要的挑战是:找到一个正确的方法来将它们分隔成独立的块。与其认为IPFS可以为每个不同类型的文件提供正确的分隔方法,不如说IPFS提供了以下的几个可选选择:
就像在LIBFS[?]中一样使用Rabin Fingerprints [?]来选择一个比较合适的块边界。
使用rsync[?] rolling-checksum算法,来检测块在版本之间的改变。
允许用户指定专为特定文件而调整的’快分隔’函数。
3.6.8路径查找性能
基于路径的访问需要遍历对象图。获取每个对象要求在DHT中查找它们的key,连接到对等节点,然后获取它的块。这造成相当大的开销,特别是查找的路径由很多子路径组成时。下面的方法可以减缓开销:
- tree缓存:由于所有的对象都是哈希寻址的,它们可以被无限的缓存。另外,trees一般比较小,所以比起blobs,IPFS会优先缓存trees。
- flattened trees:对于任何tree,一个特殊的 flattened tree可以构建一个链表,所有对象都可以从这个tree中访问得到。在flattened tree中名字就是一个从原始tree分离的路径,用斜线分隔。
例如,对于上面的ttt111的flattened tree如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
{
"data":
["tree", "blob", "tree", "list", "blob" "blob"],
"links": [
{ "hash": "
", "size": 1234 "name": "ttt222-name" },
{ "hash": "
", "size": 123, "name": "ttt222-name/bbb111-name" },
{ "hash": "
", "size": 3456, "name": "ttt333-name" },
{ "hash": "
", "size": 587, "name": "ttt333-name/lll111-name"},
{ "hash": "
", "size": 22, "name": "ttt333-name/lll111-name/bbb222-name" },
{ "hash": "
", "size": 22 "name": "bbb222-name" }
] }
3.7 IPNS:命名以及易变状态
目前为止,IPFS桟形成了一个对等块交换组成一个内容可寻址的DAG对象。这提供了发布和获取不可改变的对象。这甚至可以跟踪这些对象的版本历史记录。但是,这里有一个关键成分遗漏了:易变的命名。没有这个,发送IPFS的links,所有新内容的通信肯定都会有所偏差。现在所需就是能有某些方法可以获取相同路径的的易变状态。
这值得详述原因—如果最终易变数据是必须的—我们费了很大的力气构建了一个不可改变的Merkle DAG。就当做IPFS脱离了Merkle DAG的特征:对象可以
- (a)通过哈希值可以获取
- (b)完整性的检查
- (c)link其他的对象
- (d)无限缓存。从某种意义上说:对象就是永恒的这些就是一个高性能分布式系统的关键特征,在此系统上跨网络links之间移动文件是非常昂贵的。对象内容可寻址构建了一个具有以下特点的Web,(a)优秀的宽带优化(b)不受信任的内容服务(c)永恒的links(d)能够永久备任何对象以及它的引用。
不可变的内容可寻址对象和命名的Merkle DAG, 可变指针指向Merkle DAG,实例化了一个出现在很多成功分布式系统中的二分法。这些系统包括Git的版本控制系统,使用不可变的对象和可变的引用;还有UNIX分布式的继承者Plan9[?]文件系统,使用可变的Fossil和不可变的Venti[?]。LBFS[?]同样使用可变的索引以及不可变的块。
3.7.1 自我认证名称
使用SFS[12,11]中的命名方案,给我们提供了一个种可以构建自我认证名称的方法,
在一个加密指定的全局命名空间中,这是可变的。IPFS的方案如下:
- 1.回想一下在IPFS中:NodeId = hash(node.PubKey)
- 2.我们给每个用户分配一个可变的命名空间,在此路径下:/ipns/
- 3.一个用户可以在此路径下发布一个用自己私钥签名的对象,比如说:/ipns/XLF2ipQ4jD3UdeX5xp1KBgeHRhemUtaA8Vm/
- 4.当其他用户获取对象时,他们可以检测签名是否与公钥和NodeId匹配。这个验证了用户发布对象的真实性,达到了可变状态的获取。
注意下面的细节:
- IPNS(InterPlanetary的命名空间)分开前缀是在可变和不可变的路径之间建立一个很容易辨认的区别,为了程序也为了人类阅读的便利。
-
因为这不是一个内容可寻址的对象,所以发布它就要依靠IPFS中的唯一的可变状态分配制度,路由系统。过程是(a)首先把此对象做一个常规的不可变IPFS的对象来发布(b)将此对象的哈希值作为元数据的值发布到路由系统上:
1
routing.setValue(NodeId,
) -
发布的对象中任何links在命令空间中充当子名称:
1
2
3
/ipns/XLF2ipQ4jD3UdeX5xp1KBgeHRhemUtaA8Vm/
/ipns/XLF2ipQ4jD3UdeX5xp1KBgeHRhemUtaA8Vm/docs
/ipns/XLF2ipQ4jD3UdeX5xp1KBgeHRhemUtaA8Vm/docs/ipfs
-
一般建议发布一个commit对象或者其他对象的时候,要使用历史版本记录,因为这样就用户就可以找到之前使用过的名字。不过由于这并不总是需要的,所以留个用户自己选择。
注意当用户发布一个对象的时候,他不能使用相同的方式来发布对象。
3.7.2人类友好名称
IPNS的确是一个分配和在分配名称的好方法,但是对用户却不是十分友好的,因为它使用很长的哈希值作为名称,众所周知这样的名称很难被记住。IPNS足够应付URLs,但对于很多线下的传输工作就没有这么好用了。因此,IPFS使用下面的技术来增加IPNS的用户友好度。
对等节点Links被SFS所鼓舞,用户可以直接将其他用户的对象link到自己的对象上(命令空间,家目录等等)。这有一个好处就是创建了一个可信任的Web(也支持老的真实性认证模型):
| 1 2 3 4 5 6 7 8 |
# Alice links 到Bob上 ipfs link / # Eve links 到Alice上 ipfs link / # Eve 也可以访问Bob / # 访问Verisign 认证域 / |
DNS TXT IPNS 记录
如果/ipns/是一个有效的域名称,IPFS会在DNS TXT记录中查找关键的ipns。IPFS会将查找到的值翻译为一个对象的哈希值或者另一个ipns的路径:
| 1 2 3 4 |
# DNS TXT 记录 ipfs.benet.ai. TXT "ipfs=XLF2ipQ4jD3U ..." # 表现为符号链接 ln -s /ipns/XLF2ipQ4jD3U /ipns/fs.benet.ai |
Proquint 可读的标识符
总是会有将二进制编码翻译成可读文件的方法。IPNS则支持Proquint[?].。如下:
| 1 2 3 4 |
# proquint语句 /ipns/dahih-dolij-sozuk-vosah-luvar-fuluh # 分解为相应的下面形式 /ipns/KhAwNprxYVxKqpDZ |
缩短名称服务
会涌现出很多服务器提供缩短名称的服务,向用户提供他们的命名空间。就像我们现在看到的DNS和Web的URLs:
| 1 2 3 4 |
# 用户可以从下面获取一个link /ipns/shorten.er/foobar # 然后放到自己的命名空间 /ipns/XLF2ipQ4jD3UdeX5xp1KBgeHRhemUtaA8Vm |
3.8使用IPFS
IPFS设计为可以使用多种不同的方法来使用的,下面就是一些我将会继续追求的使用方式:
- 1.作为一个挂载的全局文件系统,挂载在/ipfs和/ipns下
- 2.作为一个挂载的个人同步文件夹,自动的进行版本管理,发布,以及备份任何的写入
- 3.作为一个加密的文件或者数据共享系统
- 4.作为所有软件的版本包管理者
- 5.作为虚拟机器的根文件系统
- 6.作为VM的启动文件系统 (在管理程序下)
- 7.作为一个数据库:应用可以直接将数据写入Merkle DAG数据模型中,获取所有的版本,缓冲,以及IPFS提供的分配
- 8.作为一个linked(和加密的)通信平台
- 9.作为一个为大文件的完整性检查CDN(不使用SSL的情况下)
- 10.作为一个加密的CDN
- 11.在网页上,作为一个web CDN
- 12.作为一个links永远存在新的永恒的Web
IPFS实现的目标: - (a)一个IPFS库可以导出到你自己应用中使用
- (b)命令行工具可以直接操作对象
- (c)使用FUSE[?]或者内核的模型挂载文件系统
4. 未来
IPFS的思想是几十年成功的分布式系统的探索和开源的产物。IPFS综合了很多迄今为止很成功的系统中优秀的思想。除了BitSwap新协议之外,IPFS最大的特色就是系统的耦合以及设计的综合性。
IPFS是去中心化网络基础设施的一个野心设想,很多不同类型的应用都可以建立在IPFS上。最低限度,它可以用来作为一个全局的,挂载性,版本控制文件系统和命名空间,或者作为下一代的文件共享系统。而最好的情况是,IPFS可以让Web升级一个层次,当发布一个有价值的信息时,任何感兴趣的人都可以进行发布而不会强迫性的必须只允许发布机构进行发布,用户可以信任信息的内容,信不信任信息的发送者都是无关紧要的,还有一个特点就是,一些重要但很老的文件也不会丢失。IPFS期待着带我们进入到一个永恒Wdb的世界。
5. 感谢
IPFS是一个很多很棒的主意以及系统的综合体。没有站在巨人的肩膀上,IPFS也不可能敢于有一个这么有野心的目标。个人感谢参与这些主意长期讨论的人:David Dalrymple, Joe Zimmerman, and Ali Yahya,特别是:揭开Merkle DAG的总体架构(David, Joe),滚动哈希阻塞(David), s/kademlia sybill 保护(David, Ali),特别感谢David Mazieres,为他之前非常聪明的主意。
6.引用备忘录
7.引用
[1].I. Baumgart and S. Mies. S/kademlia:一个安全的基于秘钥路由的可行方法。2007年国际会议,第2卷,1-8页,在《并发和分布式系统》中。IEEE,2007年。
[2].I. BitTorrent.Bittorrent和Attorrent软件超过1亿5000万用户里程碑,Jan。2012
[3].B. Cohen.激励机制在bittorrent中建立了健壮性。在《对等系统经济研讨会》中,第6卷,68-72页,2003年。
[4].J. Dean and S. Ghemawat. Leveldb - 一个快速和轻量级键值存储数据库,谷歌提供,2011年。
[5].M. J. Freedman, E. Freudenthal, and D. Mazieres. Coral民主内容发布。在NSDI中,第4卷,18-18页,2004年。
[6].J. H. Howard, M. L. Kazar, S. G. Menees, D. A,Nichols, M. Satyanarayanan, R. N. Sidebotham, 以及M. J. West.分布式文件系统的规模和性能。“ACM 电脑系统上的交易 (TOCS)” 6(1):51-81, 1988年