Hadoop on Yarn配置文档
目录
1软件配置文件基本信息... 1
2 安装Linux Centos6.9. 4
3 WinSCP Copy安装软件... 5
4克隆你的环境... 6
5免秘钥登录... 7
6格式化namenode,启动集群... 8
1软件配置文件基本信息
软件列表:
VMware-workstation-full-9.0.2-1031769.exe (虚拟机不能太老,发现7的话不能安装64位Centos)
CentOS-6.9-x86_64-bin-DVD1.iso (一定要64位linux,第一次安装32位的,发现hadoop只有64位下载,32位要自己编译,太麻烦了)
hadoop-2.7.5.tar.gz (这个只有64位的,32位的要自己编译)
jdk-8u161-linux-x64.tar.gz (JDK要64位的,hadoop运行用)
scala-2.11.8.tgz(好像不分32,64位)
zookeeper-3.4.10.tar.gz(好像不分32,64位)
spark-2.3.0-bin-hadoop2.7.tgz(为Spark onYarn做准备)
软件全部用WinScp上传到/hadoop目录中
软件下载后用tar zvxf hadoop-2.7.5.tar.gz解压到当前目录
Xshell-5.0.1339p.exe(远程连接linux)
apache-hive-2.3.2-bin.tar.gz(hive)
MYsql
rpm –hiv mysql-community-common-5.7.21-1.el6.x86_64.rpm
rpm –hiv mysql-community-libs-5.7.21-1.el6.x86_64.rpm
rpm –hiv mysql-community-client-5.7.21-1.el6.x86_64.rpm
rpm –hiv mysql-community-server-5.7.21-1.el6.x86_64.rpm
MYsql Driver
mysql-connector-java-5.1.46.tar.gz
目录结构:
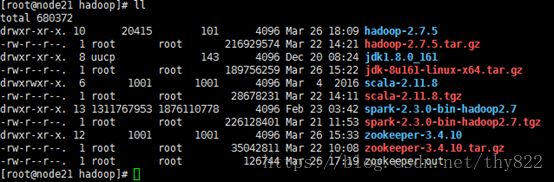
如何查看linux版本:
[root@node24 ~]# uname -a
Linux node24 2.6.32-696.el6.x86_64 #1 SMPTue Mar 21 19:29:05 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
如何查看hadoop版本:
[root@node21 logs]# file$HADOOP_HOME/lib/native/libhadoop.so.1.0.0
/hadoop/hadoop-2.7.5/lib/native/libhadoop.so.1.0.0:ELF 64-bit LSBshared object, x86-64, version 1 (SYSV), dynamically linked, not stripped
需要配置的文件如下:hadoop/zookeeper/java/scala/全部放在了/hadoop/下面
Linux配置文件
/etc/sysconfig/network-scripts/ifcfg-eth0
[root@node21 conf]# cat /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
TYPE=Ethernet
UUID=7bfe63f4-333-406a-55e-4f680a9ec018
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
DNS1=192.168.0.1
IPADDR=192.168.0.84
NETMASK=255.255.248.0
GATWAY=192.168.0.1
HWADDR=00:0C:29:F2:DC:65
PREFIX=24
DEFROUTE=yes
IPV4_FAILURE_FATAL=yes
IPV6INIT=no
NAME="System eth0"
LAST_CONNECT=1522047519
/root/.bash_profile.重启机器或执行命令:source /root/.bash_profile让修改有效
exportZOOKEEPER_HOME=/hadoop/zookeeper-3.4.10
JAVA_HOME=/hadoop/jdk1.8.0_161
CLASSPATH=$JAVA_HOME/lib/
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$ZOOKEEPER_HOME/bin
export PATH JAVA_HOME CLASSPATH
export SCALA_HOME=/hadoop/scala-2.11.8
export PATH=$PATH:$SCALA_HOME/bin
export HADOOP_HOME=/hadoop/hadoop-2.7.5
export HADOOP_PID_DIR=/data/hadoop/pids
exportHADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
exportHADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
exportHADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
exportHDFS_CONF_DIR=$HADOOP_HOME/etc/hadoop
exportYARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
exportJAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native
exportPATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
/etc/sysconfig/network
NETWORKING=yes
HOSTNAME=node21(每台机器不一样)
GATWAY=192.168.0.1
/etc/hosts
192.168.0.84 node21
192.168.0.85 node22
192.168.0.86 node23
192.168.0.87 node24
Hadoop配置文件,具体参考:
https://blog.csdn.net/thy822/article/details/79784709
/hadoop/hadoop-2.7.5/etc/hadoop/slaves
/hadoop/hadoop-2.7.5/etc/hadoop/core-site.xml
/hadoop/hadoop-2.7.5/etc/hadoop/hdfs-site.xml
/hadoop/hadoop-2.7.5/etc/hadoop/yarn-site.xml
/hadoop/hadoop-2.7.5/etc/hadoop/mapred-site.xml
/hadoop/hadoop-2.7.5/etc/hadoop/hadoop-env.sh
/hadoop/hadoop-2.7.5/etc/hadoop/mapred-env.sh
/hadoop/hadoop-2.7.5/etc/hadoop/yarn-env.sh
/hadoop/hadoop-2.7.5/etc/hadoop/yarn-site.xml(这个文件注意,node21是rm1,node22上是rm2)
Zookpeeper配置文件(node21,node22,node23,node24不要)
Mkdir /hadoop/zookeeper-3.4.10/data
Mkdir /hadoop/zookeeper-3.4.10/logs
先将cfg文件重命名:
[root@node21 hadoop]#cd /hadoop/zookeeper-3.4.10/conf
[root@node21 hadoop]#mv zoo_sample.cfgzoo.cfg
然后在最后面添加如下
dataLogDir=/hadoop/zookeeper-3.4.10/logs
dataDir=/hadoop/zookeeper-3.4.10/data
server.1=node21:2888:3888
server.2=node22:2888:3888
server.3=node23:2888:3888
在目录/hadoop/zookeeper-3.4.10/data下面添加文件myid,
node21内容是1
node22内容是2
node23内容是3
2 安装Linux Centos6.9
关闭防火墙
需要改为开机不启动,使用chkconfig命令
永久开启防火墙: chkconfig iptables on
查看状态: chkconfig --listiptables
永久关闭防火墙:chkconfig iptables off
查看防火墙:service iptables status
打开防火墙:service iptables start
关闭防火墙:service iptables stop
以上这是临时关闭,关闭的是当前运行的防火墙,重启之后防火墙又会启动,因为它是开机自启动的,它相当于/etc/init.d/iptables start
[root@node21 conf]# chkconfig --listiptables
iptables 0:off 1:off 2:off 3:off 4:off 5:off 6:off
[root@node21 conf]# service iptables status
iptables: Firewall is not running.
配置静态IP
在终端中输入:vi /etc/sysconfig/network-scripts/ifcfg-eth0
开始编辑,填写ip地址、子网掩码、网关、DNS等。其中“红框内的信息”是必须得有的。
编辑完成后,保存退出,重启网络服务
service network restart或/etc/init.d/networkrestart
3 WinSCP Copy安装软件
Copy haoop/zookpeeter/java/scala到 /hadoop目录
用tar zvxf spark-2.3.0-bin-hadoop2.7.tgz
解压所有软件
卸载linux已经安装的JAVA
查看安装情况
java -version
java version "1.8.0_60"
Java(TM) SE Runtime Environment (build1.8.0_60-b27)
Java HotSpot(TM) Client VM (build25.60-b23, mixed mode)
可能出现的错误信息:
bash: ./java: cannot execute binary file
出现这个错误的原因可能是在32位的操作系统上安装了64位的jdk,
查看jdk版本和Linux版本位数是否一致。
查看你安装的Ubuntu是32位还是64位系统:
sudo uname --m
i686 //表示是32位
x86_64 // 表示是64位
linux下怎么卸载自带的JDK和安装想要的JDK
卸载
1、卸载用 bin文件安装的JDK方法:
删除/usr/java目录下的所有东西
2、卸载系统自带的jdk版本方法:
查看自带的jdk:
#rpm -qa | grep gcj
看到如下信息:
libgcj-4.1.2-44.el5
java-1.4.2-gcj-compat-1.4.2.0-40jpp.115
使用rpm -e --nodeps 命令删除上面查找的内容:
#rpm -e –nodepsjava-1.4.2-gcj-compat-1.4.2.0-40jpp.115
3、卸载rpm安装的jkd版本
查看安装的jdk:
#rpm -qa|grep jdk
看到如下信息:
java-1.6.0-openjdk-1.6.0.0-0.25.b09.el5
jdk-1.6.0_16-fcs
卸载:
#rpm -e --nodeps jdk-1.6.0_16-fcs
java或javac会出现“cannotrestore segment prot after reloc: Permission denied”错误解决方案:
解决的办法是在root用户下,修改/etc/selinux/config 文件,
把SELINUX=enforcing 改成 SELINUX=disabled。
然后,保存关闭,重启机器就可以了。
检查java/scala安装情况
[root@node21 conf]# java -version
java version "1.8.0_161"
Java(TM) SE Runtime Environment (build1.8.0_161-b12)
Java HotSpot(TM) 64-Bit Server VM (build25.161-b12, mixed mode)
[root@node21 conf]# scala -version
Scala code runner version 2.11.8 --Copyright 2002-2016, LAMP/EPFL
4克隆你的环境
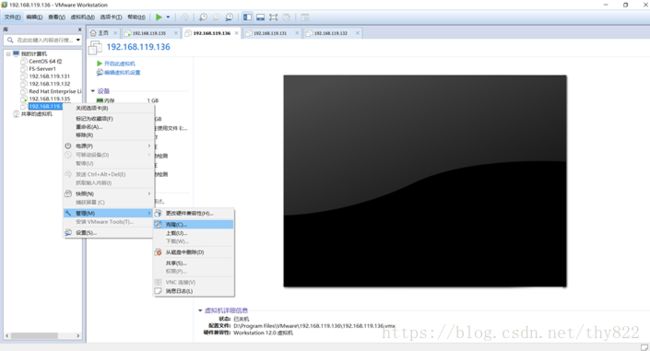
其实就是打开 VMare 后,关闭或挂起你要克隆的机器,然后右键选择【管理】-【克隆】:
剩下的都是 Next 、 Next 了,不过到这个选择【克隆方法】的时候应该注意一下,最好选择下面的【创建完整克隆】,因为这样不会依赖你原来的环境:
接下来的名字、位置什么的自己填咯。完成就行了。
2.简单配置你克隆后的环境
由于你用了克隆,所有克隆出来的环境和原来的一模一样,包括主机名、IP地址、MAC地址阿什么的,所以要解决的就几个小问题而已。
在你克隆好的机器上,右键选择【设置】-【网络适配器】-【高级】,随便点几下【生成】按钮
修改/etc/udev/rules.d/70-persistent-net.rules 文件
1 删除掉 关于 eth0 的信息。
2 修改 第二条 eth1 的网卡的名字为 eth0.
3 修改/etc/sysconfig/network-scripts/ifcfg-eth0 中mac地址为
/etc/udev/rules.d/70-persistent-net.rules 修改后的eth0的mac地址。
4 重启服务器。
5免秘钥登录
双向登陆的操作过程:
1、ssh-keygen做密码验证可以使在向对方机器上ssh ,scp不用使用密码.具体方法如下:
2、两个节点都执行操作:#ssh-keygen-t rsa
然后全部回车,采用默认值.
3、这样生成了一对密钥,存放在用户目录的~/.ssh下。
将公钥考到对方机器的用户目录下,并将其复制到~/.ssh/authorized_keys中(操作命令:#cat id_dsa.pub >> ~/.ssh/authorized_keys )。
4、设置文件和目录权限:
设置authorized_keys权限
$ chmod 600 authorized_keys
设置.ssh目录权限
$ chmod 700 -R .ssh
5、要保证.ssh和authorized_keys都只有用户自己有写权限。否则验证无效。(今天就是遇到这个问题,找了好久问题所在),其实仔细想想,这样做是为了不会出现系统漏洞。
6格式化namenode,启动集群
创建目录(主要是为hadoop的tmp.dir配置路径,格式化NameNode 时会找name目录并写入相关信息),每台机器都跑
mkdir -p /data/hadoop/{pids,storage}
mkdir -p/data/hadoop/storage/{hdfs,tmp,journal}
mkdir -p/data/hadoop/storage/hdfs/{name,data}
如果Namenode无法格式化要先删除这几个文件夹,然后重新格式化
rm -fr /data/hadoop/storage/hdfs/name/*
rm -fr /data/hadoop/storage/hdfs/data/*
rm -fr /data/hadoop/storage/journal/*
JournalNode/ Zookeeper只能为奇数个,服务器:运行的JournalNode进程非常轻量,可以部署在其他的服务器上。注意:必须允许至少3个节点。当然可以运行更多,但是必须是奇数个,如3、5、7、9个等等
ZKFC和NameNode一样
1、 服务器角色
服务器角色 |
node21 |
node22 |
node23 |
node24 |
JounralNode |
YES |
YES |
YES |
NO |
Zookeeper |
YES |
YES |
YES |
NO |
NameNode |
YES |
YES |
NO |
NO |
ZKFC |
YES |
YES |
NO |
NO |
DataNode |
NO |
NO |
YES |
YES |
ResourceManager |
YES |
YES |
NO |
NO |
Mysql |
Yes |
|||
Hive |
YES |
YES |
NO |
NO |
2、
2、Hadoop(HDFS HA)总体架构
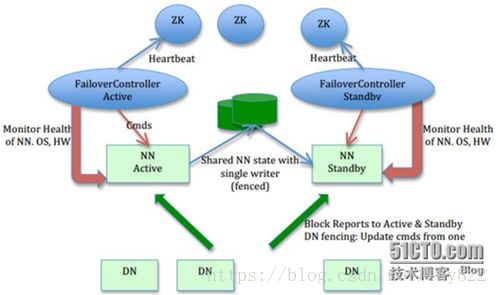
启动顺序如下:先在各个节点执行zkServer.shstart确保zookeeper都启动
1 zkServer.sh start (node21,node22,node23) 启动zookeeper
2 hdfs zkfc -formatZK (node21) 在node21上执行,创建命名空间
3 /hadoop/hadoop-2.7.5/sbin/hadoop-daemon.shstart journalnode (node21,node22,node23) 对应的节点上启动日志程序journalnode
4 hdfs namenode -format (node21)格式化主NameNode节点
5 /hadoop/hadoop-2.7.5/sbin/hadoop-daemon.shstart namenode (node21)启动主NameNode节点
6 hdfs namenode -bootstrapStandby (node22)格式备NameNode节点
7 /hadoop/hadoop-2.7.5/sbin/hadoop-daemon.shstart namenode (node22)启动备NameNode节点
8 /hadoop/hadoop-2.7.5/sbin/hadoop-daemon.shstart zkfc (node21.node22)在两个NameNode节点上执行
9 /hadoop/hadoop-2.7.5/sbin/hadoop-daemon.shstart datanode (node23,node24)、启动所有的DataNode节点(node23、node24)
10 /hadoop/hadoop-2.7.5/sbin/start-yarn.sh (node21)启动yarn
11 /hadoop/hadoop-2.7.5/sbin/yarn-daemon.shstart resourcemanager (node22)启动备份节点多行的resourcemanager
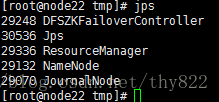
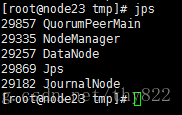
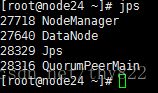
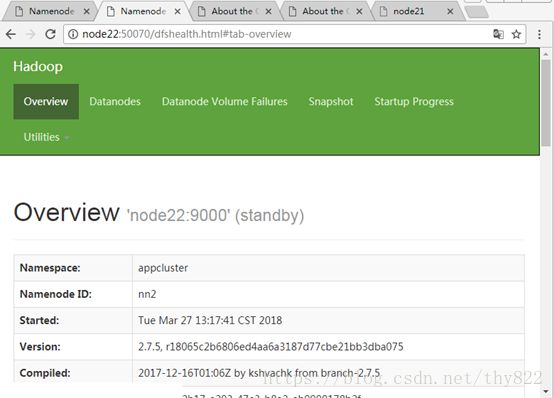
http://node21:50070/dfshealth.html#tab-overview
http://node22:50070/dfshealth.html#tab-overview
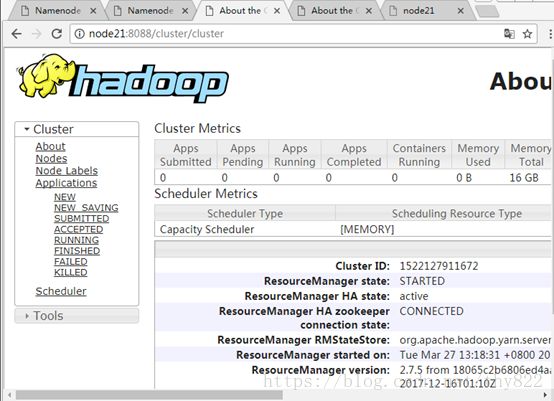
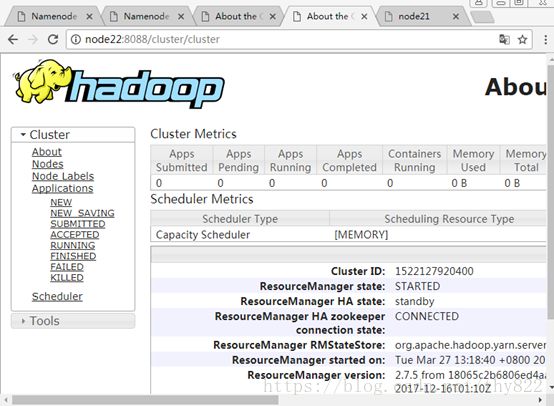
http://node21:8088/cluster/cluster
http://node22:8088/cluster/cluster
修改:C:\Windows\System32\drivers\etc\host添加
192.168.0.84 node21
192.168.0.85 node22
192.168.0.86 node23
192.168.0.87 node24
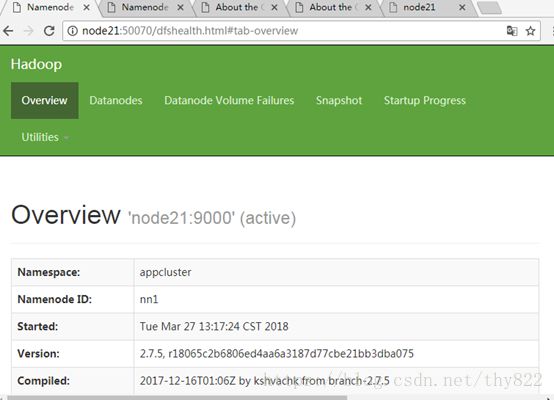
注:若格式化之后重新修改了配置文件,重新格式化之前需要删除tmp,dfs,logs文件夹。
/hadoop/hadoop-2.7.5/sbin/start-dfs.sh #启动dfs
/hadoop/hadoop-2.7.5/sbin/start-yarn.sh #启动yarn
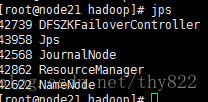
可以通过jps命令获取到ID 号,然后kill -9 id来测试备用NameNode/ResoureManager是否可以用。
可以用如下命令来启动关闭集群:
/hadoop/hadoop-2.7.5/sbin/start-all.sh(node21)
/hadoop/hadoop-2.7.5/sbin/stop-all.sh(node21)
/hadoop/hadoop-2.7.5/sbin/yarn-daemon.shstart resourcemanager (node22)
检查状态zkServer.shstatus
# hdfs namenode –format
namenode 格式化错误 Unable to checkif JNs are ready for formatting
解决方案一:
在各JournalNode节点上,输入以下命令启动journalnode服务:
本例子中要对node1/node2/node3节点执行
sbin/hadoop-daemon.sh start journalnode:
然后格式化就没问题了
测试hadoop集群:数下a.txt文件中单词的个数
hadoop jar
/hadoop/hadoop-2.7.5/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar
wordcount /tmp/a.txt /mytest
【注意】需要在NameNode节点上执行。
HDFS的关闭与启动:
# cd /usr/local/hadoop &&sbin/stop-dfs.sh
# cd /usr/local/hadoop &&sbin/start-dfs.sh
YARN的关闭与启动:
# cd /usr/local/hadoop &&sbin/stop-yarn.sh
# cd /usr/local/hadoop &&sbin/start-yarn.sh
附:常用命令
复制代码
# journalnode
hadoop-daemons.sh start journalnode
hadoop-daemons.sh stop journalnode
# namenode
hadoop namenode -format
hadoop-daemon.sh start namenode
hadoop-daemon.sh stop namenode
# 同步
hdfs namenode -bootstrapStandby
hadoop-daemon.sh start namenode
# datanode
hadoop-daemons.sh start datanode
hadoop-daemons.sh stop datanode
# zookeeper以及zkfc
zkServer.sh start
zkServer.sh stop
hdfs zkfc -formatZK
hadoop-daemons.sh start zkfc
hadoop-daemons.sh stop zkfc
# yarn
yarn-daemon.sh start resourcemanager
yarn-daemon.sh stop resourcemanager
yarn-daemon.sh start nodemanager
yarn-daemon.sh stop nodemanager
yarn-daemon.sh start proxyserver
yarn-daemon.sh stop proxyserver
mr-jobhistory-daemon.sh start historyserver
mr-jobhistory-daemon.sh stop historyserver
yarn-daemon.sh start historyserver
yarn-daemon.sh stop historyserver
# rm1 rm2为配置文件中设定的资源管理器名称
yarn rmadmin -getServiceState rm1
yarn rmadmin -getServiceState rm2
start-dfs.sh
stop-dfs.sh
start-yarn.sh
stop-yarn.sh