selenium高级自动化编程
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、环境准备
- 二、webdriver
-
- 操作浏览器的基本方法
- 元素定位
-
- xpath定位
- css定位
- 操作元素(键盘和鼠标事件)
-
- 简单操作
- submit 提交表单
- 键盘操作
- 鼠标悬停事件
- 多窗口、句柄(handle)
-
- 获取窗口句柄
- 句柄切换
- iframe
-
- frame 和 iframe 区别
- 163 登录界面
- 切换iframe
- select 下拉框
-
- 认识 select
- 二次定位
- 直接定位
- 其他定位方式
- 弹窗操作
-
- alert\confirm\prompt
- alert 操作
- confirm 操作
- prompt 操作
- 单选框和复选框
-
- 单选框
- 复选框:checkbox
- table 定位
-
- xpath 定位 table
- 富文本练习
- 获取页面元素
- 爬取网页源码
-
- page_source
- re 非贪婪模式
- cookie相关
-
- 获取 cookies:get_cookies()
- 登录后的 cookies
- 获取登陆的cookie
- 使用cookie绕过验证码登陆
- 三、使用JavaScript
-
- 控制滚动条
-
- 通过标尺拖动滚动条
- 通过元素拖动滚动条
- 日历控件readonly
- 内嵌滚动条
- 元素属性修改
- 四、浏览器打开python帮助文档
- 五、Unittest
-
- 案列1
-
- expected_condtions
- 断言方法
- 案例2
- 案例三
-
- 创建项目
- 被测对象
- 测试用例
- unittest进阶使用
- 二次封装
-
- 元素定位参数化(find_element)
- 登陆方法参数化
-
- 不会生成html报告原因
- 异常处理(NoSuchElementException)
- Excel处理
- 补充知识,使用openpyxl库处理excel
-
- 案例一、
- 案例二、
- 案例三、
- 案例四、
- 案例五、
- 案例六、
- 案例七、
- 案例八、
前言
提示:学完本篇文章,自动化测试算是入门了
提示:以下是本篇文章正文内容,下面案例可供参考
一、环境准备
1、python3.7
2、pycharm
3、selenium
4、xpath与chrome控件
selenium下载
cmd窗口下输入:pip install selenium
版本问题可能导致安装失败
xpath控件在Google应用商店下载
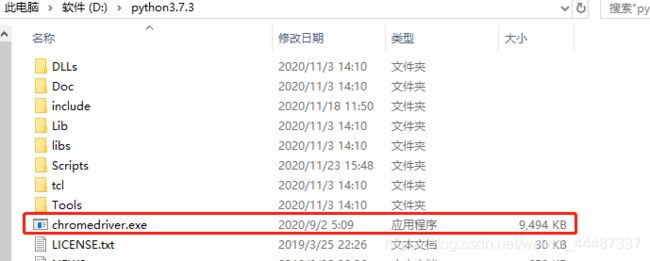
chrome控件放入python安装的根目录
下载地址:http://chromedriver.storage.googleapis.com/index.html
请与chrome浏览器的版本相对应,否则无法启动
二、webdriver
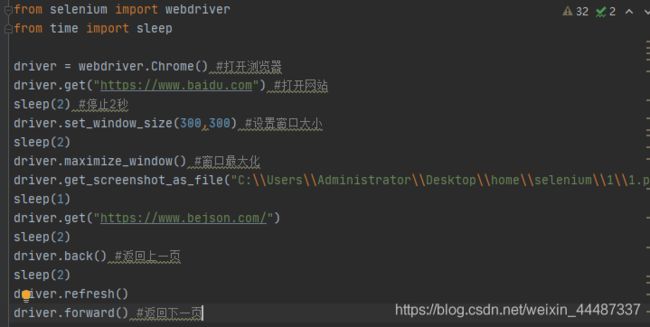
操作浏览器的基本方法
元素定位
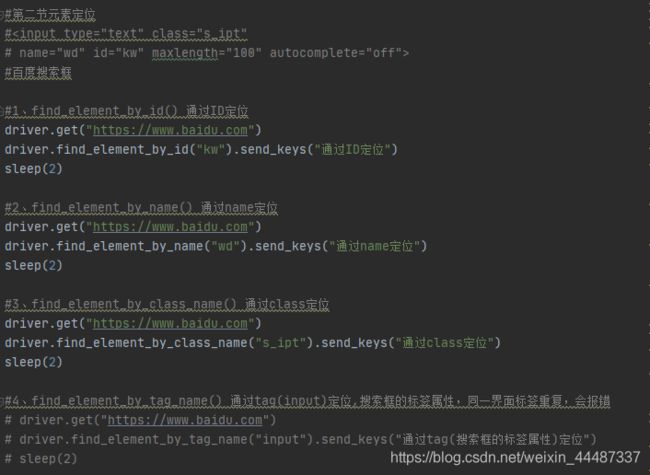
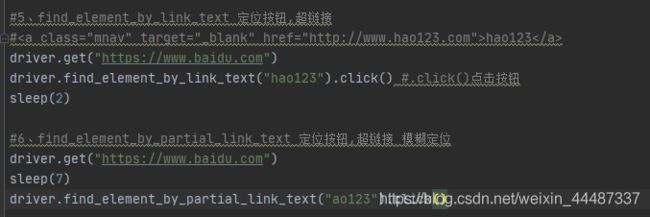
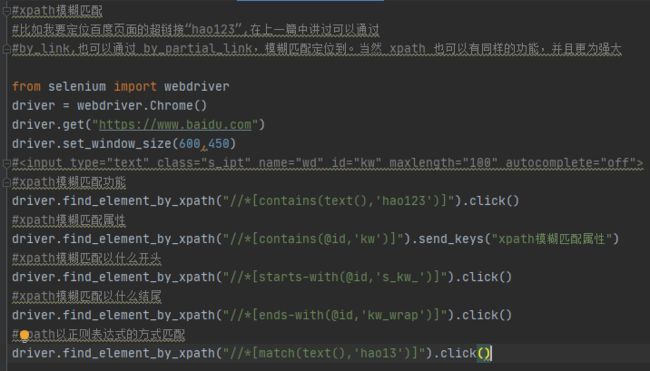
xpath定位
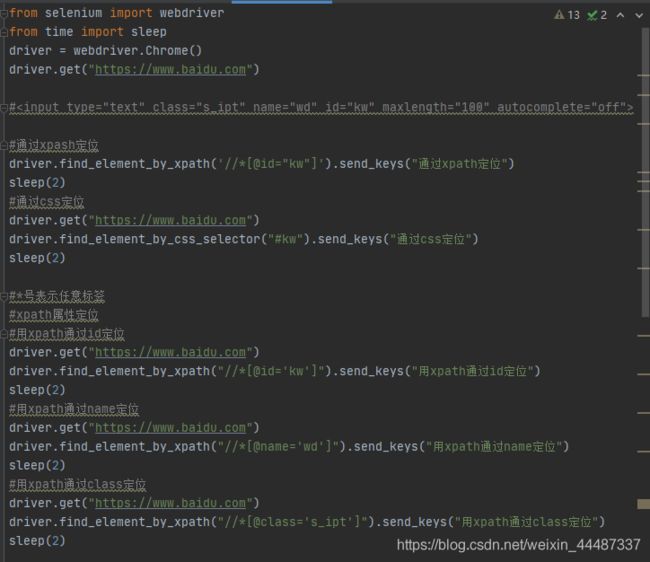
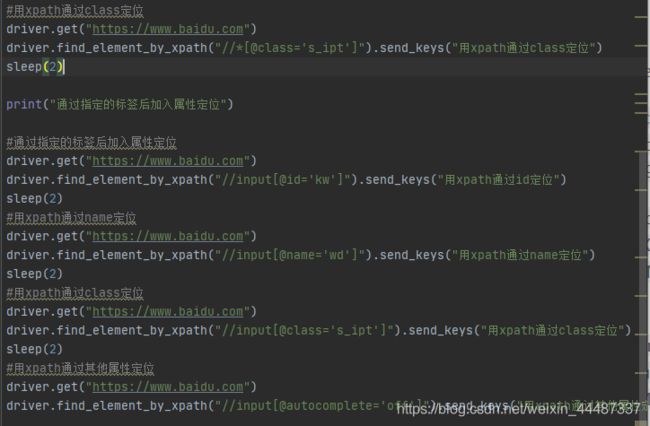
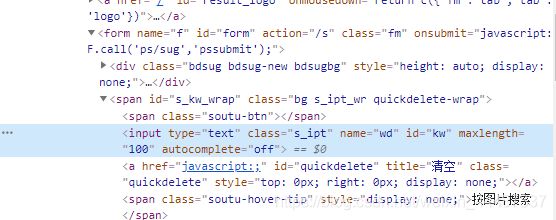
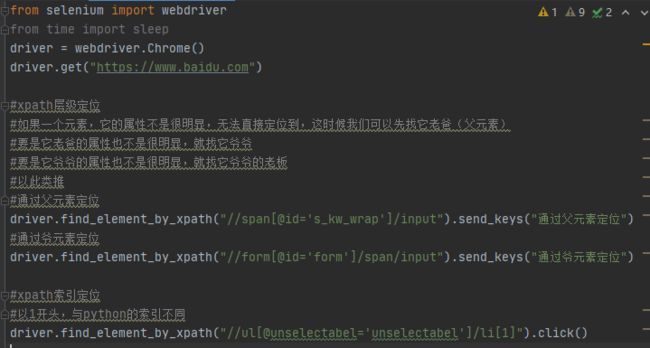
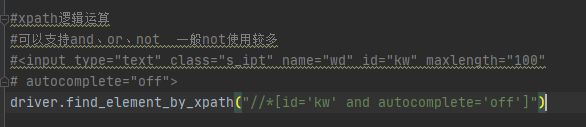
xpath模糊匹配
css定位
操作元素(键盘和鼠标事件)
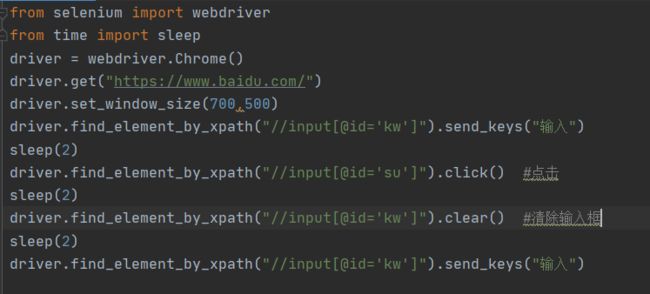
简单操作
1.点击(鼠标左键)页面按钮:click()
2.请空输入框:clear()
3.输入字符串:send_keys()
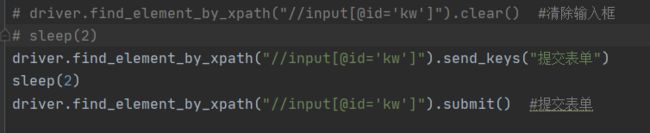
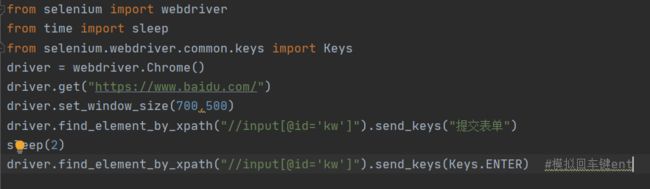
submit 提交表单
1.在前面百度搜索案例中,输入关键字后,可以直接按回车键搜索,也可以点搜索按钮
搜索。
2.submit()一般用于模拟回车键
键盘操作
1.selenium 提供了一整套的模拟键盘操作事件,前面 submit()方法如果不行的话,可以试试模拟键盘事件
2.模拟键盘的操作需要先导入键盘模块:from selenium.webdriver.common.keys import Keys
3.模拟 enter 键,可以用 send_keys(Keys.ENTER)
4.其它常见的键盘操作:
键盘 F1 到 F12:send_keys(Keys.F1) 把 F1 改成对应的快捷键
复制 Ctrl+C:send_keys(Keys.CONTROL,‘c’)
粘贴 Ctrl+V:send_keys(Keys.CONTROL,‘v’)
全选 Ctrl+A:send_keys(Keys.CONTROL,‘a’)
剪切 Ctrl+X:send_keys(Keys.CONTROL,‘x’)
制表键 Tab: send_keys(Keys.TAB)
鼠标悬停事件
1.鼠标不仅仅可以点击(click),鼠标还有其它的操作,如:鼠标悬停在某个元素上,鼠标右击,鼠标按住某个按钮拖动
2.鼠标事件需要先导入模块:from selenium.webdriver.common.action_chains import ActionChains
perform() 执行所有 ActionChains 中的行为
move_to_element() 鼠标悬停
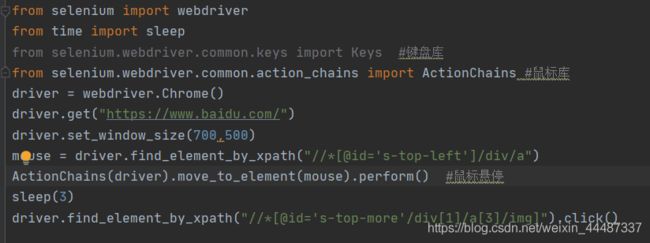
右击鼠标:context_click()
双击鼠标:double_click()
多窗口、句柄(handle)
有些页面的链接打开后,会重新打开一个窗口,对于这种情况,想在新页面上操作,就得先切换窗口了。获取窗口的唯一标识用句柄表示,所以只需要切换句柄,我们就能在多个页面上灵活自如的操作了。
本篇以打开百度新闻页面搜索按钮上的链接页面为例,依次打开每个按钮,并检验测试结果。用脚本批量操作,可以减少重复劳动,重复的事情让脚本去执行吧!
获取窗口句柄
1.打开百度新闻页面:17http://news.baidu.com/17
3.当点击百度新闻页面上新闻时,会打开一个新的窗口
3.人为操作的话,可以通过点击窗口切换到不同的窗口上,但是脚本它不
知道你要操作哪个窗口,这时候只能获取窗口唯一的标识:句柄
4.获取当前页面的句柄:driver.current_window_handle
5.获取所有窗口的句柄:driver.window_handles
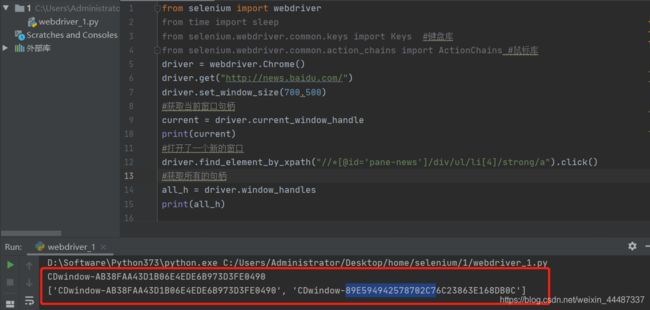
句柄切换
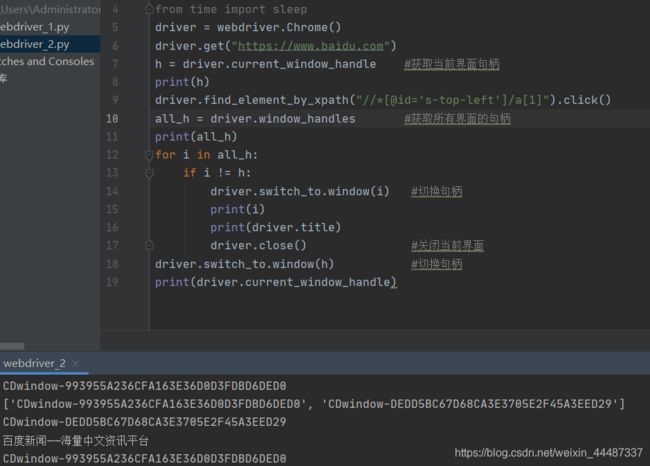
iframe
有很多小伙伴在拿 163 作为登录案例的时候,发现不管怎么定位都无法定位到,到底是什么鬼呢,下面详细介绍 iframe 相关的切换
frame 和 iframe 区别
frame 与 iframe 两者可以实现的功能基本相同,不过 iframe 比 frame 具有更多的灵活性。 frame 是整个页面的框架,iframe 是内嵌的网页元素,也可以说是内嵌的框架
iframe 标记又叫浮动帧标记,可以用它将一个 HTML 文档嵌入在一个 HTML中显示。它和 Frame 标记的最大区别是在网页中嵌入 的所包含的内容与整个页面是一个整体,而< /frame>所包含的内容是一个独立的个体,是可以独立显示的。另外,应用 iframe 还可以在同一个页面中多次显示同一内容,而不必重复这段内容的代码。
163 登录界面
确认登陆在iframe框架下
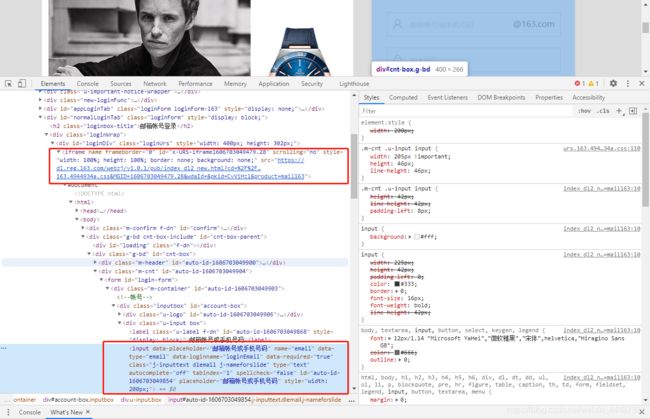
切换iframe
iframe 的切换是默认支持 id 和 name 的方法的
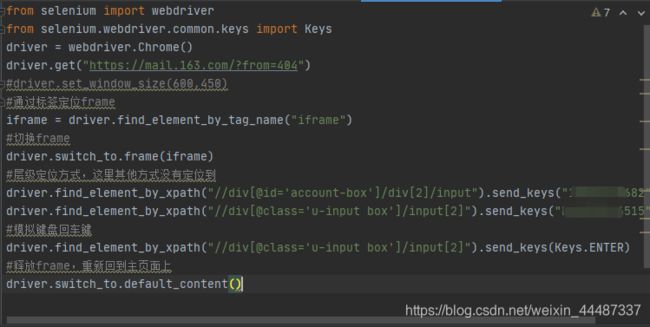
select 下拉框
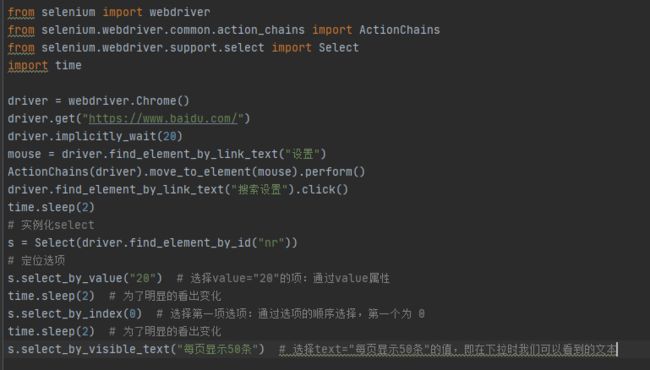
认识 select
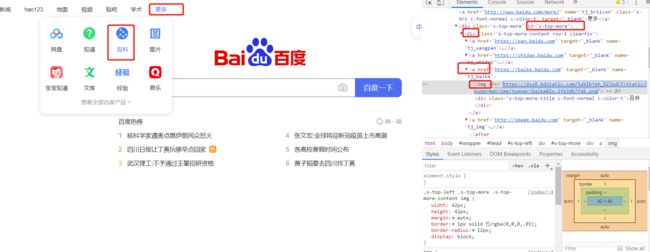
1.打开百度-设置-高级搜索设置界面,如下图所示
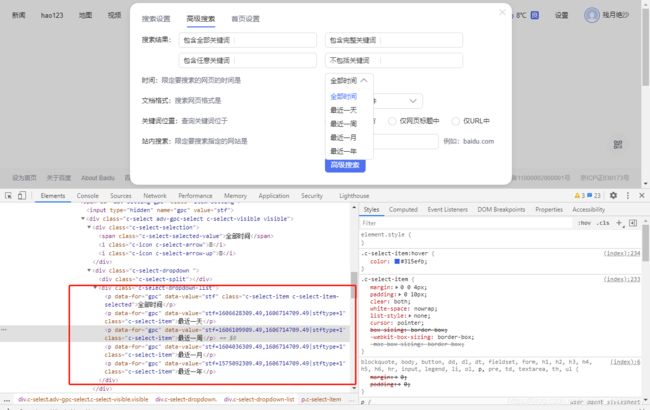
二次定位
界面改版,提供老版本百度下拉框定位方式,主要是为了了解流程,现版本不可用
选项有三个
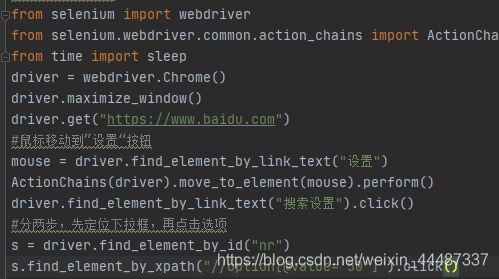
直接定位
可直接用
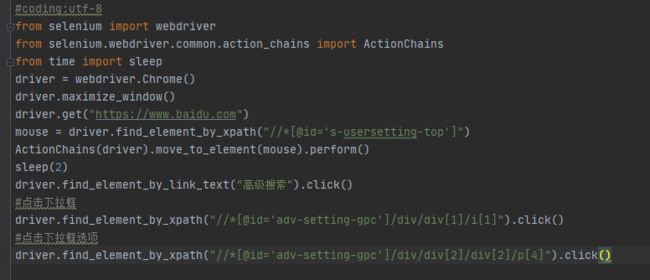
其他定位方式
这里只提供方法
弹窗操作
不是所有的弹出框都叫 alert,在使用 alert 方法前,先要识别出到底是不是alert。先认清楚 alert 长什么样子,下次碰到了,就可以用对应方法解决。
alert\confirm\prompt 弹出框操作主要方法有:
text:获取文本值
accept() :点击"确认"
dismiss() :点击"取消"或者叉掉对话框
send_keys() :输入文本值 --仅限prompt,在 alert 和 confirm 上没有输入框
alert\confirm\prompt
html代码如下,复制下面代码,改为html后缀的文件

<html>
<head>
<title>Alerttitle>
head>
<body>
body>
html>
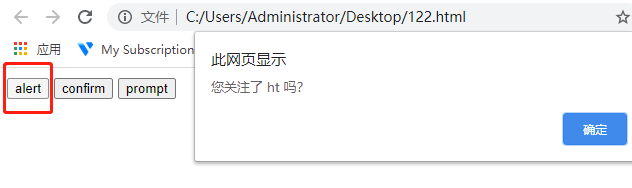
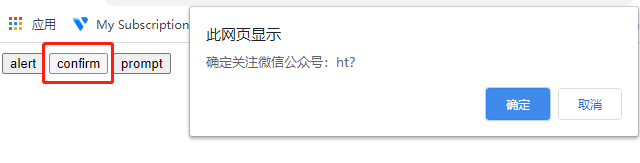
alert 操作
1.先用 switch_to.alert()方法切换到 alert 弹出框上
2.可以用 text 方法获取弹出的文本 信息
3.accept()点击确认按钮
4.dismiss()相当于点右上角 x,取消弹出框
(url 的路径,直接复制浏览器打开的路径)
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
url = "C:\\Users\\Administrator\\Desktop\\122.html"
driver.get(url)
sleep(2)
driver.find_element_by_id("alert").click() #点击”alert按钮“
sleep(2)
t = driver.switch_to.alert #切换到alert弹出框
print(t.text)
t.accept() #点击弹出框确认按钮
driver.find_element_by_id("alert").click()
sleep(2)
t = driver.switch_to.alert
t.dismiss() #退出弹出框
confirm 操作
1.先用 switch_to_alert()方法切换到 alert 弹出框上
2.可以用 text 方法获取弹出的文本 信息
3.accept()点击确认按钮
4.dismiss()相当于点取消按钮或点右上角 x,取消弹出框
(url 的路径,直接复制浏览器打开的路径)
driver = webdriver.Chrome()
url = "C:\\Users\\Administrator\\Desktop\\122.html"
driver.get(url)
sleep(2)
driver.find_element_by_id("confirm").click() #点击”confirm"按钮
sleep(2)
t = driver.switch_to.alert #切换到alert弹出框
print(t.text)
t.accept() #点击弹出框确认按钮
driver.find_element_by_id("alert").click()
sleep(2)
t = driver.switch_to.alert
t.dismiss() #退出弹出框,相当于取消按钮
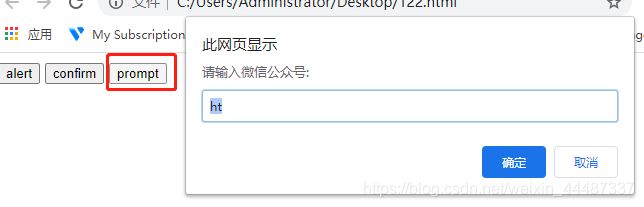
prompt 操作
1.先用 switch_to_alert()方法切换到 alert 弹出框上
2.可以用 text 方法获取弹出的文本 信息
3.accept()点击确认按钮
4.dismiss()相当于点右上角 x,取消弹出框
5.send_keys()这里多个输入框,可以用 send_keys()方法输入文本内容
(url 的路径,直接复制浏览器打开的路径)
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
url = "C:\\Users\\Administrator\\Desktop\\122.html"
driver.get(url)
sleep(2)
driver.find_element_by_id("prompt").click() #点击”confirm"按钮
sleep(2)
t = driver.switch_to.alert #切换到alert弹出框
print(t.text)
t.send_keys("hello word") #输入文本信息
sleep(2)
t.accept() #点击弹出框确认按钮
#t.dismiss() #退出弹出框,相当于取消按钮
单选框和复选框
HTML源码
<html>
<head>
<meta http-equiv="content-type"
content="text/html;charset=utf-8" />
<title>单选和复选title>
head>
<body>
form>
<h4>单选:性别h4>
<form>
<label value="radio">男label>
<input name="sex" value="male" id="boy" type="radio"><br>
<label value="radio1">女label>
<input name="sex" value="female" id="girl" type="radio">
form>
<h4>微信公众号:selenium高级自动化编程h4>
<form>
<input id="c1" type="checkbox">selenium<br>
<input id="c2" type="checkbox">python<br>
<input id="c3" type="checkbox">appium<br>
body>
html>

单选框
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
url = "C:\\Users\\Administrator\\Desktop\\233.html"
driver.get(url)
a = driver.find_element_by_id("boy").is_selected() #判断是否被选择
b = driver.find_element_by_id("girl").is_selected()
print("boy是否选中:",a)
print("girl是否选中:",b)
driver.find_element_by_id("boy").click() #点击单选
a1 = driver.find_element_by_id("boy").is_selected()
b1 = driver.find_element_by_id("girl").is_selected()
print("boy是否选中:",a1)
print("girl是否选中:",b1)
sleep(2)
driver.find_element_by_id("girl").click() #点击单选
复选框:checkbox
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
url = "C:\\Users\\Administrator\\Desktop\\233.html"
driver.get(url)
a = driver.find_element_by_id("c1").is_selected() #判断是否被选择
b = driver.find_element_by_id("c2").is_selected()
print("selenium是否选中:",a)
print("python是否选中:",b)
driver.find_element_by_id("c1").click() #点击单选
sleep(2)
a1 = driver.find_element_by_id("c1").is_selected()
b1 = driver.find_element_by_id("c2").is_selected()
print("selenium是否选中:",a1)
print("python是否选中:",b1)
driver.find_element_by_id("c1").click() #点击单选
driver.find_element_by_id("c2").click() #点击单选
driver.find_element_by_id("c3").click() #点击单选
sleep(2)
a11 = driver.find_element_by_id("c1").is_selected()
b11 = driver.find_element_by_id("c2").is_selected()
print("selenium是否选中:",a11)
print("python是否选中:",b11)
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
url = "C:\\Users\\Administrator\\Desktop\\233.html"
driver.get(url)
#find_elements_by_xpath与find_element_by_xpath
checkbox = driver.find_elements_by_xpath("//*[@type='checkbox']")
#全部勾选
for i in checkbox:
i.click()
table 定位
源码
<meta charset="UTF-8">
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<html>
<head>
<title>Table 测试模板title>
head>
<body>
<table border="1" id="myTable">
<tr>
<th>QQ 群th>
<th>QQ 号th>
<th>群主th>
tr>
<tr>
<td>selenium高级自动化编程td>
<td>123456td>
<td>httd>
tr>
<tr>
<td>appium 自动化td>
<td>123456789td>
<td>httd>
tr>
table>
body>
html>
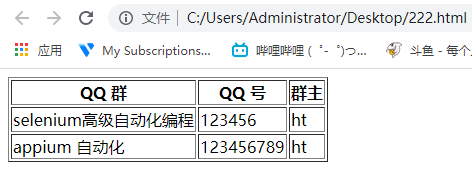
table特征:
1.table 页面查看源码一般有这几个明显的标签:table、tr、th、td
2.<table>标示一个表格
3.<tr>标示这个表格中间的一个行
4.</th> 定义表头单元格
5.</td> 定义单元格标签,一组<td>标签将建立一个单元格,<td>标签必须放在<tr>标签内
xpath 定位 table
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
url = "C:\\Users\\Administrator\\Desktop\\222.html"
driver.get(url)
#定位selenium高级自动化编程 /tbody/必须加
t = driver.find_element_by_xpath("//table[@id='myTable']/tbody/tr[2]/td[1]")
print(t.text)
富文本练习
最后写入图片的时候错误,暂时没找到原因
from selenium import webdriver
from time import sleep
driver = webdriver.Chrome()
from selenium.webdriver.common.keys import Keys
url = "https://www.cnblogs.com/"
driver.get(url)
driver.maximize_window()
sleep(2)
#登陆
driver.find_element_by_xpath("//*[@id='navbar_login_status']/a[4]").click()
driver.find_element_by_id("mat-input-0").send_keys("[email protected]")
driver.find_element_by_id("mat-input-1").send_keys("ht5")
driver.find_element_by_id("mat-input-1").send_keys(Keys.ENTER)
sleep(10)
#进入文本编辑器
#//*[@id="myblog_icon"]
driver.find_element_by_xpath("//*[@id='myblog_icon']").click()
sleep(3)
driver.find_element_by_xpath("//*[@id='blog_nav_newpost']").click()
sleep(2)
#标题输入
driver.find_element_by_id("post-title").send_keys("测试")
sleep(2)
#正文输入
driver.switch_to.frame("Editor_Edit_EditorBody_ifr")
driver.find_element_by_id("tinymce").send_keys("测试成功")
driver.switch_to.default_content()
sleep(2)
#图片上传
driver.find_element_by_id("Editor_Edit_EditorBody_uploadImage").click()
sleep(4)
#