Python爬虫 | 反爬机制:懒加载(动态加载数据的爬取)

示例网站:豆瓣电影
示例网站展示:
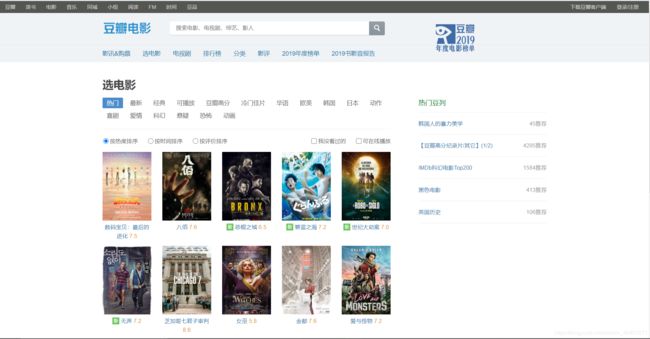
按照之前爬取网页的操作保存网页
import requests
url = 'https://movie.douban.com/explore'
headers = {
#封装请求头
'User-Agent':'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'
}
response = requests.get(url=url,headers=headers)
page_text = response.text
with open('douban.html','w',encoding='utf-8') as f:
f.write(page_text)
爬取出来的页面:
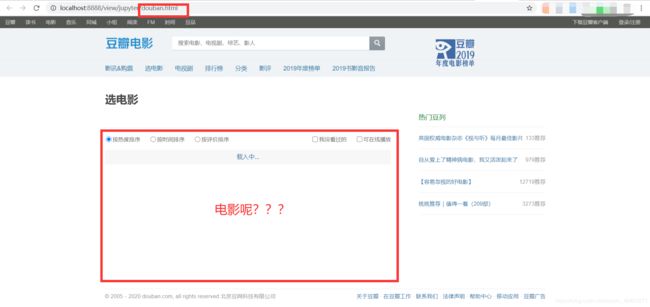
右键页面检查,随便找一部电影名搜索,发现页面请求是使用 Ajax 异步请求获取电影数据。
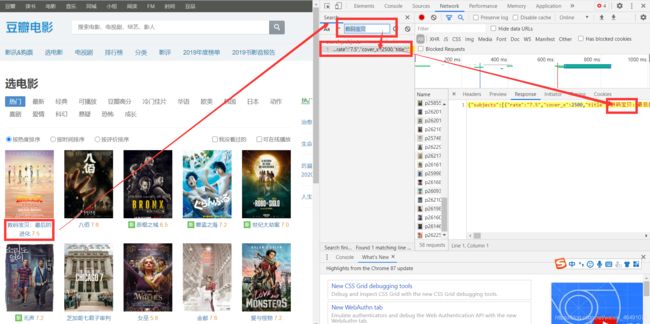
找到该条请求的 Headers 发现请求携带的参数,多次测试之后发现对应关系。
import requests
url = 'https://movie.douban.com/j/search_subjects'
headers = {
#封装请求头
'User-Agent':'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'
}
params = {
'type': 'movie',
'tag': '热门',
'sort': 'recommend',
'page_limit': '20',
'page_start': '0',
}
response = requests.get(url=url,params=params,headers=headers)
print(response.json())
数据太多,仅展示部分。

通过以上办法就能获取到电影数据
数据整理,提取电影名和电影评分
import requests
url = 'https://movie.douban.com/j/search_subjects'
headers = {
#封装请求头
'User-Agent':'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'
}
params = {
'type': 'movie',
'tag': '热门',
'sort': 'recommend',
'page_limit': '20',
'page_start': '0',
}
response = requests.get(url=url,params=params,headers=headers)
json_data = response.json() #json()可以将字符串序列化成对象
print('电影名','|','评分')
print('-|-')
for dic in json_data['subjects']:
name = dic['title']
rate = dic['rate']
print(name,'|',rate)
| 电影名 | 评分 |
|---|---|
| 数码宝贝:最后的进化 | 7.5 |
| 八佰 | 7.6 |
| 恶棍之城 | 6.5 |
| 碧蓝之海 | 7.2 |
| 世纪大劫案 | 7.0 |
| 无声 | 7.2 |
| 芝加哥七君子审判 | 8.6 |
| 女巫 | 5.8 |
| 金都 | 7.6 |
| 爱与怪物 | 7.2 |
| 波拉特2 | 7.3 |
| 担保 | 7.8 |
| 母亲 | 6.2 |
| 奇奇怪怪:整容液 | 6.1 |
| 85年盛夏 | 6.8 |
| 飞奔去月球 | 6.5 |
| 云上情歌 | 7.7 |
| 之后2 | 5.6 |
| 误杀 | 7.7 |
| 蝴蝶梦 | 5.6 |
当然这样还是不够完美,得可以选择爬取不同的类型电影,按照不同的排列顺序展示,且可以选择需要的数据量。
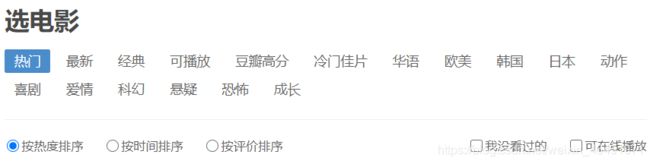
爬取前指定分类及数量
import requests
def choose(menu, tips):
i = 0
for m in menu:
print(i, ':', m)
i += 1
return input(tips + ":")
tag_menu = ['喜剧', '最新', '经典', '可播放', '豆瓣高分', '冷门佳片', '华语', '欧美', '韩国', '日本', '动作', '喜剧', '爱情', '科幻', '悬疑', '恐怖', '成长']
url = 'https://movie.douban.com/j/search_subjects'
headers = {
# 封装请求头
'User-Agent': 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/83.0.4103.116 Safari/537.36 '
}
params = {
'type': 'movie',
'tag': tag_menu[int(choose(tag_menu, '请输入您要爬取的类型编号'))],
'sort': 'recommend',
'page_limit': input('请输入您要爬取的条数'),
'page_start': '0',
}
response = requests.get(url=url, params=params, headers=headers)
json_data = response.json() # json()可以将字符串序列化成对象
print('电影名', '|', '评分')
print('-|-')
for dic in json_data['subjects']:
name = dic['title']
rate = dic['rate']
print(name, '|', rate)