Python爬取智联招聘网之贵阳python求职信息
智联招聘(NYSE:ZPIN):为求职者提供免费注册、求职指导、简历管理、职业测评等服务的一个网站,它提供了丰富的求职信息,可以很快的查询到符合自己职位。如我查询贵州python职位需求的信息。
智联官网: https://www.zhaopin.com/
时间: 2019/08/09
爬取内容: 职位名称,工作类型,公司名称,工资,地点,经验,学历,性质,规模,福利,发布时间等等。
操作环境: win10, python3.6, jupyter notebook,谷歌浏览器
技术实现思路:
- 在官网搜索python,地点选择贵阳
- 寻找数据接口
- 实现路径跳转
- 请求数据
- 提取数据
- 保存数据
- 所有源码汇总
思路分步讲解
1、在官网搜索python,地点选择贵阳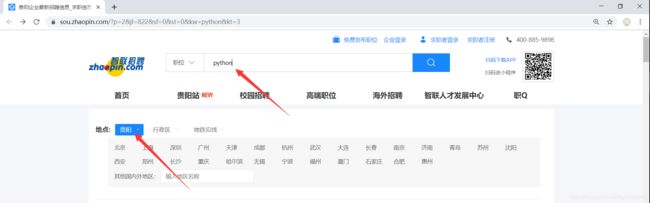
2、寻找数据接口
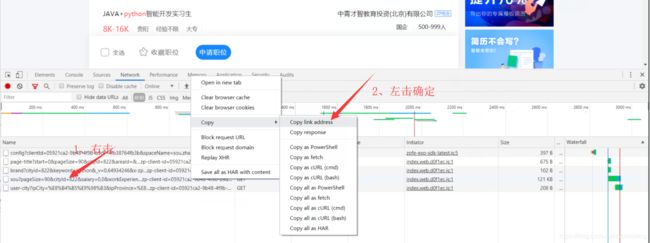
2.1、右击>检查>Network>XHR>F5刷新
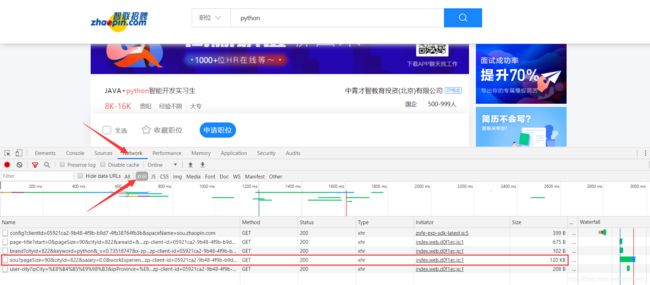
2.2、这样就找到传递数据的链接了,怎么确定是它呢?
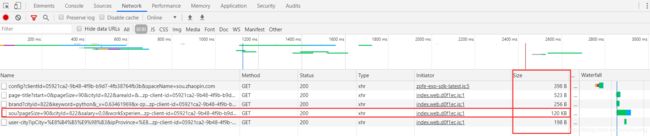
方法一、 先往数据大的路径看,通常都是它
方法二、 精准确定,保证我们选择的路径是正确的
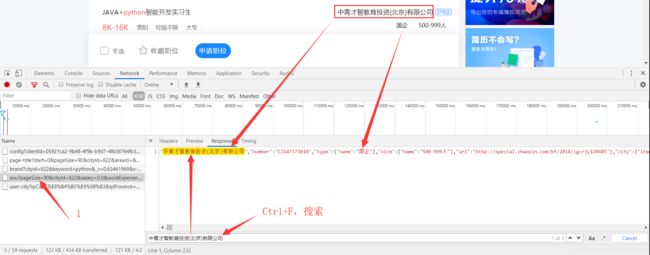
方法三、 也可以复制它的路径到浏览器中打开
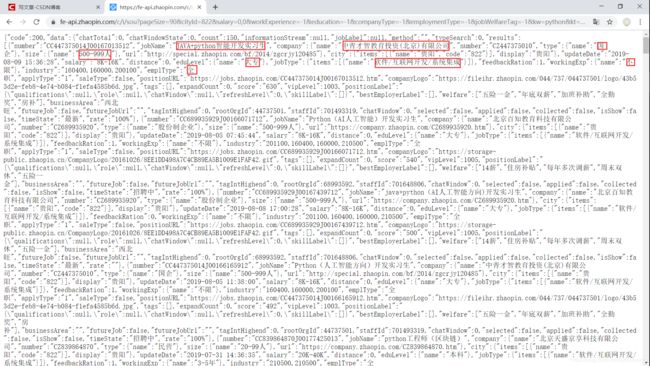
在浏览器中打开后确定信息:
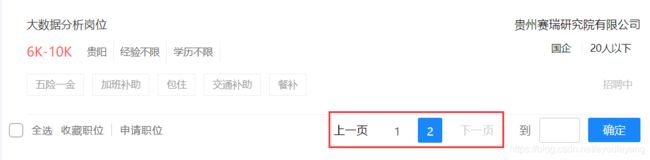
3、实现路径跳转
在网页的底部,观察到网页有两个页面,而我们的这样获取的只有一个路径,对于页面少的,我们可以把每个路径直接传进去,但对于页面很多的,一个一个的传就不理想了,所以有必要解析网页路径的特点。
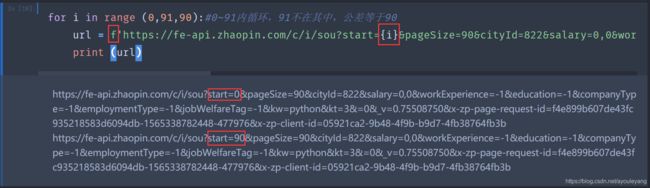
3.1、分析路径
两个路径对比:
#第一页
https://fe-api.zhaopin.com/c/i/sou?pageSize=90&cityId=822&salary=0,0&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=python&kt=3&=0&_v=0.75508750&x-zp-page-request-id=f4e899b607de43fc935218583d6094db-1565338782448-477976&x-zp-client-id=05921ca2-9b48-4f9b-b9d7-4fb38764fb3b
#第二页
https://fe-api.zhaopin.com/c/i/sou?start=90&pageSize=90&cityId=822&salary=0,0&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=python&kt=3&=0&_v=0.07041181&x-zp-page-request-id=c606b527a1444fc785e351546979e9b0-1565338838650-260626&x-zp-client-id=05921ca2-9b48-4f9b-b9d7-4fb38764fb3b
对比结果:

(1)第一个路径缺少start=90,90的意思是上个页面加载了90条数据,所以可以给第一个路径缺少的地方改为start=0 ,浏览器会自己解析回来的。

(2)这里发现它们的id也不一样,这是请求服务器时产生的id,每次都会变化,可以试试。在这里不需要管它,并不影响结果
3.2、在浏览器检查刚匹配的第一页路径是否正确

检查无误,匹配结果正确!!!可以用这个方法实现网页跳转
4、 请求数据
4.1、查看网页数据的请求方式:它用的时get方法

4.2、使用requests的get方法请求数据
import requests
url = 'https://fe-api.zhaopin.com/c/i/sou?start=0&pageSize=90&cityId=822&salary=0,0&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=python&kt=3&=0&_v=0.75508750&x-zp-page-request-id=f4e899b607de43fc935218583d6094db-1565338782448-477976&x-zp-client-id=05921ca2-9b48-4f9b-b9d7-4fb38764fb3b'
res = requests.get(url)
print (res.json())
运行部分结果如下:

4.3、格式化数据
上面的结果很乱,不方便人直接观看,可以导入pprint这个包输出美观的json数据。
import pprint
pprint.pprint(res.json())

它的数据是字典类型,这样就方便进行才查找了,也可以不使用pprint这个库来格式化数据,直接来网上在线json解析。
5、 提取数据
截取第一个招聘公司的数据进行讲解:
{
'code': 200,
'data': {
'chatTotal': 0,
'chatWindowState': 0,
'count': 149,
'informationStream': None,
'jobLabel': None,
'method': '',
'numFound': 999999,
'numTotal': 149,
'results': [{
'applied': False,
'applyType': '1',
'bestEmployerLabel': [],
'businessArea': '西北旺',
'chatWindow': 0,
'city': {
'display': '贵阳',
'items': [{
'code': '822', 'name': '贵阳'}]},
'collected': False,
'company': {
'name': '中青才智教育投资(北京)有限公司',
'number': 'CZ447375010',
'size': {
'name': '500-999人'},
'type': {
'name': '国企'},
'url': 'http://special.zhaopin.com/bf/2014/zgcrjy120485'},
'companyLogo': 'https://fileihr.zhaopin.com/044/737/044737501/logo/43b53d2e-feb8-4e74-b084-f1efa4585b6d.jpg',
'distance': 0,
'eduLevel': {
'name': '大专'},
'emplType': '全职',
'expandCount': 0,
'feedbackRation': 1,
'futureJob': False,
'futureJobUrl': '',
'industry': '160400,160000,200100',
'isShow': False,
'jobName': 'JAVA+python智能开发实习生',
'jobType': {
'items': [{
'name': '软件/互联网开发/系统集成'}]},
'number': 'CC447375014J00167013512',
'positionLabel': '{"qualifications":null,"role":null,"chatWindow":null,"refreshLevel":0,"skillLabel":[]}',
'positionURL': 'https://jobs.zhaopin.com/CC447375014J00167013512.htm',
'rate': '100%',
'rootOrgId': 44737501,
'salary': '8K-16K',
'saleType': False,
'score': '616',
'selected': False,
'staffId': 701493319,
'tagIntHighend': 0,
'tags': [],
'timeState': '最新',
'updateDate': '2019-08-09 15:36:28',
'vipLevel': 1003,
'welfare': ['五险一金', '年底双薪', '加班补助', '全勤奖', '房补'],
'workingExp': {
'name': '不限'}},
通过观察,我们发现每个公司的数据模块都在data下面的results中,可先对它进行查找并储存在results中:
results = res.json()['data']['results']
运行结果:
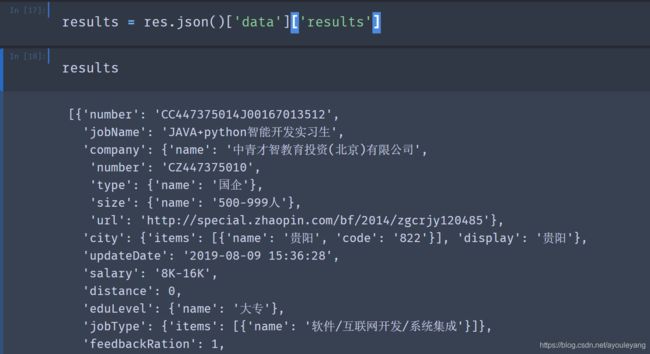
在results字典中查找结果:
- 查找工作名称: jobName的上一次就是results

- 查找公司名称: 公司名称的上一次是company,再上一层才是results
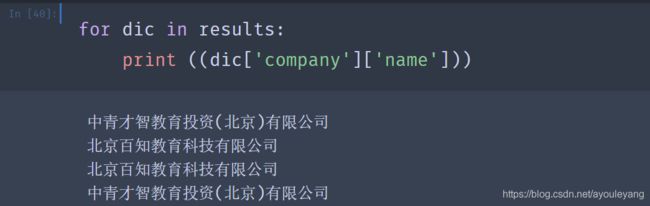
- 查找公司规模: 公司大小上一层是size,再上一层是company,要再上一层才是results; 公司类型也是同理
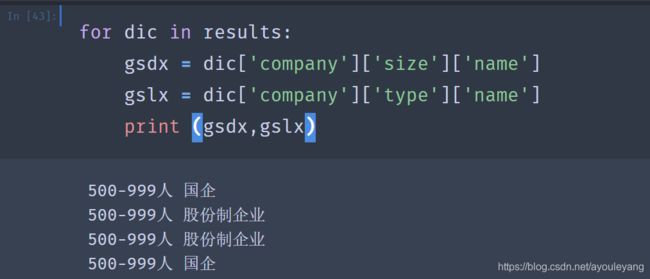
- 查找工作类型: 工作类型name上层jobType中隐藏了数组
for dic in results:
jobType = (dic['jobType']['items'])
print (jobType)
#输出结果: [{'name': '软件/互联网开发/系统集成'}] ,这是一个数组
print ((jobType)[0])
#输出结果: {'name': '软件/互联网开发/系统集成'}, [0]把数组变成字典类型
print ((jobType)[0]['name'])
#输出结果: 软件/互联网开发/系统集成
简写:jobType = jobType = (dic['jobType']['items'][0]['name'])
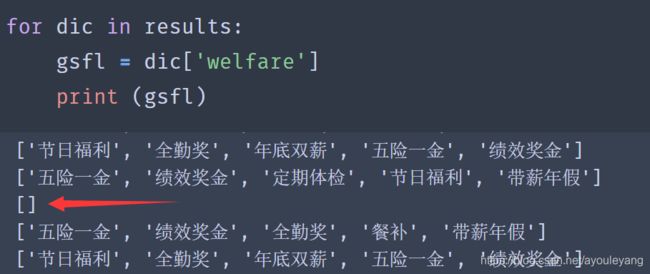
- 查找公司福利:公司福利的获取和工作名称一样,但要注意两点:
(1)有一些公司没有标福利;
(2)它输出的内容不是字符串,而是数组,如图:
解决方法:
for dic in results:
welfare = dic['welfare']#输出字符串
if len(welfare) != 0:
#如果welfare的长度不为0,就标有公司福利
gsfl = str(welfare).replace("['","").replace("']","").replace("', '",",")
#1、str()把数组转化为字符串
#2、replace把转化的字符串中不需要的内容替换
else:
gsfl = ("")
print (gsfl)
运行结果部分截图:

简化代码:
for dic in results:
gsfl = str(dic['welfare']).replace("['","").replace("']","").replace("', '",",") if len(dic['welfare']) != 0 else ""
print (gsfl)
6、保存数据
把爬取到的数据保存到csv文件,方便查看
#创建CSV文件,并写入表头信息
fp = open('G:\Zhilian_python.csv','a',newline='',encoding='utf-8')
writer = csv.writer(fp)
writer.writerow(('职位名称','公司名称')) #头部
for dic in results:
city = dic['jobName'] #查找所在城市
comName = dic['company']['name'] #查找公司名称
# 写入数据
writer.writerow((city,comName))
# 关闭文件
fp.close()
7. 所有源码汇总
import requests,csv
#创建CSV文件,并写入表头信息
fp = open('G:\Zhilian_python.csv','a',newline='',encoding='utf-8')
writer = csv.writer(fp)
writer.writerow(('职位名称','职位类型','发布状态','公司名称','公司详情','工资','文凭','经验','地点','公司类型','公司规模','福利')) #头部
for i in range(0,91,90):#在0~91内循环,91不在其中,公差等于90
url = f'https://fe-api.zhaopin.com/c/i/sou?start={i}&pageSize=90&cityId=822&salary=0,0&workExperience=-1&education=-1&companyType=-1&employmentType=-1&jobWelfareTag=-1&kw=python&kt=3&=0&_v=0.75508750&x-zp-page-request-id=f4e899b607de43fc935218583d6094db-1565338782448-477976&x-zp-client-id=05921ca2-9b48-4f9b-b9d7-4fb38764fb3b'
res = requests.get(url)
results = res.json()['data']['results']
#在字典中查找
for dic in results:
jobName = dic['jobName'] #查找工作名称
jobType = jobType = (dic['jobType']['items'][0]['name']) #获取职位类型, 注意其中的数组
#职位类型
timeState = dic['timeState'] #发布时间
comName = dic['company']['name'] #查找公司名称
href = dic['company']['url'] #公司详情链接
salary = dic['salary'] #工资
eduLevel= dic['eduLevel']['name']#文凭
workingExp = dic['workingExp']['name']#经验
city = dic['city']['display']#工作地点
comType = dic['company']['type']['name'] #公司类型,tpye是关键词,不能赋值
size = dic['company']['size']['name'] #公司规模
#查找公司福利,判断是否标有福利,转化数据类型,替换字符
welfare = str(dic['welfare']).replace("['","").replace("']","").replace("', '",",") if len(dic['welfare']) != 0 else ""
print (jobName,jobType,timeState,comName,href,salary,eduLevel,workingExp,city,comType,size,welfare)
# 写入数据
writer.writerow((jobName,jobType,timeState,comName,href,salary,eduLevel,workingExp,city,comType,size,welfare))
# 关闭文件
fp.close()
最终输出的结果:
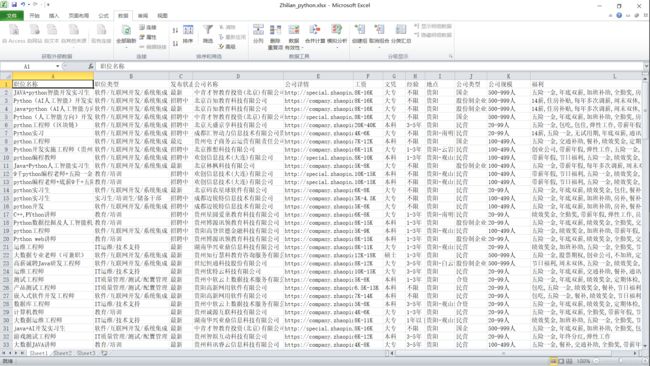
注意: csv文件出现乱码,可以这样打开
- 新建Excel表格
- 数据>自文本>选择刚爬取的csv文件>打开
- 选择分隔符号>下一步>去掉Tab键,勾选逗号
- 完成>确定
如有更好的方法,敬请指点!