爬虫爬一些网站是总是得到一个空的列表
#抓取PTT八卦版的网页原始码(HTML)
import urllib.request as req
url="https://www.ptt.cc/bbs/Gossiping/index.html"
#建立一个Request物件,附加Request Headers 的资讯
request=req.Request(url,headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36"
})
with req.urlopen(request) as response:
data=response.read().decode("utf-8")
#资料解析
import bs4
root=bs4.BeautifulSoup(data,"html.parser")
titles=root.find_all("div",class_="title")
print(titles)
for title in titles:
if title.a !=None: #如果标题包含 a 标签(没有被删除)。印出来
print(title.a.string)
抓取ptt八卦版的时候,我们会得到一个空的列表,原因是一般网页在我们访问时会向我们的浏览器中存放一个cookie,在连线的时候cookie会被放到“Request Headers”中被带出去,但是有的网页需要通过点击才会得到这个cookie。所以我们要爬取这些网页的时候就要手动添加一个点击得到的cookie发送过去。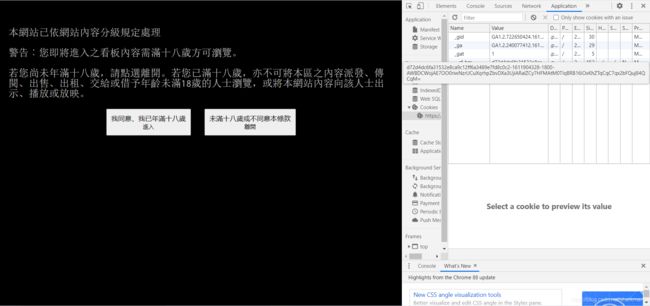
我们会看到点击前的cookie是这个样子的。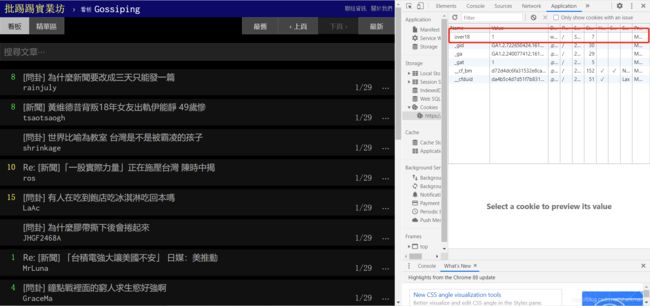
点击后cookie中会多出一个"over18=1"的内容,所以我们要把他也加到我们的程式中去。
#抓取PTT电影版的网页原始码(HTML)
import urllib.request as req
url="https://www.ptt.cc/bbs/Gossiping/index.html"
#建立一个Request物件,附加Request Headers 的资讯
request=req.Request(url,headers={
"cookie":"over18=1",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36"
})
with req.urlopen(request) as response:
data=response.read().decode("utf-8")
#资料解析
import bs4
root=bs4.BeautifulSoup(data,"html.parser")
titles=root.find_all("div",class_="title")
print(titles)
for title in titles:
if title.a !=None: #如果标题包含 a 标签(没有被删除)。印出来
print(title.a.string)
这样我们就可以直接爬取ptt八卦版的的标题啦。