hadoop框架流程图梳理
hadoop
- HDFS
- yarn
-
- yarn 资源调度
- yarn提交job的源码流程
- mapreduce
-
- 流程
- MR程序的几种提交运行模式
- 切片(split)
-
- 提交任务时获取切片split信息的流程
- MRAPPMaster的监控调度机制(shuffle)
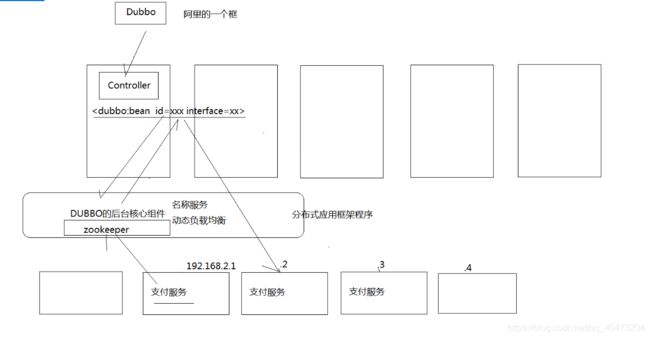
- Dubbo
- HA
-
- HDFSHA
- YARNHA
- HIVE
- Hbase
- Storm
HDFS
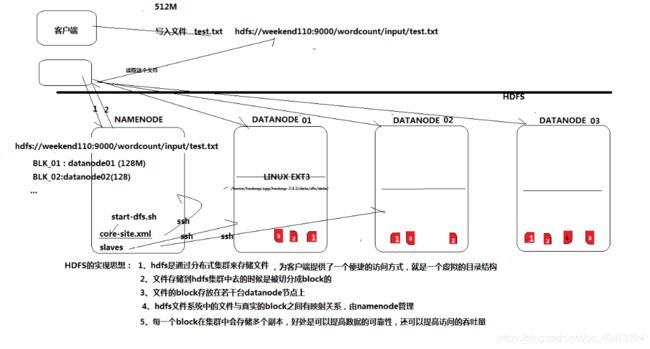
yarn
yarn 资源调度
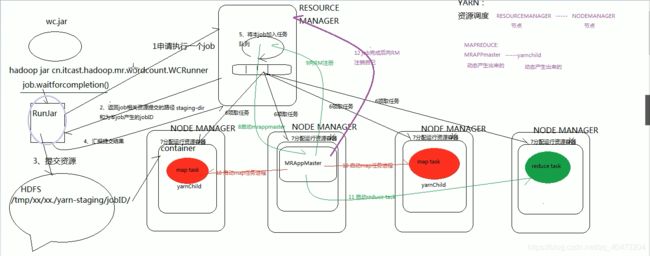
yarn提交job的源码流程
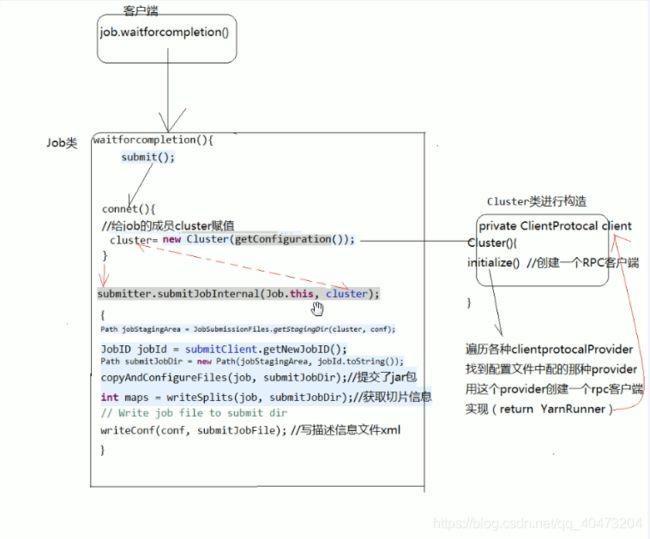
mapreduce
流程
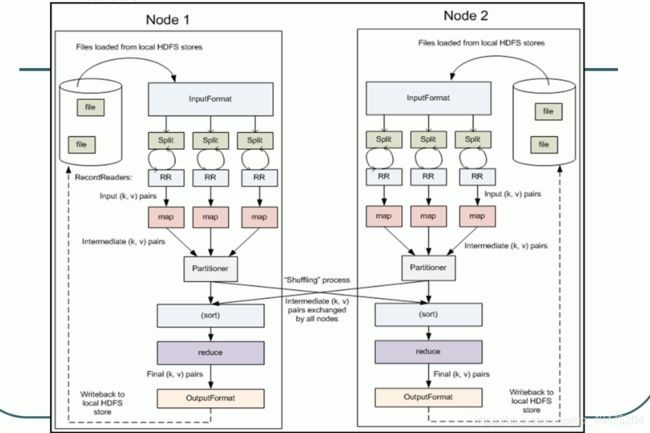
MR程序的几种提交运行模式
本地模型运行
1/在windows的eclipse里面直接运行main方法,就会将job提交给本地执行器localjobrunner执行
----输入输出数据可以放在本地路径下(c:/wc/srcdata/)
----输入输出数据也可以放在hdfs中(hdfs://weekend110:9000/wc/srcdata)
2/在linux的eclipse里面直接运行main方法,但是不要添加yarn相关的配置,也会提交给localjobrunner执行
----输入输出数据可以放在本地路径下(/home/hadoop/wc/srcdata/)
----输入输出数据也可以放在hdfs中(hdfs://weekend110:9000/wc/srcdata)
集群模式运行
1/将工程打成jar包,上传到服务器,然后用hadoop命令提交 hadoop jar wc.jar cn.itcast.hadoop.mr.wordcount.WCRunner
2/在linux的eclipse中直接运行main方法,也可以提交到集群中去运行,但是,必须采取以下措施:
----在工程src目录下加入 mapred-site.xml 和 yarn-site.xml
----将工程打成jar包(wc.jar),同时在main方法中添加一个conf的配置参数 conf.set(“mapreduce.job.jar”,“wc.jar”);
3/在windows的eclipse中直接运行main方法,也可以提交给集群中运行,但是因为平台不兼容,需要做很多的设置修改
----要在windows中存放一份hadoop的安装包(解压好的)
----要将其中的lib和bin目录替换成根据你的windows版本重新编译出的文件
----再要配置系统环境变量 HADOOP_HOME 和 PATH
----修改YarnRunner这个类的源码
切片(split)
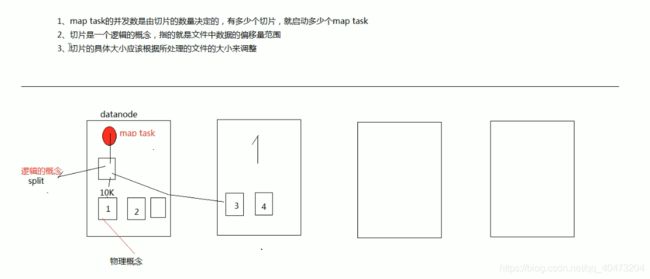
提交任务时获取切片split信息的流程

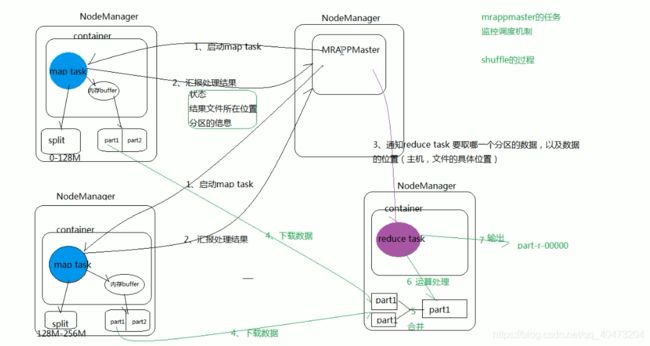
MRAPPMaster的监控调度机制(shuffle)
Dubbo
HA
HDFSHA
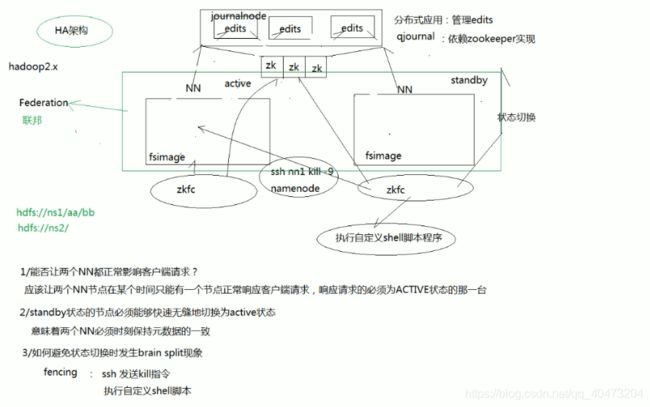
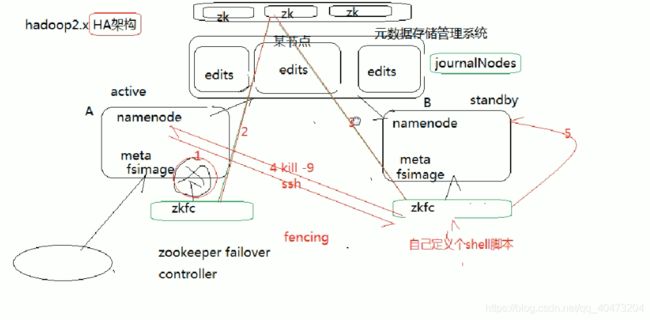
fencing机制防止脑裂(两个namenode同时处于active)(两种实现方式)
1 ssh kill(杀死异常namenode,将当前namenode设置为active)
但是这种方式,由于网络原因或者对方机器故障的原因,可能没有返回值。这时候,可以定义超时时间,调用自定义shell脚本
2 ?
federation :一个集群可以存在多对namenode,每一个namenode形成一个nameservice,多个nameservice在一个集群里面,这种方式就叫做联邦机制。
YARNHA
HIVE
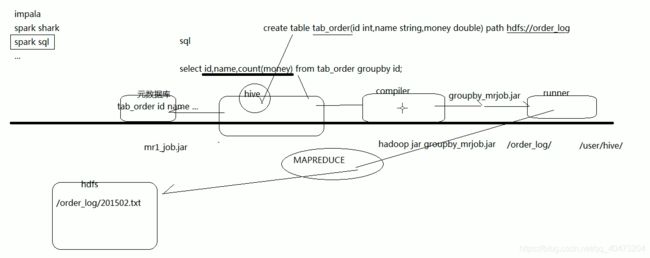
HIVE 不支持一条一条的insert数据插入,
其在建表的时候,若文件已经存在,一般将文件与数据对应起来,有两种方式
1.数据导入,将数据导导表里面,就是建立映射关系。
2.在建表时就是定了,对应哪些文件。
一条hive语句翻译成一个mr程序来执行。
Hbase

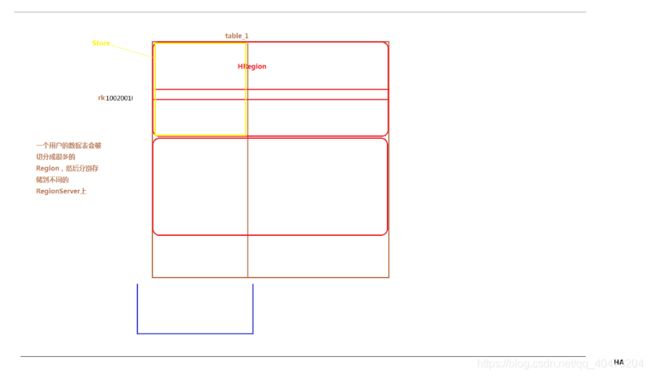
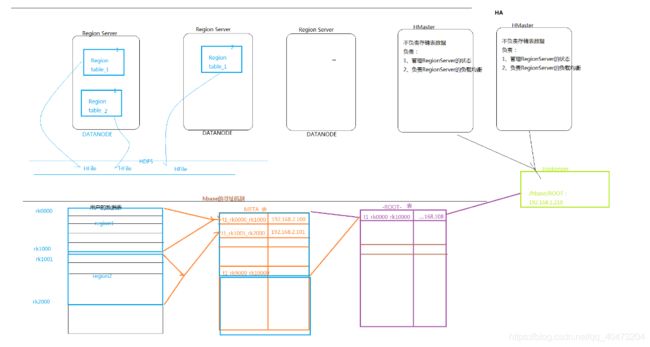
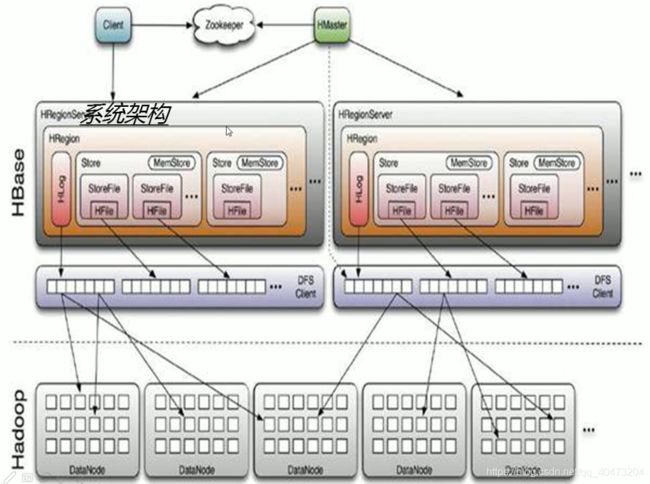
教程的示例语句(shell)
create 'mygirls',{NAME => 'base_info',VERSIONS => 3},{NAME=>'extra_info'}
put 'mygirls','0001','base_info:name','fengjie'
put 'mygirls','0001','base_info:age','18'
put 'mygirls','0001','base_info:sex','jipinnvren'
put 'mygirls','0001','extra_info:boyfriend','huangxiaoming'
get 'mygirls','0001'
put 'mygirls','0001','base_info:name','fengbaobao'
get 'mygirls','0001',{COLUMN => 'base_info:name',VERSIONS=> 10}
put 'mygirls','0001','base_info:name','fengfeng'
get 'mygirls','0001',{COLUMN => 'base_info:name',VERSIONS=> 10}
put 'mygirls','0001','base_info:name','qinaidefeng'
get 'mygirls','0001',{COLUMN => 'base_info:name',VERSIONS=> 10}
scan 'mygirls'
scan 'mygirls',{RAW => true, VERSIONS => 10}
Storm

storm的深入学习:
分布式共享锁的实现
事务topology的实现机制及开发模式
在具体场景中的跟其他框架的整合(flume/activeMQ/kafka(分布式的消息队列系统) /redis/hbase/mysql cluster)