前言
ThreadPoolExecutor是JDK1.5之后才有的线程池类,JDK帮我们实现了基于ThreadPoolExecutor创建的newSingleThreadExecutor、newFixedThreadPool、newCachedThreadPool等方便使用的线程池,那么为什么这些线程池在阿里巴巴的开发规范中却不推荐使用呢? 我相信读了这篇文章后你将豁然开朗。
提示:以下是本篇文章正文内容,下面案例可供参考
一、技术介绍
1.线程池是什么?
线程池是一种多线程处理形式,处理过程中将任务添加到队列,然后在创建线程后自动启动这些任务。线程池线程都是后台线程。每个线程都使用默认的堆栈大小,以默认的优先级运行,并处于多线程单元中。如果某个线程在托管代码中空闲(如正在等待某个事件),则线程池将插入另一个辅助线程来使所有处理器保持繁忙。如果所有线程池线程都始终保持繁忙,但队列中包含挂起的工作,则线程池将在一段时间后创建另一个辅助线程但线程的数目永远不会超过最大值。超过最大值的线程可以排队,但他们要等到其他线程完成后才启动。 ---摘自百度百科
二、使用步骤
1.ThreadPoolExecutor参数介绍

我们看下ThreadPoolExecutor类的execute方法底层源码进行分析

OK,根据判断可知:
1.如果正在运行的线程少于corePoolSize线程,请尝试使用给定命令作为其第一个任务启动一个新线程。
2.如果任务可以成功排队,那么我们仍然需要再次检查是否应该添加线程(因为现有线程自上次检查后就死掉了),或者自进入此方法后该池已关闭。因此,我们重新检查状态,并在必要时回滚排队,如果停止,或者如果没有线程,则启动一个新线程。
3.如果我们无法将任务排队,则尝试添加一个新线程。如果失败,我们知道我们已关闭或处于饱和状态,因此拒绝该任务。
2.newSingleThreadExecutor使用
代码如下(示例):
@Test
public void testNewSingleThreadExecutor() {
ExecutorService threaPool = Executors.newSingleThreadExecutor();
long start = System.currentTimeMillis();
System.out.println("线程池执行开始");
int idx = 10;
while (--idx > 0) {
threaPool.execute(() -> {
try {
LOGGER.info("线程执行中");
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException interruptedException) {
interruptedException.printStackTrace();
}
});
}
threaPool.shutdown();
for (; ; ) {
if (threaPool.isTerminated())
break;
}
long end = System.currentTimeMillis();
System.out.println("线程池执行结束,总用时:" + (end - start) + " ms ");
}
复制代码此测试方法运行的结果如下: 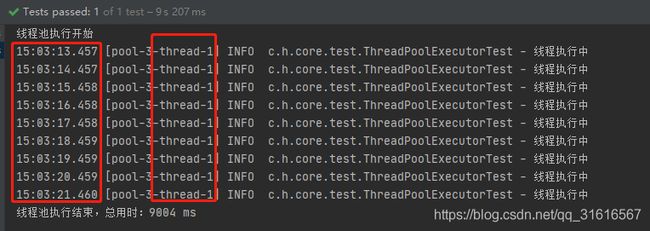 注意看我用红框标记的地方,只采用了1个线程去执行,原理是什么呢?让我们看看newSingleThreadExecutor的源码
注意看我用红框标记的地方,只采用了1个线程去执行,原理是什么呢?让我们看看newSingleThreadExecutor的源码
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue()));
}
复制代码 构建了ThreadPoolExecutor线程池,核心线程1个,最大执行线程1个,等待队列是LinkedBlockingQueue,咱们再点进去看看LinkedBlockingQueue默认构造函数是啥 
 可以看到这是默认时一个容量为Interger.MAX_VALUE的队列
可以看到这是默认时一个容量为Interger.MAX_VALUE的队列
结论:newSingleThreadExecutor是一个核心线程为1,线程池中允许最大线程为1,等待队列为无限大的线程池,所以你应该知道为什么它只开了一个线程去执行了。
3.newFixedThreadPool使用
代码如下(示例):
@Test
public void testNewFixedThreadPool() {
ExecutorService threaPool = Executors.newFixedThreadPool(5);
long start = System.currentTimeMillis();
System.out.println("线程池执行开始");
int idx = 20;
while (--idx >= 0) {
threaPool.execute(() -> {
try {
LOGGER.info("线程执行中");
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException interruptedException) {
interruptedException.printStackTrace();
}
});
}
threaPool.shutdown();
for (; ; ) {
if (threaPool.isTerminated())
break;
}
long end = System.currentTimeMillis();
System.out.println("线程池执行结束,总用时:" + (end - start) + " ms ");
}
复制代码先来看下执行结果
 OK,看下执行结果可知,只开启了5个线程,每次批量的执行5个,接下来咱们看看它的源码
OK,看下执行结果可知,只开启了5个线程,每次批量的执行5个,接下来咱们看看它的源码  也同样的构造了ThreadPoolExecutor线程池,参数为:核心线程数、线程池最大线程数都为传入的参数,单元测试传的是5,所以开5个线程运行,运行完重复使用这5个线程去执行队列中的。
也同样的构造了ThreadPoolExecutor线程池,参数为:核心线程数、线程池最大线程数都为传入的参数,单元测试传的是5,所以开5个线程运行,运行完重复使用这5个线程去执行队列中的。
结论:newFixedThreadPool是一个根据传入参数来执行固定大小的线程池
4.newCachedThreadPool使用
代码如下(示例):
@Test
public void testNewCachedThreadPool() {
ExecutorService threaPool = Executors.newCachedThreadPool();
long start = System.currentTimeMillis();
System.out.println("线程池执行开始");
int idx = 200;
while (--idx >= 0) {
threaPool.execute(() -> {
LOGGER.info("线程执行中");
});
}
threaPool.shutdown();
for (; ; ) {
if (threaPool.isTerminated())
break;
}
long end = System.currentTimeMillis();
System.out.println("线程池执行结束,总用时:" + (end - start) + " ms ");
}
复制代码OK,这里跟上面不同,咱们执行200个线程,咋们先看执行结果,  很明显可以看到跟上面的不同,在执行时间很短的任务时重复的利用线程去执行,原因是什么呢?咱们先看源码
很明显可以看到跟上面的不同,在执行时间很短的任务时重复的利用线程去执行,原因是什么呢?咱们先看源码  创建了一个核心线程数为0,最大执行线程为Interger.MAX_VALUE,并且注意这里用了SynchronousQueue这个队列,SynchronousQueue没有容量,是无缓冲等待队列,是一个不存储元素的阻塞队列,会直接将任务交给消费者,必须等队列中的添加元素被消费后才能继续添加新的元素。
创建了一个核心线程数为0,最大执行线程为Interger.MAX_VALUE,并且注意这里用了SynchronousQueue这个队列,SynchronousQueue没有容量,是无缓冲等待队列,是一个不存储元素的阻塞队列,会直接将任务交给消费者,必须等队列中的添加元素被消费后才能继续添加新的元素。
SynchronousQueue,至于它的底层原理后期会写一篇专门关于队列的文章,这里不再细说
结论:newCachedThreadPool它是一个可以无限扩大的线程池,当前没有空闲线程时它会创建一个新的线程,如果有空闲线程会使用空闲线程处理
5.线程池的使用推荐
通过以上的测试案例与源码分析,相信大家对线程池有了一定的认识,总结如下:
1.newSingleThreadExecutor:只开启一个线程运行,处理效率较慢,阻塞队列大小是没有大小限制的,如果队列堆积数据太多会造成资源消耗
2.newFixedThreadPool:一个固定大小的线程池,可控制线程并发数量,但阻塞队列大小是没有大小限制的,如果队列堆积数据太多会造成资源消耗
3.newCachedThreadPool:比较适合处理执行时间较短的业务,但线程若是无限制的创建,可能会导致内存占用过多而产生OOM,并且会造成cpu过度切换消耗太多资源。
所以使用推荐是根据业务场景实现自定义ThreadPoolExecutor,特别是高并发大流量系统,这也是为什么阿里内部不推荐使用以上几种线程池的原因。