程序猿成长日记(四): Pytorch框架, 用CharRNN实现的自动诗句生成(原理及代码)
Pytorch框架,CharRNN自动唐诗生成
- RNN简单解析
- 实验部分
-
- 初始语料处理
- 载入到数据类
- 定义Pytorch神经网络
- 预测生成部分
- 主函数部分
- 结果展示
RNN简单解析
RNN(RecurrentNeuralNetwork)又称循环神经网络, 以其独有的隐藏状态的输入h在序列问题和文本问题上,有比较好的实现.为了做个对比我们先来看看普通的神经网络长什么样子:
然后我们再来看看RNN的标准架构:

其实RNN同普通的DNN网络差异并不大,主要是多了一个h隐藏状态的输入.这个隐藏状态h是为了保存上一个节点对于下一个节点的影响而存在,这也就是为什么,RNN神经网络能够具有一定意义上的记忆能力. 对于每一个传播节点,他的前向传播同一般的神经网络差异不大, 公式如下:
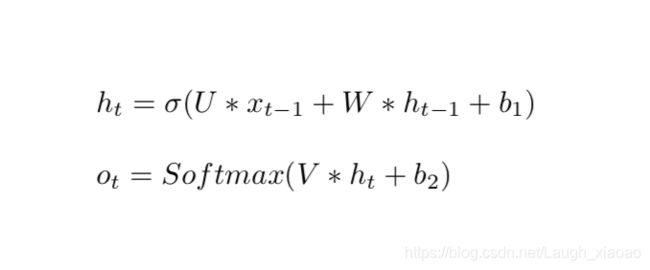
虽然看着RNN的前馈公式并不复杂,但RNN本身的训练却十分困难,一般是采用BPTT的方法,但也经常会遭遇到梯度消失和梯度爆炸的状况.具体的公式推导可以看:
循环神经网络(一般RNN)推导
实验部分
既然我们已经知道了RNN的基本架构,那么,我们又该如何将RNN用作我们的文本生成呢?话不多说,一起来看.
其实用RNN来生成的思想很简单, 就是将前一个字进行词嵌入,后一个字作为标签,将这个组合输入到RNN的网络里面
等待训练拟合之后,再用一个引导词,训练出它的预测结果,再用其预测结果,来训练下一个词,循环往复,从而实现RNN生成文本的效果.
话fa不多说,show your the code!
初始语料处理
首先对我们的语料进行处理,收集词袋,将每一行的诗句按字分割,然后组装word2num和num2word的两个字典初始的处理工作就做好了.
(没有采用jieba分词的原因是,分割出来的不等长字串处理比较麻烦, 故就凑合了一下,有可能分词后的会更准确,有待一起努力!)
def DataProcess(data):
"""
:param data:
:return: 处理过后的词
"""
SplitLine = []
BagOfWords = []
for line in data:#居然不需要精确划分词句.....
# line = jieba.lcut(line) # 精确模式分割诗句
# line = " ".join(line).split(" ")
line = list(line)
SplitLine.append(line)
BagOfWords += line
BagOfWords = set(BagOfWords)
# 将词语转换成对应的数值
NumOfWord = [[_] for _ in range(len(BagOfWords))]
ec2 = OneHotEncoder()
NumOfVec = ec2.fit_transform(NumOfWord).toarray()
NumOfVec = NumOfVec.astype(int).tolist() # 数值转换成onehot向量并存储
word2num = dict(zip(BagOfWords, [_[0] for _ in NumOfWord]))
num2word = dict(zip([_[0] for _ in NumOfWord], BagOfWords))
SplitLineVec = []
for line in SplitLine:
for i, word in enumerate(line): # 数字转换成对应的数值
line[i] = word2num[word]
SplitLineVec.append(line)
return BagOfWords, word2num, num2word, SplitLineVec, NumOfVec
载入到数据类
在完成对数据的处理之后,我们就将其载入到Pytorch的自定义数据类中,~~讲道理一直报错…最后没有用到dataloader了就…~~基本就是将每一行的第一个字符移动到最后,从而实现基本(instance-label)的对子了,具体如下:
class TextDataset(object):
"""torch默认的数据类"""
def __init__(self, arr):
self.arr = arr
def __getitem__(self, item):
x = torch.LongTensor(self.arr[item])
y = torch.zeros(x.shape, dtype=torch.int64)
# 将输入的第一个字符作为最后一个输入的 label
y[:-1], y[-1] = x[1:], x[0]
return x, y
def __len__(self):
return self.arr.shape[0]
定义Pytorch神经网络
神经网络部分就比较简单了, Embedding+GRU+Relu+Linear输出层,
损失函数由于是nn.CrossEntropyLoss()所以不用在加softmax层了.需要注意的是,RNN喂入数据的维度比较奇葩,(seq_length,batch,input_dim),解析一下:batch固定会是1代表每一次输入的都是一行序列,原本seq_length则根据每一句话的词不一样,但我们是按照字划分,所以目前相同,input_dim则根据每个人的设定不一样了.
话到这里,看代码吧.
class Rnn(nn.Module):
def __init__(self, Vocab_Size, num_layers=1, embed_size=256, hidden_size=128):
super(Rnn, self).__init__()
self.Vocab_Size = Vocab_Size
self.num_layers = num_layers
self.embed_size = embed_size
self.hidden_size = hidden_size
self.embedding = nn.Embedding(self.Vocab_Size, self.embed_size) # 实现词嵌入
self.rnn = nn.GRU(
input_size=self.embed_size,
hidden_size=self.hidden_size,
num_layers=self.num_layers,
)
self.Dropout = nn.Dropout(0.5)
self.out = nn.Linear(self.hidden_size, self.Vocab_Size) # 输出多分类词数用于下一次输入
def forward(self, x, h_state=None):
batch = x.size(0)
if h_state is None:
h_state = torch.zeros(self.num_layers, batch, self.hidden_size)
x = self.embedding(x) # 首先实现词嵌入,按照词数目自动转换成对应的嵌入向量,不必再onehot自己编啦!
x = x.permute(1, 0, 2)
out, h_state = self.rnn(x, h_state)
le, mb, hd = out.shape
out = out.view(le * mb, hd)
out = self.Dropout(out)
out = self.out(out)
return out, h_state
预测生成部分
先对隐藏状态进行预热,之后循环输入循环预测,最后输出指定长度的诗句即可.
这里的Pick_Top_N是选取预测概率的前5个字,按照一个给定的概率抽取一个字作为预测结果,增加了随机性.
def Pick_Top_N(preds, top_n=5):
"""按概率随机选取前n个预测值作为最后的输出"""
top_prob, top_label = torch.topk(preds, top_n, dim=1)
top_prob += abs(min(top_prob)) #防止出现小数
top_prob /= torch.sum(top_prob)
top_prob = top_prob.squeeze(0).numpy()
top_label = top_label.squeeze(0).numpy()
return np.random.choice(top_label, size=1, p=top_prob)
def GeneratePoem(model, train_set):
"""预测生成部分:"""
Line_Length = 20 #默认词的长度是20个词
# 对当前的状态进行预热
init_state = None
init_X, _ = train_set.__getitem__(rand)
for i in range(len(init_X) // 2):
input = init_X[i].reshape(1, 1)
_, init_state = model(input, init_state)
#获取预热后的最后一个元素
last_x = init_X[len(init_X)//2 - 1]
result = [] #生成的结果
for j in range(Line_Length):
last_x = last_x.reshape(1, 1)
out, init_state = model(last_x, init_state)
pre = Pick_Top_N(out.data, 1)
result.append(pre)
return result
主函数部分
最后是主函数部分,可以保存一定epoch下的代码,进行比较,代码如下:
if __name__ == '__main__':
data = LoadData("../poetry.txt", "r")
BagOfWords, word2num, num2word, SplitLineVec, NumOfVec = DataProcess(data[:1500])
model = Rnn(BagOfWords.__len__())
print(BagOfWords.__len__())
# 定义损失函数等
loss_func = nn.CrossEntropyLoss() # 交叉熵
optimizer = torch.optim.Adam(model.parameters(), lr=0.02)
train_set = TextDataset(np.array(SplitLineVec))
EPOCHES = 12 # 迭代次数
#BATCH 固定了为1,即一次只输入一行语句,采用的SGD的方法训练
"""训练部分"""
for epoch in range(EPOCHES):
train_loss = 0
for length in range(SplitLineVec.__len__()):
batch_x, batch_y = train_set.__getitem__(length)
#调整数据喂入的维度 wordnum * batchsize
batch_x = batch_x.reshape(batch_x.size(0), 1)
prediction, _ = model(batch_x)
loss = loss_func(prediction, batch_y)
optimizer.zero_grad() # 清空原有梯度 否则梯度会累加
loss.backward() # 自动调用BP
nn.utils.clip_grad_norm(model.parameters(), 5) # 梯度裁剪
optimizer.step() # 更新参数
train_loss += loss.data.numpy()
print("\nEpoch: {}".format(epoch + 1), " Loss: {:.3f}".format(np.exp(train_loss / SplitLineVec.__len__())))
#用训练好的模型生成数据
rand = random.randint(0, SplitLineVec.__len__())
result = GeneratePoem(model, train_set, NumOfVec)
result = [num2word[int(_)] for _ in result]
Gen_Poem = []
for i in range(0, 16, 5):
Gen_Poem.append(''.join(result[i:i+5]))
print(result)
print(Gen_Poem)
with open("MyGeneratePoems.txt", 'a+') as f:
f.write("EPOCHES: {}\n".format(EPOCHES))
for line in Gen_Poem:
f.write(line+" ")
f.write("\n")
结果展示
让我们看看不同epoch下的生成诗句吧!

讲道理,有些诗句还是可以的,但是训练还是不好,究其原因
- 个人PC端算力有限,仅用了1000行诗句
- epoch数很小
- 字分割而非词分割,效果不好.
好了,到此实验全部结束了,祝大家玩的开心 一同进步
完整github代码参考
参考文献:
简单的Char RNN生成文本
Char RNN原理介绍以及文本生成实践
循环神经网络(RNN)原理通俗解释
RNN以及LSTM的介绍和公式梳理
《The Unreasonable Effectiveness of Recurrent Neural Networks》阅读笔记
The Unreasonable Effectiveness of Recurrent Neural Networks