rnn pytorch
Today, we’ll continue our journey through the fascinating world of natural language processing (NLP) by introducing the operation and use of recurrent neural networks to generate text from a small initial text. This type of problem is known as language modeling and is used when we want to predict the next word or character in an input sequence of words or characters.
今天,我们将通过介绍递归神经网络的操作和使用以从较小的初始文本生成文本,继续在迷人的自然语言处理(NLP)世界中前进。 这种类型的问题称为语言建模,在我们要预测单词或字符的输入序列中的下一个单词或字符时使用。
But in language-modeling problems, the presence of words isn’t the only thing that’s important but also their order — i.e., when they’re presented in the text sequence. In other words, the context that surrounds each word becomes a fundamental piece to predict the next one.
但是在语言建模问题中,单词的存在不是唯一重要的,而是单词的顺序,即当它们以文本顺序显示时。 换句话说,每个单词周围的上下文成为预测下一个单词的基础。
And in this scenario, the traditional NLP methods, based on frequencies and probabilities of the words, aren’t very effective because they’re based on the premise of the independence of the words from each other.
在这种情况下,基于单词的频率和概率的传统NLP方法不是很有效,因为它们基于单词彼此独立的前提。
Here is where RNN networks can become a fundamental tool because of their ability to remember the different parts of a series of inputs, which means they can take the previous parts of a sentence into account to interpret context.
在这里,RNN网络可以成为基本工具,因为它们能够记住一系列输入的不同部分,这意味着它们可以考虑句子的前部分来解释上下文。
RNN的简要说明 (Brief Description of RNN)
In summary, in a vanilla neural network, the output of a layer is a function or transformation of its input applying some learnable weights.
总之,在普通神经网络中,层的输出是应用一些可学习的权重的函数或输入的变换。
In contrast, in an RNN, not only the input is taken into account but also the context or previous state of the network itself. As we progress in the forward pass through the network, it builds a representation of its state that aims to collect information obtained in previous steps, which is called the hidden state.
相反,在RNN中,不仅要考虑输入,还要考虑网络本身的上下文或先前状态。 当我们通过网络前进时,它会建立其状态的表示形式,该状态旨在收集在先前步骤中获得的信息,称为隐藏状态。
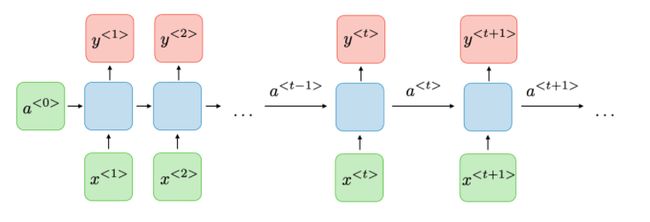
Here, for each timestep t, we have an activation a
在这里,对于每个时间步长t ,都有一个激活a

Therefore, each element of the sequence that passes through the network contributes to the current state and the latter to the output. And both the input and the previous hidden state incorporate new information to update the value of the hidden state for an arbitrarily long sequence of observations. RNNs can remember previous entries, but this capacity is restricted in time or steps — it was one of the first challenges to solve with these networks.
因此,通过网络的序列中的每个元素都有助于当前状态,后者有助于输出。 输入和先前的隐藏状态都包含新信息,以针对任意长的观察序列更新隐藏状态的值。 RNN可以记住以前的条目,但是这种能力在时间或步骤上受到限制-这是使用这些网络解决的首要挑战之一。
“The longer the input series is, the more the network “forgets”. Irrelevant data is accumulated over time and it blocks out the relevant data needed for the network to make accurate predictions about the pattern of the text. This is referred to as the vanishing gradient problem.” — Wikipedia
“输入序列越长,网络“遗忘”就越多。 不相关的数据会随着时间的推移而累积,并且会阻塞网络对文本样式进行准确预测所需的相关数据。 这被称为消失梯度问题。” —维基百科
You can dive deeper into that problem at this link. This a common problem with very deep neural networks. In the field of NLP and RNN, to solve this problem some advanced architectures have been developed, like LSTM and GRUs.
您可以在此链接上更深入地研究该问题。 这是非常深的神经网络的常见问题。 在NLP和RNN领域,为了解决此问题,已经开发了一些高级架构,例如LSTM和GRU。
长短期记忆(LSTM) (Long Short-Term Memory (LSTM))
LSTM networks seek to preserve relevant information from much earlier steps, for which they contain multiple gates that control how much information to keep or delete from the input and the previous states:
LSTM网络试图从更早的步骤中保留相关信息,为此,它们包含多个门,这些门控制从输入和先前状态保留或删除多少信息:

W is the recurrent connection between the previous hidden layer and the current hidden layer. U is the weight matrix that connects the inputs to the hidden layer, and C is a candidate hidden state that’s computed based on the current input and the previous hidden state. C is the internal memory of the unit.
W是前一个隐藏层和当前隐藏层之间的循环连接。 U是将输入连接到隐藏层的权重矩阵, C是根据当前输入和先前的隐藏状态计算出的候选隐藏状态。 C是单元的内部存储器。
- Forget gate: How much information from the past should be considered now? 忘记门:现在应该考虑多少过去的信息?
- Input gate + cell gate: Should we add information to the state from the input and how much? 输入门+单元门:我们应该从输入中向状态添加信息吗?
- Output gate: How much information should we output from the previous state? 输出门:我们应该从以前的状态输出多少信息?
“In a similar way, an LSTM works as follows:
“以类似的方式,LSTM的工作方式如下:
• It keeps track not just of short term memory, but also of long term memory
•它不仅可以跟踪短期记忆,还可以跟踪长期记忆
• In every step of the sequence, the long and short term memory in the step get merged
•在序列的每个步骤中,该步骤中的长期和短期记忆将合并
• From this, we get a new long term memory, short term memory, and prediction”
•由此,我们获得了新的长期记忆,短期记忆和预测”
— Peter Foy, “An Introduction to Recurrent Neural Networks & LSTMs”
— Peter Foy,“递归神经网络和LSTM简介”
在Amazon SageMaker中创建和部署ML模型 (Create and Deploy an ML Model in Amazon SageMaker)
First, we enumerate the steps in the general outline for SageMaker projects using a notebook instance:
首先,我们列举了使用笔记本实例的SageMaker项目的总体概述中的步骤:
- Download or otherwise retrieve the data. 下载或以其他方式检索数据。
- Process/prepare the data. 处理/准备数据。
- Upload the processed data to S3. 将处理后的数据上传到S3。
- Train a chosen model. 训练选定的模型。
- Test the trained model (typically using a batch transform job). 测试训练好的模型(通常使用批处理转换作业)。
- Deploy the trained model. 部署经过训练的模型。
- Use the deployed model. 使用部署的模型。
For this project, you’ll be following the steps in the general outline with some modifications, we are going to test the model on the deployed model.
对于本项目,您将按照一般概述中的步骤进行一些修改,我们将在部署的模型上测试模型。
The source code is publicly available in my github repository, this is the link to the full notebook. Here we will only show the more relevant sections.
源代码可在我的github存储库中公开获得,这是完整笔记本的链接。 在这里,我们将仅显示更相关的部分。
下载并准备数据集 (Download and prepare the data set)
Steps 1 and 2 aren’t specific to the SageMaker tool; they’re essentially the same regardless of the platform. So we’re not going to discuss them; we’ll just mention the source of our data set.
步骤1和2并非特定于SageMaker工具; 无论平台如何,它们本质上都是相同的。 因此,我们不再讨论它们。 我们将仅提及数据集的来源。
First, we’ll define the sentences that we want our model to output when fed with the first word or the first few characters. Our data set is a text file containing Shakespeare’s plays or books, from where we’ll extract a sequence of chars to use as the input to our model. Then our model will learn how to complete sentences like “Shakespeare would do.” This data set can be downloaded from Karpathy’s GitHub account.
首先,我们将定义我们的模型输出第一个单词或前几个字符后要输出的句子。 我们的数据集是一个文本文件,其中包含莎士比亚的戏剧或书籍,我们将从中提取一系列字符作为模型输入。 然后我们的模型将学习如何完成“莎士比亚会做”之类的句子。 可以从Karpathy的GitHub帐户下载此数据集。
Then, we only need to lowercase the text and create the corresponding dictionaries: char2int to transform the words to integers and int2char for the reverse process.
然后,我们只需要小写文本并创建相应的字典:char2int即可将单词转换为整数,并将int2char转换为逆过程。
class CharVocab:
''' Create a Vocabulary for '''
def __init__(self, type_vocab,pad_token='', eos_token='', unk_token=''): #Initialization of the type of vocabulary
self.type = type_vocab
#self.int2char ={}
self.int2char = []
if pad_token !=None:
self.int2char += [pad_token]
if eos_token !=None:
self.int2char += [eos_token]
if unk_token !=None:
self.int2char += [unk_token]
#self.int2char[1]=eos_token
#self.int2char[2]=unk_token
self.char2int = {}
def __call__(self, text): #When called, adds the values of parameters x_1 and x_2, prints and returns the result
# Join all the sentences together and extract the unique characters from the combined sentences
chars = set(''.join(text))
# Creating a dictionary that maps integers to the characters
self.int2char += list(chars)
# Creating another dictionary that maps characters to integers
self.char2int = {char: ind for ind, char in enumerate(self.int2char)}
vocab = CharVocab('char',None,None,'')
vocab(sentences)
print('Length of vocabulary: ', len(vocab.int2char))
print('Int to Char: ', vocab.int2char)
print('Char to Int: ', vocab.char2int) 编码文本并创建输入和目标数据集(Encode the text and create the input and target data sets)
Now we can encode our text, replacing every character by the integer value in the dictionary. When we have our data set unified and prepared, we should do a quick check to see an example of the data our model will be trained on. This is generally a good idea, as it allows you to see how each of the further processing steps affect the reviews, and it also ensures that the data has been loaded correctly.
现在我们可以对文本进行编码,将每个字符替换为字典中的整数值。 统一并准备好数据集后,我们应该进行快速检查,以查看将要训练模型的数据的示例。 通常,这是一个好主意,因为它使您可以查看每个进一步的处理步骤如何影响审阅,还可以确保正确加载数据。
As we’re going to predict the next character in the sequence at each time step, we’ll have to divide each sentence into:
因为我们要在每个时间步预测序列中的下一个字符,所以我们必须将每个句子划分为:
Input data: The last input character should be excluded as it doesn’t need to be fed into the model (it’s the target label for the last input character)
输入数据:应该排除最后一个输入字符,因为它不需要输入到模型中(这是最后一个输入字符的目标标签)
Target/ground-truth label: This is one timestep ahead of the input data. as this will be the correct answer for the model at each timestep corresponding to the input data.
目标/地面真相标签:这比输入数据提前一个时间步。 因为这将是在每个时间步长对应于输入数据的模型的正确答案。
def one_hot_encode(indices, dict_size):
''' Define one hot encode matrix for our sequences'''
# Creating a multi-dimensional array with the desired output shape
# Encode every integer with its one hot representation
features = np.eye(dict_size, dtype=np.float32)[indices.flatten()]
# Finally reshape it to get back to the original array
features = features.reshape((*indices.shape, dict_size))
return features
def encode_text(input_text, vocab, one_hot = False):
# Replace every char by its integer value based on the vocabulary
output = [vocab.char2int.get(character,0) for character in input_text]
if one_hot:
# One hot encode every integer of the sequence
dict_size = len(vocab.char2int)
return one_hot_encode(output, dict_size)
else:
return np.array(output)
# Encode the train dataset
train_data = encode_text(sentences, vocab, one_hot = False)
# Create the input sequence, from 0 to len-1
input_seq=train_data[:-1]
# Create the target sequence, from 1 to len. It is right-shifted one place
target_seq=train_data[1:]将数据上传到Amazon S3(Upload the Data to Amazon S3)
Now, we’ll need to upload the training dataset to S3 in order for our training code to access it. In fact, we’ll save it locally, and it’ll be uploaded to S3 later on when running the training.
现在,我们需要将训练数据集上传到S3,以便我们的训练代码访问它。 实际上,我们会将其保存在本地,然后在进行培训时将其上传到S3。
import sagemaker
# Get the session id
sagemaker_session = sagemaker.Session()
# Get the bucet, in our example the default buack
bucket = sagemaker_session.default_bucket()
# Set the S3 subfolder where our data will be stored
prefix = 'sagemaker/char_level_rnn'
# Get the role for permission
role = sagemaker.get_execution_role()
nput_data = sagemaker_session.upload_data(path=DATA_PATH, bucket=bucket, key_prefix=prefix)Note: The cell above uploads the entire contents of our data directory. This includes the char_dict.pkl(char2int) and int_dict.pkl (int2char) files. This is fortunate as we’ll need this later on when we create an endpoint that accepts an arbitrary input text. For now, we’ll just take note of the fact that it resides in the data directory (and so also in the S3 training bucket) and that we’ll need to make sure it gets saved in the model directory.
注意:上面的单元格上载了数据目录的全部内容。 这包括char_dict.pkl (char2int)和int_dict.pkl (int2char)文件。 这很幸运,因为稍后我们将创建一个接受任意输入文本的终结点时将需要它。 现在,我们只需要注意以下事实:它位于数据目录中(因此也位于S3训练存储桶中),并且需要确保将其保存在模型目录中。

建立和训练PyTorch模型 (Build and Train the PyTorch Model)
A model in the SageMaker framework, in particular, comprises three objects:
SageMaker框架中的模型尤其包含三个对象:
- Model artifacts, 模型工件
- Training code培训守则
- Inference code推断码
Each of these interact with one another.
这些中的每一个都相互影响。
We’ll start by implementing our own neural network in PyTorch along with a training script. For the purposes of this project, we need to provide the model object implementation in the model.py file, inside of the train folder.
我们将从在PyTorch中实现我们自己的神经网络以及训练脚本开始。 就本项目而言,我们需要在train文件夹内的model.py文件中提供模型对象实现。
import torch
from torch import nn
from torch.autograd import Variable
class RNNModel(nn.Module):
def __init__(self, vocab_size, embedding_size, hidden_dim, n_layers, drop_rate=0.2):
super(RNNModel, self).__init__()
# Defining some parameters
self.hidden_dim = hidden_dim
self.embedding_size = embedding_size
self.n_layers = n_layers
self.vocab_size = vocab_size
self.drop_rate = drop_rate
self.char2int = None
self.int2char = None
# Dropout layer
self.dropout = nn.Dropout(drop_rate)
# RNN Layer
self.rnn = nn.LSTM(embedding_size, hidden_dim, n_layers, dropout=drop_rate, batch_first = True)
# Fully connected layer
self.decoder = nn.Linear(hidden_dim, vocab_size)
def forward(self, x, state):
# shape: [batch_size, seq_len, embedding_size]
rnn_out, state = self.rnn(x, state)
#print('Out RNN shape: ', rnn_out.shape)
# rnn_out shape: [batch_size, seq_len, rnn_size]
# hidden shape: [num_layers, batch_size, rnn_size]
rnn_out = self.dropout(rnn_out)
# shape: [batch_size, seq_len, rnn_size]
# Stack up LSTM outputs using view
# you may need to use contiguous to reshape the output
rnn_out = rnn_out.contiguous().view(-1, self.hidden_dim)
logits = self.decoder(rnn_out)
# output shape: [seq_len * batch_size, vocab_size]
return logits, state
def init_state(self, device, batch_size=1):
"""
initialises rnn states.
"""
return (torch.zeros(self.n_layers, batch_size, self.hidden_dim).to(device),
torch.zeros(self.n_layers, batch_size, self.hidden_dim).to(device))The model is very simple with just a couple of layers:
该模型非常简单,只有几层:
- The LSTM layer, acting as an encoder LSTM层,充当编码器
- A dropout layer to reduce overfitting辍学层,以减少过度拟合
- The decoder or a fully connected or dense layer that returns the probability of every character to be the next one解码器或完全连接或密集的层,返回每个字符成为下一个字符的概率
在SageMaker上训练模型(Train the Model on SageMaker)
When a PyTorch model is constructed in SageMaker, an entry point must be specified. This is the Python file that’ll be executed when the model is trained. Inside of the train directory is a file called train.py that contains most of the necessary code to train our model.
在SageMaker中构建PyTorch模型时,必须指定一个入口点。 这是训练模型后将执行的Python文件。 train目录内有一个名为train.py的文件,其中包含训练模型所需的大多数代码。
Note: The train_main() function must be pasted into the train/train.py file where required.
注意: train_main()必须将train_main()函数粘贴到train/train.py文件中。
def train_main(model, optimizer, loss_fn, batch_data, num_batches, val_batches, batch_size, seq_len, n_epochs, clip_norm, device):
# Training Run
for epoch in range(1, n_epochs + 1):
start_time = time.time()
# Store the loss in every batch iteration
epoch_losses =[]
# Init the hidden state
hidden = model.init_state(device, batch_size)
# Train all the batches in every epoch
for i in range(num_batches-val_batches):
# Get the next batch data for input and target
input_batch, target_batch = next(batch_data)
# Onr hot encode the input data
input_batch = one_hot_encode(input_batch, model.vocab_size)
# Tranform to tensor
input_data = torch.from_numpy(input_batch)
target_data = torch.from_numpy(target_batch)
# Create a new variable for the hidden state, necessary to calculate the gradients
hidden = tuple(([Variable(var.data) for var in hidden]))
# Move the input data to the device
input_data = input_data.to(device)
# Set the model to train and prepare the gradients
model.train()
optimizer.zero_grad() # Clears existing gradients from previous epoch
# Pass Fordward the RNN
output, hidden = model(input_data, hidden)
output = output.to(device)
# Move the target data to the device
target_data = target_data.to(device)
target_data = torch.reshape(target_data, (batch_size*seq_len,))
# Calculate the loss
loss = loss_fn(output, target_data.view(batch_size*seq_len))
# Save the loss
epoch_losses.append(loss.item()) #data[0]
# Does backpropagation and calculates gradients
loss.backward()
# clip gradient norm
nn.utils.clip_grad_norm_(model.parameters(), clip_norm)
# Updates the weights accordingly
optimizer.step()
# Now, when the epoch is finished, evaluate the model on validation data
model.eval()
val_hidden = model.init_state(device, batch_size)
val_losses = []
for i in range(val_batches):
# Get the next batch data for input and target
input_batch, target_batch = next(batch_data)
# Onr hot encode the input data
input_batch = one_hot_encode(input_batch, model.vocab_size)
# Tranform to tensor
input_data = torch.from_numpy(input_batch)
target_data = torch.from_numpy(target_batch)
# Create a new variable for the hidden state, necessary to calculate the gradients
hidden = tuple(([Variable(var.data) for var in val_hidden]))
# Move the input data to the device
input_data = input_data.to(device)
# Pass Fordward the RNN
output, hidden = model(input_data, hidden)
output = output.to(device)
# Move the target data to the device
target_data = target_data.to(device)
target_data = torch.reshape(target_data, (batch_size*seq_len,))
loss = loss_fn(output, target_data.view(batch_size*seq_len))
# Save the loss
val_losses.append(loss.item()) #data[0]
model.train()
print('Epoch: {}/{}.............'.format(epoch, n_epochs), end=' ')
print('Time: {:.4f}'.format(time.time() - start_time), end=' ')
print("Train Loss: {:.4f}".format(np.mean(epoch_losses)), end=' ')
print("Val Loss: {:.4f}".format(np.mean(val_losses)))
return epoch_lossesThe way that SageMaker passes hyperparameters to the training script is by arguments. These arguments can then be parsed and used in the training script. To see how this is done, take a look at the provided train/train.py file.
SageMaker将超参数传递给训练脚本的方式是通过参数。 然后,可以在训练脚本中解析并使用这些参数。 要查看如何完成此操作,请查看提供的train/train.py文件。
In summary, the main function in the train.py file executes the steps:
总之, train.py file的main函数执行以下步骤:
- Load the datasets 加载数据集
- Create the batch data generator创建批处理数据生成器
- Create or restore the model from a previous execution从先前的执行中创建或还原模型
- Train and evaluate the model训练和评估模型
- Save the model and dictionaries for inference保存模型和字典以进行推断
主要火车算法(Main train algo)
Once we have our train.py file, we’re ready to create a training job in SageMaker. First, we need to set which type of instance will run our training:
有了train.py文件后,就可以在SageMaker中创建培训工作了。 首先,我们需要设置哪种类型的实例将运行我们的训练:
Local: We don’t launch a real compute instance, just a container where our scripts will run. This scenario is very useful to test that the train script is working fine because it’s faster to run a container than a compute instance. But, finally, when we confirm that everything is working, we must change the instance type for a real training instance.
本地:我们不会启动真正的计算实例,而只是启动脚本的容器。 这种情况对于测试训练脚本是否正常工作非常有用,因为运行容器比计算实例要快。 但是,最后,当我们确认一切正常时,我们必须更改实际训练实例的实例类型。
ml.m4.4xlarge: This is a CPU instanceml.m4.4xlarge:这是一个CPU实例ml.p2.xlarge: A GPU instance to use when managing a big volume of data to train on.ml.p2.xlarge:管理大量数据进行训练时使用的GPU实例。
from sagemaker.pytorch import PyTorch
# Select the type of instance to use for training
#instance_type='ml.m4.4xlarge' # CPU instance
instance_type='ml.p2.xlarge' # GPU instance
#instance_type='local'
#Create the estimator object
estimator = PyTorch(entry_point="train.py",
source_dir="train",
role=role,
framework_version='0.4.0',
train_instance_count=1,
train_instance_type=instance_type,
hyperparameters={
'epochs': 50,
'hidden_dim': 512,
'n_layers': 2,
})
estimator.fit({'training': input_data})At this point, SageMaker launches a compute instance where our training code is executed, and it usually take hours or days depending on the data and model complexity (in our case it takes about 45-60 minutes). You can follow the training progress on Amazon CloudWatch if it’s printed out. At the end, the model artifacts are stored in S3, and they’ll be loaded during the deployment step.
此时,SageMaker将启动一个计算实例,在该实例中执行我们的训练代码,这通常需要数小时或数天,具体取决于数据和模型的复杂性(在我们的情况下,大约需要45-60分钟)。 如果已打印出来,您可以在Amazon CloudWatch上跟踪培训进度。 最后,模型工件存储在S3中,并将在部署步骤中加载它们。

定义推理算法(Define the Inference Algorithm)
Now it’s time to create some custom inference code so we can send the model an initial string that hasn’t been processed and determine the next character on the string.
现在是时候创建一些自定义推断代码,以便我们可以向模型发送尚未处理的初始字符串,并确定该字符串上的下一个字符。
By default, the estimator we created, when deployed, will use the entry script and directory that we provided when creating the model. However, since we wish to accept a string as our input and our model expects a processed text, we need to write some custom inference code.
默认情况下,我们创建的估算器在部署后将使用我们在创建模型时提供的输入脚本和目录。 但是,由于我们希望接受字符串作为输入,并且我们的模型需要经过处理的文本,因此我们需要编写一些自定义推断代码。
We’ll store the code for inference in the serve directory. Provided in this directory is the model.py file that we used to construct our model, a utils.py file that contains the one-hot-encode and encode_text preprocessing functions we used during the initial data processing, and predict.py, the file that’ll contain our custom inference code. Note also that requirements.txt is present, which will tell SageMaker what Python libraries are required by our custom inference code.
我们会将推理代码存储在serve目录中。 此目录中提供的是model.py文件,我们用于构建我们的模型,一个utils.py包含该文件one-hot-encode和encode_text我们的初始数据处理过程中所使用的预处理的功能,和predict.py ,文件其中将包含我们的自定义推断代码。 还请注意,存在requirements.txt ,它将告诉SageMaker我们的自定义推理代码需要哪些Python库。
When deploying a PyTorch model in SageMaker, you’re expected to provide four functions that the SageMaker inference container will use.
在SageMaker中部署PyTorch模型时,应该提供SageMaker推理容器将要使用的四个功能。
model_fn: This function is the same function that we used in the training script, and it tells SageMaker how to load our model. This function must be calledmodel_fn()and takes as its only parameter a path to the directory where the model artifacts are stored. This function must also be present in the Python file which we specified as the entry point. It also reads the saved dictionaries because they should be used during the inference process.model_fn:此函数与我们在训练脚本中使用的函数相同,它告诉SageMaker如何加载模型。 该函数必须称为model_fn()并且以其唯一参数为指向存储模型工件的目录的路径。 此函数还必须存在于我们指定为入口点的Python文件中。 它还会读取已保存的字典,因为应该在推理过程中使用它们。input_fn: This function receives the raw serialized input that has been sent to the model's endpoint, and its job is to deserialize and make the input available for the inference code. Later, we’ll mention what ourinput_fnfunction is doing.input_fn:此函数接收已发送到模型端点的原始序列化输入,其工作是反序列化并使输入可用于推理代码。 稍后,我们将提到我们的input_fn函数正在做什么。output_fn: This function takes the output of the inference code, and its job is to serialize this output and return it to the caller of the model's endpoint.output_fn:此函数获取推理代码的输出,其作用是序列化此输出并将其返回给模型端点的调用者。predict_fn: The heart of the inference script, this is where the actual prediction is done and is the function that you’ll need to complete.predict_fn:推理脚本的核心,这是完成实际预测的地方,并且是您需要完成的功能。
For the simple example we’re constructing during this project, the input_fn and output_fn methods are relatively straightforward. We’re required to accept a string as input, composed by the desired length of the output and the initial string. And we expect to return a single string as the output, the new text generated. You might imagine, though, that in a more complex application, the input or output may be image data or some other binary data that’d require some effort to serialize.
对于我们在此项目期间构建的简单示例, input_fn和output_fn方法相对简单。 我们需要接受一个字符串作为输入,该字符串由所需的输出长度和初始字符串组成。 我们希望返回一个字符串作为输出,即生成新文本。 但是,您可能会想到,在更复杂的应用程序中,输入或输出可能是图像数据或其他一些需要序列化的二进制数据。
Finally, we must build a predict_fn method that’ll receive the input string, encode it (char2int), one-hot encode, and send it to the model. Every output will be decoded (int2char) and appended to the final output string.
最后,我们必须构建一个predict_fn方法,该方法将接收输入字符串,对其进行编码(char2int),进行一次热编码,然后将其发送给模型。 每个输出将被解码(int2char)并附加到最终输出字符串。
Make sure you save the completed file as predict.py in the serve directory.
确保将完成的文件另存为serve目录中的predict.py 。
def sample_from_probs(probs, top_n=10):
"""
truncated weighted random choice.
"""
_, indices = torch.sort(probs)
# set probabilities after top_n to 0
probs[indices.data[:-top_n]] = 0
# Sampling the index of the predicted next char
sampled_index = torch.multinomial(probs, 1)
return sampled_index
def predict_probs(model, hidden, character, vocab, device):
# One-hot encoding our input to fit into the model
character = np.array([[vocab[c] for c in character]])
character = one_hot_encode(character, len(vocab))
character = torch.from_numpy(character)
character = character.to(device)
with torch.no_grad():
# Forward pass through the model
out, hidden = model(character, hidden)
# Return the logits
prob = nn.functional.softmax(out[-1], dim=0).data
return prob, hidden
def predict_fn(input_data, model):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if model.char2int is None:
raise Exception('Model has not been loaded properly, no word_dict.')
# Extract the input data and the desired length
out_len, start = input_data
out_len = int(out_len)
model.eval() # eval mode
start = start.lower()
# Clean the text as the text used in training
start = clean_text(start, True)
# First off, run through the starting characters
chars = [ch for ch in start]
size = out_len - len(chars)
# Init the hidden state
state = model.init_state(device, 1)
# Warm up the initial state, predicting on the initial string
for ch in chars:
#char, state = predict(model, ch, state, top_n=top_k)
probs, state = predict_probs(model, state, ch, model.char2int, device)
next_index = sample_from_probs(probs, 5)
# Include the last char predicted to the predicted output
chars.append(model.int2char[next_index.data[0]])
# Now pass in the previous characters and get a new one
for ii in range(size-1):
#char, h = predict_char(model, chars, vocab)
probs, state = predict_probs(model, state, chars[-1], model.char2int, device)
next_index = sample_from_probs(probs, 5)
# append to sequence
chars.append(model.int2char[next_index.data[0]])
# Join all the chars
#chars = chars.decode('utf-8')
return ''.join(chars)In short, the inference process consists of processing and encoding the input string, initializing the state of the model, executing a forward pass of the model for each character, and updating the state of the model. The output of each iteration returns the probability of each character to be the next. We sample on those probabilities to extract the next character, which we join to the output text string.
简而言之,推理过程包括对输入字符串进行处理和编码,初始化模型的状态,对每个字符执行模型的前向传递以及更新模型的状态。 每次迭代的输出返回每个字符成为下一个字符的概率。 我们对这些概率进行采样以提取下一个字符,然后将其连接到输出文本字符串。
部署推理模型 (Deploy the Model for Inference)
Now that the custom inference code has been written, we’ll create and deploy our model. To begin with, we need to construct a new PyTorchModel object pointing to the model artifacts created during training and also pointing to the inference code we wish to use. Then we can call the deploy method to launch the deployment container.
现在已经编写了自定义推理代码,我们将创建并部署我们的模型。 首先,我们需要构造一个新的PyTorchModel对象,该对象指向训练期间创建的模型工件,并指向我们希望使用的推理代码。 然后,我们可以调用deploy方法来启动部署容器。
Note: The default behavior for a deployed PyTorch model is to assume that any input passed to the predictor is a numpy array. In our case, we want to send a string so we need to construct a simple wrapper around the RealTimePredictor class to accommodate simple strings. In a more complicated situation, you may want to provide a serialization object, for example if you wanted to sent image data.
注意:已部署的PyTorch模型的默认行为是假定传递给预测变量的任何输入都是numpy数组。 在我们的例子中,我们想发送一个字符串,因此我们需要围绕RealTimePredictor类构造一个简单的包装器以容纳简单的字符串。 在更复杂的情况下,您可能想提供一个序列化对象,例如,如果要发送图像数据。
Now, we can deploy our trained model
现在,我们可以部署我们训练有素的模型
from sagemaker.predictor import RealTimePredictor
from sagemaker.pytorch import PyTorchModel
class StringPredictor(RealTimePredictor):
def __init__(self, endpoint_name, sagemaker_session):
super(StringPredictor, self).__init__(endpoint_name, sagemaker_session, content_type='text/plain')
# Create a model in Sagemaker
model = PyTorchModel(model_data=estimator.model_data,
role = role,
framework_version='0.4.0',
entry_point='predict.py',
source_dir='serve',
predictor_cls=StringPredictor)
# Deploy the model on a compute instance
predictor = model.deploy(initial_instance_count=1, instance_type='ml.m4.xlarge')Note: When deploying a model, you’re asking SageMaker to launch a compute instance that’ll wait for data to be sent to it. As a result, this compute instance will continue to run until you shut it down. This is important to know since the cost of a deployed endpoint depends on how long it has been running for.
注意:在部署模型时,您要让SageMaker启动一个计算实例,该实例将等待数据发送到该实例。 因此,此计算实例将继续运行,直到您将其关闭。 这一点很重要,因为部署的端点的成本取决于其运行了多长时间。
In other words, if you are no longer using a deployed endpoint, shut it down!
换句话说,如果您不再使用已部署的端点,请将其关闭!
And the time for testing our model has arrived — it’s so simple:
而且测试模型的时间到了–非常简单:
init_text = sentences[963:1148]
test_text = str(len(init_text))+'-'+init_text
new_text = predictor.predict(test_text).decode('utf-8')
print(new_text)Text: he did content to say it was for his country he did it to please his mother and to be partly proud; which he is, even till the altitude of his virtue. what he cannot help in his nature,Init text: he did content to say it was for his country he did it toText predicted: he did content to say it was for his country he did it to please his mother and to be partly proud which he is even till the altitude of his virtue what he cannot help in his nature ofAs we can observe, the predicted text is practically the same as the original text, which means that our network is able to generate the text that it has received in its training stage — its memory is working fine!
正如我们所看到的,预测文本实际上与原始文本相同,这意味着我们的网络能够生成在训练阶段收到的文本-它的内存工作正常!
Finally, when the service isn’t going to be consumed, you must shutdown it.
最后,当服务将不被使用时,您必须关闭它。
predictor.delete_endpoint()翻译自: https://medium.com/better-programming/intro-to-rnn-character-level-text-generation-with-pytorch-db02d7e18d89
rnn pytorch