机器学习mlflow
Managing machine learning model development can be a non-trivial task, involving multiple steps; model selection, framework selection, data processing, metric optimization, and lastly, model packaging and deployment. An organized workflow makes model management less complicated and adds reproducibility to experiments.
中号anaging机器学习模型的发展可以是一个不平凡的任务,涉及多个步骤; 模型选择,框架选择,数据处理,度量优化,最后是模型打包和部署。 井井有条的工作流程可以简化模型管理,并提高实验的可重复性。
MLflow简介 (Introduction to MLflow)
MLfLow is an open-source machine learning lifecycle management tool that facilitates organizing workflow for training, tracking and productionizing machine learning models. It is designed to work along with most recent machine learning libraries and frameworks available out there.
MLfLow是一种开放源代码的机器学习生命周期管理工具,可帮助组织用于训练,跟踪和生产机器学习模型的工作流。 它旨在与现有的最新机器学习库和框架一起使用。
According to the official website, there are four components that MLflow currently offers:
根据官方网站,MLflow当前提供四个组件:
Tracking: Record and query experiments: code, data, config, and results
跟踪:记录和查询实验:代码,数据,配置和结果
Projects: Package data science code in a format to reproduce runs on any platform
项目:以某种格式打包数据科学代码以重现在任何平台上的运行
Models: Deploy machine learning models in diverse serving environments
模型:在不同的服务环境中部署机器学习模型
Registry: Store, annotate, discover, and manage models in a central repository
注册表:在中央存储库中存储,注释,发现和管理模型
In the forthcoming sections, we will go over how all of these components can be leveraged to organize the machine learning workflow.
在接下来的部分中,我们将介绍如何利用所有这些组件来组织机器学习工作流程。
安装MLflow (Installing MLflow)
MLflow python package can be easily installed using pip or conda whichever you prefer.
可以使用pip或conda轻松安装MLflow python软件包。
shell> pip install mlflowIf you are using Databricks, all the ML runtimes come with mlflow installed and can be readily used to log model runs on DBFS storage from a Databricks notebook.
如果使用的是Databricks,则所有ML运行时都安装了mlflow,可以很容易地用于记录Databricks笔记本在DBFS存储上运行的模型。
To test the installation, run the mlflow command in the terminal:
要测试安装,请在终端中运行mlflow命令:
shell> mlflowYou should get an output similar to this:
您应该得到类似于以下的输出:
Usage: mlflow [OPTIONS] COMMAND [ARGS]...Options:
--version Show the version and exit.
--help Show this message and exit.Commands:
azureml Serve models on Azure ML.
download Downloads the artifact at the specified DBFS...
experiments Tracking APIs.
pyfunc Serve Python models locally.
run Run an MLflow project from the given URI.
sagemaker Serve models on SageMaker.
sklearn Serve SciKit-Learn models.
ui Run the MLflow tracking UI.MLflow追踪 (MLflow Tracking)
Tracking component consists of a UI and APIs for logging parameters, code version, metrics and output files. MLflow runs are grouped into experiments such that the logs for different runs of an experiment can be tracked and compared. This also provides the ability to visualize and compare the logged parameters and metrics. MLflow provides simple API Support for most popular platforms including Python, REST, R and Java.
跟踪组件由用于记录参数,代码版本,指标和输出文件的UI和API组成。 MLflow运行被分组为实验,以便可以跟踪和比较实验不同运行的日志。 这还提供了可视化和比较记录的参数和指标的功能。 MLflow为包括Python,REST,R和Java在内的大多数流行平台提供了简单的API支持。

By default, mlflow uses local storage to run the tracking server. MLflow does provide the option to track runs to a remote server as well. This can be done by calling mlflow.set_tracking_uri() The remote tracking server can be assigned using a SQLALchemy link, local file path, HTTP server, or a Data Lake path.
默认情况下,mlflow使用本地存储来运行跟踪服务器。 MLflow确实提供了跟踪运行到远程服务器的选项。 可以通过调用mlflow.set_tracking_uri()来完成。可以使用SQLALchemy链接,本地文件路径,HTTP服务器或数据湖路径来分配远程跟踪服务器。
The following snippet shows how to start a run and log parameters and metrics:
以下代码段显示了如何启动运行并记录参数和指标:
import os
from mlflow import log_metric, log_param, log_artifact
with mlflow.start_run() as run:
# Log a parameter (key-value pair)
log_param("param1", 5)
# Log a metric; metrics can be updated throughout the run
log_metric("foo", 1)
log_metric("foo", 2)
log_metric("foo", 3)
# Log an artifact (output file)
with open("output.txt", "w") as f:
f.write("Hello world!")
log_artifact("output.txt")An artifact can be a file with model results or outputs. The log_artifact() method can be used to log such files generated by a run.
工件可以是带有模型结果或输出的文件。 log_artifact()方法可用于记录运行生成的此类文件。
Mlflow stores all the runs under ‘default’ experiment name, by default. We can assign an experiment name by using the set_experiment() method before calling the start_run() method which will create a run in this experiment.
默认情况下,Mlflow将所有运行存储在“默认”实验名称下。 我们可以在调用start_run()之前使用set_experiment()方法分配实验名称。 方法将在此实验中创建运行。
mlflow.set_experiment(‘MNIST’)MLflow also provides automatic experiment logging support for major machine learning frameworks; including Tensorflow, PyTorch, Gluon, XGBoost, LightGBM, SparkML, and FastAI. The autologging capability can be invoked by importing the autolog method from the supported framework binding provided in the mlflow package.
MLflow还为主要的机器学习框架提供了自动实验记录支持; 包括Tensorflow,PyTorch,Gluon,XGBoost,LightGBM,SparkML和FastAI。 可以通过从mlflow软件包中提供的受支持的框架绑定中导入自动记录方法来调用自动记录功能。
The following code snippet demonstrates how the autolog feature can be used with Tensorflow:
以下代码段演示了如何与Tensorflow一起使用自动记录功能:
## MLflow Model Tracking and Versioning Example
import tensorflow as tf
import tensorflow.keras as keras
from tensorflow.keras import models
from tensorflow.keras import layers
import mlflow
from mlflow import pyfunc
# Define Tensorflow Keras model and load data
# We define a simple Convolutional Neural Network and train and predict on MNIST data
# Hyperparameters
batch_size = 1024
epochs = 15
num_classes = 10
learning_rate = 0.01
# Load MNIST dataset
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = x_train.reshape(x_train.shape[0], 28, 28, 1)
x_test = x_test.reshape(x_test.shape[0], 28, 28, 1)
x_train = x_train.astype('float32')/255
x_test = x_test.astype('float32')/255
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
# Simple CNN Model
model = models.Sequential()
model.add(layers.Conv2D(32, kernel_size=(3, 3),
activation='relu',
input_shape=(28, 28, 1)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
model.add(layers.Dropout(0.25))
model.add(layers.Flatten())
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(num_classes, activation='softmax'))
# We define the training function that takes in the dataset, the model definition, adds a compiler and sets some hyperparameters for tuning.
def train(learning_rate=1.0):
# Adadelta optimizer
optimizer = keras.optimizers.Adadelta(lr=learning_rate)
# Compile keras model
model.compile(optimizer=optimizer,
loss='categorical_crossentropy',
metrics=['accuracy'])
# Train model
model.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=2,
validation_data=(x_test, y_test))
# MLflow offers autologging bindings for Deep Learning framework
import mlflow.tensorflow
mlflow.tensorflow.autolog(every_n_iter=1)
# Start the run
with mlflow.start_run(run_name='mnist-run-2') as run:
run_id = run.info.run_id
# train model
train(learning_rate)
# Get trained model
model_uri = mlflow.get_artifact_uri("model")
# Evaluate Trained Model *Load Model & Evaluate*
import mlflow.keras
keras_model = mlflow.keras.load_model(model_uri)
loss, acc = keras_model.evaluate(x_test, y_test, verbose=False)
print(f"Model Evaluation Results:- loss: {loss:.4f} Acc: {acc:.4f}")To access the mlflow UI, run the following command in the terminal from the same directory as the code:
要访问mlflow UI,请在终端中从与代码相同的目录中运行以下命令:
mlflow uiIf you are using a remote tracking server, the same tracking URI must be provided as the backend store URI to start the mlflow UI. This can be done by passing an additional argument.
如果使用的是远程跟踪服务器,则必须提供与后端存储URI相同的跟踪URI,以启动mlflow UI。 这可以通过传递附加参数来完成。
mlflow ui --backend-store-uri The MLflow UI can be accessed at: http://localhost:5000.
可以在以下位置访问MLflow UI: http:// localhost:5000 。
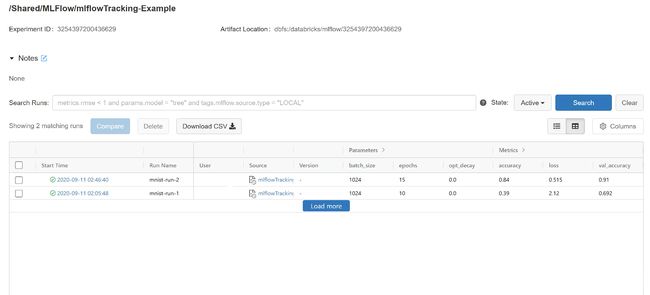
What we have done so far? We created a script which autologs the necessary parameters and metrics for a tensorflow model training into an mlflow run. The mlflow UI shows a list of all the runs for a selected experiment with a brief description of the run in tabular format. The details of a run can be viewed by clicking on the timestamp.
到目前为止我们做了什么? 我们创建了一个脚本,该脚本将用于tensorflow模型训练的必要参数和指标自动记录到mlflow运行中。 mlflow UI会以表格格式显示所选实验的所有运行的列表,并对运行进行简要说明。 单击时间戳可以查看运行的详细信息。
MLflows autolog feature automatically logs all the necessary parameters (epochs, batch size, optimizer used, and learning rate etc.) and metrics (loss and criterion for train as well as validation data) during the run. It even logs the trained model which can be seen in artifacts section of the run in the UI.
MLflows自动记录功能会在运行期间自动记录所有必要的参数(历元,批大小,使用的优化程序和学习率等)和指标(训练的损失和准则以及验证数据)。 它甚至记录经过训练的模型,可以在UI的运行的工件部分中看到。
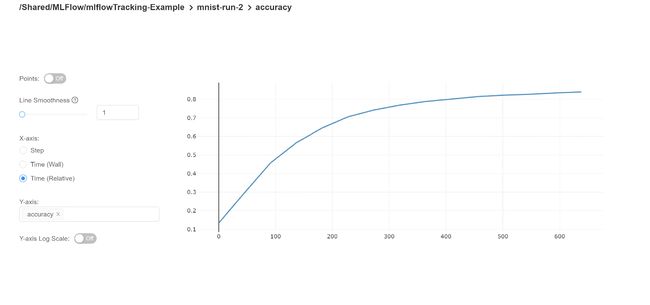
It is important to observe and understand how the metrics change throughout a run. Visualizations are the best way to track the metric values through the training process. MLflow facilitates this by providing simple-to-use automated plot generation inside the mlflow run UI. By clicking on a metric we can visualize the plots for it.
重要的是要观察并了解指标在整个运行过程中如何变化。 可视化是在训练过程中跟踪指标值的最佳方法。 MLflow通过在mlflow运行用户界面内提供易于使用的自动绘图生成,从而促进了这一过程。 通过单击一个指标,我们可以将其可视化。
MLflow项目(MLflow Project)
An MLflow Project is a format for packaging data science code in a reusable and reproducible way, based primarily on conventions.
MLflow项目是一种主要基于约定以可重用和可再现的方式打包数据科学代码的格式。
Essentially, an MLflow Project bundles various components of the machine learning code that includes the API and command-line tools for running projects. Each project is simply a directory of files, or a Git repository, containing your code. This makes it possible to chain together multiple projects into workflows.
本质上,MLflow项目捆绑了机器学习代码的各种组件,其中包括用于运行项目的API和命令行工具。 每个项目都只是包含您的代码的文件目录或Git存储库。 这样就可以将多个项目链接到工作流程中。
Each project contains AnMLproject file which may look something like this:
每个项目都包含一个MLproject文件,该文件可能类似于以下内容:
name: keras-mnist
conda_env: conda.yaml
entry_points:
main:
parameters:
batch_size: {type: int, default: 100}
epochs: {type: int, default: 1000}
command: "python train.py --batch_size={batch_size} --epochs={epochs}"The MLproject file is used to define the name of the project, environment that is used to run the project, and what command to execute. The conda.yaml defines the environment dependencies for the project. This can be generated easily from an existing conda environment and looks something like this:
MLproject文件用于定义项目名称,用于运行项目的环境以及要执行的命令。 conda.yaml定义项目的环境依赖性。 这可以从现有的conda环境中轻松生成,如下所示:
name: keras-mnist
channels:
- defaults
- anaconda
- conda-forge
dependencies:
- python=3.6
- pip
- pip:
- mlflow
- tensorflow==2.3.0MLflow does support Docker environment and system environments as well. More information on this is available here.
MLflow确实也支持Docker环境和系统环境。 有关此的更多信息,请参见此处。
The project can be executed by using the mlflow run command in the terminal from the same directory:
可以在同一目录中的终端中使用mlflow run命令来执行项目:
shell> mlflow run .This will build the conda environment and execute the command mentioned in the MLprojectfile. Inference scripts can similarly be packaged into a project.
这将构建conda环境并执行MLproject文件中提到的命令。 推理脚本可以类似地打包到项目中。
MLflow模型 (MLflow Models)
An MLflow Model is a standard format for packaging machine learning models that can be used in a variety of downstream tools.
MLflow模型是包装机器学习模型的标准格式,可以在各种下游工具中使用。
Using the MLflow model format, models from various frameworks can be stored in a standard format which can be consumed in various forms including real-time serving through a REST API, batch inference on Apache Spark, or can even as a python_function.
使用MLflow模型格式,可以将各种框架的模型以标准格式存储,可以以各种形式使用,包括通过REST API进行实时服务,在Apache Spark上进行批量推断,甚至可以作为python_function 。
Similar to MLflow Projects, MLflow Models contain two config files: MLmodel and conda.yaml which contain the model and environment configurations, respectively.
与MLflow项目相似,MLflow模型包含两个配置文件: MLmodel和conda.yaml ,分别包含模型和环境配置。
The MLmodel file looks contains the following:
MLmodel文件的外观包含以下内容:
artifact_path: model
flavors:
keras:
data: data
keras_module: keras
keras_version: 2.4.3
python_function:
data: data
env: conda.yaml
loader_module: mlflow.keras
python_version: 3.7.7
run_id: e256210d0ed94b4886efcfdf6f95aac3
utc_time_created: '2020-09-15 07:08:50.850162'data is the directory containing the model files in native flavor format, which in this case is an keras h5 model file.
data是包含本机样式格式的模型文件的目录,在本例中为keras h5模型文件。
The autologging feature also writes the model to the run directory. Path to the model can be used to serve this model as a REST API.
自动记录功能还将模型写入运行目录。 该模型的路径可用于将该模型用作REST API。
mlflow models serve -m MLflow模型注册表 (MLflow Model Registry)
The MLflow Model Registry component is a centralized model store, set of APIs, and UI, to collaboratively manage the full lifecycle of an MLflow Model.
MLflow Model Registry组件是一个集中的模型存储,一组API和UI,用于协作管理MLflow模型的整个生命周期。
An MLflow model can be registered to the centralized model registry which provides a convenient way to maintain model versions, annotate different version, and monitor their stages (staging, production, and archived).
可以将MLflow模型注册到集中式模型注册表中,该注册表提供了一种便捷的方式来维护模型版本,注释不同版本以及监视其阶段(分段,生产和归档) 。

A Registered Model has a unique name, contains versions, associated transitional stages, model lineage, and other metadata. An MLflow model can either be registered using the UI workflow or using the python API:
注册模型具有唯一的名称,包含版本,关联的过渡阶段,模型沿袭和其他元数据。 可以使用UI工作流程或使用python API注册MLflow模型:
from mlflow.tracking import MlflowClient# Create a Registered Model
client = MlflowClient()
client.create_registered_model("MNIST-Keras")# Create a model version
result = client.create_model_version(
name="MNIST-Keras",
source="./mlruns/0/
artifacts/model",
run_id="
)The create_registered_model() method creates a new registered model in the model registry and the create_model_version() method creates a new version for the registered model. This method takes 3 parameters; name, source, and run id. Source is the path to the updated MLflow Model.
该create_registered_model()方法创建一个新注册的模型在模型注册表和create_model_version()方法创建的注册模型的新版本。 此方法有3个参数; 名称,来源和运行ID。 源是更新的MLflow模型的路径。
Another way to do this is using the register_model API:
另一种方法是使用register_model API:
mlflow.register_model(
"runs:/
"MNIST-Keras"
)If a model with the provided name does not exist this mlflow creates a new registered model with the name.
如果不存在具有提供名称的模型,则此mlflow会使用该名称创建一个新的注册模型。
Model stage transition is another useful feature that mlflow provides. As the model evolves, its stage can be updated:
模型阶段过渡是mlflow提供的另一个有用功能。 随着模型的发展,其阶段可以更新:
client = MlflowClient()client.transition_model_version_stage(
name="MNIST-Keras",
version=1,
stage="Production"
)The above command will update the stage of the version 1 of the ‘MNIST-Keras’ model to Production.
上面的命令会将“ MNIST-Keras”模型的版本1的阶段更新为Production 。
A registered model can be served using the mlflow CLI:
可以使用mlflow CLI为注册模型提供服务:
#!/usr/bin/env sh
# Set environment variable for the tracking URL where the Model Registry resides
export MLFLOW_TRACKING_URI=http://localhost:5000
# Serve the production model from the model registry
mlflow models serve -m "models:/MNIST-Keras/Production"The MLFLOW_TRACKING_URI environment variable should point to the tracking server (mentioned in the mlflow tracking section) where the model registry resides.
MLFLOW_TRACKING_URI环境变量应指向模型注册表所在的跟踪服务器(在mlflow跟踪部分中提到) 。
结论 (Conclusion)
Thank you for reading this post! In this post, I have tried to cover all the major components of MLflow’s Machine Learning management toolkit. Aside from the areas covered in this post, MLflow also provides various deployment APIs for various infrastructures including, AWS Sagemaker, Microsoft Azure and Databricks clusters. In the future posts, we will show how to leverage the MLflow deployment APIs to deploy machine learning models to production in one of these Major infrastructure options.
感谢您阅读这篇文章! 在本文中,我试图介绍MLflow的机器学习管理工具包的所有主要组件。 除了本文所涉及的领域外,MLflow还为各种基础设施(包括AWS Sagemaker,Microsoft Azure和Databricks集群)提供了各种部署API。 在以后的文章中,我们将展示如何利用MLflow部署API在这些主要基础架构选项之一中将机器学习模型部署到生产环境。
翻译自: https://medium.com/engineering-at-ooba/machine-learning-lifecycle-management-using-mlflow-64d3bd75b6bd
机器学习mlflow