maskrcnn用于目标检测_Mask RCNN用于船舶检测和分割

作者 | Gabriel Garza
来源 | Medium
编辑 | 代码医生团队
在这篇文章中,将使用Mask R-CNN构建一个模型,该模型将卫星图像作为输入,然后检测海洋中的任何船只,输出一个分割图像中每个船舶实例的mask。将使用 Kaggle Airbus Challenge提供的训练和开发数据集以及Matterport的伟大Mask R-CNN实施库。
链接到github中的代码:
https://github.com/gabrielgarza/Mask_RCNN
深度学习最激动人心的应用之一是机器理解图像的能力。李飞飞将此称为赋予机器“看见能力”。如下面的图像(a)中所述,检测和分割中存在四类主要问题。
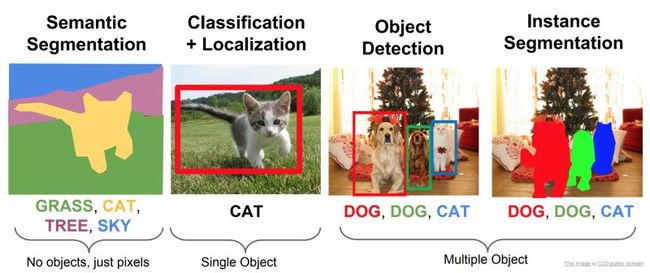
(a)李飞飞斯坦福课程 - 检测和分割
实例分割有几种方法,在这篇文章中将使用Mask R-CNN。
Mask R-CNN
Mask R-CNN是对快速R-CNN的扩展。更快的R-CNN预测边界框和Mask R-CNN本质上增加了一个分支以并行地预测对象Mask。
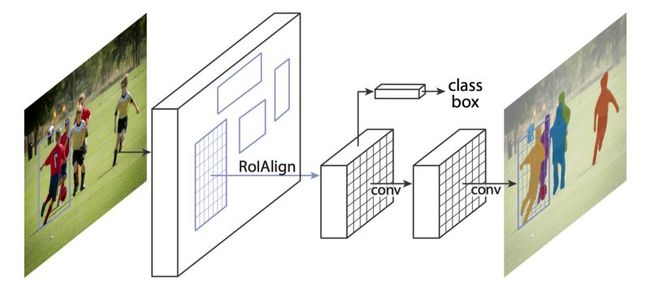
Mask R-CNN框架用于实例分割。资料来源:
https://arxiv.org/abs/1703.06870

Mask R-CNN预测边界框和对象Mask的示例
不详细讨论Mask R-CNN如何工作,这里是一般步骤:
骨干模型:标准卷积神经网络,用作特征提取器。例如,它会将1024x1024x3图像转换为32x32x2048要素图,作为下一层的输入。
区域提议网络(RPN):使用由多达200K锚定框定义的区域,RPN扫描每个区域并预测对象是否存在。RPN的一大优势是不扫描实际图像,网络扫描特征图,使其更快。
感兴趣区域分类和边界框:在该步骤中,算法将RPN提出的感兴趣区域作为输入并输出分类(softmax)和边界框(回归量)。
分段Mask:在最后一步中,将正ROI区域作为输入的算法和具有浮点值的28x28像素Mask生成为对象的输出。在推理期间,这些Mask按比例放大。
使用Mask R-CNN进行训练和推理
将使用Matterport构建的令人敬畏的Mask R-CNN库,而不是基于研究论文复制整个算法。必须A)生成训练和开发设置,B)做一些争论加载到库中,C)在AWS中设置训练环境进行训练,D)使用迁移学习从coco预开始训练的重量,和E)调整模型,以获得良好的结果。
第1步:下载Kaggle数据并生成Train和Dev Splits
Kaggle提供的数据集包含数十万个图像,因此最简单的方法是将它们直接下载到将要进行训练的AWS机器上。一旦下载它们,就必须将它们分成train和dev集合,这将通过python脚本随机完成。
强烈建议使用Spot实例从Kaggle使用Kaggle的API下载数据,并将该压缩数据上传到S3存储桶。您稍后将从S3下载该数据并在训练时解压缩。
Kaggle提供了一个名为train_ship_segmentations.csv的csv文件,其中包含两列:ImageId和EncodedPixels(运行长度编码格式)。假设已经将图像下载到 ./datasets/train_val/路径中,可以将图像拆分并将图像移动到train和dev中,使用以下代码设置文件夹:
train_ship_segmentations_df = pd.read_csv(os.path.join("./datasets/train_val/train_ship_segmentations.csv"))
msk = np.random.rand(len(train_ship_segmentations_df)) 0.8
train = train_ship_segmentations_df[msk]
test = train_ship_segmentations_df[~msk] # Move train set for index, row in train.iterrows():
image_id = row["ImageId"]
old_path = "./datasets/train_val/{}".format(image_id)
new_path = "./datasets/train/{}".format(image_id) if os.path.isfile(old_path):
os.rename(old_path, new_path) # Move dev set for index, row in test.iterrows():
image_id = row["ImageId"]
old_path = "./datasets/train_val/{}".format(image_id)
new_path = "./datasets/val/{}".format(image_id) if os.path.isfile(old_path): os.rename(old_path, new_path)
完整的代码可以在repo中的Generate Train Val Sets jupyter Notebook中找到
第2步:将数据加载到库中
Mask R-CNN库遵循加载数据集的特定约定。需要创建一个ShipDataset实现所需主要功能的类:
#ship.pyclass ShipDataset(utils.Dataset):def load_ship(self,dataset_dir,subset):def load_mask(self,image_id):def image_reference(self,image_id):
要将运行长度编码Mask转换为图像mask(布尔张量),在下面使用此函数rle_decode。这用于生成加载到库中的基础真值mask,以便在ShipDataset课程中进行训练。
def rle_decode(self, mask_rle, shape=(768, 768)):'''
mask_rle: run-length as string formated (start length)
shape: (height,width) of array to return
Returns numpy array, 1 - mask, 0 - background
'''if not isinstance(mask_rle, str):
img = np.zeros(shape[0]*shape[1], dtype=np.uint8)return img.reshape(shape).T
s = mask_rle.split()
starts, lengths = [np.asarray(x, dtype=int) for x in (s[0:][::2], s[1:][::2])]
starts -= 1
ends = starts + lengths
img = np.zeros(shape[0]*shape[1], dtype=np.uint8)for lo, hi in zip(starts, ends):
img[lo:hi] = 1return img.reshape(shape).T
第3步:使用P3竞价型实例和AWS Batch设置训练
鉴于想要训练的大型数据集,需要使用AWS GPU实例在实际的时间内获得良好的结果。P3实例非常昂贵,但是你使用竞价型实例可以获得p3.2xlarlar,大约每小时0.9美元,这意味着节省了大约70%。这里的关键是尽可能高效和自动化,以免在非训练任务中浪费任何时间/金钱,例如设置数据等。为此将使用shell脚本和docker容器,然后使用令人敬畏的AWS Batch服务来安排我们的训练。
做的第一件事是创建一个为AWS Batch配置的深度学习AMI,它使用遵循本AWS指南的 nvidia-docker 。AMI ID是ami-073682d8e65240b76,它向社区开放。这将允许使用带有GPU的docker容器进行训练。
接下来是创建一个dockerfile,它包含需要的所有依赖项以及将负责下载数据和运行训练的shell脚本。
FROM nvidia/cuda:9.0-cudnn7-devel-ubuntu16.04
MAINTAINER Gabriel Garza # Essentials: developer tools, build tools, OpenBLAS
RUN apt-get update && apt-get install -y --no-install-recommends \
apt-utils git curl vim unzip openssh-client wget \
build-essential cmake \
libopenblas-dev## Python 3.5## For convenience, alias (but don't sym-link) python & pip to python3 & pip3 as recommended in:# http://askubuntu.com/questions/351318/changing-symlink-python-to-python3-causes-problems
RUN apt-get install -y --no-install-recommends python3.5 python3.5-dev python3-pip python3-tk && \
pip3 install pip==9.0.3 --upgrade && \
pip3 install --no-cache-dir --upgrade setuptools && \
echo "alias python='python3'" >> /root/.bash_aliases && \
echo "alias pip='pip3'" >> /root/.bash_aliases# Pillow and it's dependencies
RUN apt-get install -y --no-install-recommends libjpeg-dev zlib1g-dev && \
pip3 --no-cache-dir install Pillow# Science libraries and other common packages
RUN pip3 --no-cache-dir install \
numpy scipy sklearn scikit-image==0.13.1 pandas matplotlib Cython requests pandas imgaug# Install AWS CLI
RUN pip3 --no-cache-dir install awscli --upgrade## Jupyter Notebook## Allow access from outside the container, and skip trying to open a browser.# NOTE: disable authentication token for convenience. DON'T DO THIS ON A PUBLIC SERVER.
RUN pip3 --no-cache-dir install jupyter && \
mkdir /root/.jupyter && \
echo "c.NotebookApp.ip = '*'" \"\nc.NotebookApp.open_browser = False" \"\nc.NotebookApp.token = ''" \
> /root/.jupyter/jupyter_notebook_config.py
EXPOSE 8888## Tensorflow 1.6.0 - GPU## Install TensorFlow
RUN pip3 --no-cache-dir install tensorflow-gpu# Expose port for TensorBoard
EXPOSE 6006## OpenCV 3.4.1## Dependencies
RUN apt-get install -y --no-install-recommends \
libjpeg8-dev libtiff5-dev libjasper-dev libpng12-dev \
libavcodec-dev libavformat-dev libswscale-dev libv4l-dev libgtk2.0-dev \
liblapacke-dev checkinstall
RUN pip3 install opencv-python## Keras 2.1.5#
RUN pip3 install --no-cache-dir --upgrade h5py pydot_ng keras## PyCocoTools## Using a fork of the original that has a fix for Python 3.# I submitted a PR to the original repo (https://github.com/cocodataset/cocoapi/pull/50)# but it doesn't seem to be active anymore.
RUN pip3 install --no-cache-dir git+https://github.com/waleedka/coco.git#subdirectory=PythonAPI
COPY setup_project_and_data.sh /home
COPY train.sh /home
COPY predict.sh /home
WORKDIR "/home"
请注意复制到容器中的最后三个shell脚本:
setup_project_and_data.sh - >克隆Mask R-CNN repo,从S3下载并解压缩数据,将数据分成train和dev设置,下载在S3中保存的最新权重
train.sh- >加载最新的权重,运行train命令python3 ./ship.py train --dataset=./datasets --weights=last,在训练结束后将训练的权重上传到S3
predict.sh - >下载Kaggle Challenge测试数据集(用于提交攻击条目),为每个图像生成预测,将mask转换为行程编码,并将预测CSV文件上传到S3。
第3步:使用AWS Batch训练模型
AWS Batch的优点在于您可以创建使用竞价型实例的计算环境,它将使用您的docker容器运行作业,然后在作业结束后立即终止竞价型实例。
不会在这里详细介绍,但实质上是您构建映像,将其上传到AWS ECR,然后在AWS Batch中安排您的训练或推理作业以命令运行bash predict.sh或bash train.sh等待它完成(您可以通过查看AWS Watch中的日志来跟踪进度)。生成的文件(训练的权重或预测csv)由我们的脚本上传到S3。
第一次训练时,传入coco参数(in train.sh)以便使用迁移学习并在已经训练过的coco数据集之上训练模
python3 ./ship.py train --dataset=./datasets --weights=coco
一旦完成了初始训练,就会将last参数传递给train命令,这样就可以开始训练:
python3 ./ship.py train --dataset=./datasets --weights=last
可以使用ShipConfig类调整模型并覆盖默认设置。将非最大抑制设置为0对于摆脱预测重叠的船masks(Kaggle挑战不允许)非常重要。
class ShipConfig(Config):"""Configuration for training on the toy dataset.
Derives from the base Config class and overrides some values.
"""# Give the configuration a recognizable name
NAME = "ship"# We use a GPU with 12GB memory, which can fit two images.# Adjust down if you use a smaller GPU.
IMAGES_PER_GPU = 1# Number of classes (including background)
NUM_CLASSES = 1 + 1 # Background + ship# Number of training steps per epoch
STEPS_PER_EPOCH = 500# Skip detections with
DETECTION_MIN_CONFIDENCE = 0.95# Non-maximum suppression threshold for detection
DETECTION_NMS_THRESHOLD = 0.0
IMAGE_MIN_DIM = 768
IMAGE_MAX_DIM = 768
第4步:预测船舶分段
要生成预测,所要做的就是使用bash predict.sh命令在AWS Batch中运行容器。这将使用里面的脚本generate_predictions.py,这里是推理的样子片段:
class InferenceConfig(config.__class__):# Run detection on one image at a time
GPU_COUNT = 1
IMAGES_PER_GPU = 1
DETECTION_MIN_CONFIDENCE = 0.95
DETECTION_NMS_THRESHOLD = 0.0
IMAGE_MIN_DIM = 768
IMAGE_MAX_DIM = 768
RPN_ANCHOR_SCALES = (64, 96, 128, 256, 512)
DETECTION_MAX_INSTANCES = 20# Create model object in inference mode.
config = InferenceConfig()
model = modellib.MaskRCNN(mode="inference", model_dir=MODEL_DIR, config=config)# Instantiate dataset
dataset = ship.ShipDataset()# Load weights
model.load_weights(os.path.join(ROOT_DIR, SHIP_WEIGHTS_PATH), by_name=True)
class_names = ['BG', 'ship']# Run detection# Load image ids (filenames) and run length encoded pixels
images_path = "datasets/test"
sample_sub_csv = "sample_submission.csv"# images_path = "datasets/val"# sample_sub_csv = "val_ship_segmentations.csv"
sample_submission_df = pd.read_csv(os.path.join(images_path,sample_sub_csv))
unique_image_ids = sample_submission_df.ImageId.unique()
out_pred_rows = []
count = 0for image_id in unique_image_ids:
image_path = os.path.join(images_path, image_id)if os.path.isfile(image_path):
count += 1
print("Step: ", count)# Start counting prediction time
tic = time.clock()
image = skimage.io.imread(image_path)
results = model.detect([image], verbose=1)
r = results[0]# First Image
re_encoded_to_rle_list = []for i in np.arange(np.array(r['masks']).shape[-1]):
boolean_mask = r['masks'][:,:,i]
re_encoded_to_rle = dataset.rle_encode(boolean_mask)
re_encoded_to_rle_list.append(re_encoded_to_rle)if len(re_encoded_to_rle_list) == 0:
out_pred_rows += [{ 'ImageId': image_id, 'EncodedPixels': None}]
print("Found Ship: ", "NO")else:for rle_mask in re_encoded_to_rle_list:
out_pred_rows += [{ 'ImageId': image_id, 'EncodedPixels': rle_mask}]
print("Found Ship: ", rle_mask)
toc = time.clock()
print("Prediction time: ",toc-tic)
submission_df = pd.DataFrame(out_pred_rows)[['ImageId', 'EncodedPixels']]
filename = "{}{:%Y%m%dT%H%M}.csv".format("./submissions/submission_", datetime.datetime.now())
submission_df.to_csv(filename, index=False)
遇到了几个具有挑战性的案例,例如图像中的波浪和云,模型最初认为这些是船只。为了克服这一挑战,将区域建议网络的锚箱尺寸修改RPN_ANCHOR_SCALES为更小,这显着改善了结果,因为模型不再预测小波浪将成为船舶。
结果
在大约30个epochs(在ship.py中定义)之后,您可以获得不错的结果。训练了160个epochs,并且在我的Kaggle提交中能够达到80.5%的准确率。
已经包含了一个Jupyter Notebook inspect_shyp_model.ipynb,它允许您运行模型并对计算机上的任何图像进行预测。
以下是一些示例图像,其中实例的预测概率为船舶,分段蒙版和覆盖在顶部的边界框:

Mask R-CNN模型预测8/8船舶带有Mask

模型预测2/2船

模型与彼此相邻的船舶存在一些问题

波浪会为模型产生误报。需要进一步训练/调整以完全克服。

与一些停靠的船和一些船只位于陆地上的困难形象。
结论
总的来说,学到了很多关于Mask R-CNN如何工作以及它有多强大的知识。关于如何应用这项技术的可能性是无穷无尽的,并且考虑如何让机器“看到”的能力有助于改善世界,这是令人兴奋的。
Github Repo:https://github.com/gabrielgarza/Mask_RCNN

关于图书
《深度学习之TensorFlow:入门、原理与进阶实战》和《Python带我起飞——入门、进阶、商业实战》两本图书是代码医生团队精心编著的 AI入门与提高的精品图书。配套资源丰富:配套视频、QQ读者群、实例源码、 配套论坛:http://bbs.aianaconda.com 。更多请见:aianaconda.com

![]()