Python-100-Days day16~20 Python语言进阶
项目地址
https://github.com/jackfrued/Python-100-Days
Day01~15 - Python语言基础Day16~20 - Python语言进阶
Day21~30 - Web前端入门
Day31~35 - 玩转Linux操作系统
Day36~40 - 数据库基础和进阶
Day41~55 - 实战Django
Day56~60 - 实战Flask
Day61~65 - 实战Tornado
Day66~75 - 爬虫开发
Day76~90 - 数据处理和机器学习
Day91~100 - 团队项目开发
Python-100-Days day16~20 Python语言进阶
- 重要知识点
-
- 生成式(推导式)的用法
- 嵌套的列表的坑
-
- 区分两个概念 对象和对象的引用
- 小例子
- 正确代码
- heapq模块(堆排序)
- itertools模块(迭代工具模块)
- collections模块
-
- 找出序列中出现最多的模块
- 数据结构和算法
-
- 算法分析
- 搜索与排序
- 常用算法
- 数据结构思维导图
- 函数的使用方式
-
- 将函数视为“一等公民”
- 高阶函数的用法(filter、map以及它们的替代品)
-
- filter的用法
- map的用法
- 位置参数、可变参数、关键字参数、命名关键字参数
-
- 位置参数
- 默认参数
- 可变参数 (在函数内部自动组装为一个tuple)
- 关键字参数 (在函数内部自动组装为一个dict)
- 命名关键字参数
- 参数组合
- 函数参数小结
- 参数的元信息(代码可读性问题)
-
- 函数的注解 annotations属性
- 创建装饰器保留函数元信息
- 匿名函数和内联函数的用法(lambda函数)
- 闭包和作用域问题
-
- 闭包
- 函数作用域
- 总结:nonlocal与global的区别
- 装饰器函数(使用装饰器和取消装饰器)
- 面向对象相关知识
-
- 三大支柱:封装、继承、多态
-
- 例子:工资结算系统。
- 类与类之间的关系
-
- 例子:扑克游戏
- 对象的复制(深复制/深拷贝/深度克隆和浅复制/浅拷贝/影子克隆)
- 垃圾回收、循环引用和弱引用
- 魔法属性和方法
-
- 何为魔法属性
- 魔法方法
-
- __init__ () 魔法方法
- __del__() 魔法方法
- __str__ () 魔法方法
- __dict__() 魔法方法
- __getitem__(),__setitem__(),__delitem__()魔法方法
- __iter__()魔法方法
- __next__()魔法方法
- __name__()魔法方法
- 上下文管理器 __enter__()和__exit__()方法
- 混入(Mixin)
- 元编程和元类
- 面向对象设计原则
- GoF设计模式
- 迭代器和生成器
-
- 迭代器
- 生成器
- 并发编程
-
- 多线程
- 多进程
- 重点:多线程和多进程的比较。
- 异步处理
- 重点:异步I/O与多进程的比较。
- 小结
Python语言进阶
常用数据结构
函数的高级用法 - “一等公民” / 高阶函数 / Lambda函数 / 作用域和闭包 / 装饰器
面向对象高级知识 - “三大支柱” / 类与类之间的关系 / 垃圾回收 / 魔术属性和方法 / 混入 / 元类 / 面向对象设计原则 / GoF设计模式
迭代器和生成器 - 相关魔术方法 / 创建生成器的两种方式
并发和异步编程 - 多线程 / 多进程 / 异步IO / async和await
重要知识点
生成式(推导式)的用法
prices = {
'AAPL': 191.88,
'GOOG': 1186.96,
'IBM': 149.24,
'ORCL': 48.44,
'ACN': 166.89,
'FB': 208.09,
'SYMC': 21.29
}
# 用股票价格大于100元的股票构造一个新的字典
prices2 = {
key: value for key, value in prices.items() if value > 100}
print(prices2)

说明:生成式(推导式)可以用来生成列表、集合和字典。
详细用法
https://blog.csdn.net/weixin_45391970/article/details/109153424
嵌套的列表的坑
Python中有一种内置的数据类型叫列表(list),它是一种容器,可以用来承载其他的对象(准确的说是其他对象的引用),列表中的对象可以称为列表的元素,很明显我们可以把列表作为列表中的元素,这就是所谓的嵌套列表。
嵌套列表可以模拟出现实中的表格、矩阵、2D游戏的地图(如植物大战僵尸的花园)、棋盘(如国际象棋、黑白棋)等。
在使用嵌套的列表时要小心,否则很可能遭遇非常尴尬的情况,下面是一个小例子。
# 录入五个学生三门课程的成绩
names = ['关羽', '张飞', '赵云', '马超', '黄忠']
courses = ['语文', '数学', '英语']
scores = [[None] * len(courses)] * len(names)
# scores = [[None] * len(courses) for _ in range(len(names))] # 正确的
for row, name in enumerate(names):
for col, course in enumerate(courses):
scores[row][col] = float(input(f'请输入{name}的{course}成绩: '))
print(scores)
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
语法 以下是 enumerate() 方法的语法:
enumerate(sequence, [start=0])
参数
sequence – 一个序列、迭代器或其他支持迭代对象。
start – 下标起始位置。
返回值 返回 enumerate(枚举) 对象。
我们希望录入5个学生3门课程的成绩,于是定义了一个有5个元素的列表,而列表中的每个元素又是一个由3个元素构成的列表,这样一个列表的列表刚好跟一个表格是一致的,相当于有5行3列。
接下来我们通过嵌套的for-in循环输入每个学生3门课程的成绩。程序执行完成后我们发现,每个学生3门课程的成绩是一模一样的(尴尬),而且就是最后录入的那个学生的成绩。

区分两个概念 对象和对象的引用
要想把这个坑填平,我们首先要区分对象和对象的引用这两个概念,而要区分这两个概念,还得先说说内存中的栈和堆。
我们经常会听人说起“堆栈”这个词,但实际上“堆”和“栈”是两个不同的概念。众所周知,一个程序运行时需要占用一些内存空间来存储数据和代码,那么这些内存从逻辑上又可以做进一步的划分。
对底层语言(如C语言)有所了解的程序员大都知道,程序中可以使用的内存从逻辑上可以为五个部分,按照地址从高到低依次是:栈(stack)、堆(heap)、数据段(data segment)、只读数据段(static area)和代码段(code segment)。
栈用来存储局部、临时变量,以及函数调用时保存现场和恢复现场需要用到的数据,这部分内存在代码块开始执行时自动分配,代码块执行结束时自动释放,通常由编译器自动管理。
堆的大小不固定,可以动态的分配和回收,因此如果程序中有大量的数据需要处理,这些数据通常都放在堆上,如果堆空间没有正确的被释放会引发内存泄露的问题,而像Python、Java等编程语言都使用了垃圾回收机制来实现自动化的内存管理(自动回收不再使用的堆空间)。
小例子
所以,下面的代码中,变量a并不是真正的对象,它是对象的引用,相当于记录了对象在堆空间的地址,通过这个地址我们可以访问到对应的对象。
a = object()b = ['apple', 'pitaya', 'grape']
b = ['apple', 'pitaya', 'grape']
同理,变量b是列表容器的引用,它引用了堆空间上的列表容器,而列表容器中并没有保存真正的对象,它保存的也仅仅是对象的引用。
知道了这一点,我们可以回过头看看刚才的程序,我们对列表进行[[0]* 3] * 5操作时,仅仅是将[0, 0, 0] 这个列表的地址进行了复制,并没有创建新的列表对象。
所以,容器中虽然有5个元素,但是这5个元素引用了同一个列表对象。这一点可以通过id函数检查scores[0]和scores[1]的地址得到证实。
a = [[0]*3]*5
print(id(a[0]))
print(id(a[1])) # id相等
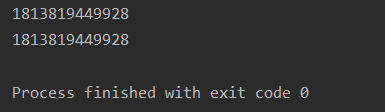
id() 函数返回对象的唯一标识符,标识符是一个整数。 CPython 中 id() 函数用于获取对象的内存地址。
id 语法:id([object])
参数说明:object – 对象。
返回值 返回对象的内存地址。
正确代码
所以,正确的代码应该按照如下的方式进行修改。
方法一 变得不再嵌套
names = ['关羽', '张飞', '赵云', '马超', '黄忠']
courses = ['语文', '数学', '英语']
scores = [[None]] * len(names)
for row, name in enumerate(names):
scores[row] = [None] * len(courses) # 变得不再嵌套
for col, course in enumerate(courses):
# scores[row][col] = float(input(course + ': '))
scores[row][col] = float(input(f'请输入{name}的{course}成绩: '))
print(scores)
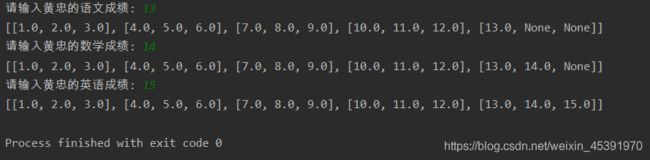
方法二
names = ['关羽', '张飞', '赵云', '马超', '黄忠']
courses = ['语文', '数学', '英语']
# 录入五个学生三门课程的成绩
scores = [[None] * len(courses) for _ in range(len(names))]
for row, name in enumerate(names):
for col, course in enumerate(courses):
scores[row][col] = float(input(f'请输入{name}的{course}成绩: '))
print(scores)
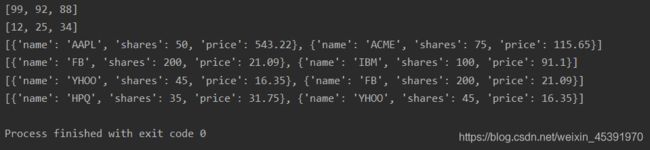
heapq模块(堆排序)
"""
从列表中找出最大的或最小的N个元素
堆结构(大根堆/小根堆)
"""
import heapq
list1 = [34, 25, 12, 99, 87, 63, 58, 78, 88, 92]
list2 = [
{
'name': 'IBM', 'shares': 100, 'price': 91.1},
{
'name': 'AAPL', 'shares': 50, 'price': 543.22},
{
'name': 'FB', 'shares': 200, 'price': 21.09},
{
'name': 'HPQ', 'shares': 35, 'price': 31.75},
{
'name': 'YHOO', 'shares': 45, 'price': 16.35},
{
'name': 'ACME', 'shares': 75, 'price': 115.65}
]
print(heapq.nlargest(3, list1))
print(heapq.nsmallest(3, list1))
print(heapq.nlargest(2, list2, key=lambda x: x['price']))
print(heapq.nlargest(2, list2, key=lambda x: x['shares']))
itertools模块(迭代工具模块)
"""
迭代工具模块
"""
import itertools
# 产生ABCD的全排列
itertools.permutations('ABCD')
# 产生ABCDE的五选三组合
itertools.combinations('ABCDE', 3)
# 产生ABCD和123的笛卡尔积
itertools.product('ABCD', '123')
# 产生ABC的无限循环序列
itertools.cycle(('A', 'B', 'C'))
collections模块
常用的工具类:
namedtuple:命令元组,它是一个类工厂,接受类型的名称和属性列表来创建一个类。
deque:双端队列,是列表的替代实现。Python中的列表底层是基于数组来实现的,而deque底层是双向链表,因此当你需要在头尾添加和删除元素是,deque会表现出更好的性能,渐近时间复杂度为O(1)。
Counter:dict的子类,键是元素,值是元素的计数,它的most_common()方法可以帮助我们获取出现频率最高的元素。Counter和dict的继承关系我认为是值得商榷的,按照CARP原则,Counter跟dict的关系应该设计为关联关系更为合理。
OrderedDict:dict的子类,它记录了键值对插入的顺序,看起来既有字典的行为,也有链表的行为。
defaultdict:类似于字典类型,但是可以通过默认的工厂函数来获得键对应的默认值,相比字典中的setdefault()方法,这种做法更加高效。
找出序列中出现最多的模块
"""
找出序列中出现次数最多的元素
"""
from collections import Counter
words = [
'look', 'into', 'my', 'eyes', 'look', 'into', 'my', 'eyes',
'the', 'eyes', 'the', 'eyes', 'the', 'eyes', 'not', 'around',
'the', 'eyes', "don't", 'look', 'around', 'the', 'eyes',
'look', 'into', 'my', 'eyes', "you're", 'under'
]
counter = Counter(words)
print(counter.most_common(3))
数据结构和算法
算法分析
数据结构与算法内容庞杂,需要持续学习
我的专栏 python数据结构与算法 持续更新
https://blog.csdn.net/weixin_45391970/category_10485032.html
算法:解决问题的方法和步骤
评价算法的好坏:渐近时间复杂度和渐近空间复杂度。
渐近时间复杂度的大O标记:
- 常量时间复杂度 - 布隆过滤器 / 哈希存储
- 对数时间复杂度 - 折半查找(二分查找)
- 线性时间复杂度 - 顺序查找 / 计数排序
- 对数线性时间复杂度 - 高级排序算法(归并排序、快速排序)
- 平方时间复杂度 - 简单排序算法(选择排序、插入排序、冒泡排序)
- 立方时间复杂度 - Floyd算法 / 矩阵乘法运算
- 几何级数时间复杂度 - 汉诺塔
- 阶乘时间复杂度 - 旅行经销商问题 - NPC
搜索与排序
https://blog.csdn.net/weixin_45391970/article/details/108205004
常用算法
穷举法 - 又称为暴力破解法,对所有的可能性进行验证,直到找到正确答案。
贪婪法(贪心算法) - 在对问题求解时,总是做出在当前看来最好的选择,不追求最优解,快速找到满意解。
分治法 - 把一个复杂的问题分成两个或更多的相同或相似的子问题,再把子问题分成更小的子问题,直到可以直接求解的程度,最后将子问题的解进行合并得到原问题的解。
回溯法 - 回溯法又称为试探法,按选优条件向前搜索,当搜索到某一步发现原先选择并不优或达不到目标时,就退回一步重新选择。
动态规划 - 基本思想也是将待求解问题分解成若干个子问题,先求解并保存这些子问题的解,避免产生大量的重复运算。
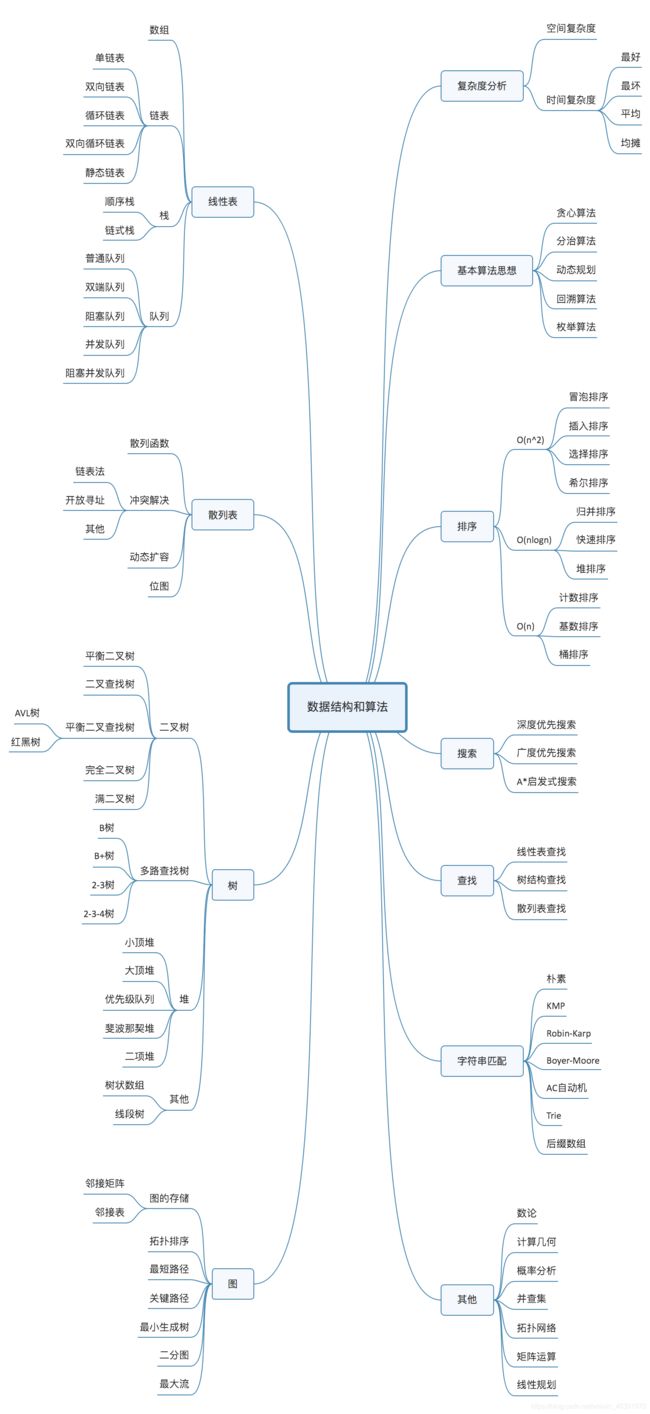
数据结构思维导图
函数的使用方式
将函数视为“一等公民”
函数可以赋值给变量
函数可以作为函数的参数
函数可以作为函数的返回值
高阶函数的用法(filter、map以及它们的替代品)
items1 = list(map(lambda x: x ** 2, filter(lambda x: x % 2, range(1, 10))))
items2 = [x ** 2 for x in range(1, 10) if x % 2]
filter的用法
过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
# filter() 函数用于过滤序列,过滤掉不符合条件的元素,返回一个迭代器对象,如果要转换为列表,可以使用 list() 来转换。
# 该接收两个参数,第一个为函数,第二个为序列,序列的每个元素作为参数传递给函数进行判,然后返回 True 或 False,最后将返回 True 的元素放到新列表中。
filter(function, iterable)
# 参数
# function -- 判断函数。
# iterable -- 可迭代对象。
# 返回值 返回一个迭代器对象
# filter函数
def is_odd(n):
return n % 2 == 1
tmplist = filter(is_odd, [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
newlist = list(tmplist)
print(newlist)
# [1, 3, 5, 7, 9]
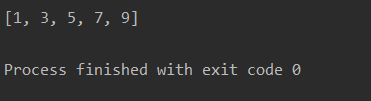
filter()也接收一个函数和一个序列。和map()不同的是,filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素。
例如,在一个list中,删掉偶数,只保留奇数,可以这么写:
def is_odd(n):
return n % 2 == 1
list(filter(is_odd, [1, 2, 4, 5, 6, 9, 10, 15]))
# 结果: [1, 5, 9, 15]
把一个序列中的空字符串删掉,可以这么写:
def not_empty(s):
return s and s.strip()
list(filter(not_empty, ['A', '', 'B', None, 'C', ' ']))
# 结果: ['A', 'B', 'C']
可见用filter()这个高阶函数,关键在于正确实现一个“筛选”函数。
注意到filter()函数返回的是一个Iterator,也就是一个惰性序列,所以要强迫filter()完成计算结果,需要用list()函数获得所有结果并返回list。
map的用法
# map() 会根据提供的函数对指定序列做映射。
# 第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
map() 函数语法:map(function, iterable, ...)
# 参数
# function -- 函数
# iterable -- 一个或多个序列
# 返回值 返回迭代器
map()函数接收两个参数,一个是函数,一个是Iterable,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator(迭代器)返回。
举例说明,比如我们有一个函数f(x)=x2,要把这个函数作用在一个list [1, 2, 3, 4, 5, 6, 7, 8, 9]上,就可以用map()实现如下:

def f(x):
return x * x
r = map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])
print(list(r))
# [1, 4, 9, 16, 25, 36, 49, 64, 81]
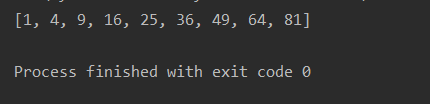
map()传入的第一个参数是f,即函数对象本身。由于结果r是一个Iterator,Iterator是惰性序列,因此通过list()函数让它把整个序列都计算出来并返回一个list。
你可能会想,不需要map()函数,写一个循环,也可以计算出结果:
L = []
for n in [1, 2, 3, 4, 5, 6, 7, 8, 9]:
L.append(f(n))
print(L)
的确可以,但是,从上面的循环代码,能一眼看明白“把f(x)作用在list的每一个元素并把结果生成一个新的list”吗?
所以,map()作为高阶函数,事实上它把运算规则抽象了,因此,我们不但可以计算简单的f(x)=x2,还可以计算任意复杂的函数,比如,把这个list所有数字转为字符串:
print(list(map(str, [1, 2, 3, 4, 5, 6, 7, 8, 9])))
# ['1', '2', '3', '4', '5', '6', '7', '8', '9']

位置参数、可变参数、关键字参数、命名关键字参数
定义函数的时候,我们把参数的名字和位置确定下来,函数的接口定义就完成了。对于函数的调用者来说,只需要知道如何传递正确的参数,以及函数将返回什么样的值就够了,函数内部的复杂逻辑被封装起来,调用者无需了解。
Python的函数定义非常简单,但灵活度却非常大。除了正常定义的必选参数外,还可以使用默认参数、可变参数和关键字参数,使得函数定义出来的接口,不但能处理复杂的参数,还可以简化调用者的代码。
位置参数
我们先写一个计算x2的函数:
def power(x):
return x * x
对于power(x)函数,参数x就是一个位置参数。
当我们调用power函数时,必须传入有且仅有的一个参数x:
power(5)
# 25
power(15)
# 225
现在,如果我们要计算x3怎么办?可以再定义一个power3函数,但是如果要计算x4、x5……怎么办?我们不可能定义无限多个函数。
你也许想到了,可以把power(x)修改为power(x, n),用来计算xn,说干就干:
def power(x, n):
s = 1
while n > 0:
n = n - 1
s = s * x
return s
对于这个修改后的power(x, n)函数,可以计算任意n次方:
print(power(5))
# 25
print(power(15))
# 225
修改后的power(x, n)函数有两个参数:x和n,这两个参数都是位置参数,调用函数时,传入的两个值按照位置顺序依次赋给参数x和n。
默认参数
新的power(x, n)函数定义没有问题,但是,旧的调用代码失败了,原因是我们增加了一个参数,导致旧的代码因为缺少一个参数而无法正常调用:

这个时候,默认参数就排上用场了。由于我们经常计算x2,所以,完全可以把第二个参数n的默认值设定为2:
def power(x, n = 2):
s = 1
while n > 0:
n = n - 1
s = s * x
return s
print(power(5))
print(power(5, 2))
这样,当我们调用power(5)时,相当于调用power(5, 2):

而对于n > 2的其他情况,就必须明确地传入n,比如power(5, 3)。
从上面的例子可以看出,默认参数可以简化函数的调用。设置默认参数时,有几点要注意:
- 一是必选参数在前,默认参数在后,否则Python的解释器会报错(思考一下为什么默认参数不能放在必选参数前面);
- 二是如何设置默认参数。当函数有多个参数时,把变化大的参数放前面,变化小的参数放后面。变化小的参数就可以作为默认参数。
使用默认参数有什么好处?最大的好处是能降低调用函数的难度。
举个例子,我们写个一年级小学生注册的函数,需要传入name和gender两个参数:
def enroll(name, gender):
print('name:', name)
print('gender:', gender)
这样,调用enroll()函数只需要传入两个参数:
print(enroll('Sarah', 'F'))

如果要继续传入年龄、城市等信息怎么办?这样会使得调用函数的复杂度大大增加。
我们可以把年龄和城市设为默认参数:
def enroll(name, gender, age=6, city='Beijing'):
print('name:', name)
print('gender:', gender)
print('age:', age)
print('city:', city)
这样,大多数学生注册时不需要提供年龄和城市,只提供必须的两个参数:
def enroll(name, gender, age=6, city='Beijing'):
print('name:', name)
print('gender:', gender)
print('age:', age)
print('city:', city)
print(enroll('Sarah', 'F'))
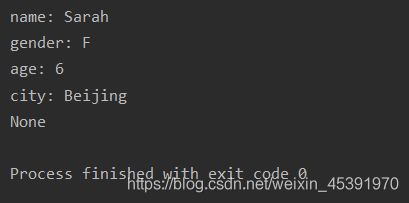
只有与默认参数不符的学生才需要提供额外的信息:
enroll('Bob', 'M', 7)
enroll('Adam', 'M', city='Tianjin')
可见,默认参数降低了函数调用的难度,而一旦需要更复杂的调用时,又可以传递更多的参数来实现。无论是简单调用还是复杂调用,函数只需要定义一个。
有多个默认参数时,调用的时候,既可以按顺序提供默认参数,比如调用enroll(‘Bob’, ‘M’, 7),意思是,除了name,gender这两个参数外,最后1个参数应用在参数age上,city参数由于没有提供,仍然使用默认值。
也可以不按顺序提供部分默认参数。当不按顺序提供部分默认参数时,需要把参数名写上。比如调用enroll(‘Adam’, ‘M’, city=‘Tianjin’),意思是,city参数用传进去的值,其他默认参数继续使用默认值。
默认参数很有用,但使用不当,也会掉坑里。默认参数有个最大的坑,演示如下:
先定义一个函数,传入一个list,添加一个END再返回:
当你正常调用时,结果似乎不错:
当你使用默认参数调用时,一开始结果也是对的:
但是,再次调用add_end()时,结果就不对了:
def add_end(L=[]):
L.append('END')
return L
print(add_end([1, 2, 3]))
print(add_end(['x', 'y', 'z']))
print(add_end())
print(add_end())
print(add_end())

很多初学者很疑惑,默认参数是[],但是函数似乎每次都“记住了”上次添加了’END’后的list。
原因解释如下:
Python函数在定义的时候,默认参数L的值就被计算出来了,即[],因为默认参数L也是一个变量,它指向对象[],每次调用该函数,如果改变了L的内容,则下次调用时,默认参数的内容就变了,不再是函数定义时的[]了。
定义默认参数要牢记一点:默认参数必须指向不变对象!
要修改上面的例子,我们可以用None这个不变对象来实现:
def add_end(L=None):
if L is None:
L = []
L.append('END')
return L
print(add_end())
print(add_end())
print(add_end())

为什么要设计str、None这样的不变对象呢?因为不变对象一旦创建,对象内部的数据就不能修改,这样就减少了由于修改数据导致的错误。此外,由于对象不变,多任务环境下同时读取对象不需要加锁,同时读一点问题都没有。我们在编写程序时,如果可以设计一个不变对象,那就尽量设计成不变对象。
可变参数 (在函数内部自动组装为一个tuple)
在Python函数中,还可以定义可变参数。顾名思义,可变参数就是传入的参数个数是可变的,可以是1个、2个到任意个,还可以是0个。
我们以数学题为例子,给定一组数字a,b,c……,请计算a2 + b2 + c2 + ……。
要定义出这个函数,我们必须确定输入的参数。由于参数个数不确定,我们首先想到可以把a,b,c……作为一个list或tuple传进来,这样,函数可以定义如下:
def calc(numbers):
sum = 0
for n in numbers:
sum = sum + n * n
return sum
但是调用的时候,需要先组装出一个list或tuple:
print(calc([1, 2, 3]))
# 14
print(calc((1, 3, 5, 7)))
# 84
如果利用可变参数,调用函数的方式可以简化成这样:
print(calc(1, 2, 3))
print(calc(1, 3, 5, 7))
所以,我们把函数的参数改为可变参数:
def calc(*numbers):
sum = 0
for n in numbers:
sum = sum + n * n
return sum
定义可变参数和定义一个list或tuple参数相比,仅仅在参数前面加了一个*号。在函数内部,参数numbers接收到的是一个tuple,因此,函数代码完全不变。但是,调用该函数时,可以传入任意个参数,包括0个参数:
def calc(*numbers):
sum = 0
for n in numbers:
sum = sum + n * n
return sum
print(calc(1, 2))
# 5
print(calc())
# 0
如果已经有一个list或者tuple,要调用一个可变参数怎么办?可以这样做:
nums = [1, 2, 3]
print(calc(nums[0], nums[1], nums[2]))
# 14
这种写法当然是可行的,问题是太繁琐,所以Python允许你在list或tuple前面加一个*号,把list或tuple的元素变成可变参数传进去:
nums = [1, 2, 3]
print(calc(*nums))
# 14
*nums表示把nums这个list的所有元素作为可变参数传进去。这种写法相当有用,而且很常见。
关键字参数 (在函数内部自动组装为一个dict)
可变参数允许你传入0个或任意个参数,这些可变参数在函数调用时自动组装为一个tuple。
而关键字参数允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict。
请看示例:
def person(name, age, **kw):
print('name:', name, 'age:', age, 'other:', kw)
函数person除了必选参数name和age外,还接受关键字参数kw。在调用该函数时,可以只传入必选参数:
print(person('Michael', 30))
# name: Michael age: 30 other: {}
也可以传入任意个数的关键字参数:
print(person('Bob', 35, city='Beijing'))
# name: Bob age: 35 other: {'city': 'Beijing'}
print(person('Adam', 45, gender='M', job='Engineer'))
# name: Adam age: 45 other: {'gender': 'M', 'job': 'Engineer'}
关键字参数有什么用?它可以扩展函数的功能。比如,在person函数里,我们保证能接收到name和age这两个参数,但是,如果调用者愿意提供更多的参数,我们也能收到。试想你正在做一个用户注册的功能,除了用户名和年龄是必填项外,其他都是可选项,利用关键字参数来定义这个函数就能满足注册的需求。
和可变参数类似,也可以先组装出一个dict,然后,把该dict转换为关键字参数传进去:
extra = {
'city': 'Beijing', 'job': 'Engineer'}
print(person('Jack', 24, city=extra['city'], job=extra['job']))
# name: Jack age: 24 other: {'city': 'Beijing', 'job': 'Engineer'}
当然,上面复杂的调用可以用简化的写法:
extra = {
'city': 'Beijing', 'job': 'Engineer'}
print(person('Jack', 24, **extra))
# name: Jack age: 24 other: {'city': 'Beijing', 'job': 'Engineer'}
extra表示把extra这个dict的所有key-value用关键字参数传入到函数的kw参数,kw将获得一个dict,注意kw获得的dict是extra的一份拷贝,对kw的改动不会影响到函数外的extra。
命名关键字参数
对于关键字参数,函数的调用者可以传入任意不受限制的关键字参数。至于到底传入了哪些,就需要在函数内部通过kw检查。
仍以person()函数为例,我们希望检查是否有city和job参数:
def person(name, age, **kw):
if 'city' in kw:
# 有city参数
pass
if 'job' in kw:
# 有job参数
pass
print('name:', name, 'age:', age, 'other:', kw)
但是调用者仍可以传入不受限制的关键字参数:
print(person('Jack', 24, city='Beijing', addr='Chaoyang', zipcode=123456))
# name: Jack age: 24 other: {'city': 'Beijing', 'addr': 'Chaoyang', 'zipcode': 123456}
如果要限制关键字参数的名字,就可以用命名关键字参数,例如,只接收city和job作为关键字参数。这种方式定义的函数如下:
def person(name, age, *, city, job):
print(name, age, city, job)
和关键字参数**kw不同,命名关键字参数需要一个特殊分隔符*,*后面的参数被视为命名关键字参数。
调用方式如下:
print(person('Jack', 24, city='Beijing', job='Engineer')
# Jack 24 Beijing Engineer)
如果函数定义中已经有了一个可变参数,后面跟着的命名关键字参数就不再需要一个特殊分隔符*了:
def person(name, age, *args, city, job):
print(name, age, args, city, job)
命名关键字参数必须传入参数名,这和位置参数不同。如果没有传入参数名,调用将报错:
print(person('Jack', 24, 'Beijing', 'Engineer'))

由于调用时缺少参数名city和job,Python解释器把这4个参数均视为位置参数,但person()函数仅接受2个位置参数。
命名关键字参数可以有缺省值(默认值),从而简化调用:
def person(name, age, *, city='Beijing', job):
print(name, age, city, job)
由于命名关键字参数city具有默认值,调用时,可不传入city参数:
print(person('Jack', 24, job='Engineer')
# Jack 24 Beijing Engineer)
使用命名关键字参数时,要特别注意,如果没有可变参数,就必须加一个作为特殊分隔符。如果缺少,Python解释器将无法识别位置参数和命名关键字参数:
def person(name, age, city, job):
# 缺少 *,city和job被视为位置参数
pass
参数组合
在Python中定义函数,可以用必选参数、默认参数、可变参数、关键字参数和命名关键字参数,这5种参数都可以组合使用。但是请注意,参数定义的顺序必须是:必选参数、默认参数、可变参数、命名关键字参数和关键字参数。
比如定义一个函数,包含上述若干种参数:
def f1(a, b, c=0, *args, **kw):
print('a =', a, 'b =', b, 'c =', c, 'args =', args, 'kw =', kw)
def f2(a, b, c=0, *, d, **kw):
print('a =', a, 'b =', b, 'c =', c, 'd =', d, 'kw =', kw)
在函数调用的时候,Python解释器自动按照参数位置和参数名把对应的参数传进去。
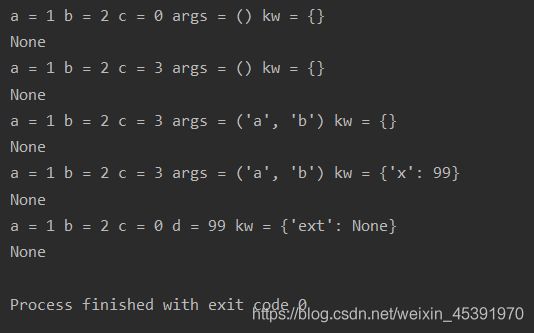
print(f1(1, 2))
# a = 1 b = 2 c = 0 args = () kw = {}
print(f1(1, 2, c=3))
# a = 1 b = 2 c = 3 args = () kw = {}
print(f1(1, 2, 3, 'a', 'b')
# a = 1 b = 2 c = 3 args = ('a', 'b') kw = {}
print(f1(1, 2, 3, 'a', 'b', x=99))
# a = 1 b = 2 c = 3 args = ('a', 'b') kw = {'x': 99}
print(f2(1, 2, d=99, ext=None))
# a = 1 b = 2 c = 0 d = 99 kw = {'ext': None}
注意 python中的方法如果没有写返回值,那么默认返回的none
最神奇的是通过一个tuple和dict,你也可以调用上述函数:
args = (1, 2, 3, 4)
kw = {
'd': 99, 'x': '#'}
print(f1(*args, **kw))
# a = 1 b = 2 c = 3 args = (4,) kw = {'d': 99, 'x': '#'}
args = (1, 2, 3)
kw = {
'd': 88, 'x': '#'}
print(f2(*args, **kw))
# a = 1 b = 2 c = 3 d = 88 kw = {'x': '#'}

所以,对于任意函数,都可以通过类似func(*args, **kw)的形式调用它,无论它的参数是如何定义的。
虽然可以组合多达5种参数,但不要同时使用太多的组合,否则函数接口的可理解性很差。
函数参数小结
小结
Python的函数具有非常灵活的参数形态,既可以实现简单的调用,又可以传入非常复杂的参数。
默认参数一定要用不可变对象,如果是可变对象,程序运行时会有逻辑错误!
要注意定义可变参数和关键字参数的语法:
*args是可变参数,args接收的是一个tuple;
**kw是关键字参数,kw接收的是一个dict。
以及调用函数时如何传入可变参数和关键字参数的语法:
可变参数既可以直接传入:
func(1, 2, 3),
又可以先组装list或tuple,再通过args传入:
func((1, 2, 3));
关键字参数既可以直接传入:
func(a=1, b=2),
又可以先组装dict,再通过kw传入:
func({‘a’: 1, ‘b’: 2})。
使用*args和**kw是Python的习惯写法,当然也可以用其他参数名,但最好使用习惯用法。
命名的关键字参数是为了限制调用者可以传入的参数名,同时可以提供默认值。
定义命名的关键字参数在没有可变参数的情况下不要忘了写分隔符,否则定义的将是位置参数。*
参数的元信息(代码可读性问题)
当写好一个函数以后,想为这个函数的参数添加一些额外的信息,这样的话,其他的使用者就可以清楚的知道这个函数应该怎么使用,这个时候可以使用函数参数注解。
函数参数注解能提示程序员应该怎样正确使用这个函数。
比如,下面这个函数就是一个被注解了的函数:
# 添加函数元信息
def add(x:int, y:int) -> int:
# x:数据类型, -> 返回值数据类型
return x + y
Python解释器不会对这些注解添加任何的语义。
它们不会被类型检查,运行时跟没有加注解之前的效果也没有任何的差距。
但是,对于那些阅读代码的人来说,就有很大的帮助。
例如 leetcode题解中(以925题为例),就有函数相关的元信息,告诉阅读者这个函数的参数和返回值的相关信息。
class Solution:
def isLongPressedName(self, name: str, typed: str) -> bool:
pass
第三方工具和框架可能会对这些注解添加语义,同时它们也会出现在文档中。
def add(x:int, y:int) -> int:
return x + y
help(add)
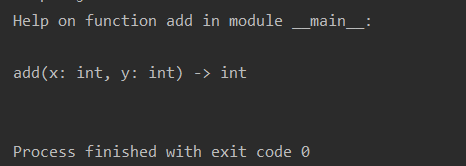
你可以使用任意类型的对象给函数添加注解(例如数字,字符串,对象实例等等), 但是使用类或者字符串会比较好。
函数的注解 annotations属性
函数的注解只存储在函数的__annotations属性中。例如:
def add(x:int, y:int) -> int:
return x + y
print(add.__annotations__)

尽管注解的使用方法可能会有很多中,但是它们的主要用途还是文档。
因为Python并没有类型声明,通常来讲仅仅通过阅读源码很难知道应该传递什么样的参数给这个函数。
而使用函数注解就能给代码阅读人员更多的提示,让他们可以更好的使用函数。
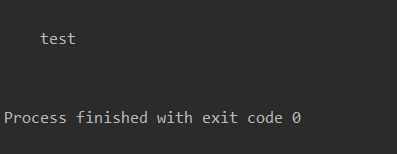
创建装饰器保留函数元信息
使用 functools 库中的 @wraps 装饰器来注解底层包装函数
from functools import wraps
def test_04(func):
@wraps(func)
def wrapper(*args, **kwargs):
result = func(*args, **kwargs)
return result
return wrapper
@test_04
def login():
"""
test
"""
pass
print(login.__doc__) # 输出注释信息
匿名函数和内联函数的用法(lambda函数)
当我们在传入函数时,有些时候,不需要显式地定义函数,直接传入匿名函数更方便。
在Python中,对匿名函数提供了有限支持。还是以map()函数为例,计算f(x)=x2时,除了定义一个f(x)的函数外,还可以直接传入匿名函数:
list(map(lambda x: x * x, [1, 2, 3, 4, 5, 6, 7, 8, 9]))
# [1, 4, 9, 16, 25, 36, 49, 64, 81]
通过对比可以看出,匿名函数lambda x: x * x实际上就是:
def f(x):
return x * x
关键字lambda表示匿名函数,冒号前面的x表示函数参数。
匿名函数有个限制,就是只能有一个表达式,不用写return,返回值就是该表达式的结果。
用匿名函数有个好处,因为函数没有名字,不必担心函数名冲突。此外,匿名函数也是一个函数对象,也可以把匿名函数赋值给一个变量,再利用变量来调用该函数
f = lambda x: x * x
print(f)
# at 0x101c6ef28>
print(f(5))
# 25
同样,也可以把匿名函数作为返回值返回,比如:
def build(x, y):
return lambda: x * x + y * y
闭包和作用域问题
闭包
闭包就是能够读取其他函数内部变量的函数。
函数作用域
Python搜索变量的LEGB顺序(Local >>> Embedded >>> Global >>> Built-in)
事实上,Python查找一个变量时会按照“局部作用域”、“嵌套作用域”、“全局作用域”和“内置作用域”的顺序进行搜索,前三者我们在上面的代码中已经看到了,所谓的“内置作用域”就是Python内置的那些标识符,我们之前用过的input、print、int等都属于内置作用域。
global和nonlocal关键字的作用
global:声明或定义全局变量(要么直接使用现有的全局作用域的变量,要么定义一个变量放到全局作用域)。
nonlocal:声明使用嵌套作用域的变量(嵌套作用域必须存在该变量,否则报错)。
总结:nonlocal与global的区别
首先,要明确 nonlocal 关键字是定义在闭包里面的(不定义在闭包里会抛异常SyntaxError: nonlocal declaration not allowed at module level)
global 是对整个环境下的变量起作用,而不是对函数内的变量起作用。
nonlocal:如果在闭包内给该变量赋值,那么修改的其实是闭包外那个作用域中的变量。
global:用来表示对该变量的赋值操作,将会直接修改模块作用域里的那个变量。(nonlocal与global互为补充)
装饰器函数(使用装饰器和取消装饰器)
第九天的学习中有
https://blog.csdn.net/weixin_45391970/article/details/109213321
面向对象相关知识
三大支柱:封装、继承、多态
例子:工资结算系统。
在第九天的学习中有
https://blog.csdn.net/weixin_45391970/article/details/10885960
类与类之间的关系
is-a关系:继承
has-a关系:关联 / 聚合 / 合成
use-a关系:依赖
例子:扑克游戏
在第九天的学习中有
https://blog.csdn.net/weixin_45391970/article/details/108859604
对象的复制(深复制/深拷贝/深度克隆和浅复制/浅拷贝/影子克隆)
垃圾回收、循环引用和弱引用
Python使用了自动化内存管理,这种管理机制以引用计数为基础,同时也引入了标记-清除和分代收集两种机制为辅的策略。
typedef struct _object {
/* 引用计数 */
int ob_refcnt;
/* 对象指针 */
struct _typeobject *ob_type;
} PyObject;
/* 增加引用计数的宏定义 */
#define Py_INCREF(op) ((op)->ob_refcnt++)
/* 减少引用计数的宏定义 */
#define Py_DECREF(op) \ //减少计数
if (--(op)->ob_refcnt != 0) \
; \
else \
__Py_Dealloc((PyObject *)(op))
导致引用计数+1的情况:
对象被创建,例如a = 23
对象被引用,例如b = a
对象被作为参数,传入到一个函数中,例如f(a)
对象作为一个元素,存储在容器中,例如list1 = [a, a]
导致引用计数-1的情况:
对象的别名被显式销毁,例如del a
对象的别名被赋予新的对象,例如a = 24
一个对象离开它的作用域,例如f函数执行完毕时,f函数中的局部变量(全局变量不会)
对象所在的容器被销毁,或从容器中删除对象
引用计数可能会导致循环引用问题,而循环引用会导致内存泄露,如下面的代码所示。为了解决这个问题,Python中引入了“标记-清除”和“分代收集”。在创建一个对象的时候,对象被放在第一代中,如果在第一代的垃圾检查中对象存活了下来,该对象就会被放到第二代中,同理在第二代的垃圾检查中对象存活下来,该对象就会被放到第三代中。
# 循环引用会导致内存泄露 - Python除了引用技术还引入了标记清理和分代回收
# 在Python 3.6以前如果重写__del__魔术方法会导致循环引用处理失效
# 如果不想造成循环引用可以使用弱引用
list1 = []
list2 = []
list1.append(list2)
list2.append(list1)
以下情况会导致垃圾回收:
调用gc.collect()
gc模块的计数器达到阀值
程序退出
如果循环引用中两个对象都定义了__del__方法,gc模块不会销毁这些不可达对象,因为gc模块不知道应该先调用哪个对象的__del__方法,这个问题在Python 3.6中得到了解决。
也可以通过weakref模块构造弱引用的方式来解决循环引用的问题。
魔法属性和方法
(请参考《Python魔法方法指南》)
有几个小问题请大家思考:
自定义的对象能不能使用运算符做运算?
自定义的对象能不能放到set中?能去重吗?
自定义的对象能不能作为dict的键?
自定义的对象能不能使用上下文语法?
何为魔法属性
魔法属性和魔法方法是python内置的一些属性和方法。代表着特殊意义,命名时会在前后加两个下划线,在执行特定的操作时,系统会自动调用。
接下来,我们就列举一些常见的魔法属性和方法。
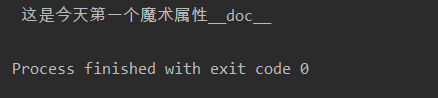
__doc__魔法属性 表示类的描述信息
class Fo:
""" 这是今天第一个魔术属性__doc__"""
def func(self):
pass
print(Fo.__doc__)
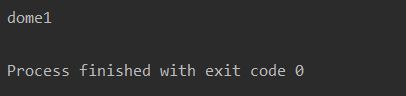
__moudle__魔法属性 表示当前操作的对象在那个模块
dome1.py
# -*- coding:utf-8 -*-
class Person(object):
def __init__(self):
self.name =' __moudle__'
dome2.py
from dome1 import Person
obj = Person()
print(obj.__module__)
__class__魔法属性 表示当前操作的对象的类是什么
dome1.py
# -*- coding:utf-8 -*-
class Person(object):
def __init__(self):
self.name =' __moudle__'
dom2.py
from dome1 import Person
obj = Person()
print(obj.__class__)
魔法方法
init () 魔法方法
初始化类属性方法,通过类创建对象时,自动触发执行
class Person:
def __init__(self, name):
self.name = name
self.age = 18
obj = Person('python')
print(obj.name)
del() 魔法方法
当对象在内存中被释放时,自动触发执行
class Dome:
def __del__(self):
print('类已经被删除')
obj = Dome()

str () 魔法方法
打印 对象 时,默认输出该方法的返回值
class Dome:
def __str__(self):
return 'python'
obj = Dome()
print(obj)

dict() 魔法方法
类或对象中的所有属性
class Province(object):
country = 'China'
def __init__(self, name, count):
self.name = name
self.count = count
def func(self, *args, **kwargs):
print('func')
# 获取类的属性,即:类属性、方法、
print(Province.__dict__)
obj1 = Province('山东', 10000)
print(obj1.__dict__)
obj2 = Province('山西', 20000)
print(obj2.__dict__)
输出结果
{
'__module__': '__main__', 'country': 'China', '__init__': <function Province.__init__ at 0x0000014573B3E7B8>, 'func': <function Province.func at 0x0000014573B3ED08>, '__dict__': <attribute '__dict__' of 'Province' objects>, '__weakref__': <attribute '__weakref__' of 'Province' objects>, '__doc__': None}
{
'name': '山东', 'count': 10000}
{
'name': '山西', 'count': 20000}
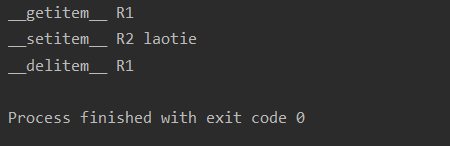
getitem(),setitem(),delitem()魔法方法
用于索引操作,如字典。以上分别表示获取、设置、删除数据
# -*- coding:utf-8 -*-
class Dome(object):
def __getitem__(self, key):
print('__getitem__', key)
def __setitem__(self, key, value):
print('__setitem__', key, value)
def __delitem__(self, key):
print('__delitem__', key)
obj = Dome()
result = obj['R1'] # 自动触发执行 __getitem__
obj['R2'] = 'laotie' # 自动触发执行 __setitem__
del obj['R1'] # 自动触发执行 __delitem__
由于这三个方法单独使用没作用,所以通常配合使用来实现某种功能
iter()魔法方法
让一个对象变得可以迭代
next()魔法方法
定义一个迭代器,让其能够通过next(迭代对象的迭代器)对一个可迭代对象进行迭代
(这两个方法迭代器中讲了)
name()魔法方法
这个魔法方法,并不作用于类(这里我把它归为魔法方法可能不够严谨),当前程序的名称
注意,该方法所在的.py文件如果作为一个工具包引入时,它里面包括的代码不会被引入,通常作为开发人员的调试空间(为所欲为也不会被外界发现)
上下文管理器 enter()和__exit__()方法
enter()和__exit__()方法,它就属于上下文管理对象。上下文管理器的主要原理是你的代码会放到 with 语句块中执行。 当出现 with 语句的时候,对象的 enter() 方法被触发, 它返回的值(如果有的话)会被赋值给 as 声明的变量。然后,with 语句块里面的代码开始执行。 最后,exit() 方法被触发进行清理工作。
enter():进入于此相关的上下文。如果存在该方法,with语法会把该方法的返回值作为绑定到as子句中指定的变量上。
exit:退出与此对象相关的上下文
文件IO操作可以对文件对象使用上下文管理,使用with……as语法。
class Test(object):
def __init__(self,name,flag):
self.filename = name
self.flag = flag
def __enter__(self):
'''
@summary: 使用with语句是调用,会话管理器在代码块开始前调用,返回值与as后的参数绑定
'''
print "__enter__:Open %s"%self.filename
self.f = open(self.filename,self.flag)
return self.f
def __exit__(self,Type, value, traceback):
'''
@summary: 会话管理器在代码块执行完成好后调用(不同于__del__)(必须是4个参数)
'''
print "__exit__:Close %s"%self.filename
self.f.close()
def __del__(self):
print "__del__"
if __name__ == "__main__":
with Test('test.txt','r+') as f:
content = f.read()
print content
print "end"
class Point:
def __init__(self):
print("init")
def __enter__(self): # 进去的时候做的事
print("enter")
def __exit__(self, exc_type, exc_val, exc_tb): # 离开的时候做的事情
print("exit")
with Point() as f:
print("do sth.")
执行顺序
__init__初始化类属性方法,通过类创建对象时,自动触发执行(最先执行)

混入(Mixin)
例子:自定义字典限制只有在指定的key不存在时才能在字典中设置键值对。
class SetOnceMappingMixin:
"""自定义混入类"""
__slots__ = ()
def __setitem__(self, key, value):
if key in self:
raise KeyError(str(key) + ' already set')
return super().__setitem__(key, value)
class SetOnceDict(SetOnceMappingMixin, dict):
"""自定义字典"""
pass
my_dict= SetOnceDict()
try:
my_dict['username'] = 'jackfrued'
my_dict['username'] = 'hellokitty'
except KeyError:
pass
print(my_dict)
元编程和元类
对象是通过类创建的,类是通过元类创建的,元类提供了创建类的元信息。所有的类都直接或间接的继承自object,所有的元类都直接或间接的继承自type。
例子:用元类实现单例模式。
import threading
class SingletonMeta(type):
"""自定义元类"""
def __init__(cls, *args, **kwargs):
cls.__instance = None
cls.__lock = threading.RLock()
super().__init__(*args, **kwargs)
def __call__(cls, *args, **kwargs):
if cls.__instance is None:
with cls.__lock:
if cls.__instance is None:
cls.__instance = super().__call__(*args, **kwargs)
return cls.__instance
class President(metaclass=SingletonMeta):
"""总统(单例类)"""
pass
面向对象设计原则
单一职责原则 (SRP)- 一个类只做该做的事情(类的设计要高内聚)
开闭原则 (OCP)- 软件实体应该对扩展开发对修改关闭
依赖倒转原则(DIP)- 面向抽象编程(在弱类型语言中已经被弱化)
里氏替换原则(LSP) - 任何时候可以用子类对象替换掉父类对象
接口隔离原则(ISP)- 接口要小而专不要大而全(Python中没有接口的概念)
合成聚合复用原则(CARP) - 优先使用强关联关系而不是继承关系复用代码
最少知识原则(迪米特法则,LoD)- 不要给没有必然联系的对象发消息
说明:上面加粗的字母放在一起称为面向对象的SOLID原则。
GoF设计模式
GOF的23种设计模式 详见以下博客
https://www.jianshu.com/p/da3ffb955a93
创建型模式:单例、工厂、建造者、原型
结构型模式:适配器、门面(外观)、代理
行为型模式:迭代器、观察者、状态、策略
例子:可插拔的哈希算法(策略模式)。
class StreamHasher():
"""哈希摘要生成器"""
def __init__(self, alg='md5', size=4096):
self.size = size
alg = alg.lower()
self.hasher = getattr(__import__('hashlib'), alg.lower())()
def __call__(self, stream):
return self.to_digest(stream)
def to_digest(self, stream):
"""生成十六进制形式的摘要"""
for buf in iter(lambda: stream.read(self.size), b''):
self.hasher.update(buf)
return self.hasher.hexdigest()
def main():
"""主函数"""
hasher1 = StreamHasher()
with open('Python-3.7.6.tgz', 'rb') as stream:
print(hasher1.to_digest(stream))
hasher2 = StreamHasher('sha1')
with open('Python-3.7.6.tgz', 'rb') as stream:
print(hasher2(stream))
if __name__ == '__main__':
main()
迭代器和生成器
迭代器
https://blog.csdn.net/weixin_45391970/article/details/109213321
生成器
https://blog.csdn.net/weixin_45391970/article/details/109140959
并发编程
Python中实现并发编程的三种方案:多线程、多进程和异步I/O。并发编程的好处在于可以提升程序的执行效率以及改善用户体验;坏处在于并发的程序不容易开发和调试,同时对其他程序来说它并不友好。
多线程
Python中提供了Thread类并辅以Lock、Condition、Event、Semaphore和Barrier。Python中有GIL来防止多个线程同时执行本地字节码,这个锁对于CPython是必须的,因为CPython的内存管理并不是线程安全的,因为GIL的存在多线程并不能发挥CPU的多核特性。
"""
面试题:进程和线程的区别和联系?
进程 - 操作系统分配内存的基本单位 - 一个进程可以包含一个或多个线程
线程 - 操作系统分配CPU的基本单位
并发编程(concurrent programming)
1. 提升执行性能 - 让程序中没有因果关系的部分可以并发的执行
2. 改善用户体验 - 让耗时间的操作不会造成程序的假死
"""
import glob
import os
import threading
from PIL import Image
PREFIX = 'thumbnails'
def generate_thumbnail(infile, size, format='PNG'):
"""生成指定图片文件的缩略图"""
file, ext = os.path.splitext(infile)
file = file[file.rfind('/') + 1:]
outfile = f'{PREFIX}/{file}_{size[0]}_{size[1]}.{ext}'
img = Image.open(infile)
img.thumbnail(size, Image.ANTIALIAS)
img.save(outfile, format)
def main():
"""主函数"""
if not os.path.exists(PREFIX):
os.mkdir(PREFIX)
for infile in glob.glob('images/*.png'):
for size in (32, 64, 128):
# 创建并启动线程
threading.Thread(
target=generate_thumbnail,
args=(infile, (size, size))
).start()
if __name__ == '__main__':
main()
多个线程竞争资源的情况。
"""
多线程程序如果没有竞争资源处理起来通常也比较简单
当多个线程竞争临界资源的时候如果缺乏必要的保护措施就会导致数据错乱
说明:临界资源就是被多个线程竞争的资源
"""
import time
import threading
from concurrent.futures import ThreadPoolExecutor
class Account(object):
"""银行账户"""
def __init__(self):
self.balance = 0.0
self.lock = threading.Lock()
def deposit(self, money):
# 通过锁保护临界资源
with self.lock:
new_balance = self.balance + money
time.sleep(0.001)
self.balance = new_balance
class AddMoneyThread(threading.Thread):
"""自定义线程类"""
def __init__(self, account, money):
self.account = account
self.money = money
# 自定义线程的初始化方法中必须调用父类的初始化方法
super().__init__()
def run(self):
# 线程启动之后要执行的操作
self.account.deposit(self.money)
def main():
"""主函数"""
account = Account()
# 创建线程池
pool = ThreadPoolExecutor(max_workers=10)
futures = []
for _ in range(100):
# 创建线程的第1种方式
# threading.Thread(
# target=account.deposit, args=(1, )
# ).start()
# 创建线程的第2种方式
# AddMoneyThread(account, 1).start()
# 创建线程的第3种方式
# 调用线程池中的线程来执行特定的任务
future = pool.submit(account.deposit, 1)
futures.append(future)
# 关闭线程池
pool.shutdown()
for future in futures:
future.result()
print(account.balance)
if __name__ == '__main__':
main()
修改上面的程序,启动5个线程向账户中存钱,5个线程从账户中取钱,取钱时如果余额不足就暂停线程进行等待。为了达到上述目标,需要对存钱和取钱的线程进行调度,在余额不足时取钱的线程暂停并释放锁,而存钱的线程将钱存入后要通知取钱的线程,使其从暂停状态被唤醒。可以使用threading模块的Condition来实现线程调度,该对象也是基于锁来创建的,代码如下所示:
"""
多个线程竞争一个资源 - 保护临界资源 - 锁(Lock/RLock)
多个线程竞争多个资源(线程数>资源数) - 信号量(Semaphore)
多个线程的调度 - 暂停线程执行/唤醒等待中的线程 - Condition
"""
from concurrent.futures import ThreadPoolExecutor
from random import randint
from time import sleep
import threading
class Account:
"""银行账户"""
def __init__(self, balance=0):
self.balance = balance
lock = threading.RLock()
self.condition = threading.Condition(lock)
def withdraw(self, money):
"""取钱"""
with self.condition:
while money > self.balance:
self.condition.wait()
new_balance = self.balance - money
sleep(0.001)
self.balance = new_balance
def deposit(self, money):
"""存钱"""
with self.condition:
new_balance = self.balance + money
sleep(0.001)
self.balance = new_balance
self.condition.notify_all()
def add_money(account):
while True:
money = randint(5, 10)
account.deposit(money)
print(threading.current_thread().name,
':', money, '====>', account.balance)
sleep(0.5)
def sub_money(account):
while True:
money = randint(10, 30)
account.withdraw(money)
print(threading.current_thread().name,
':', money, '<====', account.balance)
sleep(1)
def main():
account = Account()
with ThreadPoolExecutor(max_workers=15) as pool:
for _ in range(5):
pool.submit(add_money, account)
for _ in range(10):
pool.submit(sub_money, account)
if __name__ == '__main__':
main()
部分结果如下图所示
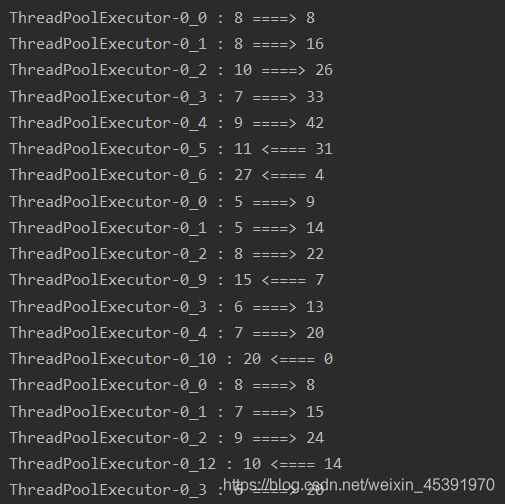
多进程
多进程可以有效的解决GIL的问题,实现多进程主要的类是Process,其他辅助的类跟threading模块中的类似,进程间共享数据可以使用管道、套接字等,在multiprocessing模块中有一个Queue类,它基于管道和锁机制提供了多个进程共享的队列。下面是官方文档上关于多进程和进程池的一个示例。
"""
多进程和进程池的使用
多线程因为GIL的存在不能够发挥CPU的多核特性
对于计算密集型任务应该考虑使用多进程
time python3 example22.py
real 0m11.512s
user 0m39.319s
sys 0m0.169s
使用多进程后实际执行时间为11.512秒,而用户时间39.319秒约为实际执行时间的4倍
这就证明我们的程序通过多进程使用了CPU的多核特性,而且这台计算机配置了4核的CPU
"""
import concurrent.futures
import math
PRIMES = [
1116281,
1297337,
104395303,
472882027,
533000389,
817504243,
982451653,
112272535095293,
112582705942171,
112272535095293,
115280095190773,
115797848077099,
1099726899285419
] * 5
def is_prime(n):
"""判断素数"""
if n % 2 == 0:
return False
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3, sqrt_n + 1, 2):
if n % i == 0:
return False
return True
def main():
"""主函数"""
with concurrent.futures.ProcessPoolExecutor() as executor:
for number, prime in zip(PRIMES, executor.map(is_prime, PRIMES)):
print('%d is prime: %s' % (number, prime))
if __name__ == '__main__':
main()
部分结果
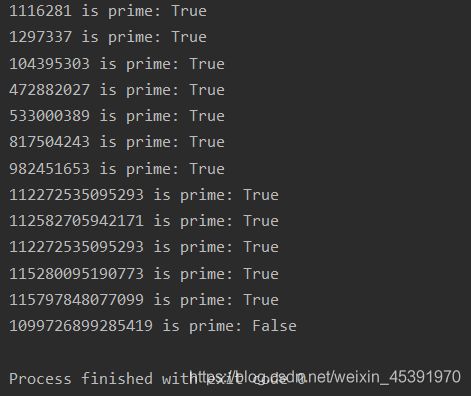
重点:多线程和多进程的比较。
以下情况需要使用多线程:
程序需要维护许多共享的状态(尤其是可变状态),Python中的列表、字典、集合都是线程安全的,所以使用线程而不是进程维护共享状态的代价相对较小。
程序会花费大量时间在I/O操作上,没有太多并行计算的需求且不需占用太多的内存。
以下情况需要使用多进程:
程序执行计算密集型任务(如:字节码操作、数据处理、科学计算)。
程序的输入可以并行的分成块,并且可以将运算结果合并。
程序在内存使用方面没有任何限制且不强依赖于I/O操作(如:读写文件、套接字等)。
异步处理
从调度程序的任务队列中挑选任务,该调度程序以交叉的形式执行这些任务,我们并不能保证任务将以某种顺序去执行,因为执行顺序取决于队列中的一项任务是否愿意将CPU处理时间让位给另一项任务。异步任务通常通过多任务协作处理的方式来实现,由于执行时间和顺序的不确定,因此需要通过回调式编程或者future对象来获取任务执行的结果。Python 3通过asyncio模块和await和async关键字(在Python 3.7中正式被列为关键字)来支持异步处理。
"""
异步I/O - async / await
"""
import asyncio
def num_generator(m, n):
"""指定范围的数字生成器"""
yield from range(m, n + 1)
async def prime_filter(m, n):
"""素数过滤器"""
primes = []
for i in num_generator(m, n):
flag = True
for j in range(2, int(i ** 0.5 + 1)):
if i % j == 0:
flag = False
break
if flag:
print('Prime =>', i)
primes.append(i)
await asyncio.sleep(0.001)
return tuple(primes)
async def square_mapper(m, n):
"""平方映射器"""
squares = []
for i in num_generator(m, n):
print('Square =>', i * i)
squares.append(i * i)
await asyncio.sleep(0.001)
return squares
def main():
"""主函数"""
loop = asyncio.get_event_loop()
future = asyncio.gather(prime_filter(2, 100), square_mapper(1, 100))
future.add_done_callback(lambda x: print(x.result()))
loop.run_until_complete(future)
loop.close()
if __name__ == '__main__':
main()
说明:上面的代码使用get_event_loop函数获得系统默认的事件循环,通过gather函数可以获得一个future对象,future对象的add_done_callback可以添加执行完成时的回调函数,loop对象的run_until_complete方法可以等待通过future对象获得协程执行结果。
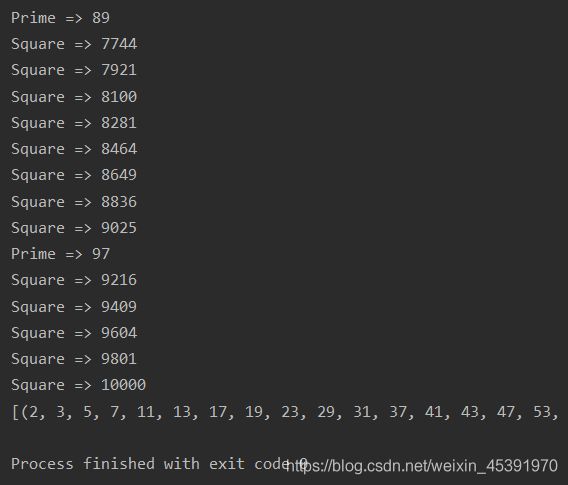
Python中有一个名为aiohttp的第三方库,它提供了异步的HTTP客户端和服务器,这个三方库可以跟asyncio模块一起工作,并提供了对Future对象的支持。Python 3.6中引入了async和await来定义异步执行的函数以及创建异步上下文,在Python 3.7中它们正式成为了关键字。下面的代码异步的从5个URL中获取页面并通过正则表达式的命名捕获组提取了网站的标题。
# 下面的代码异步的从5个URL中获取页面并通过正则表达式的命名捕获组提取了网站的标题。
import asyncio
import re
import aiohttp
PATTERN = re.compile(r'\(?P.*)\<\/title\>'</span><span class="token punctuation">)</span>
<span class="token keyword">async</span> <span class="token keyword">def</span> <span class="token function">fetch_page</span><span class="token punctuation">(</span>session<span class="token punctuation">,</span> url<span class="token punctuation">)</span><span class="token punctuation">:</span>
<span class="token keyword">async</span> <span class="token keyword">with</span> session<span class="token punctuation">.</span>get<span class="token punctuation">(</span>url<span class="token punctuation">,</span> ssl<span class="token operator">=</span><span class="token boolean">False</span><span class="token punctuation">)</span> <span class="token keyword">as</span> resp<span class="token punctuation">:</span>
<span class="token keyword">return</span> <span class="token keyword">await</span> resp<span class="token punctuation">.</span>text<span class="token punctuation">(</span><span class="token punctuation">)</span>
<span class="token keyword">async</span> <span class="token keyword">def</span> <span class="token function">show_title</span><span class="token punctuation">(</span>url<span class="token punctuation">)</span><span class="token punctuation">:</span>
<span class="token keyword">async</span> <span class="token keyword">with</span> aiohttp<span class="token punctuation">.</span>ClientSession<span class="token punctuation">(</span><span class="token punctuation">)</span> <span class="token keyword">as</span> session<span class="token punctuation">:</span>
html <span class="token operator">=</span> <span class="token keyword">await</span> fetch_page<span class="token punctuation">(</span>session<span class="token punctuation">,</span> url<span class="token punctuation">)</span>
<span class="token keyword">print</span><span class="token punctuation">(</span>PATTERN<span class="token punctuation">.</span>search<span class="token punctuation">(</span>html<span class="token punctuation">)</span><span class="token punctuation">.</span>group<span class="token punctuation">(</span><span class="token string">'title'</span><span class="token punctuation">)</span><span class="token punctuation">)</span>
<span class="token keyword">def</span> <span class="token function">main</span><span class="token punctuation">(</span><span class="token punctuation">)</span><span class="token punctuation">:</span>
urls <span class="token operator">=</span> <span class="token punctuation">(</span><span class="token string">'https://www.python.org/'</span><span class="token punctuation">,</span>
<span class="token string">'https://git-scm.com/'</span><span class="token punctuation">,</span>
<span class="token string">'https://www.jd.com/'</span><span class="token punctuation">,</span>
<span class="token string">'https://www.taobao.com/'</span><span class="token punctuation">,</span>
<span class="token string">'https://www.douban.com/'</span><span class="token punctuation">)</span>
loop <span class="token operator">=</span> asyncio<span class="token punctuation">.</span>get_event_loop<span class="token punctuation">(</span><span class="token punctuation">)</span>
cos <span class="token operator">=</span> <span class="token punctuation">[</span>show_title<span class="token punctuation">(</span>url<span class="token punctuation">)</span> <span class="token keyword">for</span> url <span class="token keyword">in</span> urls<span class="token punctuation">]</span>
loop<span class="token punctuation">.</span>run_until_complete<span class="token punctuation">(</span>asyncio<span class="token punctuation">.</span>wait<span class="token punctuation">(</span>cos<span class="token punctuation">)</span><span class="token punctuation">)</span>
loop<span class="token punctuation">.</span>close<span class="token punctuation">(</span><span class="token punctuation">)</span>
<span class="token keyword">if</span> __name__ <span class="token operator">==</span> <span class="token string">'__main__'</span><span class="token punctuation">:</span>
main<span class="token punctuation">(</span><span class="token punctuation">)</span>
</code></pre>
<h2>重点:异步I/O与多进程的比较。</h2>
<blockquote>
<p>当程序不需要真正的并发性或并行性,而是更多的依赖于异步处理和回调时,asyncio就是一种很好的选择。如果程序中有大量的等待与休眠时,也应该考虑asyncio,它很适合编写没有实时数据处理需求的Web应用服务器。</p>
</blockquote>
<p>Python还有很多用于处理并行任务的三方库,例如:joblib、PyMP等。实际开发中,要提升系统的可扩展性和并发性通常有垂直扩展(增加单个节点的处理能力)和水平扩展(将单个节点变成多个节点)两种做法。可以通过消息队列来实现应用程序的解耦合,<strong>消息队列相当于是多线程同步队列的扩展版本</strong>,不同机器上的应用程序相当于就是线程,而共享的分布式消息队列就是原来程序中的Queue。消息队列(面向消息的中间件)的最流行和最标准化的实现是AMQP(高级消息队列协议),AMQP源于金融行业,提供了排队、路由、可靠传输、安全等功能,最著名的实现包括:Apache的ActiveMQ、RabbitMQ等。</p>
<p>要实现任务的异步化,可以使用名为Celery的三方库。Celery是Python编写的分布式任务队列,它使用分布式消息进行工作,可以基于RabbitMQ或Redis来作为后端的消息代理。</p>
<h1>小结</h1>
<p>常用数据结构<br> 函数的高级用法 - “一等公民” / 高阶函数 / Lambda函数 / 作用域和闭包 / 装饰器<br> 面向对象高级知识 - “三大支柱” / 类与类之间的关系 / 垃圾回收 / 魔术属性和方法 / 混入 / 元类 / 面向对象设计原则 / GoF设计模式<br> 迭代器和生成器 - 相关魔术方法 / 创建生成器的两种方式 /<br> 并发和异步编程 - 多线程 / 多进程 / 异步IO / async和await</p>
</div>
</div>
</div>
</div>
</div>
<!--PC和WAP自适应版-->
<div id="SOHUCS" sid="1355673238759354368"></div>
<script type="text/javascript" src="/views/front/js/chanyan.js"></script>
<!-- 文章页-底部 动态广告位 -->
<div class="youdao-fixed-ad" id="detail_ad_bottom"></div>
</div>
<div class="col-md-3">
<div class="row" id="ad">
<!-- 文章页-右侧1 动态广告位 -->
<div id="right-1" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_1"> </div>
</div>
<!-- 文章页-右侧2 动态广告位 -->
<div id="right-2" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_2"></div>
</div>
<!-- 文章页-右侧3 动态广告位 -->
<div id="right-3" class="col-lg-12 col-md-12 col-sm-4 col-xs-4 ad">
<div class="youdao-fixed-ad" id="detail_ad_3"></div>
</div>
</div>
</div>
</div>
</div>
</div>
<div class="container">
<h4 class="pt20 mb15 mt0 border-top">你可能感兴趣的:(100天学python,1024程序员节)</h4>
<div id="paradigm-article-related">
<div class="recommend-post mb30">
<ul class="widget-links">
<li><a href="/article/1943993659967991808.htm"
title="系统学习Python——并发模型和异步编程:进程、线程和GIL" target="_blank">系统学习Python——并发模型和异步编程:进程、线程和GIL</a>
<span class="text-muted"></span>
<div>分类目录:《系统学习Python》总目录在文章《并发模型和异步编程:基础知识》我们简单介绍了Python中的进程、线程和协程。本文就着重介绍Python中的进程、线程和GIL的关系。Python解释器的每个实例都是一个进程。使用multiprocessing或concurrent.futures库可以启动额外的Python进程。Python的subprocess库用于启动运行外部程序(不管使用何种</div>
</li>
<li><a href="/article/1943992776169418752.htm"
title="Flask框架入门:快速搭建轻量级Python网页应用" target="_blank">Flask框架入门:快速搭建轻量级Python网页应用</a>
<span class="text-muted">「已注销」</span>
<a class="tag" taget="_blank" href="/search/python-AI/1.htm">python-AI</a><a class="tag" taget="_blank" href="/search/python%E5%9F%BA%E7%A1%80/1.htm">python基础</a><a class="tag" taget="_blank" href="/search/%E7%BD%91%E7%AB%99%E7%BD%91%E7%BB%9C/1.htm">网站网络</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/flask/1.htm">flask</a><a class="tag" taget="_blank" href="/search/%E5%90%8E%E7%AB%AF/1.htm">后端</a>
<div>转载:Flask框架入门:快速搭建轻量级Python网页应用1.Flask基础Flask是一个使用Python编写的轻量级Web应用框架。它的设计目标是让Web开发变得快速简单,同时保持应用的灵活性。Flask依赖于两个外部库:Werkzeug和Jinja2,Werkzeug作为WSGI工具包处理Web服务的底层细节,Jinja2作为模板引擎渲染模板。安装Flask非常简单,可以使用pip安装命令</div>
</li>
<li><a href="/article/1943991891796226048.htm"
title="Python Flask 框架入门:快速搭建 Web 应用的秘诀" target="_blank">Python Flask 框架入门:快速搭建 Web 应用的秘诀</a>
<span class="text-muted">Python编程之道</span>
<a class="tag" taget="_blank" href="/search/Python%E4%BA%BA%E5%B7%A5%E6%99%BA%E8%83%BD%E4%B8%8E%E5%A4%A7%E6%95%B0%E6%8D%AE/1.htm">Python人工智能与大数据</a><a class="tag" taget="_blank" href="/search/Python%E7%BC%96%E7%A8%8B%E4%B9%8B%E9%81%93/1.htm">Python编程之道</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/flask/1.htm">flask</a><a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a><a class="tag" taget="_blank" href="/search/ai/1.htm">ai</a>
<div>PythonFlask框架入门:快速搭建Web应用的秘诀关键词Flask、微框架、路由系统、Jinja2模板、请求处理、WSGI、Web开发摘要想快速用Python搭建一个灵活的Web应用?Flask作为“微框架”代表,凭借轻量、可扩展的特性,成为初学者和小型项目的首选。本文将从Flask的核心概念出发,结合生活化比喻、代码示例和实战案例,带你一步步掌握:如何用Flask搭建第一个Web应用?路由</div>
</li>
<li><a href="/article/1943990630690648064.htm"
title="【LeetCode 热题 100】24. 两两交换链表中的节点——(解法一)迭代+哨兵" target="_blank">【LeetCode 热题 100】24. 两两交换链表中的节点——(解法一)迭代+哨兵</a>
<span class="text-muted">xumistore</span>
<a class="tag" taget="_blank" href="/search/LeetCode/1.htm">LeetCode</a><a class="tag" taget="_blank" href="/search/leetcode/1.htm">leetcode</a><a class="tag" taget="_blank" href="/search/%E9%93%BE%E8%A1%A8/1.htm">链表</a><a class="tag" taget="_blank" href="/search/%E7%AE%97%E6%B3%95/1.htm">算法</a><a class="tag" taget="_blank" href="/search/java/1.htm">java</a>
<div>Problem:24.两两交换链表中的节点题目:给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。文章目录整体思路完整代码时空复杂度时间复杂度:O(N)空间复杂度:O(1)整体思路这段代码旨在解决一个经典的链表操作问题:两两交换链表中的节点(SwapNodesinPairs)。问题要求将链表中每两个相邻的节点进行交换</div>
</li>
<li><a href="/article/1943988487875260416.htm"
title="python_虚拟环境" target="_blank">python_虚拟环境</a>
<span class="text-muted">阿_焦</span>
<a class="tag" taget="_blank" href="/search/python/1.htm">python</a>
<div>第一、配置虚拟环境:virtualenv(1)pipvirtualenv>安装虚拟环境包(2)pipinstallvirtualenvwrapper-win>安装虚拟环境依赖包(3)c盘创建虚拟目录>C:\virtualenv>配置环境变量【了解一下】:(1)如何使用virtualenv创建虚拟环境a、cd到C:\virtualenv目录下:b、mkvirtualenvname>创建虚拟环境nam</div>
</li>
<li><a href="/article/1943985208218939392.htm"
title="Python爱心光波" target="_blank">Python爱心光波</a>
<span class="text-muted"></span>
<div>系列文章序号直达链接Tkinter1Python李峋同款可写字版跳动的爱心2Python跳动的双爱心3Python蓝色跳动的爱心4Python动漫烟花5Python粒子烟花Turtle1Python满屏飘字2Python蓝色流星雨3Python金色流星雨4Python漂浮爱心5Python爱心光波①6Python爱心光波②7Python满天繁星8Python五彩气球9Python白色飘雪10Pyt</div>
</li>
<li><a href="/article/1943985208697090048.htm"
title="Python流星雨" target="_blank">Python流星雨</a>
<span class="text-muted">Want595</span>
<a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>文章目录系列文章写在前面技术需求完整代码代码分析1.模块导入2.画布设置3.画笔设置4.颜色列表5.流星类(Star)6.流星对象创建7.主循环8.流星运动逻辑9.视觉效果10.总结写在后面系列文章序号直达链接表白系列1Python制作一个无法拒绝的表白界面2Python满屏飘字表白代码3Python无限弹窗满屏表白代码4Python李峋同款可写字版跳动的爱心5Python流星雨代码6Python</div>
</li>
<li><a href="/article/1943983065500020736.htm"
title="Python之七彩花朵代码实现" target="_blank">Python之七彩花朵代码实现</a>
<span class="text-muted">PlutoZuo</span>
<a class="tag" taget="_blank" href="/search/Python/1.htm">Python</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>Python之七彩花朵代码实现文章目录Python之七彩花朵代码实现下面是一个简单的使用Python的七彩花朵。这个示例只是一个简单的版本,没有很多高级功能,但它可以作为一个起点,你可以在此基础上添加更多功能。importturtleastuimportrandomasraimportmathtu.setup(1.0,1.0)t=tu.Pen()t.ht()colors=['red','skybl</div>
</li>
<li><a href="/article/1943982902379343872.htm"
title="Python 脚本最佳实践2025版" target="_blank">Python 脚本最佳实践2025版</a>
<span class="text-muted"></span>
<div>前文可以直接把这篇文章喂给AI,可以放到AI角色设定里,也可以直接作为提示词.这样,你只管提需求,写脚本就让AI来.概述追求简洁和清晰:脚本应简单明了。使用函数(functions)、常量(constants)和适当的导入(import)实践来有逻辑地组织你的Python脚本。使用枚举(enumerations)和数据类(dataclasses)等数据结构高效管理脚本状态。通过命令行参数增强交互性</div>
</li>
<li><a href="/article/1943982558085705728.htm"
title="(Python基础篇)了解和使用分支结构" target="_blank">(Python基础篇)了解和使用分支结构</a>
<span class="text-muted">EternityArt</span>
<a class="tag" taget="_blank" href="/search/%E5%9F%BA%E7%A1%80%E7%AF%87/1.htm">基础篇</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a>
<div>目录一、引言二、Python分支结构的类型与语法(一)if语句(单分支)(二)if-else语句(双分支)(三)if-elif-else语句(多分支)三、分支结构的应用场景(一)提示用户输入用户名,然后再提示输入密码,如果用户名是“admin”并且密码是“88888”则提示正确,否则,如果用户名不是admin还提示用户用户名不存在,(二)提示用户输入用户名,然后再提示输入密码,如果用户名是“adm</div>
</li>
<li><a href="/article/1943982558555467776.htm"
title="(Python基础篇)循环结构" target="_blank">(Python基础篇)循环结构</a>
<span class="text-muted">EternityArt</span>
<a class="tag" taget="_blank" href="/search/%E5%9F%BA%E7%A1%80%E7%AF%87/1.htm">基础篇</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a>
<div>一、什么是Python循环结构?循环结构是编程中重复执行代码块的机制。在Python中,循环允许你:1.迭代处理数据:遍历列表、字典、文件内容等。2.自动化重复任务:如批量处理数据、生成序列等。3.控制执行流程:根据条件决定是否继续或终止循环。二、为什么需要循环结构?假设你需要打印1到100的所有偶数:没有循环:需手动编写100行print()语句。print(0)print(2)print(4)</div>
</li>
<li><a href="/article/1943982559000064000.htm"
title="(Python基础篇)字典的操作" target="_blank">(Python基础篇)字典的操作</a>
<span class="text-muted">EternityArt</span>
<a class="tag" taget="_blank" href="/search/%E5%9F%BA%E7%A1%80%E7%AF%87/1.htm">基础篇</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>一、引言在Python编程中,字典(Dictionary)是一种极具灵活性的数据结构,它通过“键-值对”(key-valuepair)的形式存储数据,如同现实生活中的字典——通过“词语(键)”快速查找“释义(值)”。相较于列表和元组的有序索引访问,字典的优势在于基于键的快速查找,这使得它在处理需要频繁通过唯一标识获取数据的场景中极为高效。掌握字典的操作,能让我们更高效地组织和管理复杂数据,是Pyt</div>
</li>
<li><a href="/article/1943981927514042368.htm"
title="Python七彩花朵" target="_blank">Python七彩花朵</a>
<span class="text-muted">Want595</span>
<a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a>
<div>系列文章序号直达链接Tkinter1Python李峋同款可写字版跳动的爱心2Python跳动的双爱心3Python蓝色跳动的爱心4Python动漫烟花5Python粒子烟花Turtle1Python满屏飘字2Python蓝色流星雨3Python金色流星雨4Python漂浮爱心5Python爱心光波①6Python爱心光波②7Python满天繁星8Python五彩气球9Python白色飘雪10Pyt</div>
</li>
<li><a href="/article/1943975627472302080.htm"
title="用OpenCV标定相机内参应用示例(C++和Python)" target="_blank">用OpenCV标定相机内参应用示例(C++和Python)</a>
<span class="text-muted"></span>
<div>下面是一个完整的使用OpenCV进行相机内参标定(CameraCalibration)的示例,包括C++和Python两个版本,基于棋盘格图案标定。一、目标:相机标定通过拍摄多张带有棋盘格图案的图像,估计相机的内参:相机矩阵(内参)K畸变系数distCoeffs可选外参(R,T)标定精度指标(如重投影误差)二、棋盘格参数设置(根据自己的棋盘格设置):棋盘格角点数:9x6(内角点,9列×6行);每个</div>
</li>
<li><a href="/article/1943974492640440320.htm"
title="Anaconda 详细下载与安装教程" target="_blank">Anaconda 详细下载与安装教程</a>
<span class="text-muted"></span>
<div>Anaconda详细下载与安装教程1.简介Anaconda是一个用于科学计算的开源发行版,包含了Python和R的众多常用库。它还包括了conda包管理器,可以方便地安装、更新和管理各种软件包。2.下载Anaconda2.1访问官方网站首先,打开浏览器,访问Anaconda官方网站。2.2选择适合的版本在页面中,你会看到两个主要的下载选项:AnacondaIndividualEdition:适用于</div>
</li>
<li><a href="/article/1943972726150590464.htm"
title="Shader面试题100道之(81-100)" target="_blank">Shader面试题100道之(81-100)</a>
<span class="text-muted">还是大剑师兰特</span>
<a class="tag" taget="_blank" href="/search/%23/1.htm">#</a><a class="tag" taget="_blank" href="/search/Shader/1.htm">Shader</a><a class="tag" taget="_blank" href="/search/%E7%BB%BC%E5%90%88%E6%95%99%E7%A8%8B100%2B/1.htm">综合教程100+</a><a class="tag" taget="_blank" href="/search/%E5%A4%A7%E5%89%91%E5%B8%88/1.htm">大剑师</a><a class="tag" taget="_blank" href="/search/shader%E9%9D%A2%E8%AF%95%E9%A2%98/1.htm">shader面试题</a><a class="tag" taget="_blank" href="/search/shader%E6%95%99%E7%A8%8B/1.htm">shader教程</a>
<div>Shader面试题(第81-100题)以下是第81到第100道Shader相关的面试题及答案:81.Unity中如何实现屏幕空间的热扭曲效果(HeatDistortion)?热扭曲效果可以通过GrabPass抓取当前屏幕图像,然后在片段着色器中使用噪声或动态UV偏移模拟空气扰动,再结合一个透明通道控制扭曲强度来实现。82.Shader中如何实现物体轮廓高亮(OutlineHighlight)?轮廓</div>
</li>
<li><a href="/article/1943972473032732672.htm"
title="python中 @注解 及内置注解 的使用方法总结以及完整示例" target="_blank">python中 @注解 及内置注解 的使用方法总结以及完整示例</a>
<span class="text-muted">慧一居士</span>
<a class="tag" taget="_blank" href="/search/Python/1.htm">Python</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a>
<div>在Python中,装饰器(Decorator)使用@符号实现,是一种修改函数/类行为的语法糖。它本质上是一个高阶函数,接受目标函数作为参数并返回包装后的函数。Python也提供了多个内置装饰器,如@property、@staticmethod、@classmethod等。一、核心概念装饰器本质:@decorator等价于func=decorator(func)执行时机:在函数/类定义时立即执行装饰</div>
</li>
<li><a href="/article/1943971717185597440.htm"
title="Python中的静态方法和类方法详解" target="_blank">Python中的静态方法和类方法详解</a>
<span class="text-muted"></span>
<div>在Python中,`@staticmethod`和`@classmethod`是两种装饰器,它们用于定义类中的方法,但是它们的行为和用途有所不同。###@staticmethod`@staticmethod`装饰器用于定义一个静态方法。静态方法不接收类或实例的引用作为第一个参数,因此它不能访问类的状态或实例的状态。静态方法可以看作是与类关联的普通函数,但它们可以通过类名直接调用。classMath</div>
</li>
<li><a href="/article/1943969448046161920.htm"
title="Python中类静态方法:@classmethod/@staticmethod详解和实战示例" target="_blank">Python中类静态方法:@classmethod/@staticmethod详解和实战示例</a>
<span class="text-muted"></span>
<div>在Python中,类方法(@classmethod)和静态方法(@staticmethod)是类作用域下的两种特殊方法。它们使用装饰器定义,并且与实例方法(deffunc(self))的行为有所不同。1.三种方法的对比概览方法类型是否访问实例(self)是否访问类(cls)典型用途实例方法✅是❌否访问对象属性类方法@classmethod❌否✅是创建类的替代构造器,访问类变量等静态方法@stati</div>
</li>
<li><a href="/article/1943968314044772352.htm"
title="Python多版本管理与pip升级全攻略:解决冲突与高效实践" target="_blank">Python多版本管理与pip升级全攻略:解决冲突与高效实践</a>
<span class="text-muted">码界奇点</span>
<a class="tag" taget="_blank" href="/search/Python/1.htm">Python</a><a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/pip/1.htm">pip</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a><a class="tag" taget="_blank" href="/search/python3.11/1.htm">python3.11</a><a class="tag" taget="_blank" href="/search/%E6%BA%90%E4%BB%A3%E7%A0%81%E7%AE%A1%E7%90%86/1.htm">源代码管理</a><a class="tag" taget="_blank" href="/search/%E8%99%9A%E6%8B%9F%E7%8E%B0%E5%AE%9E/1.htm">虚拟现实</a><a class="tag" taget="_blank" href="/search/%E4%BE%9D%E8%B5%96%E5%80%92%E7%BD%AE%E5%8E%9F%E5%88%99/1.htm">依赖倒置原则</a>
<div>引言Python作为最流行的编程语言之一,其版本迭代速度与生态碎片化给开发者带来了巨大挑战。据统计,超过60%的Python开发者需要同时维护基于Python3.6+和Python2.7的项目。本文将系统解决以下核心痛点:如何安全地在同一台机器上管理多个Python版本pip依赖冲突的根治方案符合PEP标准的生产环境最佳实践第一部分:Python多版本管理核心方案1.1系统级多版本共存方案Wind</div>
</li>
<li><a href="/article/1943967555555225600.htm"
title="基于Python的健身数据分析工具的搭建流程day1" target="_blank">基于Python的健身数据分析工具的搭建流程day1</a>
<span class="text-muted">weixin_45677320</span>
<a class="tag" taget="_blank" href="/search/python/1.htm">python</a><a class="tag" taget="_blank" href="/search/%E5%BC%80%E5%8F%91%E8%AF%AD%E8%A8%80/1.htm">开发语言</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E6%8C%96%E6%8E%98/1.htm">数据挖掘</a><a class="tag" taget="_blank" href="/search/%E7%88%AC%E8%99%AB/1.htm">爬虫</a>
<div>基于Python的健身数据分析工具的搭建流程分数据挖掘、数据存储和数据分析三个步骤。本文主要介绍利用Python实现健身数据分析工具的数据挖掘部分。第一步:加载库加载本文需要的库,如下代码所示。若库未安装,请按照python如何安装各种库(保姆级教程)_python安装库-CSDN博客https://blog.csdn.net/aobulaien001/article/details/133298</div>
</li>
<li><a href="/article/1943961378016522240.htm"
title="从《哪吒 2》看个人IP的破局之道|创客匠人" target="_blank">从《哪吒 2》看个人IP的破局之道|创客匠人</a>
<span class="text-muted"></span>
<div>《哪吒2》以破竹之势登顶中国影史票房榜,不到9天票房突破62亿,观众自发为其“冲百亿”的热情,揭示了一个朴素却深刻的商业逻辑:IP的真正生命力,不在于短暂曝光,而在于用户愿意用行动投票的长期信任。这种逻辑,同样适用于2025年个人IP的增长突围。流量失效的真相:用户体验断层终结增长如今的IP运营者常陷入一个误区:疯狂追逐流量,却留不住用户。短视频投流成本翻倍,内容越做越多粉丝却不涨,好不容易成交的</div>
</li>
<li><a href="/article/1943958981944864768.htm"
title="传统检测响应慢?陌讯多模态引擎提速90+FPS实战" target="_blank">传统检测响应慢?陌讯多模态引擎提速90+FPS实战</a>
<span class="text-muted">2501_92473147</span>
<a class="tag" taget="_blank" href="/search/%E7%AE%97%E6%B3%95/1.htm">算法</a><a class="tag" taget="_blank" href="/search/%E8%AE%A1%E7%AE%97%E6%9C%BA%E8%A7%86%E8%A7%89/1.htm">计算机视觉</a><a class="tag" taget="_blank" href="/search/%E7%9B%AE%E6%A0%87%E6%A3%80%E6%B5%8B/1.htm">目标检测</a>
<div>开篇痛点:实时目标检测在安防监控中的核心挑战在安防监控领域,实时目标检测是保障公共安全的关键技术。然而,传统算法如YOLOv5或开源框架MMDetection常面临两大痛点:误报率高(复杂光照或遮挡场景下检测不稳定)和响应延迟(高分辨率视频流处理FPS低于30)。实测数据显示,城市交通监控系统误报率达15%,导致安保资源浪费;客户反馈表明,延迟超100ms时,目标跟踪可能失效。这些问题源于算法泛化</div>
</li>
<li><a href="/article/1943952054795956224.htm"
title="seaborn又一个扩展heatmapz" target="_blank">seaborn又一个扩展heatmapz</a>
<span class="text-muted">qq_21478261</span>
<a class="tag" taget="_blank" href="/search/%23/1.htm">#</a><a class="tag" taget="_blank" href="/search/Python%E5%8F%AF%E8%A7%86%E5%8C%96/1.htm">Python可视化</a><a class="tag" taget="_blank" href="/search/matplotlib/1.htm">matplotlib</a>
<div>推荐阅读:Pythonmatplotlib保姆级教程嫌Matplotlib繁琐?试试Seaborn!</div>
</li>
<li><a href="/article/1943951549751422976.htm"
title="NGS测序基础梳理01-文库构建(Library Preparation)" target="_blank">NGS测序基础梳理01-文库构建(Library Preparation)</a>
<span class="text-muted">qq_21478261</span>
<a class="tag" taget="_blank" href="/search/%23/1.htm">#</a><a class="tag" taget="_blank" href="/search/%E7%94%9F%E7%89%A9%E4%BF%A1%E6%81%AF/1.htm">生物信息</a><a class="tag" taget="_blank" href="/search/%E7%94%9F%E7%89%A9%E5%AD%A6/1.htm">生物学</a>
<div>本文介绍Illumina测序平台文库构建(LibraryPreparation)步骤,文库结构。写作时间:2020.05。推荐阅读:10W字《Python可视化教程1.0》来了!一份由公众号「pythonic生物人」精心制作的PythonMatplotlib可视化系统教程,105页PDFhttps://mp.weixin.qq.com/s/QaSmucuVsS_DR-klfpE3-Q10W字《Rg</div>
</li>
<li><a href="/article/1943951046015512576.htm"
title="Java设计模式实战:高频场景解析与避坑指南" target="_blank">Java设计模式实战:高频场景解析与避坑指南</a>
<span class="text-muted">mckim_</span>
<a class="tag" taget="_blank" href="/search/%E7%AC%94%E8%AE%B0/1.htm">笔记</a><a class="tag" taget="_blank" href="/search/%E5%AD%A6%E4%B9%A0/1.htm">学习</a><a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F/1.htm">设计模式</a>
<div>引言设计模式是软件开发的基石,但许多开发者面对23种模式时容易陷入“学完就忘”或“滥用模式”的困境。本文从工业级项目视角出发,精选10种高频设计模式,结合真实代码案例与主流框架应用,帮你建立模式思维,拒绝纸上谈兵。一、创建型模式:告别new的暴力美学1.工厂方法模式(FactoryMethod)核心痛点:对象创建逻辑散落各处,难以统一管理。场景案例:电商平台需要支持多种支付方式(支付宝、微信、银联</div>
</li>
<li><a href="/article/1943946256237785088.htm"
title="LeetCode Hot 100 回文链表" target="_blank">LeetCode Hot 100 回文链表</a>
<span class="text-muted">源</span>
<a class="tag" taget="_blank" href="/search/leetcode/1.htm">leetcode</a><a class="tag" taget="_blank" href="/search/%E9%93%BE%E8%A1%A8/1.htm">链表</a><a class="tag" taget="_blank" href="/search/%E7%AE%97%E6%B3%95/1.htm">算法</a>
<div>给你一个单链表的头节点head,请你判断该链表是否为回文链表。如果是,返回true;否则,返回false。示例1:输入:head=[1,2,2,1]输出:true示例2:输入:head=[1,2]输出:false提示:链表中节点数目在范围[1,105]内0vals;while(head!=nullptr){vals.emplace_back(head->val);head=head->next;}</div>
</li>
<li><a href="/article/1943943987777826816.htm"
title="自动化运维工程师面试题解析【真题】" target="_blank">自动化运维工程师面试题解析【真题】</a>
<span class="text-muted"></span>
<div>ZabbixAgent默认监听的端口是A.10050。以下是关键分析:选项排除:C.80是HTTP默认端口,与ZabbixAgent无关。D.5432是PostgreSQL数据库的默认端口,不涉及ZabbixAgent。B.10051是ZabbixServer的默认监听端口,用于接收Agent发送的数据,而非Agent自身的监听端口。ZabbixAgent的配置:根据官方文档,ZabbixAgen</div>
</li>
<li><a href="/article/1943943735205228544.htm"
title="Python 常用内置函数详解(七):dir()函数——获取当前本地作用域中的名称列表或对象的有效属性列表" target="_blank">Python 常用内置函数详解(七):dir()函数——获取当前本地作用域中的名称列表或对象的有效属性列表</a>
<span class="text-muted"></span>
<div>目录一、功能二、语法和示例一、功能dir()函数获取当前本地作用域中的名称列表或对象的有效属性列表。二、语法和示例dir()函数有两种形式,如果没有实参,则返回当前本地作用域中的名称列表。如果有实参,它会尝试返回该对象的有效属性列表。如果对象有一个名为__dir__()的方法,那么该方法将被调用,并且必须返回一个属性列表。dir()函数的语法格式如下:C:\Users\amoxiang>ipyth</div>
</li>
<li><a href="/article/1943941718281875456.htm"
title="pythonjson中list操作_Python json.dumps 特殊数据类型的自定义序列化操作" target="_blank">pythonjson中list操作_Python json.dumps 特殊数据类型的自定义序列化操作</a>
<span class="text-muted"></span>
<div>场景描述:Python标准库中的json模块,集成了将数据序列化处理的功能;在使用json.dumps()方法序列化数据时候,如果目标数据中存在datetime数据类型,执行操作时,会抛出异常:TypeError:datetime.datetime(2016,12,10,11,04,21)isnotJSONserializable那么遇到json.dumps序列化不支持的数据类型,该怎么办!首先,</div>
</li>
<li><a href="/article/82.htm"
title="java类加载顺序" target="_blank">java类加载顺序</a>
<span class="text-muted">3213213333332132</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a>
<div>package com.demo;
/**
* @Description 类加载顺序
* @author FuJianyong
* 2015-2-6上午11:21:37
*/
public class ClassLoaderSequence {
String s1 = "成员属性";
static String s2 = "</div>
</li>
<li><a href="/article/209.htm"
title="Hibernate与mybitas的比较" target="_blank">Hibernate与mybitas的比较</a>
<span class="text-muted">BlueSkator</span>
<a class="tag" taget="_blank" href="/search/sql/1.htm">sql</a><a class="tag" taget="_blank" href="/search/Hibernate/1.htm">Hibernate</a><a class="tag" taget="_blank" href="/search/%E6%A1%86%E6%9E%B6/1.htm">框架</a><a class="tag" taget="_blank" href="/search/ibatis/1.htm">ibatis</a><a class="tag" taget="_blank" href="/search/orm/1.htm">orm</a>
<div>第一章 Hibernate与MyBatis
Hibernate 是当前最流行的O/R mapping框架,它出身于sf.net,现在已经成为Jboss的一部分。 Mybatis 是另外一种优秀的O/R mapping框架。目前属于apache的一个子项目。
MyBatis 参考资料官网:http:</div>
</li>
<li><a href="/article/336.htm"
title="php多维数组排序以及实际工作中的应用" target="_blank">php多维数组排序以及实际工作中的应用</a>
<span class="text-muted">dcj3sjt126com</span>
<a class="tag" taget="_blank" href="/search/PHP/1.htm">PHP</a><a class="tag" taget="_blank" href="/search/usort/1.htm">usort</a><a class="tag" taget="_blank" href="/search/uasort/1.htm">uasort</a>
<div>自定义排序函数返回false或负数意味着第一个参数应该排在第二个参数的前面, 正数或true反之, 0相等usort不保存键名uasort 键名会保存下来uksort 排序是对键名进行的
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8&q</div>
</li>
<li><a href="/article/463.htm"
title="DOM改变字体大小" target="_blank">DOM改变字体大小</a>
<span class="text-muted">周华华</span>
<a class="tag" taget="_blank" href="/search/%E5%89%8D%E7%AB%AF/1.htm">前端</a>
<div><!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml&q</div>
</li>
<li><a href="/article/590.htm"
title="c3p0的配置" target="_blank">c3p0的配置</a>
<span class="text-muted">g21121</span>
<a class="tag" taget="_blank" href="/search/c3p0/1.htm">c3p0</a>
<div>c3p0是一个开源的JDBC连接池,它实现了数据源和JNDI绑定,支持JDBC3规范和JDBC2的标准扩展。c3p0的下载地址是:http://sourceforge.net/projects/c3p0/这里可以下载到c3p0最新版本。
以在spring中配置dataSource为例:
<!-- spring加载资源文件 -->
<bean name="prope</div>
</li>
<li><a href="/article/717.htm"
title="Java获取工程路径的几种方法" target="_blank">Java获取工程路径的几种方法</a>
<span class="text-muted">510888780</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a>
<div>第一种:
File f = new File(this.getClass().getResource("/").getPath());
System.out.println(f);
结果:
C:\Documents%20and%20Settings\Administrator\workspace\projectName\bin
获取当前类的所在工程路径;
如果不加“</div>
</li>
<li><a href="/article/844.htm"
title="在类Unix系统下实现SSH免密码登录服务器" target="_blank">在类Unix系统下实现SSH免密码登录服务器</a>
<span class="text-muted">Harry642</span>
<a class="tag" taget="_blank" href="/search/%E5%85%8D%E5%AF%86/1.htm">免密</a><a class="tag" taget="_blank" href="/search/ssh/1.htm">ssh</a>
<div>1.客户机
(1)执行ssh-keygen -t rsa -C "xxxxx@xxxxx.com"生成公钥,xxx为自定义大email地址
(2)执行scp ~/.ssh/id_rsa.pub root@xxxxxxxxx:/tmp将公钥拷贝到服务器上,xxx为服务器地址
(3)执行cat</div>
</li>
<li><a href="/article/971.htm"
title="Java新手入门的30个基本概念一" target="_blank">Java新手入门的30个基本概念一</a>
<span class="text-muted">aijuans</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/java+%E5%85%A5%E9%97%A8/1.htm">java 入门</a><a class="tag" taget="_blank" href="/search/%E6%96%B0%E6%89%8B/1.htm">新手</a>
<div>在我们学习Java的过程中,掌握其中的基本概念对我们的学习无论是J2SE,J2EE,J2ME都是很重要的,J2SE是Java的基础,所以有必要对其中的基本概念做以归纳,以便大家在以后的学习过程中更好的理解java的精髓,在此我总结了30条基本的概念。 Java概述: 目前Java主要应用于中间件的开发(middleware)---处理客户机于服务器之间的通信技术,早期的实践证明,Java不适合</div>
</li>
<li><a href="/article/1098.htm"
title="Memcached for windows 简单介绍" target="_blank">Memcached for windows 简单介绍</a>
<span class="text-muted">antlove</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/Web/1.htm">Web</a><a class="tag" taget="_blank" href="/search/windows/1.htm">windows</a><a class="tag" taget="_blank" href="/search/cache/1.htm">cache</a><a class="tag" taget="_blank" href="/search/memcached/1.htm">memcached</a>
<div>1. 安装memcached server
a. 下载memcached-1.2.6-win32-bin.zip
b. 解压缩,dos 窗口切换到 memcached.exe所在目录,运行memcached.exe -d install
c.启动memcached Server,直接在dos窗口键入 net start "memcached Server&quo</div>
</li>
<li><a href="/article/1225.htm"
title="数据库对象的视图和索引" target="_blank">数据库对象的视图和索引</a>
<span class="text-muted">百合不是茶</span>
<a class="tag" taget="_blank" href="/search/%E7%B4%A2%E5%BC%95/1.htm">索引</a><a class="tag" taget="_blank" href="/search/oeacle%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">oeacle数据库</a><a class="tag" taget="_blank" href="/search/%E8%A7%86%E5%9B%BE/1.htm">视图</a>
<div>
视图
视图是从一个表或视图导出的表,也可以是从多个表或视图导出的表。视图是一个虚表,数据库不对视图所对应的数据进行实际存储,只存储视图的定义,对视图的数据进行操作时,只能将字段定义为视图,不能将具体的数据定义为视图
为什么oracle需要视图;
&</div>
</li>
<li><a href="/article/1352.htm"
title="Mockito(一) --入门篇" target="_blank">Mockito(一) --入门篇</a>
<span class="text-muted">bijian1013</span>
<a class="tag" taget="_blank" href="/search/%E6%8C%81%E7%BB%AD%E9%9B%86%E6%88%90/1.htm">持续集成</a><a class="tag" taget="_blank" href="/search/mockito/1.htm">mockito</a><a class="tag" taget="_blank" href="/search/%E5%8D%95%E5%85%83%E6%B5%8B%E8%AF%95/1.htm">单元测试</a>
<div> Mockito是一个针对Java的mocking框架,它与EasyMock和jMock很相似,但是通过在执行后校验什么已经被调用,它消除了对期望 行为(expectations)的需要。其它的mocking库需要你在执行前记录期望行为(expectations),而这导致了丑陋的初始化代码。
&nb</div>
</li>
<li><a href="/article/1479.htm"
title="精通Oracle10编程SQL(5)SQL函数" target="_blank">精通Oracle10编程SQL(5)SQL函数</a>
<span class="text-muted">bijian1013</span>
<a class="tag" taget="_blank" href="/search/oracle/1.htm">oracle</a><a class="tag" taget="_blank" href="/search/%E6%95%B0%E6%8D%AE%E5%BA%93/1.htm">数据库</a><a class="tag" taget="_blank" href="/search/plsql/1.htm">plsql</a>
<div>/*
* SQL函数
*/
--数字函数
--ABS(n):返回数字n的绝对值
declare
v_abs number(6,2);
begin
v_abs:=abs(&no);
dbms_output.put_line('绝对值:'||v_abs);
end;
--ACOS(n):返回数字n的反余弦值,输入值的范围是-1~1,输出值的单位为弧度</div>
</li>
<li><a href="/article/1606.htm"
title="【Log4j一】Log4j总体介绍" target="_blank">【Log4j一】Log4j总体介绍</a>
<span class="text-muted">bit1129</span>
<a class="tag" taget="_blank" href="/search/log4j/1.htm">log4j</a>
<div>Log4j组件:Logger、Appender、Layout
Log4j核心包含三个组件:logger、appender和layout。这三个组件协作提供日志功能:
日志的输出目标
日志的输出格式
日志的输出级别(是否抑制日志的输出)
logger继承特性
A logger is said to be an ancestor of anothe</div>
</li>
<li><a href="/article/1733.htm"
title="Java IO笔记" target="_blank">Java IO笔记</a>
<span class="text-muted">白糖_</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a>
<div> public static void main(String[] args) throws IOException {
//输入流
InputStream in = Test.class.getResourceAsStream("/test");
InputStreamReader isr = new InputStreamReader(in);
Bu</div>
</li>
<li><a href="/article/1860.htm"
title="Docker 监控" target="_blank">Docker 监控</a>
<span class="text-muted">ronin47</span>
<a class="tag" taget="_blank" href="/search/docker%E7%9B%91%E6%8E%A7/1.htm">docker监控</a>
<div>
目前项目内部署了docker,于是涉及到关于监控的事情,参考一些经典实例以及一些自己的想法,总结一下思路。 1、关于监控的内容 监控宿主机本身
监控宿主机本身还是比较简单的,同其他服务器监控类似,对cpu、network、io、disk等做通用的检查,这里不再细说。
额外的,因为是docker的</div>
</li>
<li><a href="/article/1987.htm"
title="java-顺时针打印图形" target="_blank">java-顺时针打印图形</a>
<span class="text-muted">bylijinnan</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a>
<div>一个画图程序 要求打印出:
1.int i=5;
2.1 2 3 4 5
3.16 17 18 19 6
4.15 24 25 20 7
5.14 23 22 21 8
6.13 12 11 10 9
7.
8.int i=6
9.1 2 3 4 5 6
10.20 21 22 23 24 7
11.19</div>
</li>
<li><a href="/article/2114.htm"
title="关于iReport汉化版强制使用英文的配置方法" target="_blank">关于iReport汉化版强制使用英文的配置方法</a>
<span class="text-muted">Kai_Ge</span>
<a class="tag" taget="_blank" href="/search/iReport%E6%B1%89%E5%8C%96/1.htm">iReport汉化</a><a class="tag" taget="_blank" href="/search/%E8%8B%B1%E6%96%87%E7%89%88/1.htm">英文版</a>
<div>对于那些具有强迫症的工程师来说,软件汉化固然好用,但是汉化不完整却极为头疼,本方法针对iReport汉化不完整的情况,强制使用英文版,方法如下:
在 iReport 安装路径下的 etc/ireport.conf 里增加红色部分启动参数,即可变为英文版。
# ${HOME} will be replaced by user home directory accordin</div>
</li>
<li><a href="/article/2241.htm"
title="[并行计算]论宇宙的可计算性" target="_blank">[并行计算]论宇宙的可计算性</a>
<span class="text-muted">comsci</span>
<a class="tag" taget="_blank" href="/search/%E5%B9%B6%E8%A1%8C%E8%AE%A1%E7%AE%97/1.htm">并行计算</a>
<div>
现在我们知道,一个涡旋系统具有并行计算能力.按照自然运动理论,这个系统也同时具有存储能力,同时具备计算和存储能力的系统,在某种条件下一般都会产生意识......
那么,这种概念让我们推论出一个结论
&nb</div>
</li>
<li><a href="/article/2368.htm"
title="用OpenGL实现无限循环的coverflow" target="_blank">用OpenGL实现无限循环的coverflow</a>
<span class="text-muted">dai_lm</span>
<a class="tag" taget="_blank" href="/search/android/1.htm">android</a><a class="tag" taget="_blank" href="/search/coverflow/1.htm">coverflow</a>
<div>网上找了很久,都是用Gallery实现的,效果不是很满意,结果发现这个用OpenGL实现的,稍微修改了一下源码,实现了无限循环功能
源码地址:
https://github.com/jackfengji/glcoverflow
public class CoverFlowOpenGL extends GLSurfaceView implements
GLSurfaceV</div>
</li>
<li><a href="/article/2495.htm"
title="JAVA数据计算的几个解决方案1" target="_blank">JAVA数据计算的几个解决方案1</a>
<span class="text-muted">datamachine</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/Hibernate/1.htm">Hibernate</a><a class="tag" taget="_blank" href="/search/%E8%AE%A1%E7%AE%97/1.htm">计算</a>
<div>老大丢过来的软件跑了10天,摸到点门道,正好跟以前攒的私房有关联,整理存档。
-----------------------------华丽的分割线-------------------------------------
数据计算层是指介于数据存储和应用程序之间,负责计算数据存储层的数据,并将计算结果返回应用程序的层次。J
&nbs</div>
</li>
<li><a href="/article/2622.htm"
title="简单的用户授权系统,利用给user表添加一个字段标识管理员的方式" target="_blank">简单的用户授权系统,利用给user表添加一个字段标识管理员的方式</a>
<span class="text-muted">dcj3sjt126com</span>
<a class="tag" taget="_blank" href="/search/yii/1.htm">yii</a>
<div>怎么创建一个简单的(非 RBAC)用户授权系统
通过查看论坛,我发现这是一个常见的问题,所以我决定写这篇文章。
本文只包括授权系统.假设你已经知道怎么创建身份验证系统(登录)。 数据库
首先在 user 表创建一个新的字段(integer 类型),字段名 'accessLevel',它定义了用户的访问权限 扩展 CWebUser 类
在配置文件(一般为 protecte</div>
</li>
<li><a href="/article/2749.htm"
title="未选之路" target="_blank">未选之路</a>
<span class="text-muted">dcj3sjt126com</span>
<a class="tag" taget="_blank" href="/search/%E8%AF%97/1.htm">诗</a>
<div>作者:罗伯特*费罗斯特
黄色的树林里分出两条路,
可惜我不能同时去涉足,
我在那路口久久伫立,
我向着一条路极目望去,
直到它消失在丛林深处.
但我却选了另外一条路,
它荒草萋萋,十分幽寂;
显得更诱人,更美丽,
虽然在这两条小路上,
都很少留下旅人的足迹.
那天清晨落叶满地,
两条路都未见脚印痕迹.
呵,留下一条路等改日再</div>
</li>
<li><a href="/article/2876.htm"
title="Java处理15位身份证变18位" target="_blank">Java处理15位身份证变18位</a>
<span class="text-muted">蕃薯耀</span>
<a class="tag" taget="_blank" href="/search/18%E4%BD%8D%E8%BA%AB%E4%BB%BD%E8%AF%81%E5%8F%9815%E4%BD%8D/1.htm">18位身份证变15位</a><a class="tag" taget="_blank" href="/search/15%E4%BD%8D%E8%BA%AB%E4%BB%BD%E8%AF%81%E5%8F%9818%E4%BD%8D/1.htm">15位身份证变18位</a><a class="tag" taget="_blank" href="/search/%E8%BA%AB%E4%BB%BD%E8%AF%81%E8%BD%AC%E6%8D%A2/1.htm">身份证转换</a>
<div>
15位身份证变18位,18位身份证变15位
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
蕃薯耀 201</div>
</li>
<li><a href="/article/3003.htm"
title="SpringMVC4零配置--应用上下文配置【AppConfig】" target="_blank">SpringMVC4零配置--应用上下文配置【AppConfig】</a>
<span class="text-muted">hanqunfeng</span>
<a class="tag" taget="_blank" href="/search/springmvc4/1.htm">springmvc4</a>
<div>从spring3.0开始,Spring将JavaConfig整合到核心模块,普通的POJO只需要标注@Configuration注解,就可以成为spring配置类,并通过在方法上标注@Bean注解的方式注入bean。
Xml配置和Java类配置对比如下:
applicationContext-AppConfig.xml
<!-- 激活自动代理功能 参看:</div>
</li>
<li><a href="/article/3130.htm"
title="Android中webview跟JAVASCRIPT中的交互" target="_blank">Android中webview跟JAVASCRIPT中的交互</a>
<span class="text-muted">jackyrong</span>
<a class="tag" taget="_blank" href="/search/JavaScript/1.htm">JavaScript</a><a class="tag" taget="_blank" href="/search/html/1.htm">html</a><a class="tag" taget="_blank" href="/search/android/1.htm">android</a><a class="tag" taget="_blank" href="/search/%E8%84%9A%E6%9C%AC/1.htm">脚本</a>
<div> 在android的应用程序中,可以直接调用webview中的javascript代码,而webview中的javascript代码,也可以去调用ANDROID应用程序(也就是JAVA部分的代码).下面举例说明之:
1 JAVASCRIPT脚本调用android程序
要在webview中,调用addJavascriptInterface(OBJ,int</div>
</li>
<li><a href="/article/3257.htm"
title="8个最佳Web开发资源推荐" target="_blank">8个最佳Web开发资源推荐</a>
<span class="text-muted">lampcy</span>
<a class="tag" taget="_blank" href="/search/%E7%BC%96%E7%A8%8B/1.htm">编程</a><a class="tag" taget="_blank" href="/search/Web/1.htm">Web</a><a class="tag" taget="_blank" href="/search/%E7%A8%8B%E5%BA%8F%E5%91%98/1.htm">程序员</a>
<div>Web开发对程序员来说是一项较为复杂的工作,程序员需要快速地满足用户需求。如今很多的在线资源可以给程序员提供帮助,比如指导手册、在线课程和一些参考资料,而且这些资源基本都是免费和适合初学者的。无论你是需要选择一门新的编程语言,或是了解最新的标准,还是需要从其他地方找到一些灵感,我们这里为你整理了一些很好的Web开发资源,帮助你更成功地进行Web开发。
这里列出10个最佳Web开发资源,它们都是受</div>
</li>
<li><a href="/article/3384.htm"
title="架构师之面试------jdk的hashMap实现" target="_blank">架构师之面试------jdk的hashMap实现</a>
<span class="text-muted">nannan408</span>
<a class="tag" taget="_blank" href="/search/HashMap/1.htm">HashMap</a>
<div>1.前言。
如题。
2.详述。
(1)hashMap算法就是数组链表。数组存放的元素是键值对。jdk通过移位算法(其实也就是简单的加乘算法),如下代码来生成数组下标(生成后indexFor一下就成下标了)。
static int hash(int h)
{
h ^= (h >>> 20) ^ (h >>></div>
</li>
<li><a href="/article/3511.htm"
title="html禁止清除input文本输入缓存" target="_blank">html禁止清除input文本输入缓存</a>
<span class="text-muted">Rainbow702</span>
<a class="tag" taget="_blank" href="/search/html/1.htm">html</a><a class="tag" taget="_blank" href="/search/%E7%BC%93%E5%AD%98/1.htm">缓存</a><a class="tag" taget="_blank" href="/search/input/1.htm">input</a><a class="tag" taget="_blank" href="/search/%E8%BE%93%E5%85%A5%E6%A1%86/1.htm">输入框</a><a class="tag" taget="_blank" href="/search/change/1.htm">change</a>
<div>多数浏览器默认会缓存input的值,只有使用ctl+F5强制刷新的才可以清除缓存记录。
如果不想让浏览器缓存input的值,有2种方法:
方法一: 在不想使用缓存的input中添加 autocomplete="off";
<input type="text" autocomplete="off" n</div>
</li>
<li><a href="/article/3638.htm"
title="POJO和JavaBean的区别和联系" target="_blank">POJO和JavaBean的区别和联系</a>
<span class="text-muted">tjmljw</span>
<a class="tag" taget="_blank" href="/search/POJO/1.htm">POJO</a><a class="tag" taget="_blank" href="/search/java+beans/1.htm">java beans</a>
<div>POJO 和JavaBean是我们常见的两个关键字,一般容易混淆,POJO全称是Plain Ordinary Java Object / Pure Old Java Object,中文可以翻译成:普通Java类,具有一部分getter/setter方法的那种类就可以称作POJO,但是JavaBean则比 POJO复杂很多, Java Bean 是可复用的组件,对 Java Bean 并没有严格的规</div>
</li>
<li><a href="/article/3765.htm"
title="java中单例的五种写法" target="_blank">java中单例的五种写法</a>
<span class="text-muted">liuxiaoling</span>
<a class="tag" taget="_blank" href="/search/java/1.htm">java</a><a class="tag" taget="_blank" href="/search/%E5%8D%95%E4%BE%8B/1.htm">单例</a>
<div>/**
* 单例模式的五种写法:
* 1、懒汉
* 2、恶汉
* 3、静态内部类
* 4、枚举
* 5、双重校验锁
*/
/**
* 五、 双重校验锁,在当前的内存模型中无效
*/
class LockSingleton
{
private volatile static LockSingleton singleton;
pri</div>
</li>
</ul>
</div>
</div>
</div>
<div>
<div class="container">
<div class="indexes">
<strong>按字母分类:</strong>
<a href="/tags/A/1.htm" target="_blank">A</a><a href="/tags/B/1.htm" target="_blank">B</a><a href="/tags/C/1.htm" target="_blank">C</a><a
href="/tags/D/1.htm" target="_blank">D</a><a href="/tags/E/1.htm" target="_blank">E</a><a href="/tags/F/1.htm" target="_blank">F</a><a
href="/tags/G/1.htm" target="_blank">G</a><a href="/tags/H/1.htm" target="_blank">H</a><a href="/tags/I/1.htm" target="_blank">I</a><a
href="/tags/J/1.htm" target="_blank">J</a><a href="/tags/K/1.htm" target="_blank">K</a><a href="/tags/L/1.htm" target="_blank">L</a><a
href="/tags/M/1.htm" target="_blank">M</a><a href="/tags/N/1.htm" target="_blank">N</a><a href="/tags/O/1.htm" target="_blank">O</a><a
href="/tags/P/1.htm" target="_blank">P</a><a href="/tags/Q/1.htm" target="_blank">Q</a><a href="/tags/R/1.htm" target="_blank">R</a><a
href="/tags/S/1.htm" target="_blank">S</a><a href="/tags/T/1.htm" target="_blank">T</a><a href="/tags/U/1.htm" target="_blank">U</a><a
href="/tags/V/1.htm" target="_blank">V</a><a href="/tags/W/1.htm" target="_blank">W</a><a href="/tags/X/1.htm" target="_blank">X</a><a
href="/tags/Y/1.htm" target="_blank">Y</a><a href="/tags/Z/1.htm" target="_blank">Z</a><a href="/tags/0/1.htm" target="_blank">其他</a>
</div>
</div>
</div>
<footer id="footer" class="mb30 mt30">
<div class="container">
<div class="footBglm">
<a target="_blank" href="/">首页</a> -
<a target="_blank" href="/custom/about.htm">关于我们</a> -
<a target="_blank" href="/search/Java/1.htm">站内搜索</a> -
<a target="_blank" href="/sitemap.txt">Sitemap</a> -
<a target="_blank" href="/custom/delete.htm">侵权投诉</a>
</div>
<div class="copyright">版权所有 IT知识库 CopyRight © 2000-2050 E-COM-NET.COM , All Rights Reserved.
<!-- <a href="https://beian.miit.gov.cn/" rel="nofollow" target="_blank">京ICP备09083238号</a><br>-->
</div>
</div>
</footer>
<!-- 代码高亮 -->
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shCore.js"></script>
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shLegacy.js"></script>
<script type="text/javascript" src="/static/syntaxhighlighter/scripts/shAutoloader.js"></script>
<link type="text/css" rel="stylesheet" href="/static/syntaxhighlighter/styles/shCoreDefault.css"/>
<script type="text/javascript" src="/static/syntaxhighlighter/src/my_start_1.js"></script>
</body>
</html>