当雨课堂遇上了python自动化,奇怪的生产力出现了
前言
因为需要完成刷雨课堂网课的课程,于是便想借着这个机会来继续学习下自动化。曾经在油猴脚本中看到过雨课堂的刷课与答题脚本,虽然已经失效了,但是想着可以在这个基础上进行编写,毕竟油猴脚本更加的通用方便,可试验了很久却依然无法完成,js无法真正聚焦到html节点产生控制效果,无可奈何下,只能掏出python大法了。
通过该自动化脚本可以完成雨课堂自动刷课,答题,讨论等功能。当然,该答题并不是说可以全网自动寻找答案完成答题(暂时没有做到如此复杂,且题库难寻),而是可以在有题库答案的清空下,代替人力完成答题操作。(所以你得先拥有题库答案哦~,也许你会觉得很鸡肋,但是如果你需要完成几十个同样的答题时,不就效率来了?这不就是自动化的初衷嘛)。
因此,该自动化工具可以帮助大家学习一下自动化的小实践,期待着能够自动寻题答题的小伙伴就别抱希望啦,还是要好好自己答题~
脚本环境
'''
python3.7
依赖包:selenium
'''
正文
模拟登录
由于雨课堂的网页版登录需要微信扫码登录,如果是首次登录,所以可以设置等待时间,留给用户进行扫码登录,然后保存下用户登陆成功后的cookies信息,下次登录时直接导入cookies便可以模拟登录。
ifFirst = input("是否是第一次登录:")
if ifFirst == '1':
ls.settings['first_login'] = True
else:
ls.settings['first_login'] = False
driver = webdriver.Chrome()
driver.maximize_window()# 最大化窗口
#模拟登录
home_url="https://****.yuketang.cn/pro/portal/home/" #填上自己学校的雨课堂网址
driver.get(home_url)
driver.delete_all_cookies()
if ls.settings['first_login']:
time.sleep(10)
with open('cookies.txt','w') as cookief:
cookief.write(json.dumps(driver.get_cookies()))
else:
with open('cookies.txt','r') as cookief:
#使用json读取cookies 注意读取的是文件 所以用load而不是loads
cookieslist = json.load(cookief)
# 方法1 将expiry类型变为int
for cookie in cookieslist:
#并不是所有cookie都含有expiry 所以要用dict的get方法来获取
if isinstance(cookie.get('expiry'), float):
cookie['expiry'] = int(cookie['expiry'])
driver.add_cookie(cookie)
课程类型分析
![]()
雨课堂的课件url很有规律,一般都会在图片上所示区域标注出该章节的文件类型(视频/答题等),所以可以根据url分析出课件的类型,再做后续操作。
#返回课程类型
'''
0: 视频
1: 讨论
2:习题
3: 课件
'''
def lessonType(url):
if "video" in url:
return 0
elif "homework" in url:
return 2
elif "forum" in url:
return 1
elif "graph" in url:
return 3
判断课件完成情况
因为脚本不一定可以一次完成刷课,那么第二次打开脚本再重头开始刷就太鸡肋了,所以一定要在最开始就寻找到还没有完成的课件加入list,进行刷课。
雨课堂在已经完成的课件后都会加上“已读”等信息,如果还没完成便没有任何信息,这便是我们判断课件完成情况的突破点!

#课件完成进度(是否完成
def finishCondition(driver,lesson):
section_url = lessons[lesson]
driver.get(section_url)
section = wait_wd(driver,20,0.5).until(ec.presence_of_element_located((By.CLASS_NAME,'section-fr')))
time.sleep(10)
infos = section.find_elements(*(By.CLASS_NAME, 'el-tooltip'))
condition = []
for info in infos:
t = info.text
if t=='已读' or t=='已完成' or t=='已发言' or t=='缺勤':
condition.append(1)
else:
condition.append(0)
return condition
视频播放
通过脚本实现自动播放视频,视频播放完结后切换到下一课件。
目前的遗憾是二倍速无法开启(希望有小伙伴可以加以改进
判断视频是否播放结束
#查看播放进度,如果播放完成返回True
def getVideoFinish(driver):
time.sleep(2)
cur_videotime = driver.find_element_by_xpath('//*[@id="video-box"]/div/xt-wrap/xt-controls/xt-inner/xt-time/span[1]').text
videotime = driver.find_element_by_xpath('//*[@id="video-box"]/div/xt-wrap/xt-controls/xt-inner/xt-time/span[2]').text
print("curtime:{},videotime:{}".format(cur_videotime,videotime))
if cur_videotime=="" or videotime=="" or cur_videotime!=videotime:
return False
print("播放完毕")
return True
播放课件视频
#播放视频
def videoPlay(driver,url):
print(url)
driver.get(url)
videoBtn = wait_wd(driver,30,0.5).until(ec.presence_of_element_located((By.XPATH,'//*[@id="video-box"]/div/xt-wrap/xt-controls/xt-inner/xt-playbutton')))
volumeBtn = driver.find_element_by_xpath('//*[@id="video-box"]/div/xt-wrap/xt-controls/xt-inner/xt-volumebutton')
videoBtn_text = driver.find_element_by_xpath('//*[@id="video-box"]/div/xt-wrap/xt-controls/xt-inner/xt-playbutton/xt-tip').text
volumeBtn.click()
videoBtn.click()
while not getVideoFinish():
time.sleep(10)
答题
首先需要将题库答案存放于一个txt文件中,其中每道题之间用一个空格作为间隔。
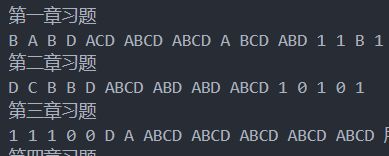
接下来就是标准的答题过程啦~
#答题
def answer(driver,url,lesson):
print(url)
driver.get(url)
driver.implicitly_wait(30)
question_list = driver.find_element_by_xpath('//*[@id="app"]/div[2]/div[2]/div[3]/div/div/div[2]/div/div[1]/div/div[2]/div[1]/div/div/div/ul')
question_btn = question_list.find_elements(*(By.TAG_NAME, 'li'))
title = driver.find_element_by_xpath('//*[@id="app"]/div[2]/div[2]/div[3]/div/div/div[1]/div/div[2]/span').text
cur_answer = []
answer_list = answer_dict[lesson]
for ans in answer_list:
if ans[0] == title:
cur_answer = ans
break
for i,qbtn in enumerate(question_btn):
qbtn.click()
question_type = driver.find_element_by_xpath('//*[@id="app"]/div[2]/div[2]/div[3]/div/div/div[2]/div/div[2]/div[1]/div[1]/div/div/div[1]').text
if "多选题" in question_type or "单选题" in question_type or "判断题" in question_type:
answer_section = driver.find_element_by_xpath('//*[@id="app"]/div[2]/div[2]/div[3]/div/div/div[2]/div/div[2]/div[1]/div[1]/div/div/div[2]/div/ul')
answer = answer_section.find_elements(*(By.TAG_NAME, 'li'))
if "主观题" in question_type:
#切换至iframe
driver.switch_to.frame("ueditor_0")
content = cur_answer[i+1]
driver.execute_script("document.getElementsByClassName('view')[1].innerText ="+"'"+content+"'")
driver.switch_to.default_content()
time.sleep(10)
if "单选题" in question_type or "多选题" in question_type:
if (i+1) < len(cur_answer):
if 'A' in cur_answer[i+1]:
answer[0].click()
if 'B' in cur_answer[i+1]:
answer[1].click()
if 'C' in cur_answer[i+1]:
answer[2].click()
if 'D' in cur_answer[i+1]:
answer[3].click()
if 'E' in cur_answer[i+1]:
answer[4].click()
if "判断题" in question_type:
if (i+1) < len(cur_answer):
if '1' == cur_answer[i+1]:
answer[0].click()
if '0' == cur_answer[i+1]:
answer[1].click()
if "填空题" in question_type:
tk_ans = cur_answer[i+1].split(',')
tk_section = driver.find_element_by_xpath('//*[@id="app"]/div[2]/div[2]/div[3]/div/div/div[2]/div/div[2]/div[1]/div[1]/div/div/div[2]/div')
tk = tk_section.find_elements(*(By.TAG_NAME, 'input'))
for k in range(len(tk_ans)):
tk[k].send_keys(tk_ans[k])
answer_btn = driver.find_element_by_xpath('//*[@id="app"]/div[2]/div[2]/div[3]/div/div/div[2]/div/div[2]/div[2]/div/div[2]/div/ul/li/span/button/span')
answer_btn.click()
time.sleep(5)
讨论
讨论其实就是将某一个同学的讨论复制粘贴一下提交。(所以记得确保有同学已经讨论过了哦~)
#讨论
def talk(driver,url):
driver.get(url)
time.sleep(3)
talk_content = driver.find_element_by_xpath('//*[@id="new_discuss"]/div/div').find_elements(*(By.TAG_NAME, 'dl'))[2].find_element_by_class_name('cont_detail').text
talk_input = driver.find_element_by_xpath('//*[@id="publish"]/div/div[1]/textarea')
talk_input.send_keys(talk_content)
time.sleep(2)
talk_input_sender = driver.find_element_by_xpath('//*[@id="publish"]/div/div[3]/button/span')
talk_input_sender.click()
time.sleep(2)
优化
脚本写的过于匆忙,还有很多值得优化的地方。
比如现在无法二倍速播放,只能开单标签页刷课等。
希望小伙伴们继续改进啦~
源码获取
我将代码放到我的github仓库啦,希望大家多给点下star~这也是我更新的动力!
下载地址:雨课堂自动化脚本
记得给我文章点赞!点赞!点赞!
记得给我仓库star!star!star!
跪求了。
其他
如果你希望我代写一些自动化脚本,欢迎私信我。