Prometheus核心概念:一图了解瞬时向量Instant vector和区间向量Range vector的区别
1 背景
我们在查询Prometheus的时候,通常有两种方式,一种是查瞬时的Metric采样数据,一种是查一段时间范围内的Metric采样数据。
如果对这两种查询方式理解不到位,结果往往是对PromQL的一些内置函数的使用是错误的,或者查询的结果并不是自己预期的那样。
那都是查Metric采样数据,查询瞬时和查询一段时间范围内这两种方式有什么区别呢?
2 图解Metric和采样
 Prometheus和Exporter的关系
Prometheus和Exporter的关系
在上一篇文章Prometheus源码分析:基于Go Client自定义的Exporter,是如何在Local存储Metrics的?中,我们介绍了Exporter是如何在Local存储Metric的。
本质是将Metric放在本地的Map中,然后等待Prometheus服务端来周期性地Pull。
3 从Prometheus服务端的视角来看Metric采样
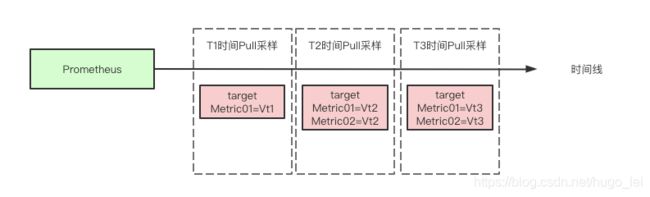 Prometheus对target的Metric进行采样
Prometheus对target的Metric进行采样
Prometheus会周期性的对Exporter的target进行PULL。
例如:在时间T1,Prometheus访问target,采样到的Metric信息是:Metric01=Vt1
例如:在时间T2,Prometheus访问target,采样到的Metric信息是:Metric01=Vt2 Metric02=Vt2
上述示例说明,Metric01在T1时刻的值是Vt1,在T2时刻的值是Vt2。
4 何为瞬时向量Instant Vector?
例如在上图中,我们查询最新的Metric信息,则会返回T3时刻的采样数据(假设T3时刻是距离服务器当前时间最近的采样时刻),包括Metric01=Vt3 Metric02=Vt3
这里的瞬时向量就是:Metric01=Vt3 Metric02=Vt3
官方示例:
http_requests_total{job="prometheus"}表示返回距离服务器当前时间最近的采样点的Metric信息。
5 何为区间向量Range Vector?
例如上图中,我们查询[startTime,endTime]之间的Metric信息,假设这个时间段包含三个采样时刻(T1,T2,T3)。
则查询返回的结果包括:
- Metric01=Vt1
- Metric01=Vt2 Metric02=Vt2
- Metric01=Vt3 Metric02=Vt3
这里的区间向量就是:包括上述5个metric信息。
官方示例:
http_requests_total{job="prometheus"}[5m]表示返回最近5分钟内的Metric信息。
5 PromQL处理瞬时向量和区间向量上的区别
5.1 PromQL聚合操作
例如:sum,min,max,count等聚合函数,只能作用于瞬时向量上。
// 这是错误的,因为count只能作用于瞬时向量,而这个查询本身返回的是区间向量
count(http_requests_total{job="prometheus"}[5m])5.2 PromQL内置函数
5.2.1 ceil()向上取整,瞬时向量
ceil(v instant-vector) 将 v 中所有元素的样本值向上四舍五入到最接近的整数。
node_load5{instance="192.168.1.75:9100"} # 结果为 2.79
ceil(node_load5{instance="192.168.1.75:9100"}) # 结果为 35.2.2 changes()数据值变化的次数,区间向量
changes(v range-vector) 输入一个区间向量, 返回这个区间向量内每个样本数据值变化的次数(瞬时向量)。
# 如果样本数据值没有发生变化,则返回结果为 1
changes(node_load5{instance="192.168.1.75:9100"}[1m]) # 结果为 16 结语
深刻的理解瞬时向量和区间向量的含义,是使用好PromQL的关键,否则我们查询的结果很可能就不符合预期。