Python爬虫学习笔记-第四课(网络请求模块补充)
网络请求模块补充
- requests模块发送Post请求
-
- 1. cookie
- 2. 处理不信任的SSL证书
- 3. session
requests模块发送Post请求
1. cookie
通过在客户端记录的信息,确定用户身份。
http是一种无连接协议,客户端和服务器交互仅限于请求/响应过程,结束后断开,下一次请求时,服务器会认为是一个新的客户端,为了维护彼此间的连接,让服务器知道这是前一个客户发起的请求,必须在一个地方保存客户端信息。
作用:
- 反爬;
- 模拟登陆。
通常情况下,网页上显示的信息可以在网页源码中找到。

点击进入12306网站,查询12月21日北京前往上海的高铁票,随便选一个,比如Z281次车票。
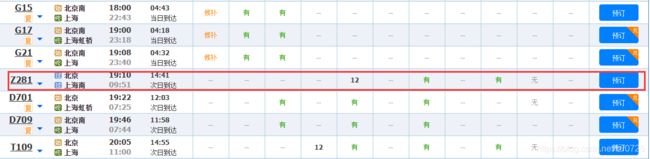
想要在网页源代码中查看该车次的相关信息,但是发现确找不到相关信息。


为什么有时候在网页中能看到数据,而在网页源码中没有
答:服务器经过多次传输,不是一次性加载完成,没有在网页源码中出现。
查找数据的过程如下:
以12306为例,车次列表的数据是用户点击查询后,服务器返回给用户的信息。想要在网页开发工具-network中看到车次的相关信息,必须点击查询后才能看到服务器返回的数据。
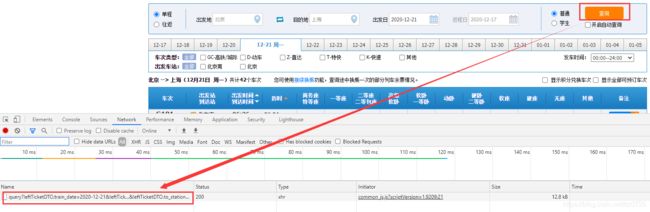
点击左侧query,再点击Preview,就能看到我们所希望爬取的数据。

小拓展:Ajax框架
通过在后台与服务器进行少量数据交换,Ajax 可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
如何爬取ajax动态添加的数据:学会分析数据接口。
上述查找12306车次信息的过程,我们并没有重新刷新网页,而是通过点击查询,就能在network中获取到相应的数据(比如车次列表),这些数据就是通过ajax加载的,也不会显示网页的源码中。
找到数据后,尝试在代码中爬取12306的车次列表数据:
import requests
url = 'https://kyfw.12306.cn/otn/leftTicket/query?leftTicketDTO.train_date=2020-12-21' \
'&leftTicketDTO.from_station=BJP&leftTicketDTO.to_station=SHH&purpose_codes=ADULT '
request_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/86.0.4240.198 Safari/537.36 '
}
res_obj = requests.get(url, headers=request_headers)
print(res_obj.content.decode('utf-8'))
运行结果:

从结果来看,我们得到的并非是期望的数据,说明网站进行了一定的反爬措施。接下来,在程序中添加对应的cookie,其内容查找方式如下图:
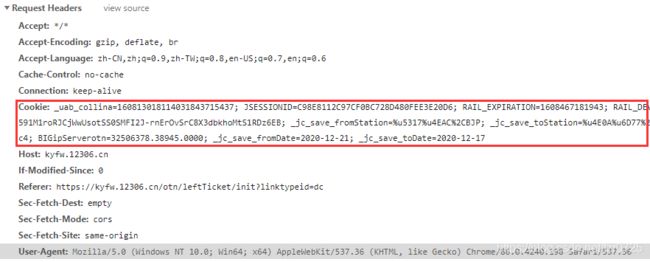
修改的代码如下:
import requests
url = 'https://kyfw.12306.cn/otn/leftTicket/query?leftTicketDTO.train_date=2020-12-21&leftTicketDTO.from_station=BJP&leftTicketDTO.to_station=SHH&purpose_codes=ADULT'
request_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/86.0.4240.198 Safari/537.36 ',
'Cookie': '_uab_collina=160813018114031843715437; JSESSIONID=C98E8112C97CF0BC728D480FEE3E20D6; RAIL_EXPIRATION=1608467181943; RAIL_DEVICEID=VIyFTB3rIXmrYHimBN2rre59wwrrlAkEu6HD80GKeQYs7QXQh22MxMyCVambfCQCsggOo_Tu1GEWoFSInrF47HtCMcv56-cHMGfg8u3VyF591M1roRJCjWwUsotSS0SMFI2J-rnErOvSrC8X3dbkhoMtS1RDz6EB; _jc_save_fromStation=%u5317%u4EAC%2CBJP; _jc_save_toStation=%u4E0A%u6D77%2CSHH; _jc_save_wfdc_flag=dc; BIGipServerpool_passport=283378186.50215.0000; route=6f50b51faa11b987e576cdb301e545c4; BIGipServerotn=32506378.38945.0000; _jc_save_fromDate=2020-12-21; _jc_save_toDate=2020-12-17'
}
res_obj = requests.get(url, headers=request_headers)
print(res_obj.content.decode('utf-8'))
运行结果:

这次的结果就正常了,必须加上cookie才能爬取到数据,也说明cookie可以用于反爬。
接下来介绍cookie在模拟登陆上的应用。以115网盘为例,先看不添加cookie下,爬取到什么内容:
import requests
url = 'https://115.com/?cid=0&offset=0&mode=wangpan'
request_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
res_obj = requests.get(url, headers=request_headers)
print(res_obj.content.decode('utf-8'))
运行结果:

结果中可以看到提示登录的内容,说明上述数据是在没有登陆的情况下爬取的。添加cookie后,能拿到的数据(需要在网页上登录以后才能获取到正确的cookie):
request_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/86.0.4240.198 Safari/537.36',
'Cookie': 'UM_distinctid=175e57d314d101-07a19b11438eb2-930346c-1fa400-175e57d314e2bd; USERSESSIONID=0f303ac702de5fd7fa281922ed0a89c725ca777d631aae0b2f2de8ea63db9d4a; acw_tc=784e2cab16082071940211811e2aaa7f43850beada872ccf28058d09feab8f; CNZZDATA1279056547=1376733246-1605869004-null%7C1608206289; UID=338294808_A1_1608207205; CID=9407b33b15b21d8cf52d1fe1edd04222; SEID=5984044a04e9546ec9c0e397299709f446d98c632531ddcafe4a52488b16ee4998bf34bb2576564dde5836a7f06ae983004bfa803a17f8b28f4a3b73; PHPSESSID=99hccn5h7hucb3bdlgj3gjg74h; 115_lang=zh'
}
运行结果:
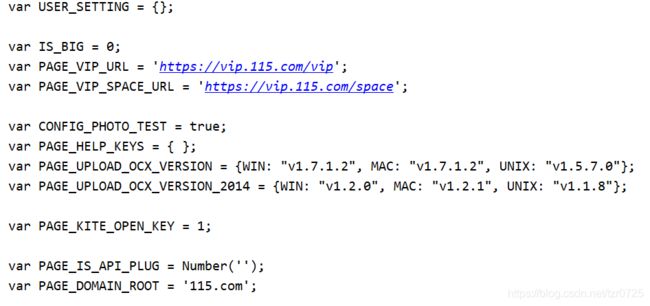
这次的内容已经没有提示登录的字样,说明在headers中添加cookie可以模拟登陆。
2. 处理不信任的SSL证书
SSL证书是数字证书的一种,类似于驾驶证、护照和营业执照的电子副本。因为配置在服务器上,也称为SSL服务器证书。SSL证书就是遵守SSL协议,由受信任的数字证书颁发机构CA,在验证服务器身份后颁发,具有服务器身份验证和数据传输加密功能。
测试网站:https://inv-veri.chinatax.gov.cn/
网站本身是没有问题的,只是ssl证书有问题。

先按照正常的流程爬取数据:
import requests
url = 'https://inv-veri.chinatax.gov.cn/'
res_obj = requests.get(url)
print(res_obj.text)
运行结果:
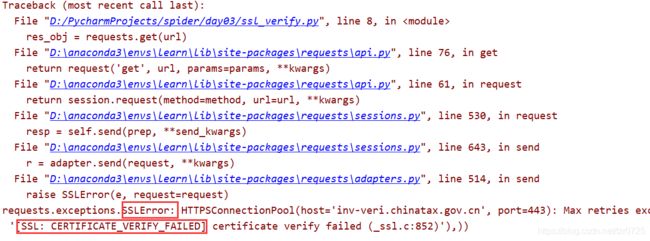
结果报了证书验证失败的错误,并非是代码本身的问题。解决的方案如下:
import requests
url = 'https://inv-veri.chinatax.gov.cn/'
request_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/86.0.4240.198 Safari/537.36 '
}
# 将关键字参数verify置为False,即不要求验证证书
res_obj = requests.get(url, headers=request_headers, verify=False)
print(res_obj.content.decode('utf-8'))
运行结果:

3. session
session通过在服务端记录的信息确定用户身份,保持当前会话。
首先,回到12306案例,尝试模拟登陆12306网站。此处登陆的方式为账号、验证码登陆。
需求:突破12306的图片验证码。
- 账号正确,密码错误,验证码错误;
- 账号正确,密码错误,验证码正确;
- 账号正确,密码正确,验证码正确;
测试情况1:

测试情况2:

情况2相比情况1多了一些数据,其中能看到login:

对于12306来说,它会先验证用户点击的验证码,只有当验证码正确,才会验证账号和密码是否正确。这样做的目的是为了杜绝软件自动地购票抢票的行为。
如果想要突破网站的图片验证,需要向如下的url发起请求:
https://kyfw.12306.cn/passport/captcha/captcha-check
得到的响应结果为result_code: "4",result_message: "验证码校验成功",则表示突破成功。
请求的时候,方式得选用Post(遇到需要登录的场景,如果用get有问题,就尝试使用Post),而且添加额外的参数(如何确定需要哪些参数得自己尝试,并没有特别好的技巧)
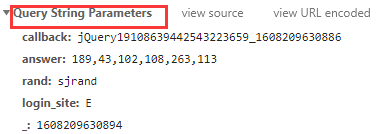
import requests
def login():
query_parameters = {
'answer': '189, 43, 102, 108, 263, 113',
'rand': 'sjrand',
'login_site': 'E'
}
request_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
url = 'https://kyfw.12306.cn/passport/captcha/captcha-check'
res_obj = requests.post(url, data=query_parameters, headers=request_headers)
print(res_obj.text)
login()
运行结果:

尝试请求,结果显然不会那么容易,毕竟都没有点击验证码。下一步的问题是如何获取验证码图片。图片验证码是在12306首页点击账号登录后出现的,如下图:

但是直接请求这个url地址是拿不到验证码图片的,需要对这个url进行一点处理,这个处理就类似于笔者之前博客中提及的请求有道词典案例(需要学JS逆向),需要删除url中的某些字符才能得到真正的验证码。这里直接给出正确的url:
https://kyfw.12306.cn/passport/captcha/captcha-image?login_site=E&module=login&rand=sjrand
拿到验证码图片之后,如何在请求中体现出点击了正确的验证码图片:
其实,仔细观察query_parameters就可以发现其中的answer其实就是用户点击正确验证码图片位置的像素坐标。所以,当我们成功获取到验证码图片后,找到要求的图片,在answer里填写正确的像素位置,就可以向服务器发起请求,模拟点击图片验证码。从严格意义上讲,点击验证码的步骤实际还是人来完成,并不能算真正意义上的突破网站验证码。
import requests
def login():
# 获取图片
pic_url = 'https://kyfw.12306.cn/passport/captcha/captcha-image?login_site=E&module=login&rand=sjrand'
pic_response = requests.get(pic_url)
codeimage = pic_response.content
# 保存验证码图片到本地
with open('code.png', 'wb') as fobj:
fobj.write(codeimage)
request_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
# 获取验证码图片位置
codeStr = input('请输入验证码坐标:')
query_parameters = {
'answer': codeStr,
'rand': 'sjrand',
'login_site': 'E'
}
url = 'https://kyfw.12306.cn/passport/captcha/captcha-check'
res_obj = requests.post(url, data=query_parameters, headers=request_headers)
print(res_obj.text)
login()
运行结果:

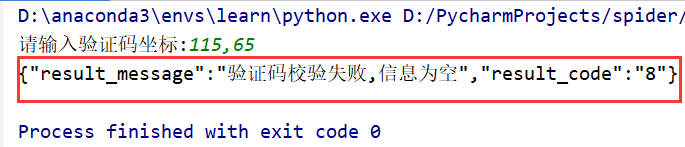
显然,到这里还没有结束,即时输入了正确的像素位置,依旧还是验证码校验失败。这个时候,就需要session登场了。
修改后的代码:
import requests
req = requests.session()
def login():
# 获取图片
pic_url = 'https://kyfw.12306.cn/passport/captcha/captcha-image?login_site=E&module=login&rand=sjrand'
pic_response = req.get(pic_url)
codeimage = pic_response.content
# 保存验证码图片到本地
with open('code.png', 'wb') as fobj:
fobj.write(codeimage)
request_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, '
'like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
# 获取验证码图片位置
codeStr = input('请输入验证码坐标:')
query_parameters = {
'answer': codeStr,
'rand': 'sjrand',
'login_site': 'E'
}
url = 'https://kyfw.12306.cn/passport/captcha/captcha-check'
res_obj = req.post(url, data=query_parameters, headers=request_headers)
print(res_obj.text)
login()
运行结果:

使用session请求该网站,让服务器记录用户的相关信息,保持会话,即保持当前状态,允许用户做其他的请求(比如点击验证码)。