Big Data Management笔记02:MapReduce &Spark
Big Data Management笔记02:MapReduce & Spark
- MapReduce
-
- MapReduce in Hadoop
-
- Shuffle
- Spark
-
- Spark Architecture
- Resilient Distributed Dataset (RDD)
-
- Create RDDs
- RDD operations
-
- Transformations
- Actions
- Lineage
- DAG(有向无环图)
- Lineage vs DAG in Spark
- Shuffle
-
- Hash Shuffle
- Sort Shuffle
- Spark Efficiency
- MapReduce vs Spark
在前一节中,我们已经了解了Hadoop如何存储数据。这一节开始,我们把目光放到如何处理数据上,我们将着重介绍Hadoop中的计算框架:MapReduce和从MapReduce发展而来的Spark。
在具体介绍它们之前,我们先来看一看,我们为什么需要这两者来帮助我们处理数据。这其实是一个很简单的问题,我们先来看一看传统的数据处理方式:
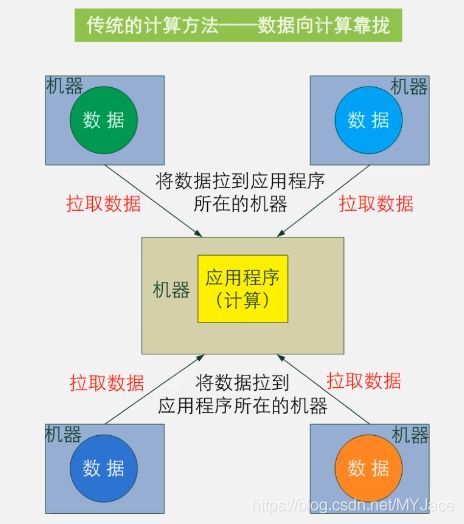
可以很直观地看到,传统的数据处理方式的核心思想是“数据向计算靠拢”,需要把数据拉取到计算节点进行计算。但当我们在处理大数据问题时,显然这种方式是不合适的。我们在之前介绍HDFS时已经说过,所有的数据都被划分为Blocks存储于不同的DataNode中,若我们拉取这些数据,会产生很大的开销,而且这对于计算节点的压力也会很大。所以,既然我们在HDFS中已经把数据分布存储在众多DataNode之中,而且这些DataNode除了硬盘资源被使用(用于存储数据)以外,CPU和内存资源都很空闲。那么,我们为什么不把这些空闲资源也调用起来的呢?
正是这种“物尽其用”的想法,使得MapReduce诞生了。
MapReduce
我们首先要明确,MapReduce的核心思想为“计算向数据靠拢”。
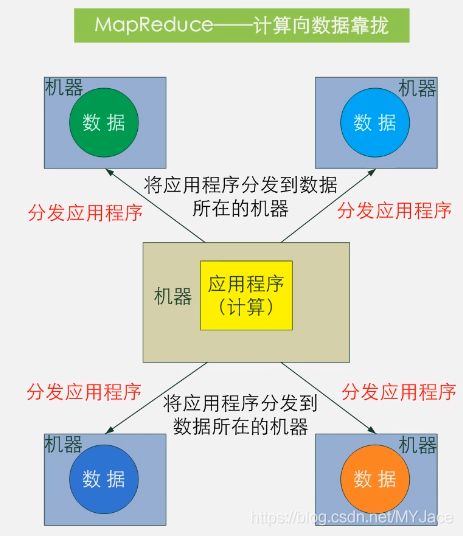
以Hadoop的Master-Slave结构来看,就是将任务进行分割,分为很多小的子任务,把这些子任务发布给各SlaveNode(DataNode)去完成,最后将它们完成的结果整合起来即可。(DataNode各自处理自己存储的Blocks,不管其他Node)

当然,想要实现这种方式,必然有一些问题需要解决,比如:
- Data relibility:如果某个DataNode失效或者丢失了一部分blocks
- Equal split of data:我们希望每个DataNode处理的数据量比较均衡,不会出现某个DataNode过载的情况
- Delay of worker:如果某个DataNode(尤其是比较重要的DataNode)的工作延迟了,很可能导致整个任务被延迟
- Failure of worker
- Aggregation the result:关乎我们如何整合每个DataNode完成的结果,并生成一个总体结果
MapReduce为我们很好地解决了以上所有问题。MapReduce是一款开源的编程框架,它
- 让我们能够在分布存储的大数据集上进行并行和分布式处理
- 且无需担心诸如DataRelibility之类的所有问题
- 为我们提供了逻辑编程的灵活性,而无需担心具体的实现细节
键值对(Key-value pair)是MapReduce中最基础的数据结构,这里的键和值可能是整数、浮点数、字符串等任意的数据结构。
MapReduce的主要组成部分就是Map和Reduce:
- Map:
- 将小数据及进一步解析为一批键值对 (
- 每一个输入键值对 ( - Reduce:
- 从多个Maps接受中间结果
- 将这些中间结果整合为最终的输出,最终结果会被返回到HDFS
MapReduce in Hadoop
数据(data)以blocks的形式存储于HDFS。Hadoop MapReduce把输入(input)划分为固定尺寸的输入分片(input splits),并为每一个分片(split)创建一个map任务。map任务对分片(split)中的每一条record运行用户定义的map函数。通常分片(split)的尺寸即为HDFS block的尺寸。
这很好理解,因为如果分片(split)的尺寸大于block的尺寸,那么就不可能把一个split完整存放于一个DataNode,这样当前DataNode在几你选哪个运算时,还将需要从另一个DataNode获取数据。
Map Tasks(Mappers) 会把输出写入local disk,即存储着block的Data Node的disk。注意,Map并不会把输出写入HDFS!!
- Map的输出即为中间结果(intermediate result)
- 一旦任务完成,Map的输出即可被丢弃
- 如果进行Map Task的节点失效了,Hadoop会自动在拥有同样blocks的节点上重新进行Map Task
Reduce Taks (Reducers):
- 通常每个Reduce Task的输入是所有Mappers的输出
- Reduce的输出会保存在HDFS(如果是迭代操作,那么每一次迭代的输出都会被存入HDFS)
- Reduce Tasks的数量不取决于输入(input)的尺寸,而是由用户指定的
MapReduce Dataflow

当有多个Reducers时,Map Tasks会将他们的输出进行划分:
- 每一个Reduce Task都有一个Partition
- 需要确保每一个Key的所有记录都在一个Partition内。比如第一个Map Task的输出为
- 具体划分的方式可由用户定义的函数决定
Shuffle
之前我们只关注了Map和Reduce,但实际上,在Map到Reduce的中间还有一个过程,就是Shuffle,我们刚刚说到的Partitioning就是Shuffle的一部分。
Shuffle本质上是一个数据再分配的过程(data redistribution)
- 用以确保每个reducer获得与同一个键(key)关联的所有值
- 所有需要分组(grouping)的操作都需要它,比如word count, 计算每个部门的平均分等类似的操作
Hadoop中的Shuffle操作使用了Shuffle and Sort机制。每一个Mapper在完成计算后,结果都会在Buffer中以Key值进行排序,这样就不需要等到所有Mappers完成计算之后再发送结果,Reducers也可以在所有Mappers结束工作之前就开始工作。
有时,也会使用Combiner来减少要进行Shuffle的数据量,即在每一个partition中,将相同键(key)的键值对组合起来。是否使用以及如何使用Combiner完全取决于用户设计。
下图是以 Word Count为例的具体流程:
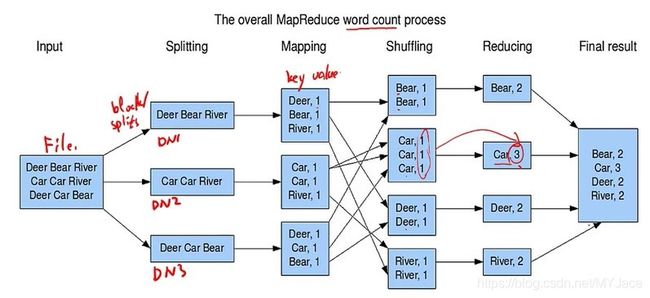
如果我们在此过程中使用Combiner,以DataNode2为例,那么Mapping结果为
Spark
尽管MapReduce已经很强大,但是它仍然存在一些问题
- MapReduce是一种优秀的one-pass计算方式,但它很难嵌套多种操作,表达能力有限(只有Map和Reduce)
- MapReduce无法进行迭代操作
- 无法进行实时性更强的的流处理 (stream processing)
- 所有从硬盘 (disk) 上读取的数据,最后都要存回 (disk)。这就是我们之前提到的MapReduce的最终结果仍要返回HDFS,而且上一篇博客已经说过,HDFS每次存储数据都要建立3个副本,这会造成空间和时间的浪费
用两个例子看一下:

第一个例子是一个典型的ML任务。每一次迭代中,我们都需要从HDFS进行读写操作,而且很多时候,ML不仅需要从HDFS读取上一次迭代的结果,还需要再次从input读取数据。
第二个例子是对查询 (query) 的处理。对于每一次查询都需要从HDFS进行读取。
以上两个列子可以让我们得出一个结论:因为HDFS的副本 (replications) 创建操作,IO读取 (效率远低于Memory读取)以及序列化操作 (serialization),MapReduce的效率会变得很低。 而这些问题都源于MapReduce最大的一个弊端:缺少有效的数据共享 (data sharing)。
正因为MapReduce的这些问题,Spark诞生了。Spark是一款用于实时处理的开源集群计算框架。(an open-source cluster computing framework for real-time processing)。Spark提供了一个接口,用于使用隐式数据并行性 (implicit data parallelism) 和容错性 (faulte tolerance) 对整个集群进行编程。它建立在MapReduce之上,并支持更多样的计算。
Spark如今已形成一套完整的生态体系:

Spark Architecture

和Hadoop“一贯”的Master/Slave结构类似,Spark的结构主要有3个部分:
- MasterNode
- 该节点负责集群 (cluster) 中的作业执行 (job execution)
- Driver program运行于MasterNode,该程序用以驱动应用。我们所编写的代码就是Driver program
- Driver program做的第一件事就是建立SparkContext (类似于DB中的connection,所有的command的执行都要通过这里) - ClusterManager
- 跨应用程序分配资源(与SparkContext协同工作)
- 分割任务并分配给WorkerNodes - WorkerNode
- 执行任务(work on partitions of RDDS in the WorkerNode)
- 最后将结果返回给SparkContext
作业(Job)指的是一系列的Transformations紧接着一个Action,只有Action会触发真正的执行(execution),比如Lazy Evaluation。具体的表现为,在运行Spark代码时,只要是Action以外的代码运行的都很快,但是当执行Action时,会花费一些时间去完成作业。这里给一个简单的例子,可以运行一下进行感受(推荐使用Jupyter Notebook):
from pyspark import SparkContext, SparkConf
# Initialise SparkContext and SparkConf
conf = SparkConf().setMaster("local").setAppName("week_4")
sc = SparkContext(conf=conf)
data = ["This is sentence one", "This is sentence two", "This is another sentence", "And this is the forth sentence"]
rdd = sc.parallelize(data, 2)
def pre_processing(sent):
words = sent.lower().split()
res = []
for word in words:
res.append((word, 1))
return res
pre_processing("This is sentence one")
rdd_1 = rdd.flatMap(pre_processing)
# Here take Action
rdd_1.collect()
Resilient Distributed Dataset (RDD)
RDD是Spark中数据所在的地方,同时他也是Spark的基本数据结构:
- Dataset: 元素的集合 (a collection of elements)。这里的元素指代各种类型的数据,比如数字、txt、字典等。
- Distributed: RDD中的数据会被分为很多分片 (chunks) 然后被分发给不同的工作节点,因此可以惊醒并行计算 (the data in an RDD can be splitted into chunks, then these chunks can be logically partioned across many severs. So user can do computation or other operations on different nodes of cluster. )
- Redilient: RDD具有容错性 (fault tolerance),这种容错性得益于RDD Lineage/DAG,因此可以在节点失效时,重新计算遗失或是损坏的partitions
RDD具有以下特征:
- In memory computation:RDD会把计算的中间结果存储在不同机器的内存 (memory) 中,而不是像MapReduce一样存储于硬盘中 (disk/hard driver),读写的速度会大大提高
- Partitioning:是RDD并行性的基础,每一个partition是data的一个逻辑划分 (logic division)。人为划分时要尽可能保证均衡划分,这样会使得对不同workers分发的chunks更均衡
- Fault tolerance
- Immutability (不变形):The data on RDD is unable to be changed once it is created. Data is safe although we share them across different processors. Reach consistency in computation.
- Persistence:User can state which RDD they will reuse and choose a store strategy for this specific RDD (On memory/disk). 默认情况下,Spark将RDD存于内存 (memory)。但有两种例外,一种是memory空间不足,第二是用户请求将RDD存于disk
- Coarse-grained operations:与Fine-grained operations相对。Fine-grained指的是操作 (operations) 可只对数据集中的一部分数据进行,所以,与之相对的Coarse-grained意味着操作会对数据集中的所有元素进行。RDD中的写操作 (writer) 是Coarse-grained,读操作 (read) 可能是Coarse-grained或是Fine-grained。 Coarse-grained的优点在于,它会让RDD更容易保证容错性,因为之前的操作是对所有的数据进行的,所以RDD Lineage可以知道所有之前的RDDs是怎样的,以及怎样的操作可以产生现在的RDDs,这样更易进行数据恢复。
- Location-stickness:RDD可以为特定的计算定义首选位置,即把RDD chunks分配到哪里。让任务尽可能靠近数据。
Create RDDs
有两种方式:
- 并行化driver program中的现有集合
- 通常,Spark会根据集群 (cluster) 的数量自动设置partitions的数量 - 引用外部存储系统中的数据集
- 比如HDFS, HBase等任何可以提供Hadoop输入格式 (Input format) 的数据源
- 默认情况下,Spark会为文件的每一个block创建一个partition
RDD operations
类似于在MapReduce中,我们只有两个操作,分别是Map和Reduce表达能力有限。RDD中我们对Map和Reduce进行扩充,也就得到了Transformation(典型就是Map)和Actions(典型是Reduce)
Transformations
Transformations就是一些函数 (functions),这些函数接受一个RDD作为输入(input),产生一个或多个RDDs作为输出(output)
Transformations可以进一步分为两类:
- Narrow Transformation
- 不会进行Data Shuffling。这就意味着在同一个partition中的数据,在进行Transformation之后仍会在同一个partition之中,而在不同partition中的data也仍会在不同的partition中
- 典型的Function有:map,flatmap, filter, sample - Wide Transformation
- 会进行Data Shuffling。同一个partition中的数据在transformation之后可能会在不同的partition中
- 典型的Function有:sortByKey, reduceBykey, groupByKey, join (大部分的函数都需要使用Key)
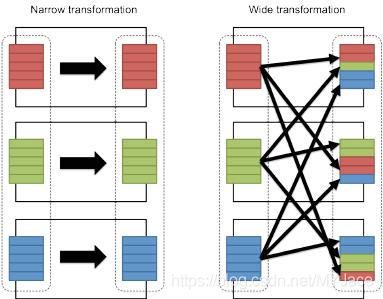
需要格外注意的是,所有的Transformation操作,它们都不会改变输入的RDD,同时它们会输出新的RDD,所以在进行编程时,需要把Transformatin的结果存储进一个新的RDD 另外值得一提的是,Transformation遵循Lazy Evaluation原则,这意味着Evaluation不会启动,直到一个Action被触发
Actions
以RDD作为输入,输出非RDD值。我们可以看做Actions返回一系列RDD Transfomantions的结果。最后的结果会返回给DriverProgram或者一个指定的外部存储 (External Storage)。重申一遍,这里的结果不一定是数字、列表、字符,可能是各种形式,但不会RDD Action操作包含了以下几种:collect, take, reduce, for each, count, save…
这里给出一些Transformations和Actions的简单例子,推荐使用Jupyter Notebook运行
from pyspark import SparkContext, SparkConf
# Initialise a SparkContext fitstly
conf = SparkConf().setMaster("local").setAppName("Example")
# Initialise 1 SparkContext with 1 configure file (If we use the same configure file to initialise another SparkText, error will occur)
sc = SparkContext(conf=conf)
# sc_2 = SparkContext(conf=conf)
data = range(1, 100)
# Create RDD by parallelize data (we can specify the number pf partitions)
rdd = sc.parallelize(data, 5)
# Using glom to view data from different partitions
rdd.glom().collect()
# Create another RDD from a txt file on the disk
rdd_1 = sc.textFile("example.txt")
# The result is a list of strings, each element corresponging to 1 line in a text file
rdd_1.collect()
""" Narrow Transformation """
# Functionality of 'map': return a new RDD by applying a function to each element in the input RDD
rdd_map = rdd_1.map(lambda x: (x, 1))
# rdd_map.collect()
rdd_map.take(4)
# Functionality of 'flat_map': flatten the array and then appply a function to each element
text = ['word count', 'word word count']
rdd_2 = sc.parallelize(text)
rdd_2.collect()
rdd_2.map(lambda x: x.split()).collect()
rdd_flatmap = rdd_2.flatMap(lambda x: x.split())
rdd_flatmap.collect()
# Functionality of 'filter': Only keep elements that satisfy the function we define
rdd_filter = rdd_flatmap.filter(lambda x: x != 'count')
rdd_filter.collect()
""" Wide Transformation """
# Fucntionality of 'reduceByKey': merge values for each key using the reduce function
rdd_reducebykey = rdd_map.reduceByKey(lambda x, y: x + y)
rdd_reducebykey.collect()
# Functionality of 'sortByKey'
rdd_flatmap.sortByKey().collect()
# Functionality of 'groupByKey': group values for each key into a single sequence
# rdd_map.groupByKey().collect()# If we use collect() directly, then we will see encoded result
for i in rdd_map.groupByKey().collect():
print(i[0], [v for v in i[1]])
# We can use several ways to pass function we need to these Transformations
def func(x, y):
return x + y
rdd_reducebykey = rdd_map.reduceByKey(func)
rdd_reducebykey.collect()
""" Actions """
# We have seen collect() and take() before
rdd.reduce(lambda x, y: x + y)
rdd.count()
这里我单独用一篇博客来介绍另外一些Spark中比较常见的Transformations Tips:Transformation Tips
Lineage
Transformations以RDD为输入,并输出新的RDD。所以RDD所有的可能来源有:Transformation的结果,从DriverProgram中已存的数据集进行并行化(parallelize)得来,从一个外部数据库得来。所以我们希望知道这些RDD之间的关系。
RDD Lineage是一幅有向图 (directed graph),记录了一个RDD的所有“祖先”RDD。也被称为 RDD Operator Graph(RDD算子图)/RDD Dependency Graph(RDD关系图)。在Lineage中:
- 点(Node)表示RDDs
- 边(Edge)表示RDDs之间的依赖关系
我们看一个具体的例子:

我们可以用r5.toDebugString()来查看r5的Lineage图
RDD Lineage存在的最主要的一个原因是为了保证RDD的容错性 (Fault Tolerance):如果RDD是由具有容错性的数据生成的,那么RDD也会具备容错性。
我们之前已经提到过,在Spark中RDD会被分为许多partitions,之后分发给各节点(Node)进行工作。所以一旦有某个节点失效了,那么这部分RDD数据(即partions)就遗失了。这个时候Cluster Manager会发现该点失效,同时分配一个新的节点来继续操作。这个新的节点会被告知去在RDD的某个特定的partition上进行操作同时也会被告知Lineage图。比如 A -> B -> C ,C丢失,那么,新的节点就可以根据Lineage图,重新计算出遗失的partition C。
顺便一提, MeSOS用于Driver Node Failure
DAG(有向无环图)
在DAG中:
- 点(Node)表示RDDs
- 边(Edge)表示对RDD进行的操作
DAG与Lazy Evaluation密切相关,这意味着,在进行一系列Transformations的过程中,DAG都不会被创建,直到Actions被调用。一旦DAG被创建,它会被提交给DAG Scheduler,之后DAG Scheduler会进一步将图分解为任务阶段 (stages of task)。任务阶段会被传达给Task Scheduler,Task Scheduler会通过cluster manager发起任务。
现在具体解释一下stage是什么:
-
stages是根据Transformations建立的
- Narrow Transformation 会被归纳为一个stage
- Wide Transformation 定义了2个stages的边界 -
DAG Scheduler会把stages提交给Task Scheduler
- Task的数量取决于partitions的数量
- 不相互依赖的stages(比如两个stages之间没有数据流通)可以提交给集群以并行执行
由于DAG提供具体操作的之间的关系,所以我们可以把它们进一步分为stages,进一步进行并行操作以及操作顺序调整以进行全局优化(Global Optimization)
Lineage vs DAG in Spark
- 都是有向无环图
- 终点(End Point)不同:DAG的终点通常是Action,Lineage的终点是一个RDD。同时每一个RDD都会有一个自己的Lineage,但是DAG是针对全局的,只会有一个
- 在Spark中,它们扮演的角色不同。DAG把整个工作流程划分为多个stages,并传递给task scheduler,为了进行lazy evaluation;Lineage是针对每个RDD,为了保证容错性
只有一种情况Lineage = DAG,那就是该Spark项目只建立一个RDD,而且它是最后一个步骤。
Shuffle
Spark和Hadoop中的Suffle有着明显的区别。
- Spark中的Shuffle由某些操作触发,比如:distinct, join, repartition以及所有 *By 和 *ByKey 操作。在Hadoop中,由Reducer触发。
- 发生于阶段 (Stages) 之间,因此,只要有一个新的阶段 (Stage) 就会有一次Shuffle
- Spark中的Shuffle主要有两种实现方式:基于Hash和基于Sort
Hash Shuffle
- 最大优势在于Hashing的速度远高于Sorting。如果你还记得,Shuffle的目的在于根据键值(key)来给Record分组,传统的Shuffle方式就是基于Sorting,而根据Sorting(O(nlogn))和Hashing(O(n))的时间复杂度,我们可以很轻易地得出结论,Hashing更高效。这是源于Hashing的特征,如果两个key,k1与k2相同,那么它们的哈希值(hash value)h(k1) = h(k2),如果哈希值不同,那么这两个key就不会相同。
- 缺点在于要创建多余的文件。尽管Spark中没有Mapper和Reducer,我们这俩就把Shuffle之前的算子当做Mapper,之后的算子当做Reducer,即前一个Stage最后的操作,和后一个Stage的第一个操作。在Hash Shuffle中,每一个Mapper要为每一个Reducer创建一个File,并将对应的键值对写入File。因此,总共会有 M x R个File。因此,创建和丢弃这些文件的速度就成了限制Hash Shuffle的瓶颈。
为了解决上述的文件过多的问题,就要使用consolidateFiles来减少文件数量。具体的操作为:不再为每一个reducer创建一个新的file,而是为output file创建一个池 (pool)。所以,当Mapper输出数据时,它向这个池请求R个文件进行操作,操作结束后,将这R个文件返还给文件池,下一个Mapper会进行同样的操作。
我们用E来表示executor的数量,C表示cores的数量,T表示CPU的数量。对任意一个executor,它只能同时进行C/T个任务,因此它只能创建C/T个组,每个组有R个文件,因此一共有 E * C/T * R个文件,相比 M * R确实减少了
Sort Shuffle
前文提到,Hash Shuffle是为了避免Sort Shuffle的问题而提出来的,但是当Spark的设计者也意识到Sort Shuffle存在的问题后,也对Sort Shuffle进行了改进。
-
每一个Mapper建立两个文件
- 一个是按键值进行排序的数据 (sorted by key)
- 另一个是每一个‘chunk’首尾的index
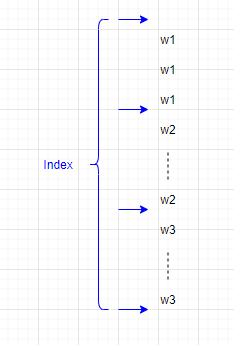
-
这些文件会被合并,最后被Reducer读取
-
当partitions的数量小到一定程度时,会变回Hash Shuffle。当number of partitions很大,Hash Shuffle不给力,反之,Hash Shuffle更好,所以partitions的数量需要权衡。
Spark Efficiency
有以下几个因素会影响Spark的效率:
- Transformations的数量
- 因为每一个Transformation都需要遍历整个数据集(RDD),所以Transformation越少越好 - Transformation的Size
- 越小的输入尺寸,会有越低的遍历成本 - Shuffles
- 因为partitions之间的数据交换成本是很高的,所以Shuffle越少越好
MapReduce vs Spark
在介绍了MapReduce和Spark之后,可能会有人产生一个疑问,那就是Spark中的Transformation就等同于MapReduce中的Map,Action就等同于Reduce吗?
答案是否定的。这里我们依然用之前已经看过的一张图就能理解:

在这张图中,我用蓝色标注了Spark的操作,红色标注了MapReduce的操作。可以清楚地看到,在Spark中,它经过了map, reduceByKey, groupByKey三个Transformations和一个Action。而在MapReduce中,它实际上只有Map,Shuffle和Reduce三个过程。