selenium+python之元素定位
本文目标:使用8种方法定位百度首页上的页面元素并进行操作。
环境基础:selenium+python基础环境已配置,能够使用selenium打开百度首页。
第一步:手动打开百度首页,然后按F12,查看首页的HTML代码
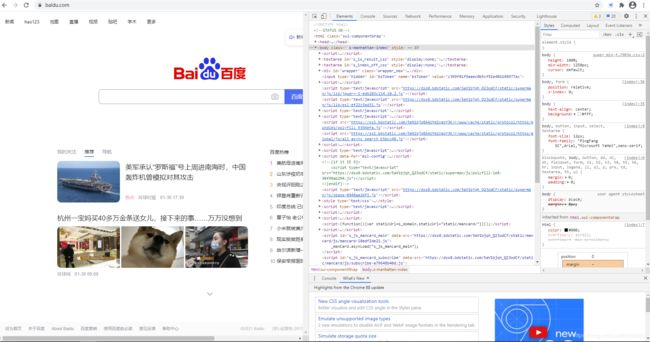
第二步:使用find_element_by_id()来定位元素。
1)按下ctrl+shift+c键,然后光标选中要点击搜索框。可以看到右边的HTML栏里高亮的部分就是这个标签的代码:。由此代码可知,搜索框的id=kw.
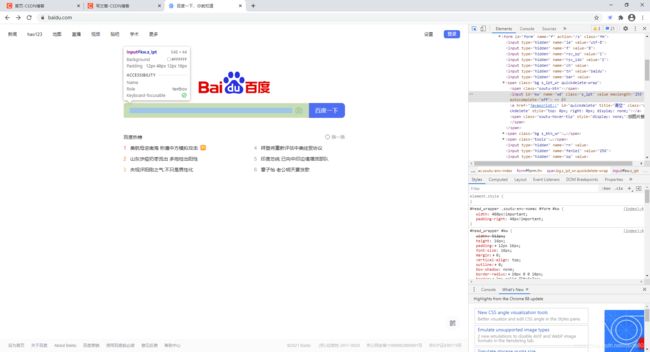
2)在python中写入代码,让selenium在搜索框中输入“python”
from selenium.webdriver import Chrome
from time import sleep
with Chrome() as driver:
'''使用上下文管理器来操作driver能够更合理的使用计算机资源,比driver = Chrome()的写法更好'''
# 访问百度网站,然后等待2秒
driver.get('http://www.baidu.com')
sleep(2)
# 选中搜索输入框并输入’python,然后等待5秒
driver.find_element_by_id('kw').send_keys('python')
sleep(5)
执行截图如下:
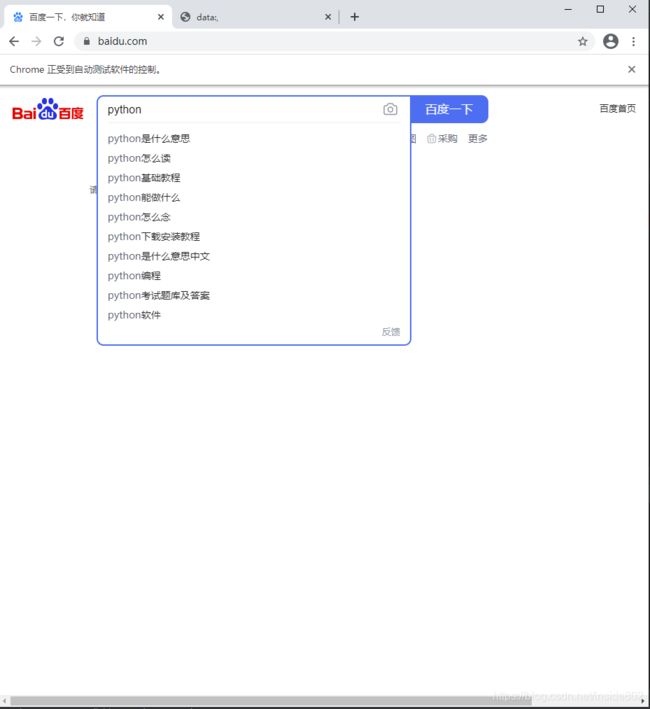
第三步:使用find_element_by_name()的方法定位元素
在第二步中,可知搜索框的name=wd,将代码重写,使用find_element_by_name的方法在输入框中输入‘python’
from selenium.webdriver import Chrome
from time import sleep
with Chrome() as driver:
'''使用上下文管理器来操作driver能够更合理的使用计算机资源,比driver = Chrome()的写法更好'''
# 访问百度网站,然后等待2秒
driver.get('http://www.baidu.com')
sleep(2)
# 选中搜索输入框并输入’python,然后等待5秒
driver.find_element_by_name('wd').send_keys('python')
sleep(5)
第四步:使用find_element_by_class_name()的方法定位元素
在第二步中,可知搜索框的class_name=s_ipt。将代码重写,使用find_element_by_class_name的方法在输入框中输入‘python’
from selenium.webdriver import Chrome
from time import sleep
with Chrome() as driver:
'''使用上下文管理器来操作driver能够更合理的使用计算机资源,比driver = Chrome()的写法更好'''
# 访问百度网站,然后等待2秒
driver.get('http://www.baidu.com')
sleep(2)
# 选中搜索输入框并输入’python,然后等待5秒
driver.find_element_by_class_name('s_ipt').send_keys('python')
sleep(5)
第五步:使用find_element_by_xpath()的方法定位元素
1)在搜索框的代码处点击右键,然后选‘copy’,然后在子菜单里选择‘copy xpath’
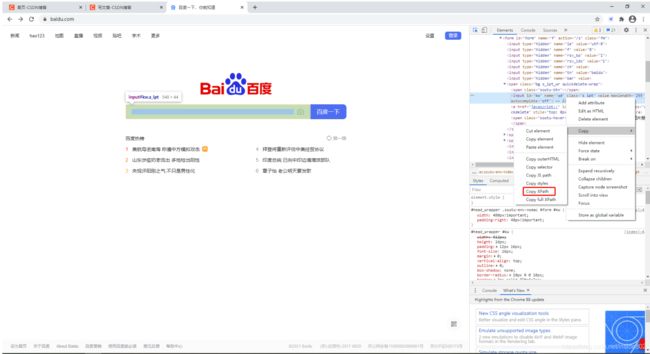
2)重写python代码,使用find_element_by_xpath()方法在输入框中输入‘python’
from selenium.webdriver import Chrome
from time import sleep
with Chrome() as driver:
'''使用上下文管理器来操作driver能够更合理的使用计算机资源,比driver = Chrome()的写法更好'''
# 访问百度网站,然后等待2秒
driver.get('http://www.baidu.com')
sleep(2)
# 选中搜索输入框并输入’python,然后等待5秒
driver.find_element_by_xpath('//*[@id="kw"]').send_keys('python')
sleep(5)
第六步:使用find_element_by_css_selector()方法定位元素
1)在搜索框的代码处点击右键,然后选‘copy’,然后在子菜单里选择‘copy selector’

2)重写python代码,使用find_element_by_css_selector()方法在搜索框中输入‘python’
from selenium.webdriver import Chrome
from time import sleep
with Chrome() as driver:
'''使用上下文管理器来操作driver能够更合理的使用计算机资源,比driver = Chrome()的写法更好'''
# 访问百度网站,然后等待2秒
driver.get('http://www.baidu.com')
sleep(2)
# 选中搜索输入框并输入’python,然后等待5秒
driver.find_element_by_css_selector('#kw').send_keys('python')
sleep(5)
第七步:使用find_element_by_link_text()方法定位元素
该方法仅用于属性为link的元素,即它是一个链接,直接通过链接名称来定位元素
1)看到百度网页上任意链接,如左上角的“新闻”链接,它的链接名称就是“新闻”
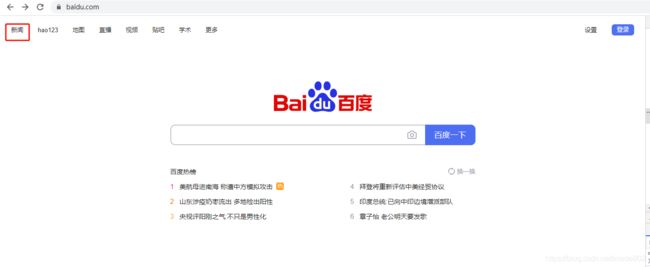
2)修改python代码,使用find_element_by_link_text()方法来点击“新闻”链接
from selenium.webdriver import Chrome
from time import sleep
with Chrome() as driver:
'''使用上下文管理器来操作driver能够更合理的使用计算机资源,比driver = Chrome()的写法更好'''
# 访问百度网站,然后等待2秒
driver.get('http://www.baidu.com')
sleep(2)
# 点击新闻链接,然后等待5秒
driver.find_element_by_link_text('新闻').click()
sleep(5)

*
第八步:使用find_element_by_partial_link_text()方法定位元素
基本同第七步,不过这次不写“新闻”链接的全部名称,只写一个“新”字
from selenium.webdriver import Chrome
from time import sleep
with Chrome() as driver:
'''使用上下文管理器来操作driver能够更合理的使用计算机资源,比driver = Chrome()的写法更好'''
# 访问百度网站,然后等待2秒
driver.get('http://www.baidu.com')
sleep(2)
# 点击新闻链接,然后等待5秒
driver.find_element_by_partial_link_text('新').click()
sleep(5)
第九步:使用find_element_by_tag_name()方法来定位元素*
1)按住ctrl+shift+c,光标选中百度首页中的百度logo,查看其HTML代码: 可知,其标签为‘area’
2)在HTML代码中按ctrl+F,在搜索框中搜索area,可以看到,所有HTML里只有1个area,因此使用find_element_tag_name的方法必然能唯一定位到这个元素
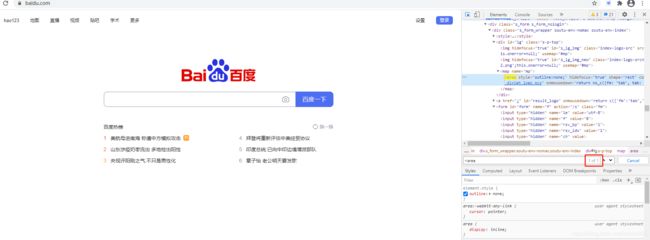
3)修改python代码,定位图中的logo,并且点击
from selenium.webdriver import Chrome
from time import sleep
with Chrome() as driver:
'''使用上下文管理器来操作driver能够更合理的使用计算机资源,比driver = Chrome()的写法更好'''
# 访问百度网站,然后等待2秒
driver.get('http://www.baidu.com')
sleep(2)
# 选中搜索输入框并输入’python,然后等待5秒
driver.find_element_by_tag_name('area').click()
sleep(5)
