Python爬虫实战01--KFC地址爬取
目标:使用requests模块对肯德基官网的数据进行爬取
目标网址: http://www.kfc.com.cn/kfccda/index.aspx
requests模块作用:requests模块是python一款原生的基于网络请求的模块,我们用来模拟浏览器发送请求。
代码思路:
1. 确定要请求的url:不用多说,不管干什么都要先确定一个明确的目标,比如你去参加跑步比赛,正常人肯定都是朝着终点跑一样,如果我们的url一开始就选择错误了,那么想获得我们想要的数据就成了无稽之谈了。
2. 发起请求:这里是用requests的请求功能来代替我们用户在网页上的鼠标点击操作,即使不用浏览器也能完成访问。
3. 获取响应数据:我们发起了请求,服务器自然会给我们回应,我们的任务就是从服务器返回的数据中筛选出我们所希望得到的数据。
4. 数据的储存:获得了我们心心念念的数据以后,我们肯定是希望将它保存,以便随时查看,这里就需要用到文件操作相关的知识。
好了,捋清楚思路,话不多说,直接开搞!
首先我们先打开目标网站进行观察,其实爬虫就是自动的下载想要的数据,只不过把我们手动下载保存的过程通过代码自动化了,说到代码,相关的参数必不可少,我们观察网页的目的就是为了找出所需要的参数。

好的,接下来就是,额……大晚上的敲代码不容易,这个薯条看着好像中暑了,不如我们……
嗝~吃完了,接着说,我们点进去可以看到目标网页,
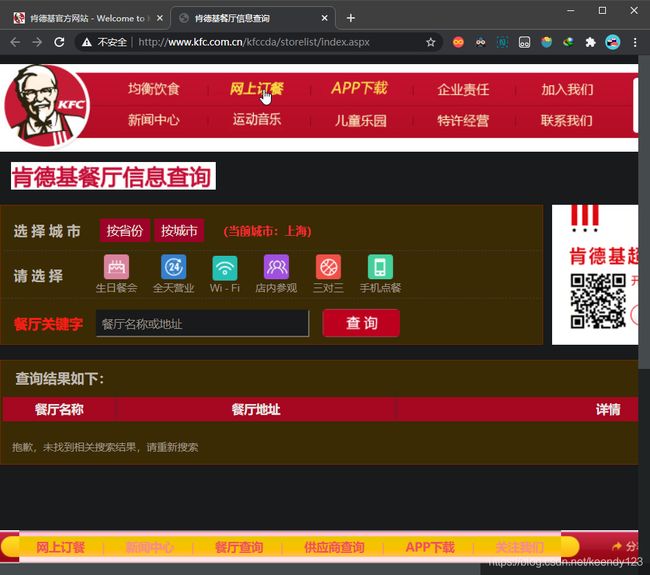
这个时候点击鼠标右键–>检查或者F12 进入开发者模式,我们就是要在这里寻找爬虫所需要的参数。在地址栏输入–>北京,发现会返回一个响应,说明我们要的数据应该在这个返回的响应中。

获取要请求的url
post_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
图中的url就是我们要请求的post_url
发起请求
response = requests.post(url=post_url,data=data,headers=headers)
图片中的request method对应到requests模块中的post方法,我们用句点表示法引用。
除了上面这两个参数之外,我们还需要一个重要参数:UA即User-Agent(请求载体的身份标识)
UA检测:门户网站的服务器会检测请求载体的身份标识,如果检测到请求的载体身份标识是某一款浏览器,说明该请求是一个正常的请求,但是如果检测到请求的载体身份标识不是基于某一款浏览器的,则说明是不正常的请求(即爬虫),服务器就有可能拒绝请求,这是现在大多数网站都会采用的一种反爬机制(网站:让你丫乱爬,爷把ip给你封喽~)
所以为了避免这种情况,我们还要使用一种反反爬手段:UA伪装,让爬虫对应的请求载体身份标识伪装成某一款浏览器,正所谓道高一尺魔高一丈,上有政策下有对策,嘿嘿~(当然,我这里只是象征性的介绍一下,毕竟我也是小白,啥也不会 = =,正可谓是菜的理直气壮!)
接着说哈,除了以上几个参数,我们resquests.post还需要一个data参数,如图

说了这么半天,我们距离真正需要的数据只差一步之遥了,在response中我们惊喜的发现,这不就是我们心心念念的地址么!这样我们所需要的东西就都齐全了,接线来就是把参数填到代码里就OK啦~
直接上代码~
# 调用requests模块
import requests
if __name__ == '__main__':
# step-1: 获取要请求的url
post_url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
kw = input('请输入城市名: ')
data = {
'cname': '',
'pid': '',
'keyword': kw,
'pageIndex': '1',
'pageSize': '10'
}
# step-2: UA伪装
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36'
}
# step-3: 发起请求
response = requests.post(url=post_url,data=data,headers=headers)
# step-4: 获得请求返回数据并保存
dict_text = response.text
#虽然返回的是txt格式,但是这里保存成json格式,就可以使用自动调整格式了,更方便查看
filename = kw+'市kfc分布.json'
fp = open(filename,'w',encoding='utf-8')
fp.write(dict_text)
print('爬取成功~')
运行完毕后,工作区会自动生成一个’北京市kfc分布.json’ 的文件,说明爬取成功~
{
"Table": [
{
"rowcount": 65
}
],
"Table1": [
{
"rownum": 1,
"storeName": "育慧里",
"addressDetail": "小营东路3号北京凯基伦购物中心一层西侧",
"pro": "24小时,Wi-Fi,店内参观,礼品卡",
"provinceName": "北京市",
"cityName": "北京市"
},
{
"rownum": 2,
"storeName": "京通新城",
"addressDetail": "朝阳路杨闸环岛西北京通苑30号楼一层南侧",
"pro": "Wi-Fi,店内参观,礼品卡,生日餐会",
"provinceName": "北京市",
"cityName": "北京市"
},
{
"rownum": 3,
"storeName": "黄寺大街",
"addressDetail": "黄寺大街15号北京城乡黄寺商厦",
"pro": "Wi-Fi,点唱机,店内参观,礼品卡,生日餐会",
"provinceName": "北京市",
"cityName": "北京市"
},
{
"rownum": 4,
"storeName": "四季青桥",
"addressDetail": "西四环北路117号北京欧尚超市F1、B1",
"pro": "Wi-Fi,礼品卡,生日餐会",
"provinceName": "北京市",
"cityName": "北京市"
},
{
"rownum": 5,
"storeName": "亦庄",
"addressDetail": "北京经济开发区西环北路18号F1+F2",
"pro": "24小时,Wi-Fi,礼品卡,生日餐会",
"provinceName": "北京市",
"cityName": "北京市"
},
{
"rownum": 6,
"storeName": "石园南大街",
"addressDetail": "通顺路石园西区南侧北京顺义西单商场石园分店一层、二层部分",
"pro": "24小时,Wi-Fi,店内参观,礼品卡,生日餐会",
"provinceName": "北京市",
"cityName": "北京市"
},
{
"rownum": 7,
"storeName": "北京南站",
"addressDetail": "北京南站候车大厅B岛201号",
"pro": "Wi-Fi,礼品卡",
"provinceName": "北京市",
"cityName": "北京市"
},
{
"rownum": 8,
"storeName": "北清路",
"addressDetail": "北京北清路1号146区",
"pro": "24小时,Wi-Fi,店内参观,礼品卡",
"provinceName": "北京市",
"cityName": "北京市"
},
{
"rownum": 9,
"storeName": "大红门新世纪肯德基餐厅",
"addressDetail": "海户屯北京新世纪服装商贸城一层南侧",
"pro": "Wi-Fi,点唱机,礼品卡",
"provinceName": "北京市",
"cityName": "北京市"
},
{
"rownum": 10,
"storeName": "巴沟",
"addressDetail": "巴沟路2号北京华联万柳购物中心一层",
"pro": "Wi-Fi,礼品卡,生日餐会",
"provinceName": "北京市",
"cityName": "北京市"
}
]
}
PS: 第一次记录学习过程,如有错误,欢迎指正哇~