【python爬虫】headless chrome + selemium,爬了一只大爬虫---酷传网用户评论数据实战(详细)
导读:
- 这篇文章提供了两种爬虫的运用实例,headless chrome + selenium和Requests爬取酷传网,python版本为3.7。这两种爬虫方法足够突破大多数网站的反爬虫技术。简单易学,建议做互联网运营岗产品岗的朋友了解下。
- CSDN上关于无头浏览器的博客,给出登录之后爬json数据的方案着实不多,这篇文章包含headless Chrome获得的string类型网页源码之后,如何进一步处理数据的方法(希望对初学者有启发)。
- 代码没有面向对象编程,在后期的迭代中会改进。
故事背景:
我上星期参加互联网运营和产品岗网课的时候,教课的大佬给我们布置任务,去收集一款叫“foodie”的APP的用户评论。
我第一念头是我可以通过安卓模拟器和fiddler抓包,直接爬各大app应用商店的数据,简单粗暴直接。
然而当我都打开了pycharm, 导入了各种包之后,大佬却突然给我发了个网址,还留了一句话:“手机评论上酷传网啊。”
。。我当时内心是有点宕机的
于是。。。咦!这网站它就是一只大爬虫啊。
 这个网站的数据应该是通过我上面的说的那种方法,从安卓模拟器里爬取各大应用商店获得。
这个网站的数据应该是通过我上面的说的那种方法,从安卓模拟器里爬取各大应用商店获得。
 (更好玩的是它这个数据是打包好的,登陆付费直接可以“导出数据”(一次三个文件)。我只好忍痛付费7元买了个24小时会员,算是致敬了这变现了爬虫技术的大佬,开发不易。我还没学到并发,多线程,分布式爬虫的技术,酷传网具体是怎么实现这种大规模高密度爬APP的,技术细节我还真说不上来。如果有大佬知道请给我留个言哈。)
(更好玩的是它这个数据是打包好的,登陆付费直接可以“导出数据”(一次三个文件)。我只好忍痛付费7元买了个24小时会员,算是致敬了这变现了爬虫技术的大佬,开发不易。我还没学到并发,多线程,分布式爬虫的技术,酷传网具体是怎么实现这种大规模高密度爬APP的,技术细节我还真说不上来。如果有大佬知道请给我留个言哈。)
想想这不成啊,我都已经开始技痒了,这时再让我收手直接从页面下载,不能忍啊忍不能啊。。。而且我这两天还真就刚好就配置了headless Chrome。。
说实话,我写python爬虫代码的次数也不算少,对付这种需要登陆的网站大多是先登陆,然后用Request库带cookies,获取相应数据。还从来没尝试过用无头浏览器登录,获取网页源码。看着这个大爬虫网站我突然有点兴奋了,也不管会不会有点南辕北辙的意思,反正我要用python 代码从这个网站一次性获得我要的数据!而不是在网站上每次三个包,分多次下载(主要是验证无头浏览器的登录网页的过程)。
无头浏览器是爬虫界比较异端的一种方案,大致原理是控制一个没有界面的浏览器去访问网站,需要获得网页源码的方式筛选需要的数据。
相比于Urllib和Requests等库和Scrapy框架,无头浏览器确实存在数据爬取效率低,环境配置流程复杂坑多,对耐心不足的用户极端不友好。但是无头浏览器的优势也是很明显的,它就是一个完整的浏览器,能够保留用户的信息,实现自动登陆,持续保持对话信息,是浏览器自动化中重要的组成部分
———————这是一条华丽分割线—————————————
进入正题
我的思路很简单
一. 无头浏览器方法:
通过Chrome打开”酷传网“登录界面,输入账号密码登录,然后用fiddler获取“foodie”的评论区数据包,找到链接接口,一步爬取数据
虽然原理简单,但是真正写起来,这个过程里的坑多的可怕。一个坑过不去,还不一定有绕行的方案。这个我们一边看代码一边聊。
import json
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from time import sleep
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--disable-gpu")
#无头浏览器驱动地址
path = "./chromedriver.exe"
#数据池
data_pool = {}
#通过无头浏览器打开“酷传网”登录界面
browser = webdriver.Chrome(executable_path = path, options=chrome_options)
#browser.set_window_size(1366,768)
url = r"http://user.kuchuan.com/user/login?redirect_uri=http%3A%2F%2Fwww.kuchuan.com%2F"
browser.get(url)
print(browser.title)
sleep(3)
#输入登录信息
#昵称/邮箱/手机号码 框
log_in1 = browser.find_element_by_xpath("/html/body/div[2]/div[2]/div/div[1]/div[1]/input")
log_in1.send_keys("“输入用户名”")
#密码输入框
log_in2 = browser.find_element_by_xpath("/html/body/div[2]/div[2]/div/div[1]/div[2]/input")
log_in2.send_keys("输入密码")
#点击登录按钮
log_in_submit = browser.find_element_by_id("login")
log_in_submit.click()
#等待网页加载五秒
sleep(5)
#从Fiddler抓包到的网址,直接获得评论数据
#渠道厂商池
phone_markets = ["360","baidu", "yingyongbao", "wandoujia", "xiaomi","huawei","oppo", "vivo", "meizu", "lianxiang"]
for item in phone_markets:
print(item)
json_url = "http://android.kuchuan.com/commentdetail?packagename=com.linecorp.foodcamcn.android&market="+item+"&score=1%2C2%2C3%2C4%2C5&index=1&count=1000&date=1552205030135"
sleep(2)
browser.get(json_url)
#获取网页源码
kfc = browser.page_source
#处理无头浏览器爬下来的string数据,去除首尾非字典类型部分代码
ak47 = kfc.split('wrap;">',1)[1].split('<',1)[0]
#用Json模块将处理后的字符转换成字典/json格式
arrayojb =json.loads(ak47)
print(type(arrayojb))
#通过字典的方法,进一步缩小取值范围
comment_list = arrayojb['data']['commentList']
print(comment_list)
full_data = []
#
#通过遍历字典,将数据按照五项标签写入CSV文件中
for a in range(len(comment_list)):
user_name =comment_list[a]['author_name']
marks =comment_list[a]['score']
user_ID =comment_list[a]['author_id']
time =comment_list[a]['time']
comment = comment_list[a]['content']
kuchau = {'用户名':user_name,"评分":marks,'作者ID':user_ID,'时间':time,'评论':comment}
full_data.append(kuchau)
保存地址 = './保存文件/{}.csv'.format(item)
with open(保存地址,"a",encoding="utf-8") as f4:
f4.write(str( user_name) + ","+ str(marks)+ "," + str(user_ID)+ "," + str(time) + ","+ str(comment))
f4.write("\n")
f4.close()
注意:
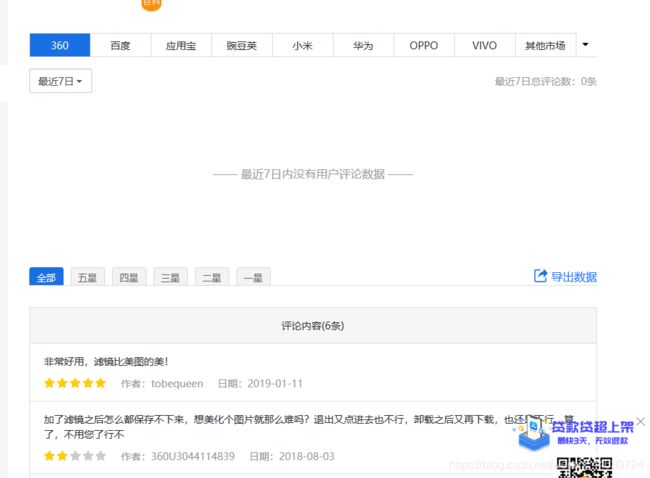
- 用webdriver爬下来的数据是这样的,以百度应用商店为例:

看起来很接近字典格式或者Json格式对不对,但是又好像多了点什么对不对?刚开始我先用正则表达式把里面的{}部分取出来,但是“当一个问题需要正则才能解决的时候,它其实是两个问题”。想了想,还是去掉头,掐掉尾,食用中间部分更可口。
我用了.split 语法去掉了多余的部分(ak47 = kfc.split(‘wrap;">’,1)[1].split(’<’,1)[0])。
然后问题就容易多了,json.loads()语法直接将爬到的数据变成了字典。

2. 将代码转为字典格式,主要是为了方便直接用字典的语法取出需要的值。这里不提倡使用jsonpath,Xpath等工具,否则就徒增计算量了。
- 评论的网址可以通过Fiddler抓包获得,这个commentdetail的包里面就是。

二. Requests模块方法:
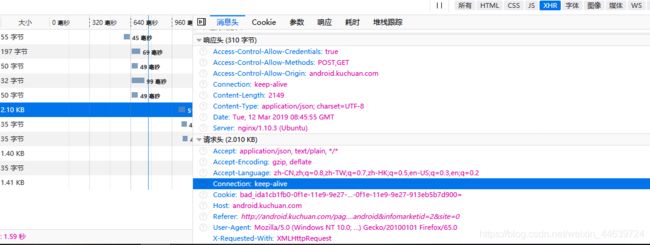
登录酷传网之后,获取网页cookie,用Request模块打开方法1中的数据接口,爬取数据。
cookies可以从火狐浏览器开发者工具里获取
import requests
import json
header = {'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Cookie': 'bad_ida1cb1fb0-0f1e-11e9-9e27-913eb5b7d900=aeca8851-4497-11e9-97f3-9f4ac7baf8ce; nice_ida1cb1fb0-0f1e-11e9-9e27-913eb5b7d900=aeca8852-4497-11e9-97f3-9f4ac7baf8ce; JSESSIONID=195vu9lpmnjwu1r4h11lxkg7rg; _qddaz=QD.tp21f8.jk27k2.jt5g8e2c; uname=13269917729; uid=541927; bcelin=+%23%24%5C%25%5E%28%28%5D%24%22%25%21%5C%5C%24%5E%5E%25%5C; _Coolchuan_com_session=BAh7C0kiCW1zZ3MGOgZFVDA6EmxvZ2luX2FjY291bnRJIhAxMzI2OTkxNzcyOQY7AFRJIhl3YXJkZW4udXNlci51c2VyLmtleQY7AFRbCEkiCVVzZXIGOwBGWwZpA%2BdECEkiIiQyYSQxMCQ4dTZMeDBKc0hHSHBFVWxhc1hneEJPBjsAVDoRc2lnbl9pbl9ob3N0IhZ3d3cuY29vbGNodWFuLmNvbToOdXNlcl9pbmZvewg6DHVzZXJfaWRpA%2BdECDoHc2siJTFiMmNlZGIxMTgyMDdiYjIwYmViOTU4Y2JhZjQyZjVmOgplbWFpbEkiN2t1Y2h1YW50ZW1wXzEzMjY5OTE3NzI5XzIwMTkwMzA4MTUyMl9QQGt1Y2h1YW4uY29tBjsAVEkiD3Nlc3Npb25faWQGOwBGSSIlMGZjYzNiNjUxMDFmY2M0YzkxNDE5YzhhMGQ5ZmQ3NjkGOwBU--3a3dd5fd22c509bdd900e806c04d99c09fa021f0; kc_ac=13269917729@#@#MUj7JeySimwlw6Rm0VLp8OUqtvrq4RVg; mm=JSm7lGZpyWKxXCXaw8CL1Q==; JSESSIONID=1duuvao922exhmei11kb2rd7h; token=d980877e388d759af48e4e73e6c5e66b; sign=gstHT4rOV22%2Bl%2Bx6H4%2FckFq82fMw9TwgkdQvpTJrX1UjsZkGdteFbSlmtGlwtTorwqmUjX2GhwPilm4VhNpbs3L%2FSSE%2FuawQOPmXZtnAJyL1kXLdc3BaNmIwBRqPhdUDa6mf7Thr9vDVzFfubT4Yc9BORgTK0mke6JHKY27BVNg%3D; href=http%3A%2F%2Fandroid.kuchuan.com%2Fpage%2Fdetail%2FsearchResult%3Fkw%3Dfoodie%26site%3D0; accessId=a1cb1fb0-0f1e-11e9-9e27-913eb5b7d900; pageViewNum=15; qimo_seosource_a1cb1fb0-0f1e-11e9-9e27-913eb5b7d900=%E7%AB%99%E5%86%85; qimo_seokeywords_a1cb1fb0-0f1e-11e9-9e27-913eb5b7d900=',
'Host': 'android.kuchuan.com',
'Referer':'http://android.kuchuan.com/page/detail/comment?package=com.linecorp.foodcamcn.android&infomarketid=2&site=0',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
#从Fiddler抓包到的网址,直接获得评论数据
#渠道厂商池
phone_markets = ["360","baidu", "yingyongbao", "wandoujia", "xiaomi","huawei","oppo", "vivo", "meizu", "lianxiang"]
for item in phone_markets:
print(item)
json_url = "http://android.kuchuan.com/commentdetail?packagename=com.linecorp.foodcamcn.android&market="+item+"&score=1%2C2%2C3%2C4%2C5&index=1&count=1000&date=1552205030135"
#获取网页源码
AK47 = requests.get(json_url, headers=header, stream=True)
M16 = AK47.text
# 用Json模块将处理后的字符转换成字典/json格式
arrayojb = json.loads(M16)
print(type(arrayojb))
# 通过字典的方法,进一步缩小取值范围
comment_list = arrayojb['data']['commentList']
full_data = []
#
#通过遍历字典,将数据按照五项标签写入CSV文件中
for a in range(len(comment_list)):
user_name =comment_list[a]['author_name']
marks =comment_list[a]['score']
user_ID =comment_list[a]['author_id']
time =comment_list[a]['time']
comment = comment_list[a]['content']
kuchau = {'用户名':user_name,"评分":marks,'作者ID':user_ID,'时间':time,'评论':comment}
full_data.append(kuchau)
保存地址 = './desktop/{}.csv'.format(item)
with open(保存地址,"a",encoding="utf-8") as f4:
f4.write(str( user_name) + ","+ str(marks)+ "," + str(user_ID)+ "," + str(time) + ","+ str(comment))
f4.write("\n")
f4.close()
注意:1. 这段代码里的M16 = AK47是必须的,建议不要去除,否则会如下图报错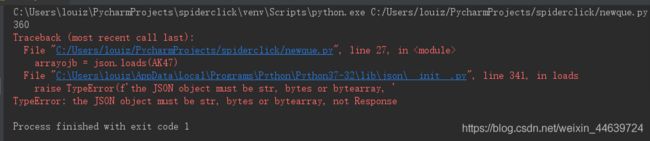
总结:
对于刚学完python基础语法的朋友,希望进阶做个小项目加强自己对python运用能力的话,爬虫会是一个非常合适的选择。以上两种方法都只是最简单的爬虫方法,连爬虫工程师的入门门槛都没够到。但对于互联网运营和产品经理等岗位来说,已经可以在某些场景下大幅度提升工作效率。本来是想在这篇文章中,进一步尝试词云图和数据可视化的,但是时间有限,我还是留着在后期的博客中更新吧。
我的python完全就是自学的,有诸多的知识点还不是很熟练,代码也非常稚嫩。希望能得到各位的指点!!谢谢