python每隔几秒执行一次_python定时任务最强框架APScheduler详细教程
APScheduler定时任务
上次测试女神听了我的建议,已经做好了要给项目添加定时任务的决定了。但是之前提供的四种方式中,她不知道具体选择哪一个。为了和女神更近一步,我把我入行近10年收藏的干货免费拿出来分享给女神,希望女神凌晨2点再找我的时候,不再是因为要给他调程序了。
Python中定时任务的解决方案,总体来说有四种,分别是:crontab、 scheduler、 Celery、 APScheduler,其中 crontab不适合多台服务器的配置、scheduler太过于简单、 Celery依赖的软件比较多,比较耗资源。最好的解决方案就是 APScheduler。
APScheduler使用起来十分方便。提供了基于日期、固定时间间隔以及 crontab类型的任务。还可以在程序运行过程中动态的新增任务和删除任务。在任务运行过程中,还可以把任务存储起来,下次启动运行依然保留之前的状态。另外最重要的一个特点是,因为他是基于 Python语言的库,所以是可以跨平台的,一段代码,处处运行!
在这里我来给大家详细介绍一下具体的用法。
一、安装:
安装非常简单,通过 pip install apscheduler即可。
二、基本使用:
先来看一段代码,然后再来给大家详细讲解其中的细节:
from apscheduler.schedulers.blocking import BlockingScheduler
from datetime import datetime
def my_clock():
print("Hello! The time is:%s"%datetime.now())
if __name__ == '__main__':
scheduler = BlockingScheduler()
scheduler.add_job(my_clock, "interval", seconds=3)
scheduler.start()
其中 BlockingScheduler是阻塞性的调度器,是最基本的调度器,下面调用 start方法就会阻塞当前进程,所以如果你的程序除了调度进程没有其他后台进程,那么是可以是否的,否则这个调度器会阻塞你程序的正常执行。
接下来就是定义一个 my_clock函数,这个函数就是需要定时调度的任务代码。
然后就是实例化一个 BlockingScheduler对象,并把 my_clock添加到任务调度中。然后看 interval参数,这里用的是间隔的方式来调度,调度频率是 seconds=3,也就是每3秒执行一次。
执行结果如下:
可以看到每隔3秒钟的时间会执行一次。说明定时任务已经成功执行了!
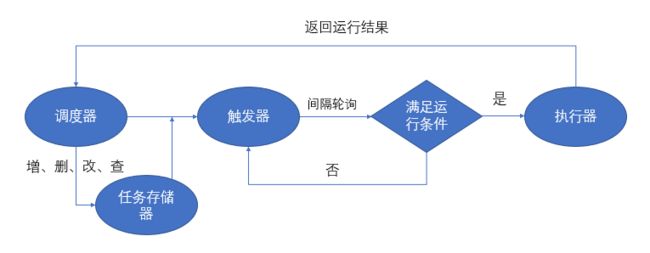
在了解了 APScheduler的基本使用后,再来对 APScheduler的四个基本对象做个了解,这样才能从全局掌握 APScheduler。
三、四个基本对象:
1. 触发器(triggers):
触发器就是根据你指定的触发方式,比如是按照时间间隔,还是按照 crontab触发,触发条件是什么等。每个任务都有自己的触发器。
2. 任务存储器(job stores):
任务存储器是可以存储任务的地方,默认情况下任务保存在内存,也可将任务保存在各种数据库中。任务存储进去后,会进行序列化,然后也可以反序列化提取出来,继续执行。
3. 执行器(executors):
执行器的目的是安排任务到线程池或者进程池中运行的。
4. 调度器(schedulers):
任务调度器是属于整个调度的总指挥官。他会合理安排作业存储器、执行器、触发器进行工作,并进行添加和删除任务等。调度器通常是只有一个的。开发人员很少直接操作触发器、存储器、执行器等。因为这些都由调度器自动来实现了。
四、触发器:
触发器有两种,第一种是 interval,第二种是 crontab。interval可以具体指定多少时间间隔执行一次。crontab可以指定执行的日期策略。以下分别进行讲解。
1. date触发器:
在某个日期时间只触发一次事件。示例代码如下:
from datetime import date
from apscheduler.schedulers.blocking import BlockingScheduler
sched = BlockingScheduler()
def my_job(text):
print(text)
sched.add_job(my_job, 'date', run_date=date(2020, 5, 22), args=['text'])
sched.start()
更多请参考:https://apscheduler.readthedocs.io/en/stable/modules/triggers/date.html
2. interval触发器:
想要在固定的时间间隔触发事件。interval的触发器可以设置以下的触发参数:
weeks:周。整形。days:一个月中的第几天。整形。hours:小时。整形。minutes:分钟。整形。seconds:秒。整形。start_date:间隔触发的起始时间。end_date:间隔触发的结束时间。jitter:触发的时间误差。
def cron_task():
scheduler = BlockingScheduler()
scheduler.add_job(tick,"cron",hour=11,minute=24)
scheduler.start()
在每天的11点24分触发事件。更多请参考:https://apscheduler.readthedocs.io/en/stable/modules/triggers/interval.html
3. crontab触发器:
在某个确切的时间周期性的触发事件。可以使用的参数如下:
year:4位数字的年份。month:1-12月份。day:1-31日。week:1-53周。day_of_week:一个礼拜中的第几天(0-6或者mon、tue、wed、thu、fri、sat、sun)。hour:0-23小时。minute:0-59分钟。second:0-59秒。start_date:datetime类型或者字符串类型,起始时间。end_date:datetime类型或者字符串类型,结束时间。timezone:时区。jitter:任务触发的误差时间。
也可以用表达式类型,可以用以下方式:
| 表达式 | 字段 | 描述 |
|---|---|---|
* |
任何 | 在每个值都触发 |
*/a |
任何 | 每隔 a触发一次 |
a-b |
任何 | 在 a-b区间内任何一个时间触发( a必须小于 b) |
a-b/c |
任何 | 在 a-b区间内每隔 c触发一次 |
xth y |
day |
第 x个星期 y触发 |
lastx |
day |
最后一个星期 x触发 |
last |
day |
一个月中的最后一天触发 |
x,y,z |
任何 | 可以把上面的表达式进行组合 |
示例如下:
def cron_task():
scheduler = BlockingScheduler()
scheduler.add_job(tick,"cron",day="4th sun",hour=20,minute=1)
scheduler.start()
五、调度器:
BlockingScheduler:适用于调度程序是进程中唯一运行的进程,调用start函数会阻塞当前线程,不能立即返回。BackgroundScheduler:适用于调度程序在应用程序的后台运行,调用start后主线程不会阻塞。AsyncIOScheduler:适用于使用了asyncio模块的应用程序。GeventScheduler:适用于使用gevent模块的应用程序。TwistedScheduler:适用于构建Twisted的应用程序。QtScheduler:适用于构建Qt的应用程序。
六、任务存储器:
任务存储器的选择有两种。一是内存,也是默认的配置。二是数据库。使用内存的方式是简单高效,但是不好的是,一旦程序出现问题,重新运行的话,会把之前已经执行了的任务重新执行一遍。数据库则可以在程序崩溃后,重新运行可以从之前中断的地方恢复正常运行。有以下几种选择:
MemoryJobStore:没有序列化,任务存储在内存中,增删改查都是在内存中完成。SQLAlchemyJobStore:使用SQLAlchemy这个ORM框架作为存储方式。MongoDBJobStore:使用mongodb作为存储器。RedisJobStore:使用redis作为存储器。
七、执行器:
执行器的选择取决于应用场景。通常默认的 ThreadPoolExecutor已经在大部分情况下是可以满足我们需求的。如果我们的任务涉及到一些 CPU密集计算的操作。那么应该考虑 ProcessPoolExecutor。然后针对每种程序, apscheduler也设置了不同的 executor:
ThreadPoolExecutor:线程池执行器。ProcessPoolExecutor:进程池执行器。GeventExecutor:Gevent程序执行器。TornadoExecutor:Tornado程序执行器。TwistedExecutor:Twisted程序执行器。AsyncIOExecutor:asyncio程序执行器。
八、定时任务调度配置:
这里我们用一个例子来说明。比如我想这样配置
执行器:
配置
default执行器为ThreadPoolExecutor,并且设置最多的线程数是20个。<
存储器:
配置
default的任务存储器为SQLAlchemyJobStore(使用SQLite)。<
任务配置:
设置
coalesce为False:设置这个目的是,比如由于某个原因导致某个任务积攒了很多次没有执行(比如有一个任务是1分钟跑一次,但是系统原因断了5分钟),如果coalesce=True,那么下次恢复运行的时候,会只执行一次,而如果设置coalesce=False,那么就不会合并,会5次全部执行。max_instances=5:同一个任务同一时间最多只能有5个实例在运行。比如一个耗时10分钟的job,被指定每分钟运行1次,如果我max_instance值5,那么在第6~10分钟上,新的运行实例不会被执行,因为已经有5个实例在跑了。
那么代码如下:
from apscheduler.schedulers.blocking import BlockingScheduler
from datetime import datetime
from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore
from apscheduler.executors.pool import ThreadPoolExecutor
def interval_task():
jobstores = {
'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite')
}
executors = {
'default': ThreadPoolExecutor(20)
}
job_defaults = {
'coalesce': False,
'max_instances': 3
}
scheduler = BlockingScheduler(jobstores=jobstores,executors=executors,job_defaults=job_defaults)
scheduler.add_job(tick,"interval",minutes=1)
scheduler.start()
九、任务操作:
1. 添加任务:
使用 scheduler.add_job(job_obj,args,id,trigger,**trigger_kwargs)。
2. 删除任务:
使用 scheduler.remove_job(job_id,jobstore=None)。
3. 暂停任务:
使用 scheduler.pause_job(job_id,jobstore=None)。
4. 恢复任务:
使用 scheduler.resume_job(job_id,jobstore=None)。
5. 修改某个任务属性信息:
使用 scheduler.modify_job(job_id,jobstore=None,**changes)。
6. 修改单个作业的触发器并更新下次运行时间:
使用 scheduler.reschedule_job(job_id,jobstore=None,trigger=None,**trigger_args)
7. 输出作业信息:
使用 scheduler.print_jobs(jobstore=None,out=sys.stdout)
十、异常监听:
当我们的任务抛出异常后,我们可以监听到,然后把错误信息进行记录。示例代码如下:
from apscheduler.schedulers.blocking import BlockingScheduler
from apscheduler.events import EVENT_JOB_EXECUTED, EVENT_JOB_ERROR
import datetime
import logging
# 配置日志显示
logging.basicConfig(level=logging.INFO,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
datefmt='%Y-%m-%d %H:%M:%S',
filename='log1.txt',
filemode='a')
def aps_test(x):
print (datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'), x)
def date_test(x):
print(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'), x)
# 故意抛出异常
print (1/0)
def my_listener(event):
if event.exception:
print ('任务出错了!!!!!!')
else:
print ('任务照常运行...')
scheduler = BlockingScheduler()
scheduler.add_job(func=date_test, args=('一次性任务,会出错',), next_run_time=datetime.datetime.now() + datetime.timedelta(seconds=15), id='date_task')
scheduler.add_job(func=aps_test, args=('循环任务',), trigger='interval', seconds=3, id='interval_task')
# 配置任务执行完成和执行错误的监听
scheduler.add_listener(my_listener, EVENT_JOB_EXECUTED | EVENT_JOB_ERROR)
# 设置日志
scheduler._logger = logging
scheduler.start()
以上便是 APScheduler库的详细用法了。如果我们需要在项目中开一个定时功能,完全可以选择 APScheduler,轻量又功能强大。
这次女神再也不用2点跑到公司去加班啦~
您也可购买Python测试开发高级实战课程
