性能竞赛优秀项目 | 分得干脆、合得高效,用 Shuffle 优化 TiDB 算子
作者介绍:黄建博,云计算领域技术开发工程师;金灵, Shopee 软件研发工程师。
他们的队伍 huang-b 在性能竞赛中斩获一等奖,本文将介绍 Shuffle 优化 TiDB 算子项目的设计与实践过程。
在我们往常的印象中,分与合是一对矛盾的概念,但是这次比赛留给我们队伍一个很深刻的印象是,分与合是一对互相促进的矛盾,只有干净利落地分解,才能高效地合并。这种印象一方面来自于我们的参赛思路,我们选择的方向是使用 Shuffle 操作将算子的数据源拆分为多个独立的分区,然后通过并行计算来提升整体的吞吐,优化的过程就是寻找更合适的分解方式,追求更好的扩展性和计算性能,相关技术细节在正文中有详细介绍。另一方面,则是来自于我们的参赛体验。
我们的队伍有两位成员一位顾问,分散在国内三座不同的城市,比赛从开始到结束,我们没有机会线下交流过,全都是以 slack 和文档的形式进行合作,我们开玩笑说,在做一个分布式的比赛的同时,我们也是一支分布式的队伍。在这样一种受限的条件下,有两个因素对队伍的高效合作起了关键作用:其一是我们的顾问对任务做了干净利落的拆分,同样的思路应用到两个不同类型的算子上,使得我们可以花开两朵,各表一枝;其二就是 TiDB 整体高内聚低耦合的设计,从纵向的角度讲,就是 TiDB 清晰的分层设计使得我们的优化可以只关注解析器和执行器层面,而不必深入更底层的 TiKV 存储,从横向的角度讲,就是 TiDB 对分治和多态的充分实践使得我们可以只关注被优化的算子,而不必担心对其它算子产生副作用。
技术背景
我们的优化思路是使用 Shuffle 算子来实现 MergeJoin 算子和 StreamAggregation 算子的并行化。Shuffle 算子最先在 PR https://github.com/pingcap/tidb/pull/14238 中引入,用于并行化 Window 算子。图 1 展示的就是 Window 算子的并行化过程。
图中左侧是串行的 Window 算子,因为 Window 算子要求输入数据有序,所以在数据源和 Window 之间通常有一个 Sort 算子。图中右侧展示的是对应的 Shuffle 算子,为了完成并行计算,Window 算子和 Sort 算子都被复制了多份,每一份与一 ShuffleWorker 相对应,从数据源流入的数据由 Splitter 按哈希值拆分为独立的数据分区,发往不同的 ShuffleWorker ,最终各个 Window 算子的结果汇总后输出。图中所画箭头就是数据流动的方向,其中数据的分发和结果的汇总是通过 go channel 来实现的,其它数据流动都是父节点通过调用子节点的 Next 方法来获取的。图中虚线表示启动的协程,每个 ShuffleWorker 都会启动一个协程来完成自身的运算,同时 Splitter 也会启动一个协程来完成数据的分发。
题目链接:
1. ShuffleMergeJoin:https://github.com/pingcap/tidb/issues/14441
2. ShuffleStreamAgg:https://github.com/pingcap/tidb/issues/20651
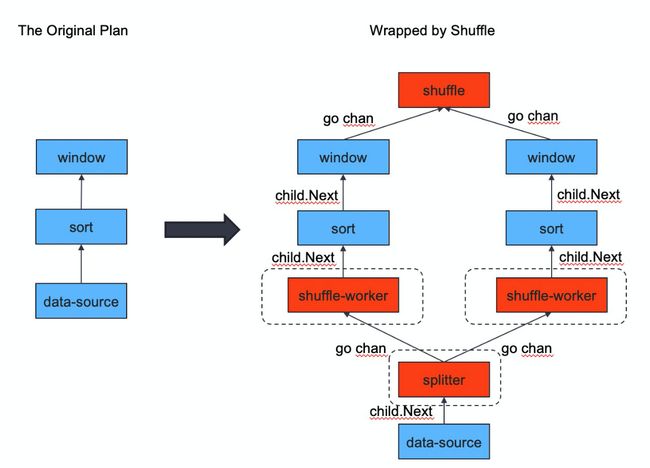
图 1 Window 算子并行化
ShuffleMergeJoin
扩展 Shuffle 算子
对 MergeJoin 做并行优化,是不是简单套用 ShuffleWindow 的框架就可以了呢?不是的,MergeJoin 算子与上文的 Window 算子不同,MergeJoin 需要两个数据源。那现在的 Shuffle 实现能不能让每个并行算子对应两个 ShuffleWorker ,进而对应两个数据源呢?答案也是不可以,因为前文提到的 Shuffle 实现把数据分区和计算并行这两个功能过度耦合在一起了,这种过度耦合使得它无法支持两个数据源。下面我们对这个问题作具体说明。
过度耦合指的是 ShuffleWorker 充当的角色太多,它既是数据流动的一环,同时也是计算并行的基本单元,于是带来了这两个问题:
1. 因为 ShuffleWorker 时数据分区,所以并行后的每个 MergeJoin 需要两个 ShuffleWorker 来接收来自两个数据源的数据,但是 ShuffleWorker 同时又是计算并行的基本单元,于是有 n 个 MergeJoin 算子就会出现 2n 个协程,同一个 MergeJoin 算子的两个协程还会出现数据竞争。
2. 控制逻辑复杂, ShuffleWorker 作为数据的一个分区,它必须作为 Sort 算子的子节点,而它作为计算并行的基本单元,又必须在协程中调用 Window 算子的 Next 方法来完成计算,所以在原来的实现往 ShuffleWorker 里放了个指向 Window 算子的指针,这样的设计一方面存在破坏执行树有向无环特性的隐患,另一方面也降低了代码的可读性。
当然,第一个问题我们可以通过在 ShuffleWorker 中增加一个布尔变量来解决:同一个 MergeJoin 对应的两个 ShuffleWorker 一个为 true,一个为 false,只有为 true 的那个才会启动协程。可是这个方法无疑会使上面提到的复杂的逻辑更加复杂。
**我们提出的解决方案是把数据分区和计算并行解耦。**如图 2 所示:计算并行还是由 ShuffleWorker 负责,但是它不再是数据流动过程中的一环,它原来在数据流动过程中的位置由 ShuffleReceiver 来代替。MergeJoin 是 ShuffleWorker 的一个成员,每个 ShuffleWorker 对应一个协程,在协程中调用 MergeJoin 的 Next 方法,并将结果发送给汇总算子,这样上文中提到的两个问题都得到了解决。
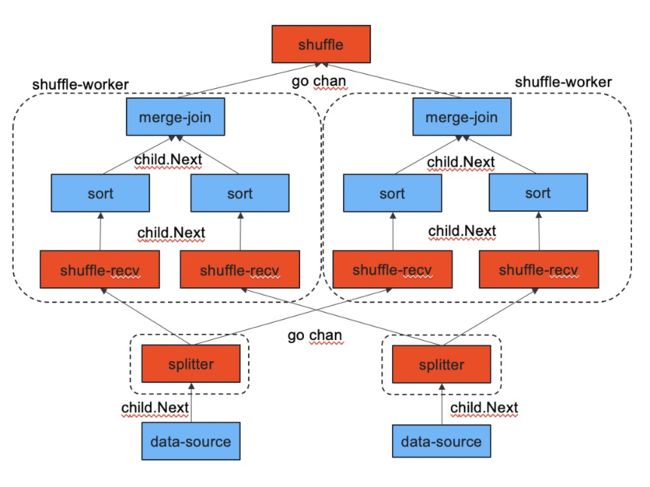
图 2 拓展后的 Shuffle 算子
相关 PR:https://github.com/pingcap/tidb/pull/20942
实现与效果
在实现中我们考虑两个场景:其一是数据源本身无序的情况,这种情况下数据进入 MergeJoin 之前要先经过 Sort 节点;另一是数据源本身有序的情况,这种情况下数据进入 MergeJoin 之前无需排序。

图 3 数据源无序情况下的 ShuffleMergeJoin
图 3 展示的就是数据源无序情况下 MergeJoin 的并行化过程,这种情况 MergeJoin 和 Sort 算子的计算开销都可以分摊到多个协程上。启动 2 个 worker 的优化效果如表 1 所示,我们在不同规模的数据源上都做了测试,表中前两列是两个数据源的行数,表中的后两列是串行和并行版本的运行性能,单位是 ns/op,越小性能越高。从表中可以看出, Shuffle 是可以明显加速 MergeJoin 运算的,并且数据量越大的情况下加速效果越好(因为并行化是会引入管道、协程等额外开销的,比较大的数据量才能保证并行化的收益大于开销)。在我们的几个测试案例中,效果最好的情况下 2 个 worker 的运算时间仅为串行版本的 56.5% 。
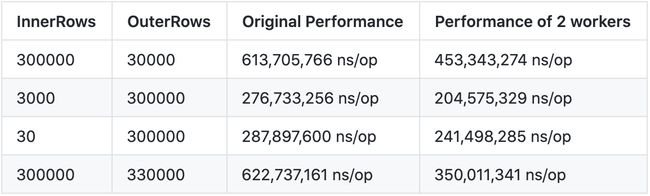
表 1 ShuffleMergeJoin 优化效果
图 4 展示的是数据源有序情况下 MergeJoin 的并行化过程,区别就是数据不再经过 Sort 算子。这种情况下计算的负载本身比较轻量,相比之下根据哈希值来分发数据的 Splitter 就成为了系统的性能瓶颈,并行化以后性能提升并不明显。

图 4 数据源有序情况下的 ShuffleMergeJoin
相关 PR:
1. ShuffleMergeJoin 实现:https://github.com/pingcap/tidb/pull/21255
2. 控制参数:https://github.com/pingcap/tidb/pull/21332
3. 单元测试与性能测试:https://github.com/pingcap/tidb/pull/21360
ShuffleStreamAggregation
聚合运算是 SQL 语句必不可少的一部分,无论是 OLTP 还是 OLAP 场景,聚合都是经常被使用到的算子。
从系统实现层面来看,聚合的实现一般有两种,第一种是基于 Hash 的方法,该方法通过构建 Hash table,维护每一个被聚合元素的值,计算得到最后的结果值。另外一种,则是基于有序数据流的方法,该方法要求输入数据源必须是有序的,然后通过遍历有序的数据流,并在同时维护相应的聚合值,即可得到最后的计算结果。
一般来说,基于 Hash 的方法具有更快的计算速度,但是它需要维护一个 Hash table,内存空间使用成本较高,当被聚合 key 的可能取值个数非常大的时候,那么相应 Hash table 中的元素个数也会非常多,对内存是个不小的考验,存在爆内存的风险,这反而导致计算不能正常地被完成。而基于有序数据流方法的聚合运算实现方式,无需随时都在内存中维护所有的被聚合 key 的值,因此内存使用量相对较小,但是它的运行速度相对而言更慢一点,且更为严格地要求输入数据必须是有序的。如果可以提升基于有序数据流方法的聚合算子的运行速度,那么该方法将会更加适用于大数据量的情况。因此我们选择对基于有序数据流方法的聚合运算实现方法,即 Stream Aggregation 进行并行加速,以提升该算子的整体运行速度。
实现与效果
在具体的实现过程中,我们利用了之前由其他社区贡献者提供的 Shuffle 算子,在 StreamAggregation 算子外围,将输入数据分割成多个有序的输入数据流,分别输入到多个 StreamAggregation 算子当中,然后通过简单的整合,得到最后的计算结果。简单地说,初始输入数据源 DataSource,首先会经过 Shuffle 算子,被分割成多个 Partition,且每个 Partition 都是其内部有序的,然后每个 Partition 分别被作为一 StreamAggregation 算子的输入,生成部分结果,最后通过对相同 key 的元素进行整合,即可得到最后的整体计算结果。
此处需要考虑 DataSource 是否有序的情况,如果 DataSource 在被聚合 key 上是无序的,比如普通的 PhysicalTableReader 算子,或其他算子的输出,那么需要在被分割之前,使得其有序,因此需要在其上添加一个 Sort 算子(如图 5 所示)。

图 5 数据源无序情况下的 ShuffleStreamAggregation
针对这种场景,我们的方法最后取得了非常明显的性能提升(如表 2 所示)。分析认为,非并行的情况下,Sort 作用在整个 DataSource 之上,而并行化的版本是作用在每个不同的 Partition 之上,输入相对较小,且并行执行,因此性能提升较大。
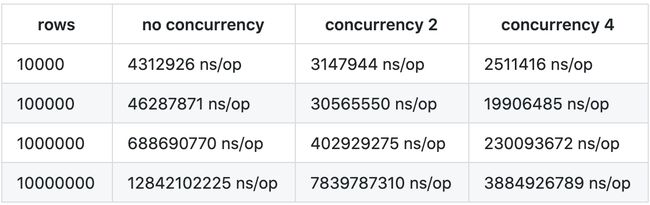
表 2 ShuffleStreamAggregation 优化效果
另外,还需要考虑 DataSource 在被聚合 key 上是有序的情况,比如下面的 SQL 语句,被聚合 key 为 b,且输入数据源 t 上刚好有由 b 创建的索引,因此在具体的计算过程中, DataSource 是基于 b 的 PhysicalIndexTableReader ,那么我们就无序引入 Sort 算子,直接将输入分割成多个 Partition,然后经过图 6 所示的计算过程即可得到结果。
create table t(a int, b int, key b(b));
select /*+ stream_agg() */ count(a) from t group by b;

图 6 数据源有序情况下的 ShuffleStreamAggregation
通过 Benchmark 的结果表明,在该情况下,目前的基于 Shuffle 的实现,运行速度并没有得到提升,反而有所下降,我们粗浅地认为,当前的 Shuffle 实现方式是瓶颈点,是后续需要被解决的重点。
相关 PR:
-
https://github.com/pingcap/tidb/pull/20658
-
https://github.com/pingcap/tidb/pull/21095
RangeSplitter
上面说了, Shuffle 算子会把数据输入分割成多个 Partition,最开始的时候只有基于 Hash 方法的 Splitter 被实现,该实现对输入数据是否有序并不做要求。对于数据源有序的情况,尽管该方法依旧适用,但是使用基于 Range 的方法对数据源进行分割,是一个更为自然的方式,因为被聚合 key 相同的多行数据,必然是紧挨在以前的,如果可以直接找到这一块数据的起始点和结束点,整体一次性分割,则无需构建 HashTable,也不用调用开销更为明显的 HashFunction,使得Partiton 过程的开销更小。基于这一思路,我们实现了 PartitionRangeSplitter,该方法的计算原理是,将紧挨一起的相同聚合 key 的多行数据,批量地分发到一个 worker 之上。相较于基于 Hash 方法的 Partitioner 而言,基于 Range 方法的实现方式的开销更小,在同时处理有序输入数据源的情况下,使用 RangePartitioner 能比使用 HashPartitioner 快上一倍的速度(详见表 3),由此证明了该算子更加适用于数据源有序的情况。
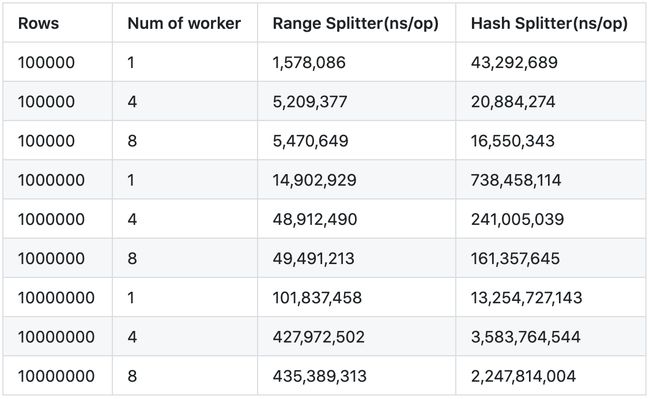
表 3 RangeSplitter 与 HashSplitter 性能比较
相关 PR:
1. RangeSplitter 实现:https://github.com/pingcap/tidb/pull/21306
2. 相关性能测试:https://github.com/pingcap/tidb/pull/21363
总结
在本次性能挑战大赛中,我们使用 Shuffle 算子对 MergeJoin 算子和 Stream Aggregation 算子进行了加速,在数据源无序的场景下,取得了明显的性能提升。在优化 MergeJoin 的过程中,为了适配多个数据源的算子,我们对现有的 Shuffle 实现做了扩展,提高了可读性和可扩展性。在优化 StreamAggregation 的过程中,考虑到数据源有序的情况,提出了一个简单的基于 Range 方法的 Splitter 实现,也证明了其有效性。我们在后续将会考虑如何对现有的 Shuffle 算子进行改造,消除其中存在的性能瓶颈,以期进一步提升基于 Shuffle 的一系列并行算子的性能。