深度学习系列1:框架pytorch
1. pytorch介绍
深度学习的框架基本都是基于计算图的,其中静态计算图先定义再运行(比如前面介绍的tensorflow),而动态图则是一边定义一边运行(比如本篇介绍的pytorch)。
pytorch的框架遵循张量tensor(从0.4起, Variable 正式合并入Tensor)->神经网络nn.Module的层次,比tensorflow简洁很多。
2. 基本概念总结
2.1 Tensor
Tensor和Numpy的ndarrays类似,但Tensor可以使用GPU进行加速。Tensor和Numpy共享内存,转换很快。
Tensor有不同的数据类型,每种类型分别对应有CPU和GPU版本(HalfTensor除外)。默认的tensor是FloatTensor,可通过t.set_default_tensor_type 来修改默认tensor类型(如果默认类型为GPU tensor,则所有操作都将在GPU上进行)。
2.1.2 内存管理
Tensor的类型对分析内存占用很有帮助。例如对于一个size为(1000, 1000, 1000)的FloatTensor,它有100010001000=10^9个元素,每个元素占32bit/8 = 4Byte内存,所以共占大约4GB内存/显存。HalfTensor是专门为GPU版本设计的,同样的元素个数,显存占用只有FloatTensor的一半,所以可以极大缓解GPU显存不足的问题,但由于HalfTensor所能表示的数值大小和精度有限,所以可能出现溢出等问题。

-
广播法则(broadcast)是科学运算中经常使用的一个技巧,它在快速执行向量化的同时不会占用额外的内存/显存。 Numpy的广播法则定义如下:
让所有输入数组都向其中shape最长的数组看齐,shape中不足的部分通过在前面加1补齐
两个数组要么在某一个维度的长度一致,要么其中一个为1,否则不能计算
当输入数组的某个维度的长度为1时,计算时沿此维度复制扩充成一样的形状 -
PyTorch当前已经支持了自动广播法则,但是笔者还是建议读者通过以下两个函数的组合手动实现广播法则,这样更直观,更不易出错:
unsqueeze或者view,或者tensor[None],:为数据某一维的形状补1,实现法则1
expand或者expand_as,重复数组,实现法则3;该操作不会复制数组,所以不会占用额外的空间。
注意,repeat实现与expand相类似的功能,但是repeat会把相同数据复制多份,因此会占用额外的空间。


t.set_num_threads可以设置PyTorch进行CPU多线程并行计算时候所占用的线程数,这个可以用来限制PyTorch所占用的CPU数目。
t.set_printoptions可以用来设置打印tensor时的数值精度和格式。 下面举例说明:
2.1.2 常用事项
get和set方法:一般来说,tensor的get和set方法同名,set方法会在后面多一个下划线,比如.requires_grad_( … )是set方法,而.requires_grad()是get方法。
数据拷贝:t.tensor()总是会进行数据拷贝,新tensor和原来的数据不再共享内存。所以如果你想共享内存的话,建议使用torch.from_numpy()或者tensor.detach()来新建一个tensor, 二者共享内存。
取数据:使用.item()可以获得一元tensor的值;二元tensor的值可以通过下标来获取;使用gather、index_select/masked_selected可以在选定维度上选择数据;PyTorch在0.2版本中完善了索引操作,目前已经支持绝大多数numpy的高级索引。高级索引可以看成是普通索引操作的扩展,但是高级索引操作的结果一般不和原始的Tensor共享内存。

自动微分:在新版本中,Tensor可以直接使用autograd功能(不需要再封装为Variable),只需要设置tensor.requries_grad=True。注意使用.backward进行反向传播时,如果输出变量不是标量,需要制定一个尺寸相同的tensor作为输入变量,当做每一个分量的权重。需要重新计算时,使用下面的方法将梯度清零:x.grad.data.zero_()
在预测的时候,可以关闭autograd功能,提高速度,节约内存,方法是:with t.no_grad()
运算符重载:Tensor的很多操作,例如div、mul、pow、fmod等,PyTorch都实现了运算符重载,所以可以直接使用运算符。如a ** 2 等价于torch.pow(a,2), a * 2等价于torch.mul(a,2)。Tensor的比较运算符也都实现了重载,比如a>=b、a>b、a!=b、a==b,其返回结果是一个ByteTensor,可用来选取元素。
改变尺寸:使用view、unsqueeze、squeeze、resize方法。需要注意的是,矩阵的转置会导致存储空间不连续,需调用它的.contiguous方法将其转为连续。
归并操作:此类操作会使输出形状小于输入形状,并可以沿着某一维度进行指定操作。大多数函数都有一个参数dim,用来指定这些操作是在哪个维度上执行的。关于dim(对应于Numpy中的axis)的解释众说纷纭,这里提供一个简单的记忆方式:假设输入的形状是(m, n, k),如果指定dim=0,输出的形状就是(1, n, k)或者(n, k);如果指定dim=1,输出的形状就是(m, 1, k)或者(m, k);如果指定dim=2,输出的形状就是(m, n, 1)或者(m, n)。size中是否有"1",取决于参数keepdim,keepdim=True会保留维度1。
- mean/sum/median/mode 均值/和/中位数/众数
- norm/dist 范数/距离
- std/var 标准差/方差
- cumsum/cumprod 累加/累乘
2.1.3 GPU
tensor可以很随意的在gpu/cpu上传输。使用tensor.cuda(device_id)或者tensor.cpu()。另外一个更通用的方法是tensor.to(device)。
Tensor的保存和加载十分的简单,使用t.save和t.load即可完成相应的功能。在save/load时可指定使用的pickle模块,在load时还可将GPU tensor映射到CPU或其它GPU上。

2.2 Network
2.2.1 数据结构
torch.nn的核心数据结构是Module,它是一个抽象概念,既可以表示神经网络中的某个层(layer),也可以表示一个包含很多层的神经网络。nn.Module基类的构造函数如下:
def __init__(self):
self._parameters = OrderedDict()
self._modules = OrderedDict()
self._buffers = OrderedDict()
self._backward_hooks = OrderedDict()
self._forward_hooks = OrderedDict()
self.training = True
其中每个属性的解释如下:
- _parameters:字典,保存用户直接设置的parameter,self.param = nn.Parameter(t.randn(3, 3))会被检测到,在字典中加入一个key为’param’,value为对应parameter的item。
- _modules:子module,通过self.submodel = nn.Linear(3, 4)指定的子module会保存于此。
- _buffers:缓存。如batchnorm使用momentum机制,每次前向传播需用到上一次前向传播的结果。
- _backward_hooks与_forward_hooks:钩子技术,用来提取中间变量,类似variable的hook。
- training:BatchNorm与Dropout层在训练阶段和测试阶段中采取的策略不同,通过判断training值来决定前向传播策略。
上述几个属性中,_parameters、_modules和_buffers这三个字典中的键值,都可以通过self.key方式获得,效果等价于self._parameters[‘key’].
2.2.2 定义方式
第一种方式,继承nn.Module类:
定义网络时,需要继承nn.Module,并实现它的forward方法,把网络中具有可学习参数的层放在构造函数__init__中。如果某一层(如ReLU)不具有可学习的参数,则既可以放在构造函数中,也可以不放,但建议不放在其中,而在forward中使用nn.functional代替。下面是LeNet的例子:
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
# nn.Module子类的函数必须在构造函数中执行父类的构造函数
# 下式等价于nn.Module.__init__(self)
super(Net, self).__init__()
# 卷积层 '1'表示输入图片为单通道, '6'表示输出通道数,'5'表示卷积核为5*5
self.conv1 = nn.Conv2d(1, 6, 5)
# 卷积层
self.conv2 = nn.Conv2d(6, 16, 5)
# 仿射层/全连接层,y = Wx + b
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# 卷积 -> 激活 -> 池化
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
# reshape,‘-1’表示自适应
x = x.view(x.size()[0], -1)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
print(net)
只要在nn.Module的子类中定义了forward函数,backward函数就会自动被实现(利用autograd)。forward函数的输入和输出都是Tensor。在forward 函数中可使用任何tensor支持的函数,还可以使用if、for循环、print、log等Python语法,写法和标准的Python写法一致。网络的可学习参数通过net.parameters()返回,net.named_parameters可同时返回可学习的参数及名称。
for name,parameters in net.named_parameters():
print(name,':',parameters.size())
输出为:
conv1.weight : torch.Size([6, 1, 5, 5])
conv1.bias : torch.Size([6])
conv2.weight : torch.Size([16, 6, 5, 5])
conv2.bias : torch.Size([16])
fc1.weight : torch.Size([120, 400])
fc1.bias : torch.Size([120])
fc2.weight : torch.Size([84, 120])
fc2.bias : torch.Size([84])
fc3.weight : torch.Size([10, 84])
fc3.bias : torch.Size([10])
第二种方式,类似keras,直接进行堆叠:
net2 = torch.nn.Sequential(
torch.nn.Linear(1, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 1)
)
2.2.3 网络使用
读取数据
通常来说,当你处理图像,文本,语音或者视频数据时,你可以使用标准 python 包将数据加载成 numpy 数组格式,然后将这个数组转换成 torch.*Tensor
- 对于图像,可以用 Pillow,OpenCV,还有自带的torchvision
- 对于语音,可以用 scipy,librosa
- 对于文本,可以直接用 Python 或 Cython 基础数据加载模块,或者用 NLTK 和 SpaCy
加载数据DataLoader
DataLoader 是 torch 给你用来包装你的数据的工具. 所以你要讲自己的 (numpy array 或其他) 数据形式装换成 Tensor, 然后再放进这个包装器中. 使用 DataLoader 有什么好处呢? 就是他们帮你有效地迭代数据。
下面是使用方法:
import torch
import torch.utils.data as Data
torch.manual_seed(1) # reproducible
BATCH_SIZE = 5 # 批训练的数据个数
x = torch.linspace(1, 10, 10) # x data (torch tensor)
y = torch.linspace(10, 1, 10) # y data (torch tensor)
# 先转换成 torch 能识别的 Dataset
torch_dataset = Data.TensorDataset(x,y)
# 把 dataset 放入 DataLoader
loader = Data.DataLoader(
dataset=torch_dataset, # torch TensorDataset format
batch_size=BATCH_SIZE, # mini batch size
shuffle=True, # 要不要打乱数据 (打乱比较好)
num_workers=2, # 多线程来读数据
)
for epoch in range(3): # 训练所有!整套!数据 3 次
for step, (batch_x, batch_y) in enumerate(loader): # 每一步 loader 释放一小批数据用来学习
# 假设这里就是你训练的地方...
# 打出来一些数据
print('Epoch: ', epoch, '| Step: ', step, '| batch x: ',
batch_x.numpy(), '| batch y: ', batch_y.numpy())
核心就是对torch数组再进行一次包装,定义为Data.TensorDataset格式。输出为:
tensor([ 1., 2., 3., 4., 5., 6., 7., 8., 9., 10.]) tensor([10., 9., 8., 7., 6., 5., 4., 3., 2., 1.])
Epoch: 0 | Step: 0 | batch x: [ 5. 7. 10. 3. 4.] | batch y: [6. 4. 1. 8. 7.]
Epoch: 0 | Step: 1 | batch x: [2. 1. 8. 9. 6.] | batch y: [ 9. 10. 3. 2. 5.]
Epoch: 1 | Step: 0 | batch x: [ 4. 6. 7. 10. 8.] | batch y: [7. 5. 4. 1. 3.]
Epoch: 1 | Step: 1 | batch x: [5. 3. 2. 1. 9.] | batch y: [ 6. 8. 9. 10. 2.]
Epoch: 2 | Step: 0 | batch x: [ 4. 2. 5. 6. 10.] | batch y: [7. 9. 6. 5. 1.]
Epoch: 2 | Step: 1 | batch x: [3. 9. 1. 8. 7.] | batch y: [ 8. 2. 10. 3. 4.]
前向传递forward
调用forward方法和直接将input做参数得到的结果是一样的。
input = t.randn(1, 1, 32, 32)
out1 = net(input)
out2 = net.forward(input)
net.zero_grad() # 所有参数的梯度清零
out1.backward(t.ones(1,10)) # 反向传播
需要注意的是,torch.nn只支持mini-batches,不支持一次只输入一个样本,即一次必须是一个batch。但如果只想输入一个样本,则用 input.unsqueeze(0)将batch_size设为1。
损失函数
nn实现了神经网络中大多数的损失函数,例如nn.MSELoss用来计算均方误差,nn.CrossEntropyLoss用来计算交叉熵损失。
优化器
在反向传播计算完所有参数的梯度后,还需要使用优化方法来更新网络的权重和参数,例如随机梯度下降法(SGD)的更新策略如下:
weight = weight - learning_rate * gradient
torch.optim中实现了深度学习中绝大多数的优化方法,例如RMSProp、Adam、SGD等。优化器一般要指定要调整的参数和学习率,日不optimizer = optim.SGD(net.parameters(), lr = 0.01),更新参数用optimizer.step()即可。下面是使用方法:
import torch.optim as optim
optimizer = optim.SGD(net.parameters(), lr=0.01)
optimizer.zero_grad() # zero the gradient buffers
output = net(input)
loss = criterion(output, target)
loss.backward()
optimizer.step() # Does the update
GPU加速
用如下方式将代码转移到GPU上运行:
device = t.device("cuda:0" if t.cuda.is_available() else "cpu")
net.to(device)
images = images.to(device)
labels = labels.to(device)
保存和读取模型
在PyTorch中保存模型十分简单,所有的Module对象都具有state_dict()函数,返回当前Module所有的状态数据。将这些状态数据保存后,下次使用模型时即可利用model.load_state_dict()函数将状态加载进来。优化器(optimizer)也有类似的机制,不过一般并不需要保存优化器的运行状态。
# 保存模型
t.save(net.state_dict(), 'net.pth')
# 加载已保存的模型
net2 = Net()
net2.load_state_dict(t.load('net.pth'))
2.3 function和module
nn中还有一个很常用的模块:nn.functional,nn中的大多数layer,在functional中都有一个与之相对应的函数。nn.functional中的函数和nn.Module的主要区别在于,用nn.Module实现的layers是一个特殊的类,都是由class layer(nn.Module)定义,会自动提取可学习的参数。而nn.functional中的函数更像是纯函数,由def function(input)定义。如果模型有可学习的参数,最好用nn.Module,否则既可以使用nn.functional也可以使用nn.Module,二者在性能上没有太大差异。
下面是module的典型写法
import torch as t
from torch import nn
class Linear(nn.Module): # 继承nn.Module
def __init__(self, in_features, out_features):
super(Linear, self).__init__() # 等价于nn.Module.__init__(self)
self.w = nn.Parameter(t.randn(in_features, out_features))
self.b = nn.Parameter(t.randn(out_features))
def forward(self, x):
x = x.mm(self.w) # x.@(self.w)
return x + self.b.expand_as(x)
自定义层Linear必须继承nn.Module,并且在其构造函数中需调用nn.Module的构造函数,即super(Linear, self).init() 或nn.Module.init(self),推荐使用第一种用法,尽管第二种写法更直观。
在构造函数__init__中必须自己定义可学习的参数,并封装成Parameter,如在本例中我们把w和b封装成parameter。parameter是一种特殊的Tensor,但其默认需要求导(requires_grad = True),感兴趣的读者可以通过nn.Parameter??,查看Parameter类的源代码。
forward函数实现前向传播过程,其输入可以是一个或多个tensor。
无需写反向传播函数,nn.Module能够利用parameter的autograd自动实现反向传播,这点比Function简单许多。
使用时,直观上可将layer看成数学概念中的函数,调用layer(input)即可得到input对应的结果。它等价于layers.call(input),在__call__函数中,主要调用的是 layer.forward(x),另外还对钩子做了一些处理。所以在实际使用中应尽量使用layer(x)而不是使用layer.forward(x),关于钩子技术将在下文讲解。
Module中的可学习参数可以通过named_parameters()或者parameters()返回迭代器,前者会给每个parameter都附上名字,使其更具有辨识度。
可见利用Module实现的全连接层,比利用Function实现的更为简单,因其不再需要写反向传播函数。
多层感知机的网络结构如图4-1所示,它由两个全连接层组成,采用 函数作为激活函数,图中没有画出。

class Perceptron(nn.Module):
def __init__(self, in_features, hidden_features, out_features):
nn.Module.__init__(self)
self.layer1 = Linear(in_features, hidden_features) # 此处的Linear是前面自定义的全连接层
self.layer2 = Linear(hidden_features, out_features)
def forward(self,x):
x = self.layer1(x)
x = t.sigmoid(x)
return self.layer2(x)
2.4 反向求导
如表达式 = + 可分解为 = 和 = + ,其计算图如图3-3所示,图中MUL,ADD都是算子, , , 即变量。在反向传播过程中,autograd沿着这个图从当前变量(根节点 )溯源,可以利用链式求导法则计算所有叶子节点的梯度。每一个前向传播操作的函数都有与之对应。

有了计算图,上述链式求导即可利用计算图的反向传播自动完成,其过程如图所示。

下面是使用方式:
2.4.1 打开求导
# 下面三种方式是一样的
a = t.randn(3,4, requires_grad=True)
a = t.randn(3,4).requires_grad_()
a = t.randn(3,4)
a.requires_grad=True
2.4.2 计算梯度
求 x x x的关于 y = f ( x ) y=f(x) y=f(x)的梯度,首先设置声明tensor类型变量 x x x,声明的时候需要设置参数requires_grad=True;接下来计算出 y = f ( x ) y=f(x) y=f(x),这里的 f f f是用来表示函数运算过程,最后使用 y . b a c k w a r d ( ) y.backward() y.backward(),如果 y y y非标量,就加个参数,假设为 v v v, v v v的形状与 y y y相同,此时使用的是 y . b a c k w a r d ( v ) y.backward(v) y.backward(v),要的梯度值可以通过 x . g r a d x.grad x.grad获得(注意只有叶子节点才有grad)。
x = t.ones(1)
b = t.rand(1, requires_grad = True)
w = t.rand(1, requires_grad = True)
y = w * x # 等价于y=w.mul(x)
z = y + b # 等价于z=y.add(b)
z.backward(retain_graph=True) # 注意每次forward之后只能backward一次,如果要多次使用,需要加上retain_graph
print(t.autograd.grad(z,y)) # 非叶子节点使用这种方法,再计算一遍梯度
print(y.grad) # 非叶子节点(中间节点),梯度不保留
print(w.grad) # 叶子节点,保留梯度。
结果是
None
tensor([1.]),)
tensor([1.])
注意以下几点:
- 叶子节点的grad_fn为None。叶子节点中需要求导的tensor,具有AccumulateGrad标识,因其梯度是累加的。
- tensor默认是不需要求导的,即requires_grad属性默认为False,如果某一个节点requires_grad被设置为True,那么所有依赖它的节点requires_grad都为True。
- tensor的volatile属性默认为False,如果某一个tensor的volatile属性被设为True,那么所有依赖它的节点volatile属性都为True。volatile属性为True的节点不会求导,volatile的优先级比requires_grad高。
- 多次反向传播时,梯度是累加的。反向传播的中间缓存会被清空,为进行多次反向传播需指定retain_graph=True来保存这些缓存。
- tensor的grad与data形状一致(相当于对每一个分量进行求导,然后再组合起来),应避免直接修改tensor.data,因为对data的直接操作无法利用autograd进行反向传播
- 反向传播函数backward的参数grad_variables可以看成链式求导的中间结果,如果是标量,可以省略,默认为1。
- 梯度清零可以用optimizer.zero_grad() 或net.zero_grad()
2.5 优化器
每一轮迭代计算出来的梯度都不一样,使用不同的优化器更新梯度值,直到目标函数收敛。
# 为不同子网络设置不同的学习率,在finetune中经常用到
# 如果对某个参数不指定学习率,就使用最外层的默认学习率
optimizer =optim.SGD([
{
'params': net.features.parameters()}, # 学习率为1e-5
{
'params': net.classifier.parameters(), 'lr': 1e-2}
], lr=1e-5)
optimizer
3. 综合例子
下面使用多种方法构造神经网络:
3.1 最原始numpy版本
# -*- coding: utf-8 -*-
import numpy as np
# N是批量大小; D_in是输入维度;
# 49/5000 H是隐藏的维度; D_out是输出维度。
N, D_in, H, D_out = 64, 1000, 100, 10
# 创建随机输入和输出数据
x = np.random.randn(N, D_in)
y = np.random.randn(N, D_out)
# 随机初始化权重
w1 = np.random.randn(D_in, H)
w2 = np.random.randn(H, D_out)
learning_rate = 1e-6
for t in range(500):
# 前向传递:计算预测值y
h = x.dot(w1)
h_relu = np.maximum(h, 0)
y_pred = h_relu.dot(w2)
# 计算和打印损失loss
loss = np.square(y_pred - y).sum()
print(t, loss)
# 反向传播,计算w1和w2对loss的梯度
grad_y_pred = 2.0 * (y_pred - y)
grad_w2 = h_relu.T.dot(grad_y_pred)
grad_h_relu = grad_y_pred.dot(w2.T)
grad_h = grad_h_relu.copy()
grad_h[h < 0] = 0
grad_w1 = x.T.dot(grad_h)
# 更新权重
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2
3.2 使用tensor/loss/optim模块,可以用GPU,能自动求导
简单来说,就是tensor有auto_grad的功能,简化了反向传播步骤,直接一个backward函数就好了;此外net和tensor都可以to gpu,速度加快;nn层自带各种常见loss函数,optim有常见的更新策略,简化了代码。
# -*- coding: utf-8 -*-
import torch
dtype = torch.float
device = torch.device("cpu")
# device = torch.device(“cuda:0”)#取消注释以在GPU上运行
# N是批量大小; D_in是输入维度;
# H是隐藏的维度; D_out是输出维度。
N, D_in, H, D_out = 64, 1000, 100, 10
# 创建随机Tensors以保持输入和输出。
# 设置requires_grad = False表示我们不需要计算渐变
# 在向后传球期间对于这些Tensors。
x = torch.randn(N, D_in, device=device, dtype=dtype)
y = torch.randn(N, D_out, device=device, dtype=dtype)
# 为权重创建随机Tensors。
# 设置requires_grad = True表示我们想要计算渐变
# 在向后传球期间尊重这些张贴。
w1 = torch.randn(D_in, H, device=device, dtype=dtype, requires_grad=True)
w2 = torch.randn(H, D_out, device=device, dtype=dtype, requires_grad=True)
learning_rate = 1e-6
for t in range(500):
# 前向传播:使用tensors上的操作计算预测值y;
# 由于w1和w2有requires_grad=True,涉及这些张量的操作将让PyTorch构建计算图,
# 从而允许自动计算梯度。由于我们不再手工实现反向传播,所以不需要保留中间值的引用。
y_pred = x.mm(w1).clamp(min=0).mm(w2)
# 使用Tensors上的操作计算和打印丢失。
# loss是一个形状为()的张量
# loss.item() 得到这个张量对应的python数值
loss = (y_pred - y).pow(2).sum()
print(t, loss.item())
# 使用autograd计算反向传播。这个调用将计算loss对所有requires_grad=True的tensor的梯度。
# 这次调用后,w1.grad和w2.grad将分别是loss对w1和w2的梯度张量。
loss.backward()
# 使用梯度下降更新权重。对于这一步,我们只想对w1和w2的值进行原地改变;不想为更新阶段构建计算图,
# 所以我们使用torch.no_grad()上下文管理器防止PyTorch为更新构建计算图
with torch.no_grad():
w1 -= learning_rate * w1.grad
w2 -= learning_rate * w2.grad
# 反向传播后手动将梯度设置为零
w1.grad.zero_()
w2.grad.zero_()
我们也可以自定义算子:
这个例子中,我们自定义一个自动求导函数来展示ReLU的非线性。并用它实现我们的两层网络:
import torch
class MyReLU(torch.autograd.Function):
"""
我们可以通过建立torch.autograd的子类来实现我们自定义的autograd函数,
并完成张量的正向和反向传播。
"""
@staticmethod
def forward(ctx, x):
"""
在正向传播中,我们接收到一个上下文对象和一个包含输入的张量;
我们必须返回一个包含输出的张量,
并且我们可以使用上下文对象来缓存对象,以便在反向传播中使用。
"""
ctx.save_for_backward(x)
return x.clamp(min=0)
@staticmethod
def backward(ctx, grad_output):
"""
在反向传播中,我们接收到上下文对象和一个张量,
其包含了相对于正向传播过程中产生的输出的损失的梯度。
我们可以从上下文对象中检索缓存的数据,
并且必须计算并返回与正向传播的输入相关的损失的梯度。
"""
x, = ctx.saved_tensors
grad_x = grad_output.clone()
grad_x[x < 0] = 0
return grad_x
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# N是批大小; D_in 是输入维度;
# H 是隐藏层维度; D_out 是输出维度
N, D_in, H, D_out = 64, 1000, 100, 10
# 产生输入和输出的随机张量
x = torch.randn(N, D_in, device=device)
y = torch.randn(N, D_out, device=device)
# 产生随机权重的张量
w1 = torch.randn(D_in, H, device=device, requires_grad=True)
w2 = torch.randn(H, D_out, device=device, requires_grad=True)
learning_rate = 1e-6
for t in range(500):
# 正向传播:使用张量上的操作来计算输出值y;
# 我们通过调用 MyReLU.apply 函数来使用自定义的ReLU
y_pred = MyReLU.apply(x.mm(w1)).mm(w2)
# 计算并输出loss
loss = (y_pred - y).pow(2).sum()
print(t, loss.item())
# 使用autograd计算反向传播过程。
loss.backward()
with torch.no_grad():
# 用梯度下降更新权重
w1 -= learning_rate * w1.grad
w2 -= learning_rate * w2.grad
# 在反向传播之后手动清零梯度
w1.grad.zero_()
w2.grad.zero_()
到目前为止,我们已经通过手动改变包含可学习参数的张量来更新模型的权重。对于随机梯度下降(SGD/stochastic gradient descent)等简单的优化算法来说,这不是一个很大的负担,但在实践中,我们经常使用AdaGrad、RMSProp、Adam等更复杂的优化器来训练神经网络。
import torch
# N是批大小;D是输入维度
# H是隐藏层维度;D_out是输出维度
N, D_in, H, D_out = 64, 1000, 100, 10
# 产生随机输入和输出张量
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
# 使用nn包定义模型和损失函数
model = torch.nn.Sequential(
torch.nn.Linear(D_in, H),
torch.nn.ReLU(),
torch.nn.Linear(H, D_out),
)
loss_fn = torch.nn.MSELoss(reduction='sum')
# 使用optim包定义优化器(Optimizer)。Optimizer将会为我们更新模型的权重。
# 这里我们使用Adam优化方法;optim包还包含了许多别的优化算法。
# Adam构造函数的第一个参数告诉优化器应该更新哪些张量。
learning_rate = 1e-4
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
for t in range(500):
# 前向传播:通过像模型输入x计算预测的y
y_pred = model(x)
# 计算并打印loss
loss = loss_fn(y_pred, y)
print(t, loss.item())
# 在反向传播之前,使用optimizer将它要更新的所有张量的梯度清零(这些张量是模型可学习的权重)
optimizer.zero_grad()
# 反向传播:根据模型的参数计算loss的梯度
loss.backward()
# 调用Optimizer的step函数使它所有参数更新
optimizer.step()
3.3 算子聚合成nn模块
简单来说,就是把常用算子组合封装。
# -*- coding: utf-8 -*-
import torch
# N是批大小;D是输入维度
# H是隐藏层维度;D_out是输出维度
N, D_in, H, D_out = 64, 1000, 100, 10
#创建输入和输出随机张量
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
# 使用nn包将我们的模型定义为一系列的层。
# nn.Sequential是包含其他模块的模块,并按顺序应用这些模块来产生其输出。
# 每个线性模块使用线性函数从输入计算输出,并保存其内部的权重和偏差张量。
# 在构造模型之后,我们使用.to()方法将其移动到所需的设备。
model = torch.nn.Sequential(
torch.nn.Linear(D_in, H),
torch.nn.ReLU(),
torch.nn.Linear(H, D_out),
)
# nn包还包含常用的损失函数的定义;
# 在这种情况下,我们将使用平均平方误差(MSE)作为我们的损失函数。
# 设置reduction='sum',表示我们计算的是平方误差的“和”,而不是平均值;
# 这是为了与前面我们手工计算损失的例子保持一致,
# 但是在实践中,通过设置reduction='elementwise_mean'来使用均方误差作为损失更为常见。
loss_fn = torch.nn.MSELoss(reduction='sum')
learning_rate = 1e-4
for t in range(500):
# 前向传播:通过向模型传入x计算预测的y。
# 模块对象重载了__call__运算符,所以可以像函数那样调用它们。
# 这么做相当于向模块传入了一个张量,然后它返回了一个输出张量。
y_pred = model(x)
# 计算并打印损失。
# 传递包含y的预测值和真实值的张量,损失函数返回包含损失的张量。
loss = loss_fn(y_pred, y)
print(t, loss.item())
# 反向传播之前清零梯度
model.zero_grad()
# 反向传播:计算模型的损失对所有可学习参数的导数(梯度)。
# 在内部,每个模块的参数存储在requires_grad=True的张量中,
# 因此这个调用将计算模型中所有可学习参数的梯度。
loss.backward()
# 使用梯度下降更新权重。反向传播的时候不需要自动计算梯度
# 每个参数都是张量,所以我们可以像我们以前那样可以得到它的数值和梯度
with torch.no_grad():
for param in model.parameters():
param -= learning_rate * param.grad
3.4 动态图
作为动态图和权重共享的一个例子,我们实现了一个非常奇怪的模型:一个全连接的ReLU网络,在每一次前向传播时,它的隐藏层的层数为随机1到4之间的数,这样可以多次重用相同的权重来计算。
因为这个模型可以使用普通的Python流控制来实现循环,并且我们可以通过在定义转发时多次重用同一个模块来实现最内层之间的权重共享。
我们利用Mudule的子类很容易实现这个模型:
import random
import torch
class DynamicNet(torch.nn.Module):
def __init__(self, D_in, H, D_out):
"""
在构造函数中,我们构造了三个nn.Linear实例,它们将在前向传播时被使用。
"""
super(DynamicNet, self).__init__()
self.input_linear = torch.nn.Linear(D_in, H)
self.middle_linear = torch.nn.Linear(H, H)
self.output_linear = torch.nn.Linear(H, D_out)
def forward(self, x):
"""
对于模型的前向传播,我们随机选择0、1、2、3,
并重用了多次计算隐藏层的middle_linear模块。
由于每个前向传播构建一个动态计算图,
我们可以在定义模型的前向传播时使用常规Python控制流运算符,如循环或条件语句。
在这里,我们还看到,在定义计算图形时多次重用同一个模块是完全安全的。
这是Lua Torch的一大改进,因为Lua Torch中每个模块只能使用一次。
"""
h_relu = self.input_linear(x).clamp(min=0)
for _ in range(random.randint(0, 3)):
h_relu = self.middle_linear(h_relu).clamp(min=0)
y_pred = self.output_linear(h_relu)
return y_pred
# N是批大小;D是输入维度
# H是隐藏层维度;D_out是输出维度
N, D_in, H, D_out = 64, 1000, 100, 10
# 产生输入和输出随机张量
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
# 实例化上面定义的类来构造我们的模型
model = DynamicNet(D_in, H, D_out)
# 构造我们的损失函数(loss function)和优化器(Optimizer)。
# 用平凡的随机梯度下降训练这个奇怪的模型是困难的,所以我们使用了momentum方法。
criterion = torch.nn.MSELoss(reduction='sum')
optimizer = torch.optim.SGD(model.parameters(), lr=1e-4, momentum=0.9)
for t in range(500):
# 前向传播:通过向模型传入x计算预测的y。
y_pred = model(x)
# 计算并打印损失
loss = criterion(y_pred, y)
print(t, loss.item())
# 清零梯度,反向传播,更新权重
optimizer.zero_grad()
loss.backward()
optimizer.step()
4. Visdom
Visdom的安装可通过命令pip install visdom。安装完成后,需通过python -m visdom.server命令启动visdom服务,或通过nohup python -m visdom.server &命令将服务放至后台运行。Visdom服务是一个web server服务,默认绑定8097端口,客户端与服务器间通过tornado进行非阻塞交互。
Visdom的使用有两点需要注意的地方:
需手动指定保存env,可在web界面点击save按钮或在程序中调用save方法,否则visdom服务重启后,env等信息会丢失。
客户端与服务器之间的交互采用tornado异步框架,可视化操作不会阻塞当前程序,网络异常也不会导致程序退出。
Visdom以Plotly为基础,支持丰富的可视化操作,下面举例说明一些最常用的操作。
vis作为一个客户端对象,可以使用常见的画图函数,包括:
line:类似Matlab中的plot操作,用于记录某些标量的变化,如损失、准确率等
image:可视化图片,可以是输入的图片,也可以是GAN生成的图片,还可以是卷积核的信息
text:用于记录日志等文字信息,支持html格式
histgram:可视化分布,主要是查看数据、参数的分布
scatter:绘制散点图
bar:绘制柱状图
pie:绘制饼状图
更多操作可参考visdom的github主页
这里主要介绍深度学习中常见的line、image和text操作。
Visdom同时支持PyTorch的tensor和Numpy的ndarray两种数据结构,但不支持Python的int、float等类型,因此每次传入时都需先将数据转成ndarray或tensor。上述操作的参数一般不同,但有两个参数是绝大多数操作都具备的:
win:用于指定pane的名字,如果不指定,visdom将自动分配一个新的pane。如果两次操作指定的win名字一样,新的操作将覆盖当前pane的内容,因此建议每次操作都重新指定win。
opts:选项,接收一个字典,常见的option包括title、xlabel、ylabel、width等,主要用于设置pane的显示格式。
使用下面语句启动visdom服务器
nohup python -m visdom.server &
import torch as t
import visdom
# 新建一个连接客户端
# 指定env = u'test1',默认端口为8097,host是‘localhost'
vis = visdom.Visdom(env=u'test1',use_incoming_socket=False)
# 新建一张图,画的是曲线
x = t.arange(1, 30, 0.01)
y = t.sin(x)
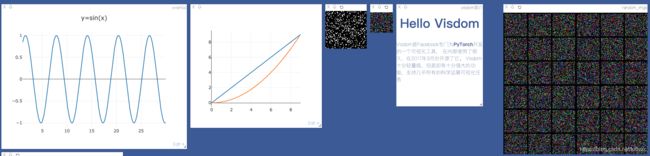
vis.line(X=x, Y=y, win='sinx', opts={
'title': 'y=sin(x)'})
# append 追加数据
for ii in range(0, 10):
# y = x
x = t.Tensor([ii])
y = x
vis.line(X=x, Y=y, win='polynomial', update='append' if ii>0 else None)
# updateTrace 新增一条线
x = t.arange(0, 9, 0.1)
y = (x ** 2) / 9
vis.line(X=x, Y=y, win='polynomial', name='this is a new Trace',update='new')
# 可视化一个随机的黑白图片
vis.image(t.randn(64, 64).numpy())
# 随机可视化一张彩色图片
vis.image(t.randn(3, 64, 64).numpy(), win='random2')
# 可视化36张随机的彩色图片,每一行6张
vis.images(t.randn(36, 3, 64, 64).numpy(), nrow=6, win='random3', opts={
'title':'random_imgs'})
vis.text(u'''Hello Visdom
Visdom是Facebook专门为PyTorch开发的一个可视化工具,
在内部使用了很久,在2017年3月份开源了它。
Visdom十分轻量级,但是却有十分强大的功能,支持几乎所有的科学运算可视化任务''',
win='visdom',
opts={
'title': u'visdom简介' }
)
import cv2
vis.images(cv2.imread(l1.png').transpose([2, 0, 1])[(2, 1, 0), :, :]) # 注意visdom显示的图片,通道在第一位,并且是bgr格式。如果要正常显示,必须做如上两个转换。