爬虫笔记:pyquery详解
pyquery
强大又灵活的网页解析库,如果你觉得正则写起来太麻烦,如果你觉得BeautifuiSoup语法太难记,如果你熟悉JQuery的语法,那么PyQuery就是你的绝对选择。
初始化
1字符串初始化
html = '''
- first item
- second item
- third item
- fourth item
- fifth item
'''
from pyquery import PyQuery as pq
doc = pq(html)#声明一个对象
print(doc('li'))#传入一个选择器
doc(‘li’) 选择器,如果选择标签直接加名字,如果选择id,加#,如果选择class,前面加.点。

2URL初始化
from pyquery import PyQuery as pq
doc = pq(url='https://www.2345.com/?38001')#传入一个网址
print(doc('head'))

3文件初始化
from pyquery import PyQuery as pq
doc = pq(filename='demo.html')
print(doc('li'))
基本CSS选择器
html = '''
- first item
- second item
- third item
- fourth item
- fifth item
'''
from pyquery import PyQuery as pq
doc = pq(html)
print(doc('#container .list li'))#id,class,标签名
doc(’#container .list li’)中list不一定是container的直接子对象,只要有层级关系就可以,中间需要用空格隔开。如果没有空格表示并列,表示条件需要同时满足。如(a.b)表示条件要同时满足ab。ab之间没有层级关系。

查找子元素
### 子元素
#%%
html = '''
- first item
- second item
- third item
- fourth item
- fifth item
'''
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
print(type(items))
print(items)
print('查找子元素')
lis = items.children()
print(type(lis))
print(lis)
print('具体子元素')
lis = items.children('.active')
print(lis)
items = doc(’.list’),items是一个查找对象,对对象可以调用查找方法,如find(查找子元素),children(直接子元素)。

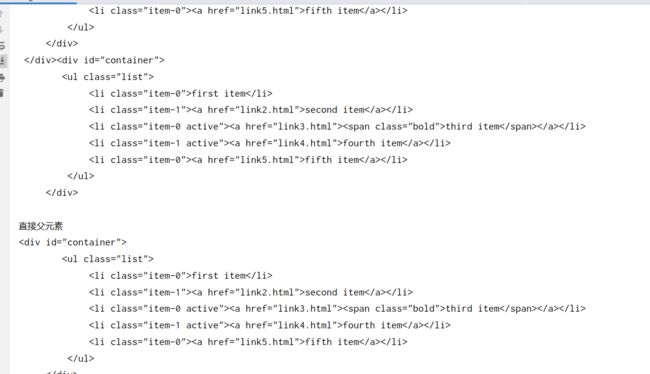
查找父元素
html = '''
- first item
- second item
- third item
- fourth item
- fifth item
'''
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.list')
parents = items.parents()
parent = items.parent()
print('父亲以及祖辈')
print(parents)
print('直接父元素')
print(parent)
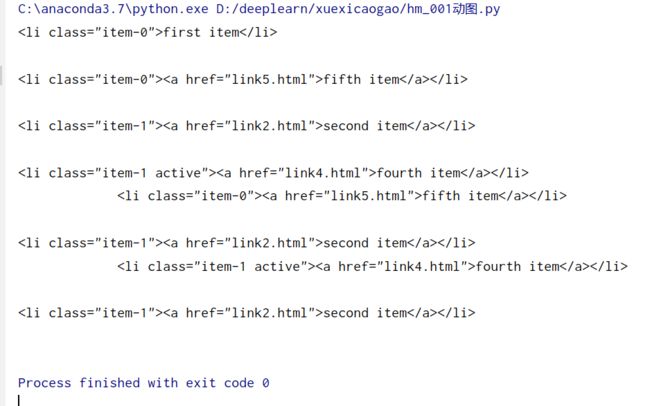
查找兄弟元素
html = '''
- first item
- second item
- third item
- fourth item
- fifth item
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.list .item-0.active')
print('所有兄弟')
print(li.siblings())
print('具体某一兄弟')
print(li.siblings('.active'))

遍历单个元素
html = '''
- first item
- second item
- third item
- fourth item
- fifth item
'''
from pyquery import PyQuery as pq
doc = pq(html)
lis = doc('li').items()
print(type(lis))
for li in lis:
print(li)

获取信息
获取属性
html = '''
- first item
- second item
- third item
- fourth item
- fifth item
'''
from pyquery import PyQuery as pq
doc = pq(html)
a = doc('.item-0.active a')
print(a)
print(a.attr('href'))#查找网址
print(a.attr.href)

获取文本
html = '''
- first item
- second item
- third item
- fourth item
- fifth item
'''
from pyquery import PyQuery as pq
doc = pq(html)
a = doc('.item-0.active a')#.item-0.active之间没有空格,表示class同时是item-0,active。有空格表示层级关系,如active a
print(a)
print(a.text())#获取文本

获取HTML
html = '''
- first item
- second item
- third item
- fourth item
- fifth item
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
print(li.html())

DOM操作
addClass、removeClass
html = '''
- first item
- second item
- third item
- fourth item
- fifth item
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')#.item-0.active,属性之间无空格,表示同时满足
print(li)
li.removeClass('active')
print(li)
li.addClass('active')
print(li)

attr、css
html = '''
- first item
- second item
- third item
- fourth item
- fifth item
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
li.attr('name', 'link')
print(li)
li.css('font-size', '14px')
print(li)

remove
html = '''
Hello, World
This is a paragraph.
'''
from pyquery import PyQuery as pq
doc = pq(html)
wrap = doc('.wrap')
print(wrap.text())
wrap.find('p').remove()
print(wrap.text())

其他DOM方法
http://pyquery.readthedocs.io/en/latest/api.html
伪类选择器
html = '''
- first item
- second item
- third item
- fourth item
- fifth item
'''
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('li:first-child')#获取第一个Li标签
print(li)
li = doc('li:last-child')#获取最后一个li标签
print(li)
li = doc('li:nth-child(2)')#获取第二个li标签
print(li)
li = doc('li:gt(2)')#获取第二个li标签
print(li)
li = doc('li:nth-child(2n)')#获取第二个li标签
print(li)
li = doc('li:contains(second)')#获取第二个li标签
print(li)
![]()
作者:电气-余登武。写作属实不容易,如果你觉得本文不错,点个赞再走。