毕设过程记录
目录
-
- 意欲何如
-
- 本文的目标读者
- 引子
- 毕设内容
- 贡献
- 语音信号处理
- 特征提取
-
- 低频特征
- 峰值特征
- 能量分布特征
- LPCC特征
- 活体检测
- 一点碎碎念,实验过程的残缺记录
- 参考文献
意欲何如
本文的目标读者
需要做 matlab信号处理相关 或 语音安全相关 或 机器学习相关 的本科生。本文可用于课程大作业的借鉴,也可为即将做毕设或参加互联网比赛的同学做参考。
引子
本文拟记录本科毕业设计的过程,主要是作为资料存放梳理的一个去处,也计划在期间记录自己的心得。本文的框架主要是根据usenix2020的论文Void:A fast and light voice liveness detection system, 所以本文也可以作为Void的论文的“辅助读物”。本文提到的知识和技能主要是用Matlab进行STFT,求自相关系数,求cdf,训练SVM等操作,这些操作并不高深,但由于整个过程中我几乎都是从零开始自学,也花费了不少时间精力。希望本文对小白入门会有一定的帮助。
本文的matlab代码(包括信号处理、特征提取和不同kernel的SVM分类器的应用)我将打包上传供下载,但是se-resnet代码主要是由我的合作同学选用并调试,故暂不提供下载。
本文有不少漏洞和不足,欢迎指教和讨论。
云在青天,俯仰之间,天地豁然。
毕设内容
- 复现一篇usenix2020的论文,主要工作是语音活体检测 — 检测输入的语音指令是人发出的还是扬声器发出的。
- 在ASVspoof 2017 和 ASVspoof 2019的PA数据集上进行测试。
- 用SE-ResNet做分类器以追求更高的检测准确率。
贡献
需要注意的是,我至今对以下部分结果是存疑的,因为我找不出切实的理由来说明为什么检测效果会这么好。
- 利用真人语音和通过扬声器重放的声音之间的频谱功率差异[10,17], 选取了四类特征(分别是低频特征,峰值特征,频谱CDF线性度特征和LPCC特征)共同构成74维的特征向量。
- 鉴于卷积神经网络(CNN)在图像分类与ASVspoof中的成功以及训练较深卷积网络时存在的梯度消失问题,本文选用了残差网络ResNet,结合17年ImageNet夺冠架构SENet[25] ,以较小的网络深度实现了较高的分类精度。
- 分别在ASVspoof 2017和ASVspoof 2019两个数据集上做了测试。其中ASVspoof 2017共包含18030条语音数据,ASVspoof 2019共包含218430条语音数据。我们的方案在2017数据集上可以达到2.381%的EER,在当年的48支参赛队伍中可以排第一;在2019数据集上则可以达到0.163%的EER,在当年的52支参赛队伍中可以排第一。
语音信号处理
语音信号转换是第一步,用到的工具是Matlab, 用到的database是ASVspoof 2017 的数据集。值得注意的是,ASVspoof2017和ASVspoof2019的数据采样率都是16kHz,这也就意味着进行FFT后我们只能得到0-8kHz频段的频谱图。但这并不影响分析,虽然理论上人类的听觉频段是20Hz-20kHz,但人类的发声频段大约在85 Hz-1100 Hz ,不论是真实语音还是重放攻击能量主要集中在这一频段,也就是说0-8kHz的频段内已经有足够充分的信息。
信号处理的过程如算法1所示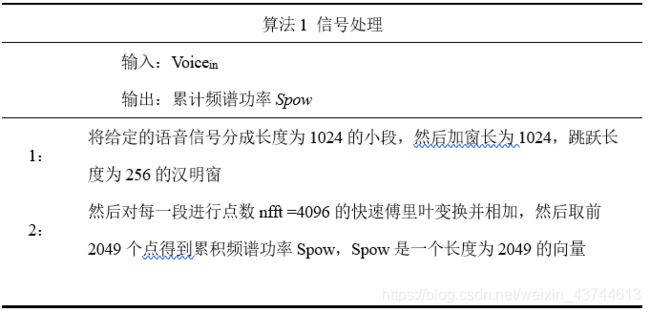
特征提取
将信号处理得到的向量Spow和 V o i c e i n Voice_{in} Voicein 作为特征提取的输入,提取分类特征。特征储存在向量FV中,接下来分别介绍四类特征及如何提取这些特征。
低频特征

真实语音和重放攻击的频谱图在低频段(2kHz以下)有很大的差异,所以,用低频段的累计频谱功率作为特征是一个不错的选择。Spow中表示2kHz以下的是大约前500个点,直接把这些点作为特征当然是可以的,但是为了让计算更方便,我们可以做平滑处理以进行进一步的优化。
峰值特征

真实语音和重放攻击的频谱图的另一个差异是真实语音在低频段波动更明显(量化来看,有更多的峰),重放攻击的波动更少(峰比较集中),而且峰的位置分布也有所差异。所以频谱图的峰值数量和位置也可以做为一类特征。提取峰值特征的过程如下所示。由于峰值肯定存在于低频段,所以为了减少计算量,我们可以用 F V 1 FV_1 FV1作为输入。
能量分布特征
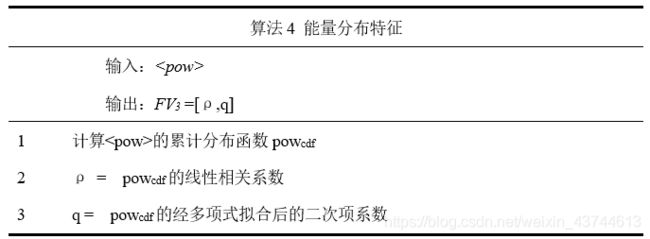
语音的能量分布情况用cdf线性度特征描述。此处的线性度指的是的累计分布函数的线性度。我们分别计算了累积分布的线性相关系数ρ和二次曲线拟合系数q。

如上图所示,虽然在决策边界上依然有不少点重合,但依然可以清楚地看到真实语音和重放攻击的CDF特征的差异,这让CDF特征有充分的的理由成为判别特征之一。
LPCC特征
线性预测倒谱系数(Linear prediction cepstrum coefficients,LPCC)。LPCC背后的基本思想是,语音样本可以近似为先前样本的线性组合。通过最小化实际语音样本与线性预测样本之间的平方差之和,可以计算语音样本的LPC系数。MATLAB 2019b中有相关函数lpc直接计算LPCC。本文使用Levinson-Durbin算法找到语音信号的12阶LPC系数。获得的12个LPC系数存储在向量 F V 4 FV_4 FV4中。
LPCC的计算可以调用matlab封装的函数,感兴趣的同学可以下载我的代码看看。
活体检测
本文首先训练了支持向量机(support vector machine,SVM)来实现语音活体检测。我们用第二步提取出来的低频特征、峰值特征、CDF线性度特征和LPCC特征共同构成一个特征向量,并用这一特征向量构造分类算法。本文测试了SVM Linear和SVM rbf分类器的效果。训练SVM并用它做测试的代码可参考附录G。
为了追求更高的精度,本文参考胡杰等人提出的方法[25]构造了一个基于挤压激励网络(Squeeze-and-Excitation Network, SENet)和残差网络(ResNet)的深度卷积网络模型SE-ResNet-50用于分类,在降低网络深度的同时,减小了计算量,提高了分类精度。
SE-ResNet的介绍可点击此链接
一点碎碎念,实验过程的残缺记录
- 截至2020/2/11 的理解
有两个思路
a. 把原始语音信号分帧,每个帧的长度是1024.然后用hammig窗去滤波,之后再进行FFT,再把每个帧的FFT之后的值加起来,就变成了累计频谱密度函数。
b. 直接运用matlab的stft函数
无论采用哪个思路,论文中提到的
Spow obtained from STFT is a vector of size 1,500
都没有得到体现,所以这个1500到底是哪儿来的呢?
- 截至2020/2/16
打算发信询问作者
一作:个人主页
二作:中央大学副教授个人主页
整理问题如下:
Q 1:在5.2 Signal trsnsformation中提到“Spow obtained from STFT is a vector of size 1,500”,不知道这1500是从哪里来的?
A 1:我已经知道你考虑的是声音信号中频率低于15khz的部分
邮件内容如下:
Dear Professer Muhammad Ejaz Ahmed:
I am writing to enquire about the algrithm 1 in your paper 'Void:A fast and light voice liveness detection system", which was published in 29th Usenix.
My name is Zizhi JIN. I am an undergraduate in the School of Electrical Engineering ,Zhejiang University(ZJU).I’m interested in sensor security and machine learning. I saw your paper ‘Void’ on the Internet. This paper used only 97 features to make a good detection effect, which caused my curiosity. So I tried to reproduce the algorithm of this paper.However, I encountered some difficulties in the reproduction process. After a week of thinking and discussion, I still have a few points that I cannot understand. So I come and ask for your help.
Questions are as follows:
1. At the end of the paragraph in section 5.2, you mentioned “Spow obtained from STFT is a vector of size 1,500” . I don’t understand what does the number 1500 mean.I thought Spow obtained from STFT is a vector of size 4096. Is the number 1500 related to the sampling rate or it represents truncating the first 1500 values from 4096 values?
I wrote a version of matlab program to try to reproduce the signal transformation process.This is the result of my signal transformation. The data set I used is ASVspoof2017. I attached my matlab program and audio to the email attachment.
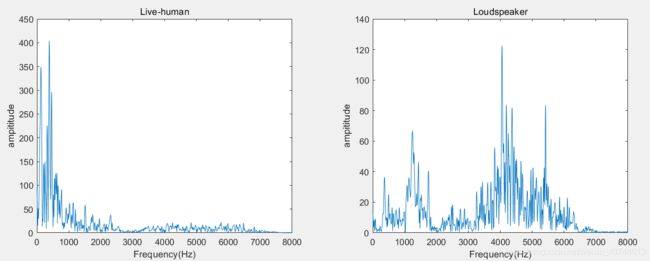
2. Take the figure.5 in the paper as an example, I couldn’t figure out why"High-quality speakers(middle and right): the power over the same frequency
range is more concentrated with less fluctuations."
Is there any physical explanation for this or is it just an observed phenomenon?

In general, I would love to ask the following two questions:
- What does the number 1500 in section 5.2 mean?
- Is there any physical explanation for Figure 5 or is it just an observed phenomenon?
Thank you very much for your attention to these questions.
With all best wishes!
参考文献
[1] 语音助手在智能汽车上商用.[2019/8/28]:
https://www.roewe.com.cn/about-roewe/tech/internet-car.html.
[2] 声学模拟器:http://homepages.loria.fr/evincent/software/Roomsimove_1.4.zip
[3] 重播设备模拟器: https://ant-novak.com/pages/sss/
[4] Andrew Liptak.用语音助手Alexa购买玩具屋的新闻.[2017/1/7]:
https://www.theverge.com/2017/1/7/14200210/amazon-alexa-tech-news-anchor-order-dollhouse
[5] Evans N W D, Kinnunen T, Yamagishi J. Spoofing and countermeasures for automatic speaker verification[C]//Interspeech. 2013: 925-929.
[6] Wu Z, Kinnunen T, Evans N, et al. ASVspoof 2015: the first automatic speaker verifica-tion spoofing and countermeasures challenge[C]//Sixteenth Annual Conference of the International Speech Communication Association. 2015.
[7] Kinnunen T, Sahidullah M, Delgado H, et al. The ASVspoof 2017 challenge: Assessing the limits of replay spoofing attack detection[J]. 2017.
[8] Todisco M, Wang X, Vestman V, et al. Asvspoof 2019: Future horizons in spoofed and fake audio detection[J]. arXiv preprint arXiv:1904.05441, 2019.
[9] Singh N, Agrawal A, Khan R A. Automatic speaker recognition: current approaches and progress in last six decades[J]. Global J Enterp Inf Syst, 2017, 9(3): 45-52.
[10] Ahmed M E, Kwak I Y, Huh J H, et al. Void: A fast and light voice liveness detection system[J]. USENIX Security: The 29th USENIX Security Symposium, Boston, USA, 2020.
[11] Zhang L, Tan S, Yang J, et al. Voicelive: A phoneme localization based liveness detection for voice authentication on smartphones[C]//Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security. 2016: 1080-1091.
[12] Wu Z, Evans N, Kinnunen T, et al. Spoofing and countermeasures for speaker verification: A survey[J]. speech communication, 2015, 66: 130-153.
[13] Carlini N, Mishra P, Vaidya T, et al. Hidden voice commands[C]//25th {USENIX} Se-curity Symposium ({USENIX} Security 16). 2016: 513-530.
[14] Zhang G, Yan C, Ji X, et al. Dolphinattack: Inaudible voice commands[C]//Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. ACM, 2017: 103-117.
[15] Roy N, Shen S, Hassanieh H, et al. Inaudible voice commands: The long-range attack and dfense[C]//15th {USENIX} Symposium on Networked Systems Design and Implemen-tation ({NSDI} 18). 2018: 547-560.
[16] Zhang L, Tan S, Yang J, et al. Voicelive: A phoneme localization based liveness detection for voice authentication on smartphones[C]//Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security. ACM, 2016: 1080-1091.
[17] Blue L, Vargas L, Traynor P. Hello, Is It Me You’re Looking For?: Differentiating Be-tween Human and Electronic Speakers for Voice Interface Security[C]//Proceedings of the 11th ACM Conference on Security & Privacy in Wireless and Mobile Networks. ACM, 2018: 123-133.
[18] T. Ko, V. Peddinti, D. Povey, M. L. Seltzer, and S. Khudan-pur, “A study on data augmentation of reverberant speech for robust speech recognition,” inProc. IEEE Int. Conf. on Acoustics,Speech and Signal Processing (ICASSP), 2017, pp. 5220–5224.
[19] Todisco M, Wang X, Vestman V, et al. Asvspoof 2019: Future horizons in spoofed and fake audio detection[J]. arXiv preprint arXiv:1904.05441, 2019.
[20] Lee K A, Larcher A, Wang G, et al. The RedDots data collection for speaker recogntion[C]//Sixteenth Annual Conference of the International Speech Communication Association. 2015.
[21] Kinnunen T, Sahidullah M, Falcone M, et al. Reddots replayed: A new replay spoofing attack corpus for text-dependent speaker verification research[C]//2017 IEEE Interna-tional Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2017: 5395-5399.
[22] Lavrentyeva G, Novoselov S, Tseren A, et al. STC antispoofing systems for the ASVSpoof2019 challenge[J]. arXiv preprint arXiv:1904.05576, 2019.
[23] Lai C I, Chen N, Villalba J, et al. ASSERT: Anti-Spoofing with squeeze-excitation and resiual networks[J]. arXiv preprint arXiv:1904.01120, 2019.
[24] Greff K, Srivastava R K, Koutník J, et al. LSTM: A search space odyssey[J]. IEEE transactions on neural networks and learning systems, 2016, 28(10): 2222-2232.
[25] Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 7132-7141.
[26] He K, Zhang X, Ren S, et al. Deep residual learning for image recogni-tion[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
[27] Lai C I, Chen N, Villalba J, et al. ASSERT: Anti-Spoofing with squeeze-excitation and residual networks[J]. arXiv preprint arXiv:1904.01120, 2019.
[28] Zhou B, Khosla A, Lapedriza A, et al. Learning deep features for discriminative locali-zation[C]//Proceedings of the IEEE conference on computer vision and pattern recogni-tion. 2016: 2921-2929.
[29] Valenti G, Daniel A, Evans N W D, et al. End-to-end automatic speaker verification with evolving recurrent neural networks[C]//Odyssey. 2018: 335-341.
[30] Zhao X, Wang Y, Wang D L. Robust speaker identification in noisy and reverberant conditions[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2014, 22(4): 836-845.