oracle 数据库命令使用记录
之前都是使用mysql数据库的,现在由于新项目甲方有钱上了oracle,虽然说oracle mysql 都是 关系型数据库用的也是sql ,但还是有些不一样的
统计总数
在mysql查询数据并获取所有满足数据的总数量可以使用
sql_calc_found_rows函数来进行查询,
select sql_calc_found_rows * from test where name = '老王' limit 1, 10
正常来说这条sql 只能查询10条name = 老王的数据,但是,使用 sql_calc_found_rows后可以查询出来整个数据表中 name = 老王的总数, 非常方便
但是在oracle 中没有使用的函数的, 这时候可以使用子查询来到达这种效果,
select count(*) over () count, t.* from test t where name = '老王' rownum 1 between 10
这时候 count 就是数据表中名字为老王的总数了,当然,也可以使用两条sql 来进行查询,
select * from test where name = '老王'
select count(*) where name = '老王'
统计总数并分页
在实际项目中展示数据是不可以一次性展示完所有数据的,一般都是以一个数量来展示,如 一次只展示10条, 20条这样子, 这时候我们要做的是 获取分页获取10条数据,并统计返回统计的有多少条进行分页,这时候在mysql中可以直接加limit 进行分页
select sql_calc_found_rows * from test where name = '老王' limit 0, 10
而在oracle 是没有limit 的,oracle中的分页使用的是 rownum, 所以得做成 子查询
select rownum rn, * from (select count(*) over () count, t.* from test t where name = '老王' ) where rn between 0 and 10
注意: 在子查询中使用* 的话要给 查询的数据表起个别民名不然会错误,这个我就没细究了,可能是和外面的 * 起冲突吧
网上说这写法效率垃圾不过似乎很常见的,因为后面还要加order by 排序吧
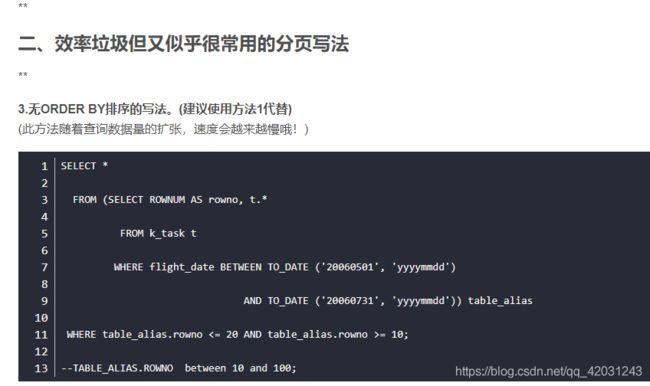
先实现功能再说其他的,以后可以再优化
排序
查询数据有多条的时候一般都需要用到排序, 通过创建时间或更新时间进行排序或倒序, mysql 可以直接加上 order by 进行排序,
select sql_calc_found_rows * from test where name = '老王' order by update_time desc limit 0, 10
而要在oracle 中实现排序还得在嵌套一层子查询,不然会和 分页冲突,当然,这是我的个人见解,可以也不太对,看看就行了
select rownum rn, * from (select ts.* from (select count(*) over () count, t.* from test t where name = '老王' ) ts order by update_time desc ) where rn between 0 and 10
sysdate
时间,一般来说数据库设计都是有时间值得, create_time update_time 这两个常见的值,
但是在设计时间值得时候不想直接设计 时间戳,那么 可以将时间字段设置为 varchar 类型
mysql 中对于这种varchar 类型的字段添加时间值可以使用 now() 函数,它可以插入一个 类似 2020-11-11 11:11:11这种格式的时间数据, 但是在oracle 中是没有oracle的, 只有 sysdate(), 但是这个sysdate 插入的是一个时间格式的数据, 和varchar 对不上, 所以要所以到 to_char()
to_char()
to_char 可以将sysdate 数据转为 普通的varchar 类型的字符串,
insert into test(id, update_time, create_time) values(1, to_char(sysdate, 'yyyy-mm-dd HH24:mi:ss', to_char(sysdate, 'yyyy-mm-dd HH24:mi:ss')))
插入后的数据数据2020-12-12 12:12:12这种类型的数据了
to_date
和 to_char 相反的是 to_date , to_date 可以将一个varchar 类型的时间数据转为datetime的时间数据,一般用在数据比较 查询范围中,
select * from test where to_date(create_time, 'yyyy-mm-dd HH24:mi:ss') between to_date('2020-10-10', 'yyyy-mm-dd H') and to_date('2020-12-12', 'yyyy-mm-dd HH24:mi:ss')
可以查询时间在 2020-10-10 至 2020-12-12 之间的所有数据, 注意: to_date 函数中 后面的 ‘yyyy-mm-dd HH24:mi:ss’ 这个格式数据只能多不能少, 比如 在 test 数据表中 create_time 的数据格式是 2020-10-10 11:11:11注意的格式的时候, 在比较的时候就不能只写 to_date(create_time, 'yyyy-mm-dd'),这样写的话会出现
ORA-01830: date format picture ends before converting entire input string错误
序列
在oracle 中是没有id 自增的, 所以我们在插入数据的时候插入数据的id 值,
如果你在插入前先去获取数据表中最后一个数据的id 值,计算出要插入的id值后再进行插入,这种方法显得就有些多余了, 这时候我们可以给数据表添加一个序列,在插入数据的时候写上这个序列名.nextval ,然后就可以自动获取到下一个id的值了
// 创建序列, 序列名是test_id_seq 序列名随便自己写
create sequence test_id_seq
// 调用一次增加多少,如我这次调用这个序列返回值是100,下一次调用返回的介绍101 在原基础上加 1
increment by 1
// 开始值,我创建完这个序列后调用次调用是 从什么开始
start with 70
// 最小值,我这个 序列调用的时候返回的值不能小于这个值,一般和start with 一样
minvalue 70
// 最大值,这个序列最多能调用返回结果的最大值
maxvalue 999999999;
创建完序列后,在以后的插入数据的操作只需要
insert into test(id, name, create_time, update_time) values(test_id_seq.nextval, '老王', to_char(sysdate, 'yyyy-mm-dd HH24:mi:ss'), to_char(sysdate, 'yyyy-mm-dd HH24:mi:ss'))
就可以了,在id 对应的值中 写上数据表 id 对应的序列,nextval 就是调用获取返回值
还有group 分组,不过我现在还没理解完,写不出来, 以后会用了有时间了就写在下一篇博客上记录吧