自然语言处理常用RNN、LSTM、GRU举例详解,通俗易懂
之前疫情网民情绪识别的模型用到了LSTM,最近面试被问到具体细节,感觉被拎出来羞辱,经过认(cha)真(yue)思(wen)考(xian),总结了一下RNN、LSTM、GRN的一些知识。为了更加易懂,本文会采用疫情网民情绪识别这篇文章里的例子。
RNN详解
说到LSTM,还是要先从RNN(循环神经网络)开始描述,算是LSTM的基础。RNN经典的模型分解可以用如下图片解释,这也是我在大部分文章中看到的解释,感兴趣的可以到RNN详解这篇文章中看看。

左侧部分,x、s、o都是向量,分别表示输入层、隐藏层和输出层的值。U是输入层到隐藏层的权重矩阵,V是隐藏层到输出层的权重矩阵,W是上一时刻的隐藏层s作为下一时刻输入的权重矩阵。把W去掉这其实就是一个简单的全连接神经网络。
右半部分是左侧图按时刻展开的图,看起来更直观。相较于全连接神经网络,隐藏层的值 s t s_{t} st 不仅取决于 x t x_{t} xt,还取决于上一时刻的隐藏值 s t − 1 s_{t-1} st−1
根据我的理解上图左半部分表示一个简单的网络加上了自己的输出对自己的输入的影响,x表示输入层,s表示隐藏层,o表示输出层,而w是自身不同状态对自己的影响,而右半部分则是展开了自己对自己影响的机制。
虽然确实对RNN有了一定了解,但本人对状态时刻t的意义非常迷惑,对这一时刻的传播没有什么认知。
找了几个解释,感觉吴恩达DeepLearning第五课中的结构图示意是比较清晰的,RNN网络外部的连接如下,RNN-cell之间是相互连接的:

而每个RNN内部结构则如下图所示:
‘’
下面是RNN的计算公式:
a t = f ( W a x x t + W a a a t − 1 + b a ) a_{t}=f(W_{ax}x_{t}+W_{aa}a_{t−1}+b_{a}) at=f(Waxxt+Waaat−1+ba)
y t = g ( W y a a t + b y ) y_{t}=g(W_{ya}a_{t}+b_{y}) yt=g(Wyaat+by)
其中 f f f一般用 t a n h tanh tanh函数,而 g g g一般用 s o f t m a x softmax softmax函数。
第一个式子是隐藏层的计算公式,DNN与RNN的区别就在于式1,即隐藏层不同,DNN的式1没有 W a a a t − 1 W_{aa}a_{t-1} Waaat−1这一项,RNN有了这一项,就有了上图中,隐藏层 a a a的时间循环,所以称之为循环神经网络。
式2是输出层的计算公式,该层是一个全连接层。
这样理解可能仍然有些抽象,下面举个例子来说明一下RNN网络。
先说明一下数据,以训练集中的第一条微博文本为例,对疫情的微博文本进行分词,采用精确模式。
原文如下:
'#男子解除隔离10天后发病##男子解除隔离10天后发病#【山东日照:一男子解除隔离10天后发病妻孩三人皆为无症状感染者】2月15日,山东省新增的新冠肺炎确诊病例中,一名42岁的日照男子刘某和家人,曾与确诊病例有接触,随后刘某和妻子于某燕(38岁)、女儿(11岁)、儿子(5岁)均被集中隔离医学观察。四人在?展开全文c'
分词后的结果如下,其中每个词都以空格为间隔:
'# 男子 解除 隔离 10 天后 发病 ## 男子 解除 隔离 10 天后 发病 # 【 山东 日照 : 一 男子 解除 隔离 10 天后 发病 妻孩三人 皆 为 无症状 感染者 】 2 月 15 日 , 山东省 新增 的 新冠 肺炎 确诊 病例 中 , 一名 42 岁 的 日照 男子 刘某 和 家人 , 曾 与 确诊 病例 有 接触 , 随后 刘某 和 妻子 于 某燕 ( 38 岁 ) 、 女儿 ( 11 岁 ) 、 儿子 ( 5 岁 ) 均 被 集中 隔离 医学观察 。 四人 在 ? 展开 全文 c'
转化成相对应的整数型数据:
[1005, 7865, 188, 2, 52, 2586, 37, 257, 1666, 746, 212, 0, 2651, 2, 0, 1842, 230, 4662, 1, 5533, 37, 81, 5979, 4852, 8, 540, 1241]
就可以得到一条输入文本的整数形式,此时再输入到网络中去。
网络如下所示(这里将原来的LSTM改为RNN以便观察):
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_3 (Embedding) (None, 100, 100) 1000000
_________________________________________________________________
lstm_3 (RNN) (None, 128) 117248
_________________________________________________________________
dropout_3 (Dropout) (None, 128) 0
_________________________________________________________________
dense_3 (Dense) (None, 3) 387
=================================================================
Total params: 1,117,635
Trainable params: 1,117,635
Non-trainable params: 0
_________________________________________________________________
假设有n条微博文本作为样本要进入网络,在embedding层之后,得到的输出应为n个100*100的矩阵,这是因为我们规定每条微博输入之前都取前100个词语(不足的补0),而每个单词被训练成100维的向量,且这些向量由于语序的原因是有顺序的。
放到整体的网络中结构如下:
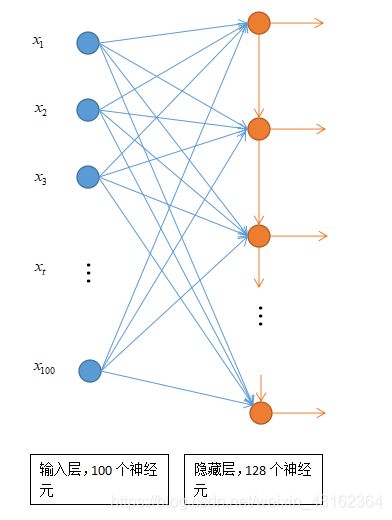
其中输入的神经元个数有100个,代表每个文本有100个单词,而每个单词经过embedding层之后都是一个100维的向量,也就是说每个 x t x_{t} xt都是一个100维的向量,代表一个单词。
输入层与隐藏层的链接仍然像全连接神经网络那样,但是在隐藏层的每个神经元中间会增加一个信息的联通,以隐藏层的第二个神经元为例,它不仅接收了100个单词的信息作为输入,还有隐藏层的第一个神经元的输出作为输入,以表示文本前后的关系信息。
LSTM详解
在解释完RNN之后,LSTM就比较好理解了,事实上,当文本很长的时候,本文中的例子只取了前200个单词进行分析,但当文本很长,神经元个数增多的时候,RNN就会出现弊端,它对于文本前后关系中"距离"比较近的关系能够比较好的表现出来,也就是短期记忆,这样对于长文本的效果就不那么好了,LSTM和GRU是作为短期记忆的解决方案而创建的。
它们具有称为门(gate)的内部机制,它可以调节信息流。这些门可以了解序列中哪些数据重要以进行保留或丢弃。这样,它可以将相关信息传递到长序列中进行预测。
LSTM只是在每个单元中加入了三个门控单元,分别是:
- 遗忘门:用来让RNN“忘记”之前没有用的信息。
- 更新门:用来让RNN决定当前输入数据中哪些信息将被留下来。
- 输出门:LSTM在得到最新节点状态c后,结合上一时刻节点的输 y ( t − 1 ) y^{(t-1)} y(t−1) 和当前时刻节点的输入 x t x^t xt来决定当前时刻节点的输出。
具体的单元结构如下图所示:

也就是说在原来的RNN中加入了新的函数(这里称之为门),来选择性的去掉、保留、输出一些信息,从而将长序列中较早期的一些文本信息保留下来。
具体这些门的工作方式,可以简单描述如下:
遗忘门:
来自前一个隐藏状态的信息和当前输入的信息同时传递到sigmoid函数中去,输出介于0和1之间的值,0代表应该丢弃,1代表应该保留。
输入门:
输入门更新细胞状态,将前一个隐藏状态的信息和当前输入的信息分别传递到sigmoid和tanh中去得到两个值,将它们相乘,得到的结果就是需要保留的信息。
输出门:
将前一个隐藏状态的信息和当前输入的信息传递到sigmoid函数中去,同时将新的细胞状态传递到tanh函数中去,两者相乘,得到该隐藏单元的输出。
实际上这方面的具体原理听起来比较晦涩,但之前发现了一个大神把LSTM神经元里的信息流动做成了动图,一目了然,可以参看这篇文章LSTM和GRU的解析从未如此通俗易懂(动图)
将各个神经元连接起来就是完整的LSTM隐藏层的结构。

实例和RNN类似,只是当词向量作为输入进入神经元后,神经元会按照某种方式对该词向量的信息进行选择,存储成新的信息,输入到相邻的隐藏层神经元中去。
GRU详解
当了解RNN和LSTM之后,GRU就变得更加自然而然了。
GRU作为LSTM的一种变体,将忘记门和输入门合成了一个单一的更新门。来决定那些信息被忘记哪些信息被添加,其内部的图示如下:

最终的模型比标准的 LSTM 模型要简单,也是非常流行的变体。