【Nginx】Nginx中的共享内存及共享内存slab管理器
1.Nginx中的通讯方式的分类
共享内存是Nginx跨worker通信的最有效手段,只要我们需要让一段业务逻辑在多个worker进程中
同时生效,比如在许多集群的流控上,必须使用共享内存,而不能在每一个worker进程中使用.
Nginx中的通讯方式的分类:
1.基础同步工具
(1)信号;
(2)共享内存.
2.高级通讯方式
(1)锁
(2)Slab内存管理器;
2.锁与Slab内存管理器
为了使用好共享内存会引出两个问题:
(1)多个进程同时操作一块内存会出现竞争关系,所以我们需要锁.
Nginx的锁在早期的时候是基于信号量的锁,信号量是Linux中比较久远的进程间通信方式,
它会导致进程进入休眠状态(发生主动切换),现在操作系统中的Nginx使用的锁大部分是自旋锁,
而不是使用信号量.
自旋锁当锁的条件没有满足,比如说这块内存现在被一号worker进程使用,二号worker进程获取
锁的时候只要一号worker进程没有释放锁,二号worker进程会一直在不停地去请求这把锁,就好像
如果是基于信号量的早期的Nginx的锁,假设这把锁锁住了一扇门,如果一号worker进程已经拿到
这把锁进到屋里,二号worker进程试图去拿锁去敲门发现里面有人了,二号worker进程会就地休息,
等到一号worker进程出来以后通知二号worker进程.
基于自旋锁的Nginx的锁,假设这把锁锁住了一扇门,如果一号worker进程已经拿到
这把锁进到屋里,二号worker进程试图去拿锁去敲门发现里面有人了,它会持续敲门.
使用自旋锁要求所有的Nginx模块必须快速地使用共享内存,快速地取得锁,快速地释放锁,一旦出现
第三方模块不遵守这样的规则,就可能导致出现死锁或者性能下降的问题.
(2)引入共享内存后,会出现第二个问题,因为一块共享内存往往是给许多对象同时使用的,如果我们在
模块中手动地去编写分配把这些内存给到不同的对象是非常繁琐的,所以这时我们使用了slab内存
管理器.3.共享内存中的数据结构
使用共享内存主要使用了rbtree和单链表两种数据结构.
比如我们想做限速或者流控等场景时,我们不能容忍在内存中做,否则一个worker进程对某个用户
触发了流控,其他worker进程还不知道,所以只能在共享内存中做,比如说
Ngx_stream_limit_conn_module等.
红黑树的插入删除非常快.比如现在发现一个客户端需要对其进行限速,限速如果达到了,需要
把这个客户端将限速数据结构容器中移除都非常快速.
第二个场景的数据结构是单链表,只需要把这些需要共享的元素串起来即可,如 Ngx_http_upstream_zone_module.
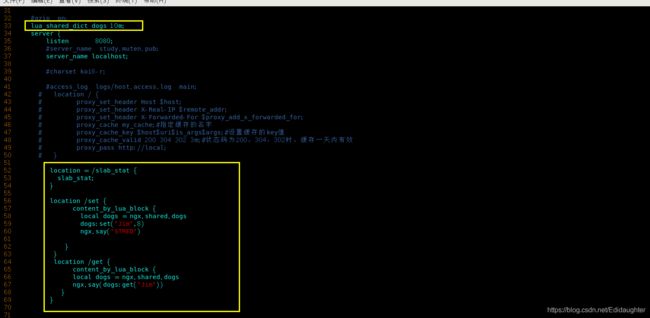
Ngx_http_lua_api
这个模块是openresty的核心模块,openresty在这个模块中定义了一个SDK--lua_shared_dict,
当这个指令出现的时候会分配一块共享内存,比如说10m,这块共享内存会有一个名字dogs.
在展示的这部分代码中我们同时使用了红黑树和链表,使用红黑树来保存每一个key-value,
红黑树中的节点就是"Jim",对应的value就是8.
为什么还需要一个链表呢?
因为10m是有限的,当我们的lua代码涉及到了应用业务代码,很容易就超过了10m限制,当我们超过
10m限制的时候,我们有很多种处理方法,比如说它写入失败,但是lua_shared_dict中用了LRU算法
进行淘汰(当达到10m最大的内存是,对最早set或get的长时间不用的那个节点进行淘汰)???
还是没说明白这个链表是用来干啥的啊?是淘汰了之后转移到链表中吗?
如何把一整块共享内存切割成小块给红黑树上的每个结点使用呢?
Slab内存管理器帮助我们做到了这个.
4.slab如何工作
Slab内存管理器如何工作:
(1)把整块的共享内存分成很多页面(如4K);
(2)每个页面会分成不同种类的各种slot,比如32字节的,64字节的,128字节的,
这些slot是以乘2的方式向上增长的,如果现在需要分配51字节的内存,就会
去找大于其大小的最小字节的那个类型的slot,比如64字节的那种slot.
从举例中可以看出,会有内存的浪费出现.51字节使用了64字节存放,浪费了13字节.
最多会有多少内存消耗呢?
两倍.
Bestfit内存分配方式的特点:
(1)最多两倍内存消耗;
(2)适合小对象(比如小于一个页面的大小,就非常合适);
(3)避免碎片;
(4)避免重复初始化.
适合小对象,比如小于一个页面的大小,就非常合适,因为它很少有碎片,
每次分配内存就会沿着还没有分配的空白的地方继续使用,当一个页面
分配完了之后,再拿一个页面给此类slot继续使用.有时候分配在这块内存
上的内容是固定的且需要初始化,用这种方式,原先的数据结构都还在,重复
使用也避免了初始化.slab内存用在了我们刚刚所说的openresty的那个场景中,
已经之前说的limit_request和limit_connection中.
5. slab内存的监控与统计
slab内存管理如何做数据的监控与统计呢?
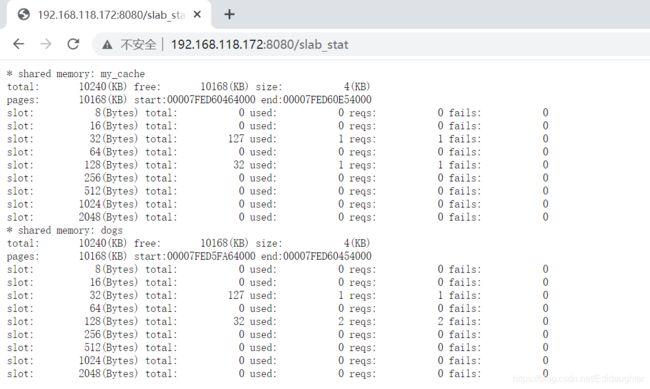
tengin中有一个模块叫做slab_stat
slab_slot可以帮我们看不同的slot目前的分配情况,使用情况,多少个请求在访问,失败了多少次等.
这个对于我们监控slab是非常有用的.
如何在openresty中使用tengin的slab_stat
http://tengine.taobao.org/document/ngx_slab_stat.html
http://tengine.taobao.org/download.html
/home/muten/module/tengine-2.2.2/modules/ngx_slab_stat
编译与安装:
./configure --add-module=/home/muten/module/tengine-2.2.2/modules/ngx_slab_stat/
make
make install
6.测试在openresty中使用tengin的slab_stat
7.further research
https://blog.csdn.net/ibless/article/details/81367700?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522160499799919725225005430%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=160499799919725225005430&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_click~default-1-81367700.first_rank_ecpm_v3_pc_rank_v2&utm_term=slab%E5%88%86%E9%85%8D%E5%99%A8&spm=1018.2118.3001.4449
https://www.cnblogs.com/doop-ymc/p/3412572.html
https://www.cnblogs.com/doop-ymc/p/3418514.html
https://blog.csdn.net/hnudlz/article/details/50972596?utm_source=blogxgwz0&utm_medium=distribute.pc_relevant_download.none-task-blog-baidujs-1.nonecase&depth_1-utm_source=distribute.pc_relevant_download.none-task-blog-baidujs-1.nonecase8.我的问题
1.ngx_slab_pool_t和ngx_pool_t这两个都是用于内存管理,有什么区别?为什么要拆分?
目前我的理解:
slab是参照内核的slab算法写的管理的是进程间的共享内存,但ngx_pool_s里面的是进程内用户空间的内存.
待确认.
对齐啊!!!为了方便寻址,对齐!!所以内核中的内存没有采用ngx_pool_s里面的那种不会产生内部内存
碎片的方式!!!(不知道是不是空欢喜,再等着进一步探索吧)
2.ngx_slab_pool_t相对于内核的slab算法有什么改进?为什么要对内核的slab重写?
性能在什么情况下优化了多少?
暂时无解.等待探索.