14.7倍推理加速、18.9倍存储节省!北航、商汤、UCSD提出首个点云二值网络 | ICLR 2021...
允中 编辑整理
量子位 报道 | 公众号 QbitAI
编者按:
无论是在自动驾驶场景中,还是在手持移动设备上,基于点云的深度学习模型应用越来越广泛。
但这些离线边缘场景自身的限制,给模型的推理、存储、传输等环节都带来了巨大的挑战。如何让点云模型在边缘设备上“又轻又快”,是工业界和学术界共同关注的重要问题。
现在,为了解决边缘设备上运行点云应用时的资源限制问题,来自北航、商汤和 UCSD的研究团队,基于神经网络量化这样的模型压缩和加速手段,提出了首个点云深度学习二值化模型 BiPointNet。
这一方法不仅在边缘设备上带来了 14.7倍 的加速比和 18.9倍 的存储节省,准确率损失也不大( 相差1-2%以内),甚至可以媲美全精度网络。
目前,这一研究成果已经被 ICLR 2021接收。
不妨一起来看看研究团队关于这篇论文的解读。
首个点云二值网络

在自动驾驶、AR 等实际应用场景下,用于点云的深度神经网络模型非常需要实时交互和快速响应。但是,它们的部署环境通常是一些资源受限的边缘设备。
尽管研究者们已经提出了诸如 Grid-GCN,RandLA-Net 和 PointVoxel 之类的新颖的算法来加速点云网络的处理,但是它们还是依赖于昂贵的浮点运算。
模型二值化方法受益于轻量的二值化参数和高效的按位操作,已成为最有前景的模型压缩加速方法之一,但是由于 2D 图像和 3D 点云之间的根本性差异,现有的二值化方法无法被直接迁移到 3D 点云网络中。
在本文中,我们提出了 BiPointNet,将全精度的点云网络转换成高效且准确的二值化模型 (整体框架图见图 1)。我们研究了二值化特征的信息熵和点云聚合函数的表现之间的关系:为了解决聚合后的二值化特征存在同质化的问题,提出了熵最大化聚合函数 (Entropy-Maximizing Aggregation,EMA);提出了逐层尺度恢复 (Layer-wise Scale Recovery,LSR) 以有效地恢复输出的尺度,并使得尺度敏感的结构可以正常运作。
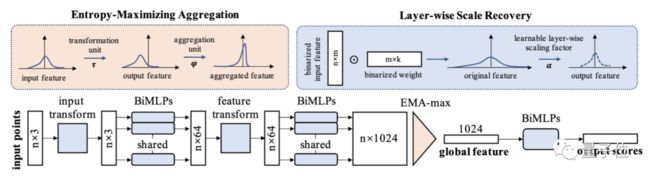
△图 1: BiPointNet 的整体框架图
我们的 BiPointNet 首次实现利用二值化点云网络进行深度学习,并极大地超越了现有的基于 2D 视觉的二值化算法。BiPointNet 的性能表现甚至可以媲美全精度的网络 (准确率相差在 1-2% 以内),它可以被轻易地扩展到其他主流的点云特征提取器上,比如 PointNet++, PointCNN, DGCNN, 和PointConv。BiPointNet 在多种任务上(例如分类、零件分割、语义分割)相较于基线算法都可以取得明显的性能提升。
此外,我们在真实设备上对 BiPointNet 进行了实际测试,实现了 14.7 倍的加速和 18.9 倍存储节省。
方法
点云非结构化(unstructured)的特征导致多层感知机是网络中最常见的结构,而二值化模型包含的是二值化的多层感知机,能够对轻量级的二值化权重和激活执行高效的位运算操作 (XNOR 和 Bitcount) :

其中,Ba 和 Bw 代表二值化激活与权重,⊙ 表示基于位运算的向量内积。
EMA:熵最大化聚合函数
我们的研究表明,由于严重的同质化现象,聚合函数是二值化的一个性能瓶颈。
理想情况下,二值化张量 B 应该尽可能多地保留原始张量 Y 所包含的信息。而当最大池化层的输入呈随机分布时,二值化输出的信息熵随着聚合元素数量 n 趋近于无穷大而趋向于 0。
由于点的数量通常较大 (如 ModelNet40 的分类任务的 n 为 1024 ),这导致不论输入池化层的特征如何,其输出特征总是高度相似的,如图 2 所示。2D 视觉中聚合函数通常用较小的核(ResNet 和 VGG-Net 中使用 2×2 的池化核),问题并不严重。因此,我们需要一类能够使 B 的信息熵最大化的聚合函数,以避免聚合引起的特征同质化问题。

△图 2: 聚合引起的特征同质化问题
我们证明,理论上存在一个分布 Y,通过最大化二值张量 B 的信息熵,能够使得 Y 和 B 的互信息最大化,以尽可能地把 Y 中的信息保留在 B 中。基于此我们提出EMA,一类二值化友好的聚合层,它基于全精度神经网络中的聚合函数,并进一步保留了输入经过变换后的熵。
EMA 的定义是:

其中 φ 表示聚合函数 (例如最大池化和平均池化),τ 表示变换单元,可以有多种形式,我们发现最简单的常数偏移已经十分有效。这个偏移将输入进行移位运算以最大化二值化特征 B 的信息熵。
BiPointNet 中的变换单元 τ 可以被定义为:
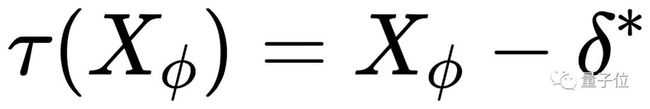
当 φ 表示最大池化时,目标函数的解与 n 无关,从而规避了在点云应用中聚合元素数量 n 过大造成的特征同质化问题。
One-Scale-Fits-All: 逐层尺度恢复
在本节,我们阐述并解决了二值化会导致特征尺度失真的问题。
我们发现,当信息熵取到最大值时,输出特征的尺度与特征通道数直接相关,因此造成尺度的不合理放大,即尺度失真。尺度失真使得一些为 3D 深度学习设计的对尺度较为敏感的结构失效(见图 3),还导致前向传播时的激活和后向传播时的梯度趋于饱和。

△图 3: 尺度失真
为了恢复输出的尺度和调整能力,我们提出在 BiPointNet 的二值线性层中应用 LSR。我们设计了一个可学习的逐层尺度恢复因子 α,并通过二值线性层和全精度的输出之间的标准差来初始化:
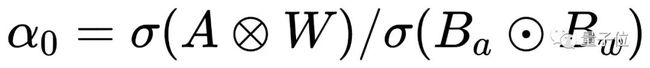
其中,σ 表示标准差。而且 α 在训练过程中是可学习的。具有 LSR 的二值线性层的计算步骤如下:

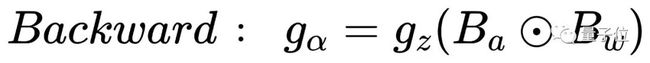
其中, gα 和 gZ 分别表示 a 和 z 的梯度。通过在 BiPointNet 中应用 LSR,我们缓解了由于二值化导致输出尺度失真的问题。
实验
我们的实验表明了 BiPointNet 在点云学习上的强大性能,部分设置下甚至媲美全精度模型。
表 1 中结果表明,同时使用EMA和LSR可以显著缩小二值化模型和全精度模型之间的性能差距。
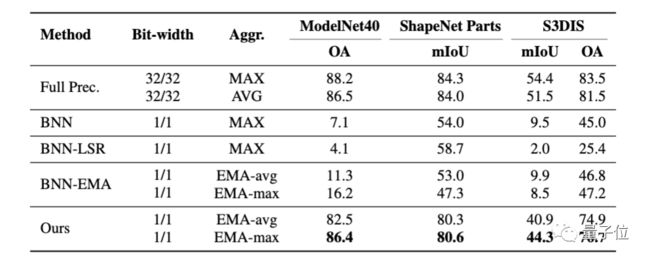
△表1: BiPointNet在ModelNet40 (分类)、
ShapeNet Parts (零件分割)、
S3DIS (语义分割) 上的消融实验
在表 2 中,我们展示了 BiPointNet 优于其他二值化方法。
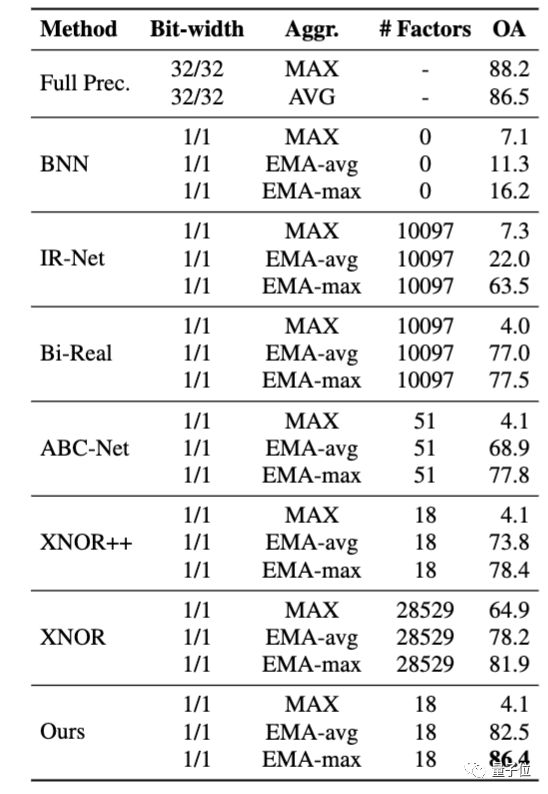
△表2: 基于 PointNet 的二值化方法对比
表 3 展示了在几种主流的点云深度学习模型中取得的提升。

△表3: 在主流骨干网络上应用我们的方法
为了验证 BiPointNet 在真实世界的边缘设备上的高效性,我们还将其部署在ARM CPU Cortex-A72 和Cortex-A53 的树莓派上。尽管PointNet 已经是现有模型中公认的快速、轻量模型,BiPointNet依然带来了14.7倍的推理加速和18.9倍的存储节省。
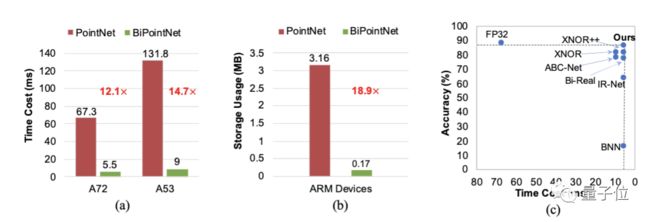
△图 5: (a) 耗时对比;(b) 存储使用对比;
(c) 不同二值化方案速度和准确率的关系散点图
总结
我们提出 BiPointNet 作为第一个在点云上实现高效学习的二值化方法。我们为研究二值化对点云学习模型的影响建立理论基础,并提出了 EMA 和 LSR 方法,提升了模型的性能表现。
BiPointNet 超过了现有的二值化方法,并且能够轻松地扩展到各种任务和骨干模型上。同时,它在资源受限的真实设备上实现了 14.7 倍的加速和 18.9 倍的存储节省。我们的工作证实了模型二值化的巨大潜力,希望这个工作能够为未来的研究打下坚实的基础。
作者介绍
这项研究工作由北京航空航天大学刘祥龙教授团队、商汤新加坡研究团队和加州大学圣迭戈分校共同完成。
北航刘祥龙教授团队近年来围绕模型低比特量化、二值量化、量化训练等方向做出了一系列具有创新性和实用性的研究成果,包括国际首个二值化点云模型BiPointNet、可微分软量化DSQ、量化训练、信息保留二值网络IR-Net等,研究论文发表在ICLR、CVPR、ICCV等国际顶级会议和期刊上。
商汤新加坡研究团队是商汤算法研究能力出海的前哨站,自2020年成立以来,服务国内外智慧城市、智慧文旅等多个新兴行业。产品研发与前沿研究并重,专注感知、重建与生成,技术方向包括场景理解、3D点云、虚拟数字人等。
论文共同第一作者秦浩桐,目前在北京航空航天大学攻读博士,主要研究方向为模型量化压缩与加速、硬件友好的深度学习。
论文共同第一作者蔡中昂,目前在新加坡商汤任算法研究员、南洋理工大学博士一年级,主要研究方向为点云深度学习、虚拟数字人。
论文共同第一作者张明远,目前在新加坡商汤任算法研究员,主要研究方向为多模态场景理解、复杂场景生成。
论文第四作者丁一芙,北京航空航天大学大四学生,目前保送北航软件国家开发环境国家重点实验室直博。
传送门
会议论文:
https://openreview.net/forum?id=9QLRCVysdlO
项目网址:
https://htqin.github.io/Projects/BiPointNet.html
代码地址:
https://github.com/htqin/BiPointNet
北航刘祥龙教授团队主页:
http://sites.nlsde.buaa.edu.cn/~xlliu/
— 完 —
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。
加入AI社群,拓展你的AI行业人脉
量子位「AI社群」招募中!欢迎AI从业者、关注AI行业的小伙伴们扫码加入,与50000+名好友共同关注人工智能行业发展&技术进展:


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~