Android 音频数据流(2): 从 AudioTrack 到 ALSA 驱动
Android 音频数据流(2): 从 AudioTrack 到 ALSA 驱动
注意:本文基于 Android 8.1 进行分析
Qidi 2020.11.17 (Markdown & Haroopad & EnterpriseArchitect)
0. 前言
在上一篇文章《Android 音频数据流(1): 从 MediaPlayer 到 AudioTrack》中,我们分析了音频数据被从数据源读取并写入 AudioTrack 的过程。这一篇文章再来看看数据从 AudioTrack 又是按照什么流程最终写入到 ALSA 驱动节点的。
相对于上一篇文章来说,这部分的逻辑要简洁得多。
1. 类图
先看类关系。简单来说,每有一个 AudioTrack 实例,就会相应地有一个 Track 实例;Track 实例既会从 匿名共享内存(AshMem) 中读取数据,又会被加入到 AudioFlinger::PlaybackThread 中进行统一管理;PlaybackThread 会把数据写入 HAL 层:

2. 时序图
再看写数据过程:
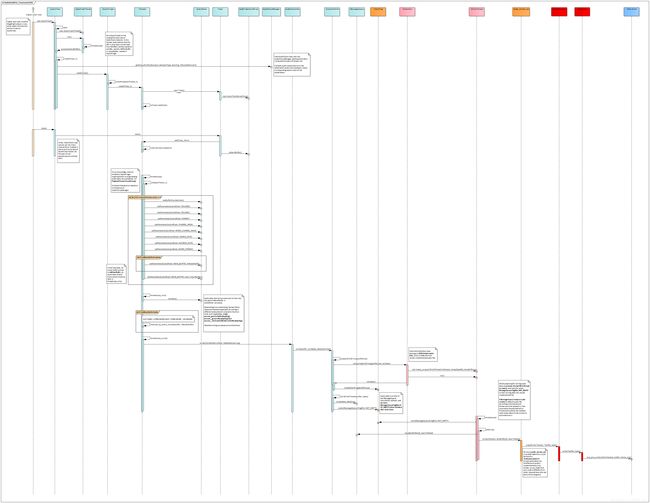
其中 AOSP 部分的逻辑(浅绿色部分)是固定的;HAL 层的实现(粉色和红色部分)则因公司而异,为了流程的完整性,图中列出的实现仅供参考。
正如上文所说,上层部件每创建一个 AudioTrack 实例,都会有一个 Track 实例相应被构造出来。上层部件调用 AudioTrack::write() 写入 匿名共享内存(AshMem) 的音频数据,会在这个 Track 实例中被读取出来,随后,该 Track 实例会被加入到 PlaybackThread 的成员变量 mTracks 中,对应的音频数据也会在 AudioFlinger 中作混音处理。
当 AudioTrack::start() 被调用后,上述 Track 实例就被加入到了 PlaybackThread 的 mActiveTracks 成员中。这是一个 SortedVector 容器类型的变量,它所包含的 Track 实例是动态变化的,代表所有当前处于活跃(播放)状态的 Track 实例。 AudioFlinger 中的混音对象,就是该容器中的这些 Track。
在 AudioFlinger 中有独立的线程负责完成音频数据的混音、读(录音)和 写(播放)工作。其中,MixerThread 负责混音的过程,主要分为 2 步:
- 汇总数据,即把所有数据写入同一个内存区。在
prepareTracks_l()函数中完成; - 处理数据,即真正进行混音操作。在
threadLoop_mix()函数中完成。
因为 MixerThread 继承自 PlaybackThread,所以其 threadLoop() 函数的关键代码逻辑如下:
bool AudioFlinger::PlaybackThread::threadLoop()
{
//......
while (!exitPending())
{
//......
Vector< sp<EffectChain> > effectChains;
{
// scope for mLock
Mutex::Autolock _l(mLock);
processConfigEvents_l();
//......
// mMixerStatusIgnoringFastTracks is also updated internally
mMixerStatus = prepareTracks_l(&tracksToRemove);
mActiveTracks.updatePowerState(this);
// prevent any changes in effect chain list and in each effect chain
// during mixing and effect process as the audio buffers could be deleted
// or modified if an effect is created or deleted
lockEffectChains_l(effectChains);
} // mLock scope ends
if (mBytesRemaining == 0) {
mCurrentWriteLength = 0;
if (mMixerStatus == MIXER_TRACKS_READY) {
// threadLoop_mix() sets mCurrentWriteLength
threadLoop_mix();
} else if ((mMixerStatus != MIXER_DRAIN_TRACK)
&& (mMixerStatus != MIXER_DRAIN_ALL)) {
// threadLoop_sleepTime sets mSleepTimeUs to 0 if data
// must be written to HAL
threadLoop_sleepTime();
if (mSleepTimeUs == 0) {
mCurrentWriteLength = mSinkBufferSize;
}
}
//......
if (mMixerBufferValid) {
void *buffer = mEffectBufferValid ? mEffectBuffer : mSinkBuffer;
audio_format_t format = mEffectBufferValid ? mEffectBufferFormat : mFormat;
// mono blend occurs for mixer threads only (not direct or offloaded)
// and is handled here if we're going directly to the sink.
if (requireMonoBlend() && !mEffectBufferValid) {
mono_blend(mMixerBuffer, mMixerBufferFormat, mChannelCount, mNormalFrameCount,
true /*limit*/);
}
memcpy_by_audio_format(buffer, format, mMixerBuffer, mMixerBufferFormat,
mNormalFrameCount * mChannelCount);
}
//......
}
//......
}
再来细看 prepareTracks_l() 函数。在这里,所有处于活跃状态的 Track 实例从 AshMem 中读出音频数据,并写入 mMixerBuffer 指向的内存区。各 Track 实例的音频参数也在这个过程中被写入 AudioMixer 对象:
AudioFlinger::PlaybackThread::mixer_state AudioFlinger::MixerThread::prepareTracks_l(
Vector< sp<Track> > *tracksToRemove)
{
//......
// find out which tracks need to be processed
size_t count = mActiveTracks.size();
//......
for (size_t i=0 ; i<count ; i++) {
const sp<Track> t = mActiveTracks[i];
// this const just means the local variable doesn't change
Track* const track = t.get();
// process fast tracks
{
// local variable scope to avoid goto warning
audio_track_cblk_t* cblk = track->cblk();
//......
size_t framesReady = track->framesReady();
//......
if ((framesReady >= minFrames) && track->isReady() &&
!track->isPaused() && !track->isTerminated())
{
ALOGVV("track %d s=%08x [OK] on thread %p", name, cblk->mServer, this);
mixedTracks++;
// track->mainBuffer() != mSinkBuffer or mMixerBuffer means
// there is an effect chain connected to the track
chain.clear();
if (track->mainBuffer() != mSinkBuffer &&
track->mainBuffer() != mMixerBuffer) {
if (mEffectBufferEnabled) {
mEffectBufferValid = true; // Later can set directly.
}
chain = getEffectChain_l(track->sessionId());
// Delegate volume control to effect in track effect chain if needed
if (chain != 0) {
tracksWithEffect++;
} else {
ALOGW("prepareTracks_l(): track %d attached to effect but no chain found on "
"session %d",
name, track->sessionId());
}
}
//......
// XXX: these things DON'T need to be done each time
mAudioMixer->setBufferProvider(name, track);
mAudioMixer->enable(name);
mAudioMixer->setParameter(name, param, AudioMixer::VOLUME0, &vlf);
mAudioMixer->setParameter(name, param, AudioMixer::VOLUME1, &vrf);
mAudioMixer->setParameter(name, param, AudioMixer::AUXLEVEL, &vaf);
mAudioMixer->setParameter(
name,
AudioMixer::TRACK,
AudioMixer::FORMAT, (void *)track->format());
mAudioMixer->setParameter(
name,
AudioMixer::TRACK,
AudioMixer::CHANNEL_MASK, (void *)(uintptr_t)track->channelMask());
mAudioMixer->setParameter(
name,
AudioMixer::TRACK,
AudioMixer::MIXER_CHANNEL_MASK, (void *)(uintptr_t)mChannelMask);
// limit track sample rate to 2 x output sample rate, which changes at re-configuration
uint32_t maxSampleRate = mSampleRate * AUDIO_RESAMPLER_DOWN_RATIO_MAX;
uint32_t reqSampleRate = track->mAudioTrackServerProxy->getSampleRate();
if (reqSampleRate == 0) {
reqSampleRate = mSampleRate;
} else if (reqSampleRate > maxSampleRate) {
reqSampleRate = maxSampleRate;
}
mAudioMixer->setParameter(
name,
AudioMixer::RESAMPLE,
AudioMixer::SAMPLE_RATE,
(void *)(uintptr_t)reqSampleRate);
AudioPlaybackRate playbackRate = track->mAudioTrackServerProxy->getPlaybackRate();
mAudioMixer->setParameter(
name,
AudioMixer::TIMESTRETCH,
AudioMixer::PLAYBACK_RATE,
&playbackRate);
/*
* Select the appropriate output buffer for the track.
*
* Tracks with effects go into their own effects chain buffer
* and from there into either mEffectBuffer or mSinkBuffer.
*
* Other tracks can use mMixerBuffer for higher precision
* channel accumulation. If this buffer is enabled
* (mMixerBufferEnabled true), then selected tracks will accumulate
* into it.
*
*/
if (mMixerBufferEnabled
&& (track->mainBuffer() == mSinkBuffer
|| track->mainBuffer() == mMixerBuffer)) {
mAudioMixer->setParameter(
name,
AudioMixer::TRACK,
AudioMixer::MIXER_FORMAT, (void *)mMixerBufferFormat);
mAudioMixer->setParameter(
name,
AudioMixer::TRACK,
AudioMixer::MAIN_BUFFER, (void *)mMixerBuffer);
// TODO: override track->mainBuffer()?
mMixerBufferValid = true;
} else {
//......
}
mAudioMixer->setParameter(
name,
AudioMixer::TRACK,
AudioMixer::AUX_BUFFER, (void *)track->auxBuffer());
//......
} else {
//......
}
} // local variable scope to avoid goto warning
}
//......
// remove all the tracks that need to be...
removeTracks_l(*tracksToRemove);
if (getEffectChain_l(AUDIO_SESSION_OUTPUT_MIX) != 0) {
mEffectBufferValid = true;
}
if (mEffectBufferValid) {
// as long as there are effects we should clear the effects buffer, to avoid
// passing a non-clean buffer to the effect chain
memset(mEffectBuffer, 0, mEffectBufferSize);
}
//......
return mixerStatus;
}
现在 AudioMixer 对象已经持有了各个 Track 的数据和参数。随后在 MixerThread::threadLoop_mix() 中, AudioMixer::process() 被调用,开始真正进行混音处理:
void AudioFlinger::MixerThread::threadLoop_mix()
{
// mix buffers...
mAudioMixer->process();
// ......
}
混音完成后,还是在 PlaybackThread::threadLoop() 中,代码执行到 PlaybackThread::threadLoop_write(),混音后的数据在这里被写入 HAL 层:
bool AudioFlinger::PlaybackThread::threadLoop()
{
//......
while (!exitPending())
{
//......
if (mEffectBufferValid) {
//ALOGV("writing effect buffer to sink buffer format %#x", mFormat);
if (requireMonoBlend()) {
mono_blend(mEffectBuffer, mEffectBufferFormat, mChannelCount, mNormalFrameCount,
true /*limit*/);
}
memcpy_by_audio_format(mSinkBuffer, mFormat, mEffectBuffer, mEffectBufferFormat,
mNormalFrameCount * mChannelCount);
}
// enable changes in effect chain
unlockEffectChains(effectChains);
if (!waitingAsyncCallback()) {
// mSleepTimeUs == 0 means we must write to audio hardware
if (mSleepTimeUs == 0) {
ssize_t ret = 0;
// We save lastWriteFinished here, as previousLastWriteFinished,
// for throttling. On thread start, previousLastWriteFinished will be
// set to -1, which properly results in no throttling after the first write.
nsecs_t previousLastWriteFinished = lastWriteFinished;
nsecs_t delta = 0;
if (mBytesRemaining) {
// FIXME rewrite to reduce number of system calls
mLastWriteTime = systemTime(); // also used for dumpsys
ret = threadLoop_write();
lastWriteFinished = systemTime();
delta = lastWriteFinished - mLastWriteTime;
if (ret < 0) {
mBytesRemaining = 0;
} else {
mBytesWritten += ret;
mBytesRemaining -= ret;
mFramesWritten += ret / mFrameSize;
}
} else if ((mMixerStatus == MIXER_DRAIN_TRACK) ||
(mMixerStatus == MIXER_DRAIN_ALL)) {
threadLoop_drain();
}
if (mType == MIXER && !mStandby) {
// write blocked detection
if (delta > maxPeriod) {
mNumDelayedWrites++;
if ((lastWriteFinished - lastWarning) > kWarningThrottleNs) {
ATRACE_NAME("underrun");
ALOGW("write blocked for %llu msecs, %d delayed writes, thread %p",
(unsigned long long) ns2ms(delta), mNumDelayedWrites, this);
lastWarning = lastWriteFinished;
}
}
//......
}
} else {
//......
}
}
// Finally let go of removed track(s), without the lock held
// since we can't guarantee the destructors won't acquire that
// same lock. This will also mutate and push a new fast mixer state.
threadLoop_removeTracks(tracksToRemove);
tracksToRemove.clear();
// FIXME I don't understand the need for this here;
// it was in the original code but maybe the
// assignment in saveOutputTracks() makes this unnecessary?
clearOutputTracks();
// Effect chains will be actually deleted here if they were removed from
// mEffectChains list during mixing or effects processing
effectChains.clear();
// FIXME Note that the above .clear() is no longer necessary since effectChains
// is now local to this block, but will keep it for now (at least until merge done).
}
threadLoop_exit();
if (!mStandby) {
threadLoop_standby();
mStandby = true;
}
releaseWakeLock();
ALOGV("Thread %p type %d exiting", this, mType);
return false;
}
HAL 层的实现因公司而异,一般各公司也不允许将这部分代码对外公开,所以此处略去细节。
但无论各家 HAL 的具体内容如何,肯定都是对 /hardware/libhardware/include/hardware/audio.h 中定义的各接口的实现( audio_stream_out 结构里声明了 write() 接口),且数据去向也是一致的 —— 最终都是调用 ALSA-Lib,通过 snd_pcm_writei() 将数据写入驱动。
至此,我们对 Android 音频数据流的 从数据源读取数据 到 写入驱动设备节点 的过程就大致清楚了。