python爬虫——批量爬取百度图片
最近做项目,需要一些数据集,图片一张一张从网上下载太慢了,于是学了爬虫。
参考了大佬的文章:https://blog.csdn.net/qq_40774175/article/details/81273198
首先打开命令行,安装requests库
pip install requests
百度图片搜索的链接如下:
url='http://image.baidu.com/search/index?tn=baiduimage&fm=result&ie=utf-8&word='#百度链接
不信你在=后面加上要搜索的关键字,放在浏览器里试试。
下面分析一波百度图片,随便搜点什么东西,在浏览器里按F12打开开发者模式:
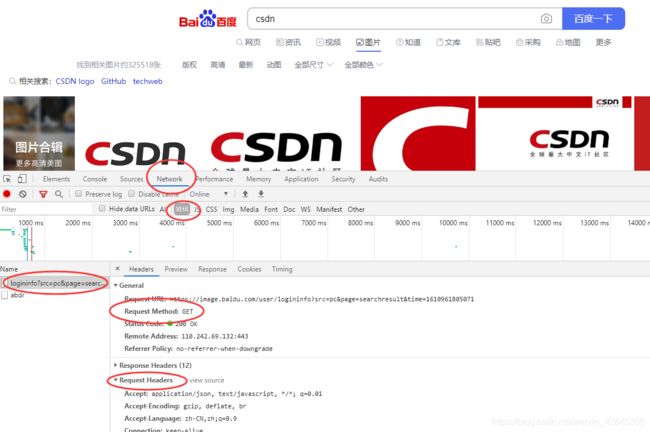
点Network标签、XHR、选上面那个name,可以看到请求方式是GET(另一种方式是POST),还有Request Headers中相关参数,表示浏览器访问的数据头。
下面伪装一个headers用来假装是浏览器访问:
headers = {
#文件头,必须有,否则会安全验证
"Accept":"application/json, text/javascript, */*; q=0.01",
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36",
'Host': 'image.baidu.com',
'Referer': 'https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=&st=-1&fm=result&fr=&sf=1&fmq=1610952036123_R&pv=&ic=&nc=1&z=&hd=&latest=©right=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&sid=&word=%E6%98%9F%E9%99%85',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'X-Requested-With': 'XMLHttpRequest'
}
从上图的分析中可以看到Request Headers中相关参数,照着格式往里面写就行了,每个人可能不一样。最好都写上,如果有错误或者遗漏,GET到的网页信息将会是百度安全验证,这是因为百度认为你是机器访问。(解决这个问题花了好久)
下面爬取网页数据并存在data.txt中进一步分析
strhtml=requests.get(url,headers=headers)#get方式获取数据
string=str(strhtml.text)
with open("data.txt","w",encoding='utf-8') as f:#这个编码是个问题
f.write(string) #这句话自带文件关闭功能,不需要再写f.close()
print("已爬取,数据存入data.txt")
注意这里的解码方式,如果utf-8是乱码,可以试试GBK或者ISO-8859-1。没有解码方式会报错。
在网页中按Ctrl+U查看源码

分析一波发现,带有thumbURL的后面含有我们要下载的图片链接。
用正则表达式在我们爬到的网页数据中找:
img_url_regex = '"thumbURL":"(.*?)",'#正则匹配式
pic_url = re.findall(img_url_regex, string) # 先利用正则表达式找到图片url
注意用正则匹配式需要import re
查阅re手册可知,.是匹配任意字符,*是匹配前一个元字符0到多次,?是匹配前一个元字符0到1次
findall的第一个参数是正则匹配式,第二个是要源文本,返回一个list
找到图片链接后,再用一遍get就很容易获得图片了,用文件操作把信息保存成一个.jpg即可。
有一个问题,就是一次搜索只能搜集大概30张图片,百度图片一页只能显示这么多,正常浏览是靠滚轮向下拉获得更多图片,那么爬虫怎么办呢?
解决办法:在URL链接最后面(包括关键字)加上&pn=
事实证明,&pn=表示当前页,注意,如果&pn=0时显示1-30张图片,&pn=1时则显示2-31张图片,因此每一页下载完图片后,需要计算此页共计多少张图片(len(pic_url )就能完事),然后再加到&pn=后面。
下载完一页接着下一页,直到全部下载完。
完整代码如下:
import requests#爬虫库
import re#正则表达式库
import os#系统库
import time#时间库
headers = {
#文件头,必须有,否则会安全验证
"Accept":"application/json, text/javascript, */*; q=0.01",
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36",
'Host': 'image.baidu.com',
'Referer': 'https://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=&st=-1&fm=result&fr=&sf=1&fmq=1610952036123_R&pv=&ic=&nc=1&z=&hd=&latest=©right=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&sid=&word=%E6%98%9F%E9%99%85',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'X-Requested-With': 'XMLHttpRequest'
}
url='http://image.baidu.com/search/index?tn=baiduimage&fm=result&ie=utf-8&word='#百度链接
print("@非常道")
keyword=input("请输入图片关键词:")
# keyword='cyberpunk'
countmax=eval(input("请输入要爬取的图片数量:"))
url=url+keyword+"&pn="
time_start=time.time()#获取初始时间
strhtml=requests.get(url,headers=headers)#get方式获取数据
string=str(strhtml.text)
# with open("data.txt","w",encoding='utf-8') as f:#这个编码是个问题
# f.write(string) #这句话自带文件关闭功能,不需要再写f.close()
# print("已爬取,数据存入data.txt")
#正则表达式取得图片总数量
totalnum = re.findall('(.*?)', string)
print("百度图片"+totalnum[0])
img_url_regex = '"thumbURL":"(.*?)",'#正则匹配式
count=0#总共下载的图片数
index=0#链接后面的序号
page=0#当前搜集的页
while(1):
strhtml=requests.get(url+str(index),headers=headers)#get方式获取数据
string=str(strhtml.text)
print("已爬取网页")
pic_url = re.findall(img_url_regex, string) # 先利用正则表达式找到图片url
print("第"+str(page+1)+"页共收集到"+str(len(pic_url))+"张图片")
index+=len(pic_url)#网址索引向后,跳到下一页继续搜刮图片
try:#如果没有文件夹就创建
os.mkdir('.'+r'\\' + keyword)
except:
pass
for each in pic_url:
print('正在下载第' + str(count + 1) + '张图片,图片地址:' + str(each))
try:
if each is not None:
pic = requests.get(each, timeout=5)
else:
continue
except BaseException:
print('错误,当前图片无法下载')
continue
else:
string = '.' + r'\\' + keyword + r'\\' + keyword + '_' + str(count+1) + '.jpg'
fp = open(string, 'wb')
fp.write(pic.content)
fp.close()
count += 1
if countmax==count:
break
if countmax==count:
break
time_end=time.time()#获取结束时间
print('处理完毕,共耗时:'+str(time_end-time_start)+"秒")
input("@非常道 按任意键继续")
咱也不是学html的,也不是学计算机的,会用就行……
有问题评论,没问题点赞 ↓ ↓ ↓ \downarrow\downarrow\downarrow ↓↓↓