python爬虫练习--爬取虎牙主播原画视频
此文章和代码仅供学习交流,请勿他用
目录
- 前言
- 爬取过程
- 爬取效果
- 完整代码
前言
- 使用的python库:os、requests、bs4
- 涉及动态数据的爬取
- 下载视频时使用断点续传技术
爬取过程
打开虎牙主播的主页看一下
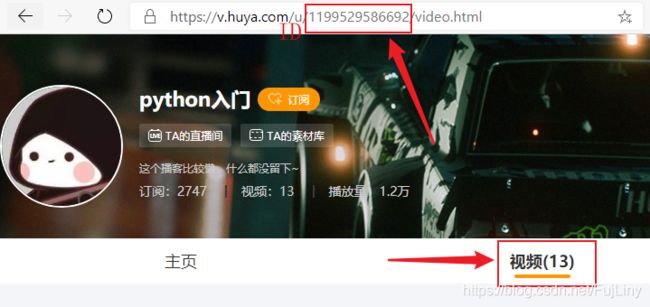
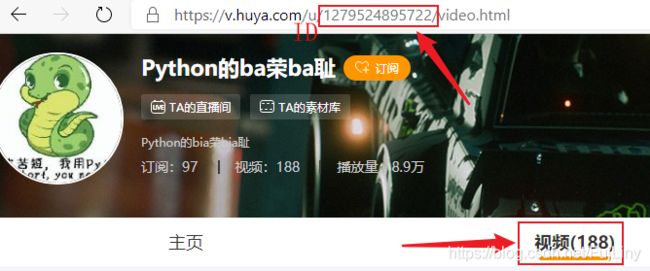
每一个主播的视频页面中,都会对应一个id值。通过这个id值就可以找到虎牙主播的视频主页。
我们可以把代码封装起来,想要爬取哪一个主播的视频,只需要修改主播ID值就好了。
class HuyaSpider:
def __init__(self,host_id):
self.url = 'https://v.huya.com/u/{}/video.html'.format(host_id)
def get_html(self):
pass
def save_file(self):
pass
def spider_start(self):
pass
h = HuyaSpider(1199529586692)
大致框架先列出来:
- 定义一个
HuyaSpider类,在实例化的时候需要传入一个参数:主播ID get_html(self)方法用来获取网页内容save_file(self)方法用来把视频保存至文件中spider_start(self)方法用来启动爬虫

初始工作已做好,开始分析网页
查看主播视频网页的源代码,找到视频列表:
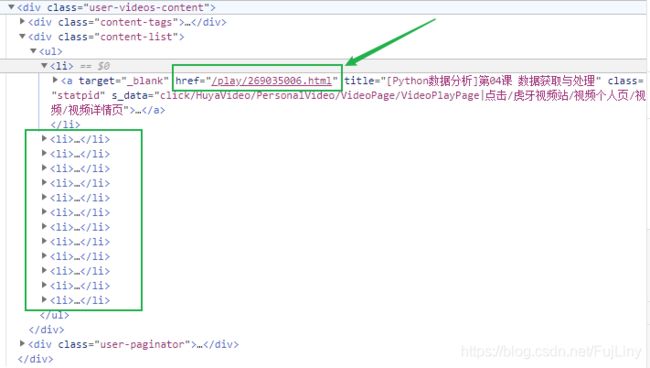
每一个视频的网页地址在源代码上找得到(经过测试,通过requests请求能够真实得到)

接下来进入一个视频网页看看
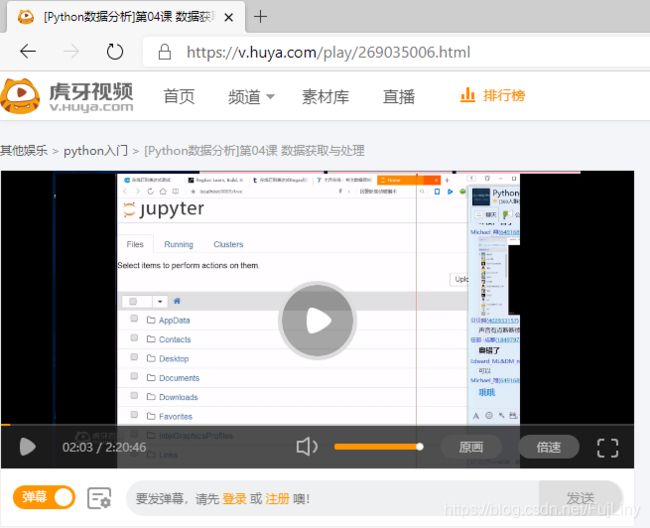
分析源代码,目的是要拿到视频的具体地址
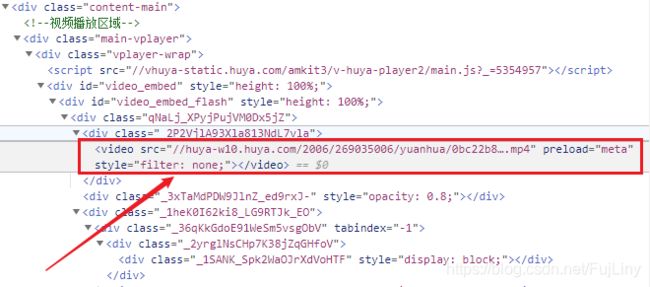
在浏览器查看的网页源代码中,找到了视频的url,看起来好像都是挺简单的,其实不然。
经过测试,requests请求得到的源代码中,是不包含上面方框圈中的标签的,也就是说从requests请求得到的源代码中是得不到视频的真实url。
因为,这是动态加载的数据,真正的视频url不会放在源网页中,而是通过别的请求得到之后再放进网页里。
所以,现在我们就要找到这个所谓的别的请求,拿到视频的url。
当然我们可以用selenium来实现抓取动态数据(selenium实现,本文不作讲解)
在浏览器源代码中把视频url拷贝一下,到浏览器开发者工具里的network里面搜索一下,
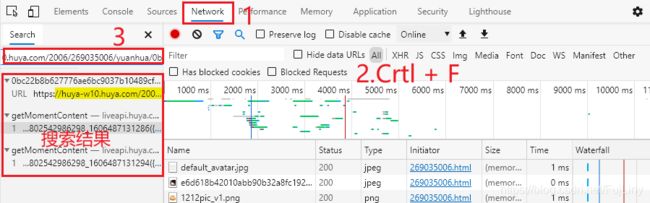
在搜索结果中有3条请求数据包含视频url。
仔细查看一下这些请求的请求体和返回的内容
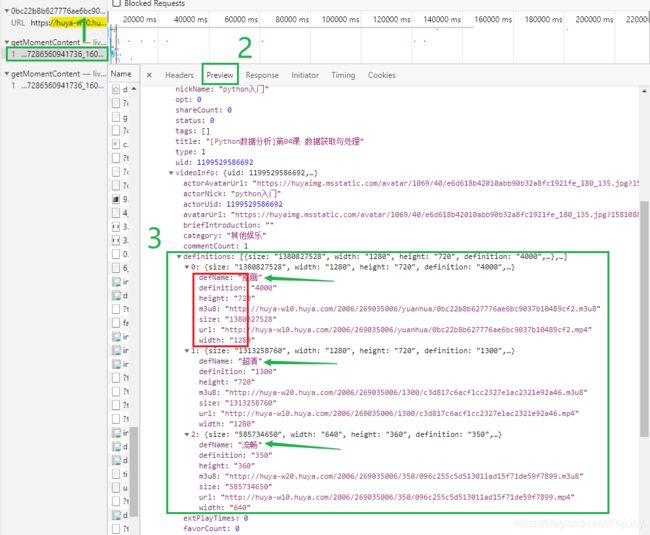
这是json格式的数据,3号绿色方框中,在definitions的值是一个列表,列表里有3个元素,每个元素中又是好几个的字典,包含画质,视频的高度和宽度,视频的大小,最重要的还包含视频的m3u8链接和url。
现在,我们在这个请求数据中不仅找到原画视频的url,而且超清,流畅的视频url都找到了。
只要我们能构造这个请求就可以搞定了
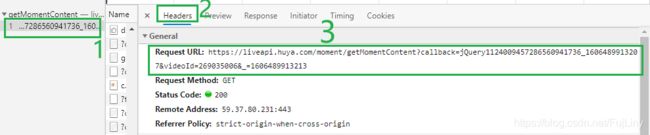
Request URL :
https://liveapi.huya.com/moment/getMomentContent?callback=jQuery1124009457286560941736_1606489913207&videoId=269035006&_=1606489913213
这个请求是由callback、videoId、uid 组成的,
vedioId很好理解,大概就是视频的id,另外两个callback和uid还不知道是什么,删掉试试??
删掉之后:https://liveapi.huya.com/moment/getMomentContent?videoId=269035006
试访问一下这个链接

我们还是拿到了这个数据,这说明videoId才是构造url的关键字段,另外两个不是必须的。
那么这个videoId=269035006是如何来的呢?
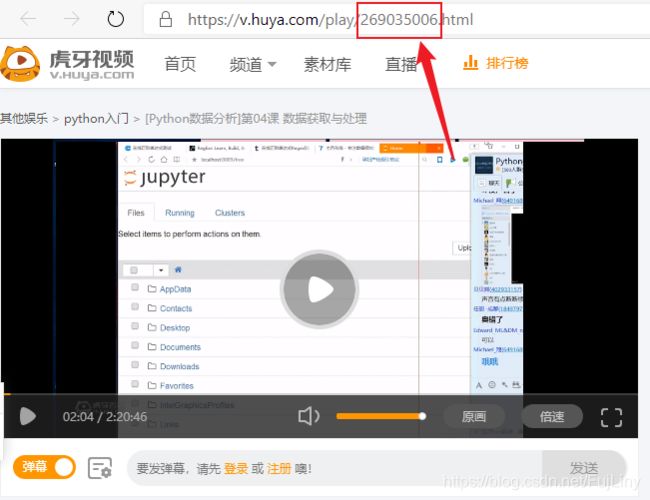
这个videoId不就正好在那嘛。
分析完了哦

从头到尾捋一下爬虫思路:
- 通过主播id构造出主播视频网页的url
- 从网页源代码中获取每个视频的网页url,并记住videoId值,
- 通过videoId构造url,请求得到json格式的数据
- 从json格式的数据中拿到真正视频的url,接着下载视频。
- 下载视频时采用断点续传的方式
下载视频和断点续传这里就不作讲解了。
有关断点续传的内容可浏览:https://blog.csdn.net/FujLiny/article/details/110098858
断点续传可避免重复下载同一个视频以及能够接着上一次下载的地方继续下载
爬取效果
(演示的是爬取别的主播)

完整代码
# Author:FuJLiny
# CSDN blog homepage:https://blog.csdn.net/FujLiny
# ------version 1-1,Update time:2020/11/28------
import os
import requests
from bs4 import BeautifulSoup
class HuyaSpider:
def __init__(self, Id):
self.url = 'https://v.huya.com/u/{}/video.html'.format(Id)
self.place = 'F:/' # 保存路径
self.videoAll = []
def get_html(self):
soup = BeautifulSoup(requests.get(self.url).text, 'lxml')
vc = soup.select('a[class="statpid selected"]')[0].text[3:-1]
vPage = (eval(vc) // 15) + 1 # (视频总数 // 15) + 1 = 视频总页数
# 遍历每一页
for i in range(1,vPage+1):
url = self.url + '?sort=news&p=%s' % i
soup = BeautifulSoup(requests.get(url).text, 'lxml')
for item in soup.select('div[class="content-list"] ul li a'):
videoId = item['href'].split('/')[-1][:-5]
dataUrl = 'https://liveapi.huya.com/moment/getMomentContent?&videoId=%s' % videoId
data = requests.get(dataUrl).json()
vTitle = data['data']['moment']['title']
vSize = data['data']['moment']['videoInfo']['definitions'][0]['size']
vUrl = data['data']['moment']['videoInfo']['definitions'][0]['url']
# 把获取到的视频标题、视频大小、视频url保存到一个字典中,并把该字典保存到列表
self.videoAll.append({
'title':vTitle, 'size':vSize, 'url':vUrl})
print('\r获取到%s个视频链接'%len(self.videoAll),end='')
def save_file(self, name, size, url):
name = self.place + '%s.mp4' % name
size = eval(size)
try:
# 构造断点续传的headers
# 关于断点续传的内容可浏览文章:https://blog.csdn.net/FujLiny/article/details/110098858
fileSize = os.path.getsize(name)
if fileSize < size:
head = {
'Range': 'bytes=%d-' % fileSize}
mode = 'ab'
else:
return
except FileNotFoundError:
fileSize = 0
head = {
'Range': 'bytes=%d-' % 0}
mode = 'wb'
print('\n正在下载:', name)
r = requests.get(url, headers=head, stream=True)
with open(name, mode=mode)as fp:
completeSize = 0
for item in r.iter_content(200000):
fp.write(item)
completeSize += len(item)
dt = completeSize / (size-fileSize)
print('\r下载进度:'+'*'*(int(dt*50))+'%.2f%%'%(dt*100), end='')
def spider_start(self):
self.get_html()
print('\n该主播共有%s个视频,开始爬取:'%len(self.videoAll))
for item in self.videoAll:
self.save_file(item['title'],item['size'], item['url'])
if __name__ == '__main__':
h = HuyaSpider(1199529586692)
h.spider_start()