Java版Word转PDF实现在线预览功能——使用LibreOffice+PDF.js组合实现
大家好,很高兴我们又见面了。记录时间:2020-10-14
最近项目中涉及到word在线预览的需求,由于word的在线预览对于格式的把控较为复杂,因此考虑将word转换成PDF进行在线预览,对于PDF的在线预览解决方案,网上谈到的比较多,针对于word转成PDF的后端解决方案不够清晰完整,比较杂乱。于是,集各家之所长,结合实际的环境,有了这一篇。
话不多说,上才艺。我会尽可能的详细,并把测试时踩过的坑一一进行说明。
内容较多,有目录,不迷路。
- 一、技术栈
- 二、功能
- 三、LibreOffice6.4.6安装——以Windows为例
-
- 1. 下载安装包
- 2. 安装LibreOffice
- 四、打开IDEA,创建一个最基础的SpringBoot项目
- 五、完成word转换成PDF的后端代码
-
- 1. 引入workable-converter依赖
- 2. 编辑项目配置文件,添加workable-converter的配置信息
- 3. 执行转换
-
- 1. 按照文件路径转换(代码原封摘抄)
- 2. 按照输入输出流转换(笔者测试时代码)
- 六、使用PDF.js完成在线预览功能
-
- 1. 官网下载PDF.js,解压,将文件夹重命名为pdfjs
- 七、测试效果与总结
一、技术栈
- LibreOffice6.4.6 官网:LibreOffice
- workable-converter 基于LibreOffice实现的文档转换项目,无框架依赖,即插即用。国内码云地址
- PDF.js(pdfjs-2.5.207-es5-dist) 官网:PDF.js
- jdk1.7+
- Tomcat7.0+
- IDEA
- 后端使用SpringBoot快速搭建word转pdf测试项目
二、功能
基于LibreOffice+PDF.js实现word转成PDF,然后在浏览器在线预览。
前端在线预览部分比较简单,使用PDF.js。
后端转换部分借助LibreOffice。
三、LibreOffice6.4.6安装——以Windows为例
1. 下载安装包
首先,去LibreOffice官网下载安装包,笔者在写这篇博文时最新的稳定版还是LibreOffice_6.4.6_Win_x64.msi,由于网络的问题,可以选择国内镜像进行下载,速度较快,在官网都有提供,比较人性化。
2. 安装LibreOffice
Windows平台安装软件的最大好处就是傻瓜式安装,一直下一步就行,鉴于本文后续内容较多,因此,不再对安装过程进行解释说明,一直点击下一步,直至安装完成即可。
安装完成后,请记住LibreOffice的安装目录,在后续的具体配置中需要用到。
默认目录:(具体还是得根据自己系统环境确认一下)
-
CentOS: /opt/libreoffice6.4/
-
Mac: /Applications/LibreOffice.app/Contents/
-
Windows: C:\Program Files\LibreOffice\
四、打开IDEA,创建一个最基础的SpringBoot项目
如何使用IDEA快速上手创建一个SpringBoot项目,相信百度上一大堆优秀的博文都介绍的很详细,在此不过多介绍,只是说明一点,在选择Dependencies的时候,仅仅选择SpringWeb即可。如下图所示。

当项目创建完成以后,目录如下图所示。
在pdfview包下新建controller包,创建ViewPDFController类,类的内容如下:
package com.ieslab.pdfview.controller;
import org.springframework.stereotype.Controller;
import org.springframework.validation.annotation.Validated;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.ResponseBody;
/**
* @version V1.0
* @Title:
* @Package com.ieslab.pdfview.controller
* @Description: TODO
* @author: zongmoumou
* @date 2020/10/13
*/
@Controller
@RequestMapping("/viewfile")
public class ViewPdfController {
@RequestMapping(value = "/pdf", method = RequestMethod.GET)
@ResponseBody
@Validated
public String viewPdf() {
return "Hello PDF!";
}
}
找到SpringBoot项目的启动类,运行项目,在地址栏输入访问路径,验证项目创建无误即可。如图:

我这里是将端口号在配置文件中改为了8081,如果没有修改的话,默认应该是8080,即url:localhost:8080/viewfile/pdf
创建好白板项目,接下来就是我们大展身手的时候了。
五、完成word转换成PDF的后端代码
1. 引入workable-converter依赖
- Maven
<dependency>
<groupId>com.liumapp.workable.convertergroupId>
<artifactId>workable-converterartifactId>
<version>v1.4.2version>
dependency>
打开项目的pom.xml文件,添加以上依赖。
2. 编辑项目配置文件,添加workable-converter的配置信息
在项目的resources目录下,创建一个yml配置文件,需要确保文件名称为application.yml、bootstrap.yml或workable-converter.yml三种命名任意一个即可
在application.yml中添加如下配置:
com:
liumapp:
workable-converter:
libreofficePath: "/Applications/LibreOffice.app/Contents"
注意:关于yml配置的格式问题,在此不过多介绍,一定要保证缩进正确,否则读取不到配置信息,造成程序运行错误。
3. 执行转换
封装的所谓转换程序,底层的原理基本都是调用LibreOffice提供的命令行命令执行转换
可以有三种方式执行转换
- 按照文件路径转换
- 按照输入输出流转换
- 按照文件Base64转换
对于以上前两种方式,本文都将核心代码摘抄过来,完整详细的workable-converter介绍内容请移步技术栈中给出的项目地址查看。
笔者对于输入输出流的方式和文件路径的方式都进行过测试,没有问题,对于第三种Base64方式,暂时没有进行测试。
1. 按照文件路径转换(代码原封摘抄)
WorkableConverter converter = new WorkableConverter();//实例化的同时,初始化配置项,配置项的校验通过Decorator装饰
ConvertPattern pattern = ConvertPatternManager.getInstance();
pattern.fileToFile("./data/test.doc", "./data/pdf/result1.pdf"); //test.doc为待转换文件路径,result1.pdf为转换结果存储路径
pattern.setSrcFilePrefix(DefaultDocumentFormatRegistry.DOC);
pattern.setDestFilePrefix(DefaultDocumentFormatRegistry.PDF);
converter.setConverterType(CommonConverterManager.getInstance());//策略模式,后续实现了新的转换策略后,在此处更换,图片转换将考虑使用新的策略来完成
boolean result = converter.convert(pattern.getParameter();
2. 按照输入输出流转换(笔者测试时代码)
笔者在实际测试时,根据官方的代码进行了修改和定制。具体如下:
WorkableConverter converter = new WorkableConverter();
ConvertPattern pattern = ConvertPatternManager.getInstance();
pattern.streamToStream(new FileInputStream("./data/test.doc"), new FileOutputStream("./data/pdf/result1_2.pdf"));
// attention !!! convert by stream must set prefix.
pattern.setSrcFilePrefix(DefaultDocumentFormatRegistry.DOC);
pattern.setDestFilePrefix(DefaultDocumentFormatRegistry.PDF);
converter.setConverterType(CommonConverterManager.getInstance());
boolean result = converter.convert(pattern.getParameter();
跟上例基本相同,唯一的变化是通过pattern.streamToStream()来设置输入输出流,转换源文件数据从输入流中读取,转换结果会直接写入输出流中,
同时要切换转换格式,跟上例一样设置不同的prefix即可
重点来了,笔者个人在学习其他博文时,最头疼的就是仅仅贴出部分代码,而没有详细的出处,导致根本无从下手,因此,笔者在完善个人博文时,可能大家觉得比较啰嗦,但还是想尽可能的照顾到像我这种小白玩家。以下是笔者实际的测试代码建立过程*
首先,在pdfview包下,创建service.fileservice.PdfService类,新建wordToPdf静态方法
具体代码如下:
public static void wordToPdf(String address, HttpServletResponse response) throws IOException, ConvertFailedException {
String uuid = UUID.randomUUID().toString().replaceAll("-", "");
String tempFilePath = "temp-" + uuid + ".pdf";
WorkableConverter converter = new WorkableConverter();
ConvertPattern pattern = ConvertPatternManager.getInstance();
pattern.streamToStream(new FileInputStream(address), new FileOutputStream(tempFilePath));
pattern.setSrcFilePrefix(DefaultDocumentFormatRegistry.DOCX);
pattern.setDestFilePrefix(DefaultDocumentFormatRegistry.PDF);
converter.setConverterType(CommonConverterManager.getInstance());
boolean result = converter.convert(pattern.getParameter());
}
}
其中,address,是word文档的路径,在后期的工作中,将改成输入输出流形式,即,以输入流的形式给出word源文件。
至于选择何种方式,是由实际的情况来决定的,笔者在开发在线预览模块时,相应的word下载模块已经由其他老师开发完成,因此,我能拿到的就是一个word文件流。具体何种方式,对于转换的性能和效果影响不明显,可放心大胆的自由选择。
整个在线预览的实现思路就是:(应该放到最开始进行说明)
获取到word文档输出流,作为转换的输入流输入,调用封装好的转换代码,将word文档转换为临时的pdf文件,存储于项目根目录下,为了避免命名冲突,临时pdf的命名格式以temp-加上UUID作为文件名称,然后将临时pdf写入到response的输出流中,写入完成就删除掉临时的pdf文件。此时,在浏览器中访问路径,会下载到转换完成的pdf文件。为了实现在线预览的功能,我们将此输出流作为PDF.js的输入流,使用PDF.js就可以进行在线预览了
说白了,我们现在的所有努力都是在将word文档转换成pdf文件,然后以response的输出流形式输出而已。
言归正传
pattern.setSrcFilePrefix(DefaultDocumentFormatRegistry.DOCX);
这一句是指定输入文件的类型,笔者进行过测试,无论是doc还是docx文件,这里使用DOCX都可以正常转换,没有出现任何问题。如果大家在测试时出现问题,请对文件类型进行判断,选择合适的文件类型。
如果转换成功,会返回bool类型的结果,此处result变量
根据转换结果,调用另一个方法outputPdf,本方法亦在当前类里面,这里插一句,因为只在本类中使用,因此此方法设置为private。outputPdf方法的作用是读取转换完成的pdf文件,以response.getOutputStream()的形式输出,返回给浏览器。
方法代码如下:
private static void outputPdf(String filePath, HttpServletResponse response) throws IOException {
response.setHeader("Access-Control-Allow-Origin", "*");
ServletOutputStream out = null;
FileInputStream in = null;
try {
in = new FileInputStream(new File(filePath));
String[] dir = filePath.split("/");
String fileName = dir[dir.length - 1];
// 设置响应类型为html,编码为utf-8,处理相应页面文本显示的乱码
response.setContentType("application/octet-stream");
// 设置文件头:最后一个参数是设置下载文件名
response.setHeader("Content-disposition", "attachment;filename=" + fileName);
out = response.getOutputStream();
// 读取文件流
int len = 0;
byte[] buffer = new byte[1024 * 10];
while ((len = in.read(buffer)) != -1) {
out.write(buffer, 0, len);
}
out.flush();
} catch (FileNotFoundException e) {
} finally {
response.flushBuffer();
try {
out.close();
in.close();
} catch (NullPointerException e) {
} catch (Exception e) {
}
}
}
完整的PdfService类如下:
package com.ieslab.pdfview.service.fileservice;
import com.liumapp.workable.converter.WorkableConverter;
import com.liumapp.workable.converter.core.ConvertPattern;
import com.liumapp.workable.converter.exceptions.ConvertFailedException;
import com.liumapp.workable.converter.factory.CommonConverterManager;
import com.liumapp.workable.converter.factory.ConvertPatternManager;
import org.jodconverter.document.DefaultDocumentFormatRegistry;
import javax.servlet.ServletOutputStream;
import javax.servlet.http.HttpServletResponse;
import java.io.*;
import java.util.UUID;
/**
* @version V1.0
* @Title:
* @Package com.ieslab.pdfview.service.fileservice
* @Description: TODO
* @author: zongmoumou
* @date 2020/10/13
*/
public class PdfService {
public static void wordToPdf(String address, HttpServletResponse response) throws IOException, ConvertFailedException {
String uuid = UUID.randomUUID().toString().replaceAll("-", "");
String tempFilePath = "temp-" + uuid + ".pdf";
WorkableConverter converter = new WorkableConverter();
ConvertPattern pattern = ConvertPatternManager.getInstance();
pattern.streamToStream(new FileInputStream(address), new FileOutputStream(tempFilePath));
pattern.setSrcFilePrefix(DefaultDocumentFormatRegistry.DOCX);
pattern.setDestFilePrefix(DefaultDocumentFormatRegistry.PDF);
converter.setConverterType(CommonConverterManager.getInstance());
boolean result = converter.convert(pattern.getParameter());
if (result) {
outputPdf(tempFilePath, response);
File file = new File(tempFilePath);
if (file != null) {
file.delete();
}
}
}
private static void outputPdf(String filePath, HttpServletResponse response) throws IOException {
response.setHeader("Access-Control-Allow-Origin", "*");
ServletOutputStream out = null;
FileInputStream in = null;
try {
in = new FileInputStream(new File(filePath));
String[] dir = filePath.split("/");
String fileName = dir[dir.length - 1];
// 设置响应类型为html,编码为utf-8,处理相应页面文本显示的乱码
response.setContentType("application/octet-stream");
// 设置文件头:最后一个参数是设置下载文件名
response.setHeader("Content-disposition", "attachment;filename=" + fileName);
out = response.getOutputStream();
// 读取文件流
int len = 0;
byte[] buffer = new byte[1024 * 10];
while ((len = in.read(buffer)) != -1) {
out.write(buffer, 0, len);
}
out.flush();
} catch (FileNotFoundException e) {
} finally {
response.flushBuffer();
try {
out.close();
in.close();
} catch (NullPointerException e) {
} catch (Exception e) {
}
}
}
}
相应的Controller类代码如下:
package com.ieslab.pdfview.controller;
import com.ieslab.pdfview.service.fileservice.PdfService;
import com.liumapp.workable.converter.exceptions.ConvertFailedException;
import org.springframework.stereotype.Controller;
import org.springframework.validation.annotation.Validated;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.ResponseBody;
import javax.servlet.http.HttpServletResponse;
import java.io.IOException;
/**
* @version V1.0
* @Title:
* @Package com.ieslab.pdfview.controller
* @Description: TODO
* @author: zongmoumou
* @date 2020/10/13
*/
@Controller
@RequestMapping("/viewfile")
public class ViewPdfController {
@RequestMapping(value = "/pdf", method = RequestMethod.GET)
@ResponseBody
@Validated
public void downloadFile(@RequestParam(value = "address") String address, HttpServletResponse response) throws IOException, ConvertFailedException {
PdfService.wordToPdf(address,response);
}
}
好了,让我们在浏览器里面测试一下,输入url:
http://localhost:8081/viewfile/pdf?address=C:/Users/zongshaofeng/Desktop/(自己找一个本机Word文档).doc
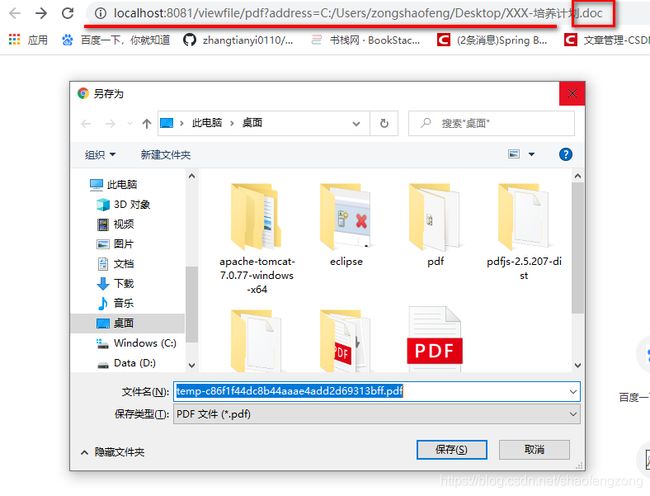
完美,以输出流的形式得到转换后的pdf文件。
而且,这里发现了没有,印证了我上文提到过的,无论是doc还是docx类型,在程序中选择DOCX,都可以进行正常转换。
六、使用PDF.js完成在线预览功能
之前说过,PDF.js是支持以pdf文件形式作为输入源,亦可以文件流的形式作为输入流,此时我们已经获取到了pdf的文件流形式,我们接下来的工作就是将文件流与PDF.js建立联系。
1. 官网下载PDF.js,解压,将文件夹重命名为pdfjs
解压之后的目录如下:
将pdfjs文件夹放到Tomcat服务器目录的webapps目录下。保证Tomcat处于启动状态。
至此,已经完成了一大半啦。让我们继续。
新建一个demo.html文件,目的为了调用PDF.js提供的viewer.html。(我们刚才已经将pdfjs部署到Tomcat中啦)
HTML内容为:
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Documenttitle>
head>
<body>
<script>
var url = "?file=" + encodeURIComponent(
"http://localhost:8081/viewfile/pdf?address=C:/Users/zongshaofeng/Desktop/123.docx") + "";
window.onload = function () {
window.location.href='http://localhost:8080/pdfjs/web/viewer.html' + url;
}
script>
body>
html>
说明,非常重要,最重要的坑:
url就是我们第五步中实现的word转换pdf,以输出流的形式输出,我们访问url就能获取到pdf文件的文件流。
通过window.location.href=xxx,将页面跳转到viewer.html,进行pdf在线预览。
pdf.js在线预览完整的url格式为:
http://localhost:8080/pdfjs/web/viewer.html?file=xxxx
坑点之一:切记、注意
file=后边的内容必须进行URLEncode编码,使用encodeURIComponent()方法,关于encodeURIComponent()与encodeURI()方法的区别,请自行百度。
如果不编码的话,请看错误:

坑点之二:切记、注意
即便这个样做了,肯定还会出现跨域问题呢,这个想到不要想,因为我们的后端项目与PDF.js根本不在同一域下,必定跨域,跨域的提示如图所示:

解决的方法也很简单粗暴,找到Tomcat目录–webapps目录–pdfjs目录–web目录下的viewer.js,找到如下的三行,注释掉就OK。
if (origin !== viewerOrigin && protocol !== "blob:") {
throw new Error("file origin does not match viewer's");
}
笔者目前的版本文件,这三行是在2182行,如果没找到也可以Ctrl+F搜索一下。
还有一点可能需要提醒一下,如果后端SpringBoot项目(获取pdf输出流)不修改端口号 ,肯定会与Tomcat(部署pdfjs)默认端口号8080冲突,SpringBoot项目启动不了哦,还是修改一下吧。
七、测试效果与总结
双击运行demo.html,运行测试效果。

到这里为止,实现word转pdf并在线预览的工作基本就结束啦。
预祝各位道友,都能马到成功。在过去现在未来,倘若工作或学习中需要实现此项功能,恰好本文中某一点或某几点拙见帮助到了你,笔者就很知足了。
也呼吁各位码友,不吝分享您宝贵的知识财富。
好啦,再会,我还会回来的!