百度飞桨架构师手把手带你零基础实践深度学习——【手写数字识别】之资源配置
百度飞桨架构师手把手带你零基础实践深度学习——打卡计划
- 总目录
- 【手写数字识别】之资源配置
-
- 单GPU训练
- 分布式训练
- 模型并行
- 数据并行
-
- PRC通信方式
- NCCL2通信方式(Collective)
下面给出课程链接,欢迎各位小伙来来报考!本帖将持续更新。我只是飞桨的搬运工

话不多说,这么良心的课程赶快扫码上车!https://aistudio.baidu.com/aistudio/education/group/info/1297?activityId=5&directly=1&shared=1
总目录
【手写数字识别】之资源配置
# 加载相关库
import os
import random
import paddle
import paddle.fluid as fluid
from paddle.fluid.dygraph.nn import Conv2D, Pool2D, Linear
import numpy as np
from PIL import Image
import gzip
import json
# 定义数据集读取器
def load_data(mode='train'):
# 读取数据文件
datafile = './work/mnist.json.gz'
print('loading mnist dataset from {} ......'.format(datafile))
data = json.load(gzip.open(datafile))
# 读取数据集中的训练集,验证集和测试集
train_set, val_set, eval_set = data
# 数据集相关参数,图片高度IMG_ROWS, 图片宽度IMG_COLS
IMG_ROWS = 28
IMG_COLS = 28
# 根据输入mode参数决定使用训练集,验证集还是测试
if mode == 'train':
imgs = train_set[0]
labels = train_set[1]
elif mode == 'valid':
imgs = val_set[0]
labels = val_set[1]
elif mode == 'eval':
imgs = eval_set[0]
labels = eval_set[1]
# 获得所有图像的数量
imgs_length = len(imgs)
# 验证图像数量和标签数量是否一致
assert len(imgs) == len(labels), \
"length of train_imgs({}) should be the same as train_labels({})".format(
len(imgs), len(labels))
index_list = list(range(imgs_length))
# 读入数据时用到的batchsize
BATCHSIZE = 100
# 定义数据生成器
def data_generator():
# 训练模式下,打乱训练数据
if mode == 'train':
random.shuffle(index_list)
imgs_list = []
labels_list = []
# 按照索引读取数据
for i in index_list:
# 读取图像和标签,转换其尺寸和类型
img = np.reshape(imgs[i], [1, IMG_ROWS, IMG_COLS]).astype('float32')
label = np.reshape(labels[i], [1]).astype('int64')
imgs_list.append(img)
labels_list.append(label)
# 如果当前数据缓存达到了batch size,就返回一个批次数据
if len(imgs_list) == BATCHSIZE:
yield np.array(imgs_list), np.array(labels_list)
# 清空数据缓存列表
imgs_list = []
labels_list = []
# 如果剩余数据的数目小于BATCHSIZE,
# 则剩余数据一起构成一个大小为len(imgs_list)的mini-batch
if len(imgs_list) > 0:
yield np.array(imgs_list), np.array(labels_list)
return data_generator
# 定义模型结构
class MNIST(fluid.dygraph.Layer):
def __init__(self):
super(MNIST, self).__init__()
# 定义一个卷积层,使用relu激活函数
self.conv1 = Conv2D(num_channels=1, num_filters=20, filter_size=5, stride=1, padding=2, act='relu')
# 定义一个池化层,池化核为2,步长为2,使用最大池化方式
self.pool1 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')
# 定义一个卷积层,使用relu激活函数
self.conv2 = Conv2D(num_channels=20, num_filters=20, filter_size=5, stride=1, padding=2, act='relu')
# 定义一个池化层,池化核为2,步长为2,使用最大池化方式
self.pool2 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')
# 定义一个全连接层,输出节点数为10
self.fc = Linear(input_dim=980, output_dim=10, act='softmax')
# 定义网络的前向计算过程
def forward(self, inputs):
x = self.conv1(inputs)
x = self.pool1(x)
x = self.conv2(x)
x = self.pool2(x)
x = fluid.layers.reshape(x, [x.shape[0], 980])
x = self.fc(x)
return x
单GPU训练
飞桨动态图通过fluid.dygraph.guard(place=None)里的place参数,设置在GPU上训练还是CPU上训练。
with fluid.dygraph.guard(place=fluid.CPUPlace()) #设置使用CPU资源训神经网络。
with fluid.dygraph.guard(place=fluid.CUDAPlace(0)) #设置使用GPU资源训神经网络,默认使用服务器的第一个GPU卡。"0"是GPU卡的编号,比如一台服务器有的四个GPU卡,编号分别为0、1、2、3。
#仅前3行代码有所变化,在使用GPU时,可以将use_gpu变量设置成True
use_gpu = False
place = fluid.CUDAPlace(0) if use_gpu else fluid.CPUPlace()
with fluid.dygraph.guard(place):
model = MNIST()
model.train()
#调用加载数据的函数
train_loader = load_data('train')
#四种优化算法的设置方案,可以逐一尝试效果
optimizer = fluid.optimizer.SGDOptimizer(learning_rate=0.01, parameter_list=model.parameters())
#optimizer = fluid.optimizer.MomentumOptimizer(learning_rate=0.01, momentum=0.9, parameter_list=model.parameters())
#optimizer = fluid.optimizer.AdagradOptimizer(learning_rate=0.01, parameter_list=model.parameters())
#optimizer = fluid.optimizer.AdamOptimizer(learning_rate=0.01, parameter_list=model.parameters())
EPOCH_NUM = 2
for epoch_id in range(EPOCH_NUM):
for batch_id, data in enumerate(train_loader()):
#准备数据,变得更加简洁
image_data, label_data = data
image = fluid.dygraph.to_variable(image_data)
label = fluid.dygraph.to_variable(label_data)
#前向计算的过程
predict = model(image)
#计算损失,取一个批次样本损失的平均值
loss = fluid.layers.cross_entropy(predict, label)
avg_loss = fluid.layers.mean(loss)
#每训练了200批次的数据,打印下当前Loss的情况
if batch_id % 200 == 0:
print("epoch: {}, batch: {}, loss is: {}".format(epoch_id, batch_id, avg_loss.numpy()))
#后向传播,更新参数的过程
avg_loss.backward()
optimizer.minimize(avg_loss)
model.clear_gradients()
#保存模型参数
fluid.save_dygraph(model.state_dict(), 'mnist')
分布式训练
在工业实践中,很多较复杂的任务需要使用更强大的模型。强大模型加上海量的训练数据,经常导致模型训练耗时严重。比如在计算机视觉分类任务中,训练一个在ImageNet数据集上精度表现良好的模型,大概需要一周的时间,因为过程中我们需要不断尝试各种优化的思路和方案。如果每次训练均要耗时1周,这会大大降低模型迭代的速度。在机器资源充沛的情况下,建议采用分布式训练,大部分模型的训练时间可压缩到小时级别。
分布式训练有两种实现模式:模型并行和数据并行。
模型并行
模型并行是将一个网络模型拆分为多份,拆分后的模型分到多个设备上(GPU)训练,每个设备的训练数据是相同的。模型并行的实现模式可以节省内存,但是应用较为受限。
模型并行的方式一般适用于如下两个场景:
-
模型架构过大: 完整的模型无法放入单个GPU。如2012年ImageNet大赛的冠军模型AlexNet是模型并行的典型案例,由于当时GPU内存较小,单个GPU不足以承担AlexNet,因此研究者将AlexNet拆分为两部分放到两个GPU上并行训练。
-
网络模型的结构设计相对独立: 当网络模型的设计结构可以并行化时,采用模型并行的方式。如在计算机视觉目标检测任务中,一些模型(如YOLO9000)的边界框回归和类别预测是独立的,可以将独立的部分放到不同的设备节点上完成分布式训练。
数据并行
数据并行与模型并行不同,数据并行每次读取多份数据,读取到的数据输入给多个设备(GPU)上的模型,每个设备上的模型是完全相同的,飞桨采用的就是这种方式。
说明:
当前GPU硬件技术快速发展,深度学习使用的主流GPU的内存已经足以满足大多数的网络模型需求,所以大多数情况下使用数据并行的方式。
数据并行的方式与众人拾柴火焰高的道理类似,如果把训练数据比喻为砖头,把一个设备(GPU)比喻为一个人,那单GPU训练就是一个人在搬砖,多GPU训练就是多个人同时搬砖,每次搬砖的数量倍数增加,效率呈倍数提升。值得注意的是,每个设备的模型是完全相同的,但是输入数据不同,因此每个设备的模型计算出的梯度是不同的。如果每个设备的梯度只更新当前设备的模型,就会导致下次训练时,每个模型的参数都不相同。因此我们还需要一个梯度同步机制,保证每个设备的梯度是完全相同的。
梯度同步有两种方式:PRC通信方式和NCCL2通信方式(Nvidia Collective multi-GPU Communication Library)。
PRC通信方式
PRC通信方式通常用于CPU分布式训练,它有两个节点:参数服务器Parameter server和训练节点Trainer,结构如 图2 所示。
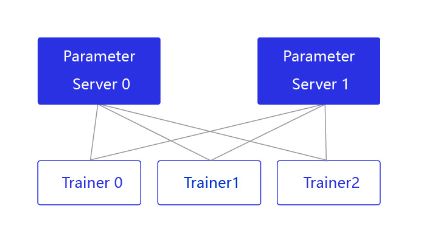
图2:Pserver通信方式的结构
parameter server收集来自每个设备的梯度更新信息,并计算出一个全局的梯度更新。Trainer用于训练,每个Trainer上的程序相同,但数据不同。当Parameter server收到来自Trainer的梯度更新请求时,统一更新模型的梯度。
NCCL2通信方式(Collective)
当前飞桨的GPU分布式训练使用的是基于NCCL2的通信方式,结构如 图3 所示。
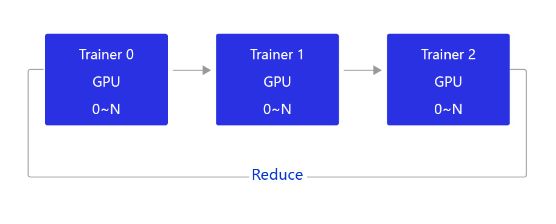
图3:NCCL2通信方式的结构
相比PRC通信方式,使用NCCL2(Collective通信方式)进行分布式训练,不需要启动Parameter server进程,每个Trainer进程保存一份完整的模型参数,在完成梯度计算之后通过Trainer之间的相互通信,Reduce梯度数据到所有节点的所有设备,然后每个节点再各自完成参数更新。
飞桨提供了便利的数据并行训练方式,用户只需要对程序进行简单修改,即可实现在多GPU上并行训练。接下来讲述如何将一个单机程序通过简单的改造,变成多机多卡程序。
说明:
AI Studio当前仅支持单卡GPU,因此本案例需要在本地GPU上执行,无法在AI Studio上演示。
在启动训练前,需要配置如下参数:
- 从环境变量获取设备的ID,并指定给CUDAPlace。
device_id = fluid.dygraph.parallel.Env().dev_id
place = fluid.CUDAPlace(device_id)
- 对定义的网络做预处理,设置为并行模式。
strategy = fluid.dygraph.parallel.prepare_context() ## 新增
model = MNIST()
model = fluid.dygraph.parallel.DataParallel(model, strategy) ## 新增
- 定义多GPU训练的reader,不同ID的GPU加载不同的数据集。
valid_loader = paddle.batch(paddle.dataset.mnist.test(), batch_size=16, drop_last=true)
valid_loader = fluid.contrib.reader.distributed_batch_reader(valid_loader)
- 收集每批次训练数据的loss,并聚合参数的梯度。
avg_loss = model.scale_loss(avg_loss) ## 新增
avg_loss.backward()
mnist.apply_collective_grads() ## 新增
完整程序如下所示。
def train_multi_gpu():
##修改1-从环境变量获取使用GPU的序号
place = fluid.CUDAPlace(fluid.dygraph.parallel.Env().dev_id)
with fluid.dygraph.guard(place):
##修改2-对原模型做并行化预处理
strategy = fluid.dygraph.parallel.prepare_context()
model = MNIST()
model = fluid.dygraph.parallel.DataParallel(model, strategy)
model.train()
#调用加载数据的函数
train_loader = load_data('train')
##修改3-多GPU数据读取,必须确保每个进程读取的数据是不同的
train_loader = fluid.contrib.reader.distributed_batch_reader(train_loader)
optimizer = fluid.optimizer.SGDOptimizer(learning_rate=0.01, parameter_list=model.parameters())
EPOCH_NUM = 5
for epoch_id in range(EPOCH_NUM):
for batch_id, data in enumerate(train_loader()):
#准备数据
image_data, label_data = data
image = fluid.dygraph.to_variable(image_data)
label = fluid.dygraph.to_variable(label_data)
predict = model(image)
loss = fluid.layers.cross_entropy(predict, label)
avg_loss = fluid.layers.mean(loss)
# 修改4-多GPU训练需要对Loss做出调整,并聚合不同设备上的参数梯度
avg_loss = model.scale_loss(avg_loss)
avg_loss.backward()
model.apply_collective_grads()
# 最小化损失函数,清除本次训练的梯度
optimizer.minimize(avg_loss)
model.clear_gradients()
if batch_id % 200 == 0:
print("epoch: {}, batch: {}, loss is: {}".format(epoch_id, batch_id, avg_loss.numpy()))
#保存模型参数
fluid.save_dygraph(model.state_dict(), 'mnist')