
Flink为了能够处理有边界的数据集和无边界的数据集,提供了对应的DataSet API和DataStream API。我们可以开发对应的Java程序或者Scala程序来完成相应的功能。下面举例了一些DataSet API中的基本的算子。
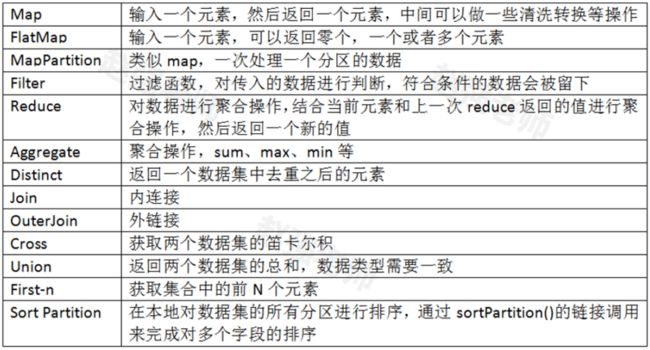
下面我们通过具体的代码来为大家演示每个算子的作用。
1、Map、FlatMap与MapPartition
//获取运行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
ArrayList data = new ArrayList();
data.add("I love Beijing");
data.add("I love China");
data.add("Beijing is the capital of China");
DataSource text = env.fromCollection(data);
DataSet> mapData = text.map(new MapFunction>() {
public List map(String data) throws Exception {
String[] words = data.split(" ");
//创建一个List
List result = new ArrayList();
for(String w:words){
result.add(w);
}
return result;
}
});
mapData.print();
System.out.println("*****************************************");
DataSet flatMapData = text.flatMap(new FlatMapFunction() {
public void flatMap(String data, Collector collection) throws Exception {
String[] words = data.split(" ");
for(String w:words){
collection.collect(w);
}
}
});
flatMapData.print();
System.out.println("*****************************************");
/* new MapPartitionFunction
第一个String:表示分区中的数据元素类型
第二个String:表示处理后的数据元素类型*/
DataSet mapPartitionData = text.mapPartition(new MapPartitionFunction() {
public void mapPartition(Iterable values, Collector out) throws Exception {
//针对分区进行操作的好处是:比如要进行数据库的操作,一个分区只需要创建一个Connection
//values中保存了一个分区的数据
Iterator it = values.iterator();
while (it.hasNext()) {
String next = it.next();
String[] split = next.split(" ");
for (String word : split) {
out.collect(word);
}
}
//关闭链接
}
});
mapPartitionData.print();
2、Filter与Distinct
//获取运行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
ArrayList data = new ArrayList();
data.add("I love Beijing");
data.add("I love China");
data.add("Beijing is the capital of China");
DataSource text = env.fromCollection(data);
DataSet flatMapData = text.flatMap(new FlatMapFunction() {
public void flatMap(String data, Collector collection) throws Exception {
String[] words = data.split(" ");
for(String w:words){
collection.collect(w);
}
}
});
//去掉重复的单词
flatMapData.distinct().print();
System.out.println("*********************");
//选出长度大于3的单词
flatMapData.filter(new FilterFunction() {
public boolean filter(String word) throws Exception {
int length = word.length();
return length>3?true:false;
}
}).print();
3、Join操作
//获取运行的环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//创建第一张表:用户ID 姓名
ArrayList> data1 = new ArrayList>();
data1.add(new Tuple2(1,"Tom"));
data1.add(new Tuple2(2,"Mike"));
data1.add(new Tuple2(3,"Mary"));
data1.add(new Tuple2(4,"Jone"));
//创建第二张表:用户ID 所在的城市
ArrayList> data2 = new ArrayList>();
data2.add(new Tuple2(1,"北京"));
data2.add(new Tuple2(2,"上海"));
data2.add(new Tuple2(3,"广州"));
data2.add(new Tuple2(4,"重庆"));
//实现join的多表查询:用户ID 姓名 所在的程序
DataSet> table1 = env.fromCollection(data1);
DataSet> table2 = env.fromCollection(data2);
table1.join(table2).where(0).equalTo(0)
/*第一个Tuple2:表示第一张表
* 第二个Tuple2:表示第二张表
* Tuple3:多表join连接查询后的返回结果 */
.with(new JoinFunction, Tuple2, Tuple3>() {
public Tuple3 join(Tuple2 table1,
Tuple2 table2) throws Exception {
return new Tuple3(table1.f0,table1.f1,table2.f1);
} }).print();
4、笛卡尔积
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//创建第一张表:用户ID 姓名
ArrayList> data1 = new ArrayList>();
data1.add(new Tuple2(1,"Tom"));
data1.add(new Tuple2(2,"Mike"));
data1.add(new Tuple2(3,"Mary"));
data1.add(new Tuple2(4,"Jone"));
//创建第二张表:用户ID 所在的城市
ArrayList> data2 = new ArrayList>();
data2.add(new Tuple2(1,"北京"));
data2.add(new Tuple2(2,"上海"));
data2.add(new Tuple2(3,"广州"));
data2.add(new Tuple2(4,"重庆"));
//实现join的多表查询:用户ID 姓名 所在的程序
DataSet> table1 = env.fromCollection(data1);
DataSet> table2 = env.fromCollection(data2);
//生成笛卡尔积
table1.cross(table2).print(); 5、First-N
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//这里的数据是:员工姓名、薪水、部门号
DataSet> grade =
env.fromElements(new Tuple3("Tom",1000,10),
new Tuple3("Mary",1500,20),
new Tuple3("Mike",1200,30),
new Tuple3("Jerry",2000,10));
//按照插入顺序取前三条记录
grade.first(3).print();
System.out.println("**********************");
//先按照部门号排序,在按照薪水排序
grade.sortPartition(2, Order.ASCENDING).sortPartition(1, Order.ASCENDING).print();
System.out.println("**********************");
//按照部门号分组,求每组的第一条记录
grade.groupBy(2).first(1).print(); 6、外链接操作
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//创建第一张表:用户ID 姓名
ArrayList> data1 = new ArrayList>();
data1.add(new Tuple2(1,"Tom"));
data1.add(new Tuple2(3,"Mary"));
data1.add(new Tuple2(4,"Jone"));
//创建第二张表:用户ID 所在的城市
ArrayList> data2 = new ArrayList>();
data2.add(new Tuple2(1,"北京"));
data2.add(new Tuple2(2,"上海"));
data2.add(new Tuple2(4,"重庆"));
//实现join的多表查询:用户ID 姓名 所在的程序
DataSet> table1 = env.fromCollection(data1);
DataSet> table2 = env.fromCollection(data2);
//左外连接
table1.leftOuterJoin(table2).where(0).equalTo(0)
.with(new JoinFunction, Tuple2, Tuple3>() {
public Tuple3 join(Tuple2 table1,
Tuple2 table2) throws Exception {
// 左外连接表示等号左边的信息会被包含
if(table2 == null){
return new Tuple3(table1.f0,table1.f1,null);
}else{
return new Tuple3(table1.f0,table1.f1,table2.f1);
}
}
}).print();
System.out.println("***********************************");
//右外连接
table1.rightOuterJoin(table2).where(0).equalTo(0)
.with(new JoinFunction, Tuple2, Tuple3>() {
public Tuple3 join(Tuple2 table1,
Tuple2 table2) throws Exception {
//右外链接表示等号右边的表的信息会被包含
if(table1 == null){
return new Tuple3(table2.f0,null,table2.f1);
}else{
return new Tuple3(table2.f0,table1.f1,table2.f1);
}
}
}).print();
System.out.println("***********************************");
//全外连接
table1.fullOuterJoin(table2).where(0).equalTo(0)
.with(new JoinFunction, Tuple2, Tuple3>() {
public Tuple3 join(Tuple2 table1, Tuple2 table2)
throws Exception {
if(table1 == null){
return new Tuple3(table2.f0,null,table2.f1);
}else if(table2 == null){
return new Tuple3(table1.f0,table1.f1,null);
}else{
return new Tuple3(table1.f0,table1.f1,table2.f1);
}
}
}).print();