2021先定个小目标?搞清楚MyCat分片的两种拆分方法和分片规则!(四):分片规则的十四种算法详细解读&代码实现(下)!
目录
- 一、应用指定算法
- 二、字符串hash解析算法
- 三、一致性hash算法
- 四、日期分片算法
- 五、单月小时算法
- 六、自然月分片算法
- 七、日期范围hash算法
一、应用指定算法
由运行阶段由应用自主决定路由到那个分片 , 直接根据字符子串(必须是数字)计算分片号 , 配置如下 :
<tableRule name="sharding-by-substring">
<rule>
<columns>id</columns>
<algorithm>sharding-by-substring</algorithm>
</rule>
</tableRule>
<function name="sharding-by-substring" class="io.mycat.route.function.PartitionDirectBySubString">
<property name="startIndex">0</property> <!-- zero-based -->
<property name="size">2</property>
<property name="partitionCount">3</property>
<property name="defaultPartition">0</property>
</function>
配置说明:
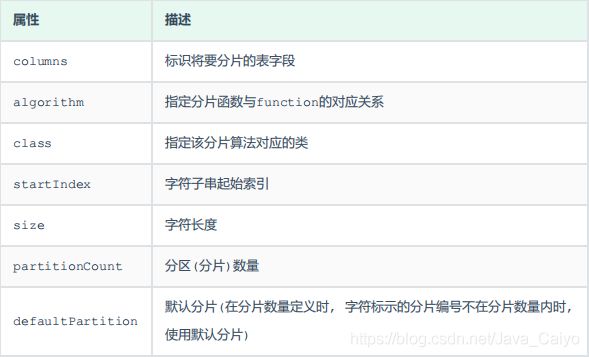
示例说明 :
id=05-100000002 , 在此配置中代表根据id中从 startIndex=0,开始,截取siz=2位数字即05,05就是获取的分区,如果没传默认分配到defaultPartition 。
测试:
配置
<table name="tb_app" dataNode="dn1,dn2,dn3" rule="sharding-by-substring"/>
数据
1). 创建表
CREATE TABLE `tb_app` (
id varchar(10) NOT NULL COMMENT 'ID',
name varchar(200) DEFAULT NULL COMMENT '名称',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
2). 插入数据
insert into tb_app (id,name) values('00-00001','Testx00001');
insert into tb_app (id,name) values('01-00001','Test100001');
insert into tb_app (id,name) values('01-00002','Test200001');
insert into tb_app (id,name) values('02-00001','Test300001');
insert into tb_app (id,name) values('02-00002','TesT400001');
二、字符串hash解析算法
截取字符串中的指定位置的子字符串, 进行hash算法, 算出分片 , 配置如下:
<tableRule name="sharding-by-stringhash">
<rule>
<columns>user_id</columns>
<algorithm>sharding-by-stringhash</algorithm>
</rule>
</tableRule>
<function name="sharding-by-stringhash" class="io.mycat.route.function.PartitionByString">
<property name="partitionLength">512</property> <!-- zero-based -->
<property name="partitionCount">2</property>
<property name="hashSlice">0:2</property>
</function>
配置说明:
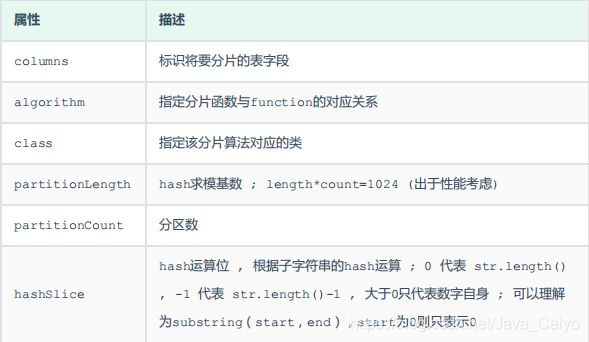
测试:
配置
<table name="tb_strhash" dataNode="dn1,dn2,dn3" rule="sharding-by-stringhash"/>
数据
1). 创建表
create table tb_strhash(
name varchar(20) primary key,
content varchar(100)
)engine=InnoDB DEFAULT CHARSET=utf8mb4;
2). 插入数据
INSERT INTO tb_strhash (name,content) VALUES('T1001', UUID());
INSERT INTO tb_strhash (name,content) VALUES('ROSE', UUID());
INSERT INTO tb_strhash (name,content) VALUES('JERRY', UUID());
INSERT INTO tb_strhash (name,content) VALUES('CRISTINA', UUID());
INSERT INTO tb_strhash (name,content) VALUES('TOMCAT', UUID());
原理:
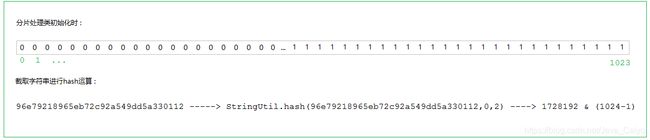
参考资料:
《开源数据库中间件MyCat实战笔记》
想要快速获取资料的同学:请添加助理VX:C18173184271,备注一下CSDN+工作年限!免费获取
以便能够充分理解学习!
三、一致性hash算法
一致性Hash算法有效的解决了分布式数据的拓容问题 , 配置如下:
<tableRule name="sharding-by-murmur">
<rule>
<columns>id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
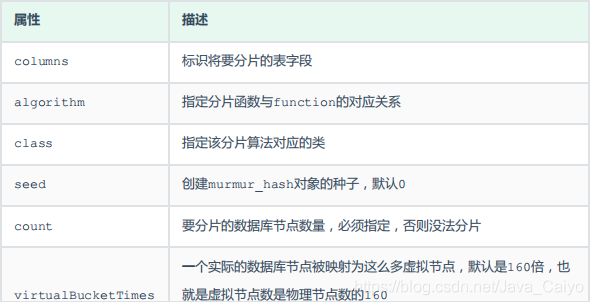
<function name="murmur" class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property>
<property name="count">3</property><!-- -->
<property name="virtualBucketTimes">160</property>
<!-- <property name="weightMapFile">weightMapFile</property> -->
<!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property> -->
</function>
配置说明:

测试:
配置
<table name="tb_order" dataNode="dn1,dn2,dn3" rule="sharding-by-murmur"/>
数据
1). 创建表
create table tb_order(
id int(11) primary key,
money int(11),
content varchar(200)
)engine=InnoDB ;
2). 插入数据
INSERT INTO tb_order (id,money,content) VALUES(1, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(212, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(312, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(412, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(534, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(621, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(754563, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(8123, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(91213, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(23232, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(112321, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(21221, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(112132, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(12132, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(124321, 100 , UUID());
INSERT INTO tb_order (id,money,content) VALUES(212132, 100 , UUID());
四、日期分片算法
按照日期来分片
<tableRule name="sharding-by-date">
<rule>
<columns>create_time</columns>
<algorithm>sharding-by-date</algorithm>
</rule>
</tableRule>
<function name="sharding-by-date" class="io.mycat.route.function.PartitionByDate">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2020-01-01</property>
<property name="sEndDate">2020-12-31</property>
<property name="sPartionDay">10</property>
</function>
配置说明:
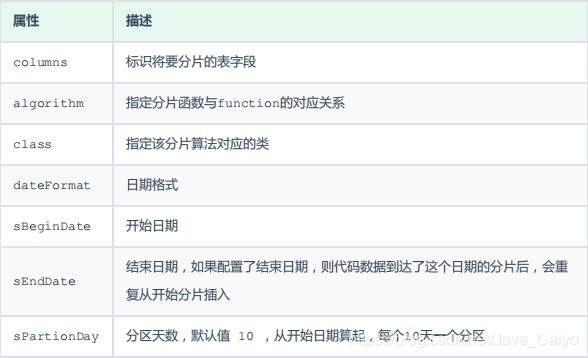
注意:配置规则的表的 dataNode 的分片,必须和分片规则数量一致,例如 2020-01-01 到 2020-12-31 ,每10天一个分片,一共需要37个分片。
五、单月小时算法
单月内按照小时拆分, 最小粒度是小时 , 一天最多可以有24个分片, 最小1个分片, 下个月从头开始循环, 每个月末需要手动清理数据。
配置如下 :
<tableRule name="sharding-by-hour">
<rule>
<columns>create_time</columns>
<algorithm>sharding-by-hour</algorithm>
</rule>
</tableRule>
<function name="sharding-by-hour" class="io.mycat.route.function.LatestMonthPartion">
<property name="splitOneDay">24</property>
</function>
配置说明:

六、自然月分片算法
使用场景为按照月份列分区, 每个自然月为一个分片, 配置如下:
<tableRule name="sharding-by-month">
<rule>
<columns>create_time</columns>
<algorithm>sharding-by-month</algorithm>
</rule>
</tableRule>
<function name="sharding-by-month" class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2020-01-01</property>
<property name="sEndDate">2020-12-31</property>
</function>
配置说明:

七、日期范围hash算法
其思想和范围取模分片一样,先根据日期进行范围分片求出分片组,再根据时间hash使得短期内数据分布的更均匀 ;
优点 : 可以避免扩容时的数据迁移,又可以一定程度上避免范围分片的热点问题
注意 : 要求日期格式尽量精确些,不然达不到局部均匀的目的
<tableRule name="range-date-hash">
<rule>
<columns>create_time</columns>
<algorithm>range-date-hash</algorithm>
</rule>
</tableRule>
<function name="range-date-hash" class="io.mycat.route.function.PartitionByRangeDateHash">
<property name="dateFormat">yyyy-MM-dd HH:mm:ss</property>
<property name="sBeginDate">2020-01-01 00:00:00</property>
<property name="groupPartionSize">6</property>
<property name="sPartionDay">10</property>
</function>
配置说明:

如果你需要这份完整版的
《开源数据库中间件MyCat实战笔记》,只需你多多支持我这篇文章。
多多支持,即可免费获取资料——三连之后(承诺:100%免费)
快速入手通道:添加助理VX:
C18173184271,备注一下CSDN+工作年限!免费获取!诚意满满!!!