多节点openstack中部署CEPH文件系统
目录
一.CEPH简介
CEPH概述
Ceph的特点
Ceph核心组件以及概念介绍
Ceph架构
Ceph的三种存储类型
二.实验环境介绍
三.部署CEPH
部署CEPH群集(mon、osd、mgr)
安装CEPH群集web管理界面,在控制节点设置
CEPH与OpenStack的对接环境的部署
CEPH对接Glance
CEPH对接cinder
CEPH对接Nova,分别在compute01和compute02节点操作
测试OpenStack+CEPH群集
一.CEPH简介
CEPH概述
- ceph是一个统一的分布式存储系统,设计初衷是提供较好的性能、可靠性和扩展性
- ceph项目最早其源于Sage就读博士期间的工作(最早的成果于2004年发表),并随后贡献给开源社区。在经过了数年的发展之后,目前已得到众多云计算厂商的支持并被广泛应用。RedHat及OpenStack都可与Ceph整合以支持虚拟机镜像的后端存储。
Ceph的特点
- 高性能
摒弃了传统的集中式存储元数据寻址的方式,采用CRUSH算法,数据分布均衡,并行度高
考虑了容灾域的隔离,能够实现各类负载的副本防止规则,例如跨机房、机架感知等
能够支持上千个存储节点的规模,支持TB到PB的数据
- 高可用性
副本数可以灵活控制
支持故障域分离,数据强一致性
多种故障场景自动进行修复自愈
没有单点故障,自动管理
- 高扩展性
去中心化
扩展灵活
随着节点增加而线性增长
- 特性丰富
支持三种存储接口:块存储、文件存储、对象存储
支持自定义接口,支持多种语言驱动
Ceph核心组件以及概念介绍
- Monitor(监控):一个Ceph集群需要多个Monitor组成的小集群,它们通过Paxos同步数据,用来保存OSD的元数据
- MGR:由于Monitor负载过大,采用MGR来辅助Monitor管理
- OSD(存储):负责响应客户端请求返回具体数据的京城,一个ceph集群有很多OSD
- MDS(元数据):CephFS服务依赖的元数据服务
- Object:Ceph最底层的存储单元是Object对象,每个Object包含元数据和原始数据
- PG(Placement Groups),PG是一个逻辑的概念,一个PG包含多个OSD。引入PG这一层是为了更好的分配数据和定位数据
- RADOS(Reliable Autonomic Distributed Object Store):帮助用户实现数据的分配、Failover等群集操作
- Libradio:
Librados是Rados提供库,因为RADOS是协议很难直接访问,因此上层的RBD、RGW和CephFS都是通过librados访问的,目前提供PHP、Ruby、Java、Python、C和C++支持
- CRUSH:CRUSH是Ceph使用的数据分布算法,类似哈希算法,让数据分配到预期的地方
- RBD(RADOS Block Device):是Ceph对外提供的块设备服务
- RGW(RADOS gateway):是ceph对外提供的对象存储服务,接口与S3和Swift兼容
- CephFS(Ceph file system),是ceph对外提供的文件系统服务
Ceph架构

- 支持三种接口(对象、块、文件)
object:有原生的API,也有兼容的swift和S3的API
block:支持精简配置、快照、克隆
file:posix接口、支持快照
Ceph的三种存储类型
文件存储
- 典型的设备:FTP、NFS服务器。为了克服块存储文件无法共享的问题,就有了文件存储,在服务器上架设FTP和NFS服务,就是文件存储
- 优点:造价低,方便文件共享
- 缺点:读写速率低,传输速率慢
- 使用场景:日志存储,有目录结构的文件存储
块存储
- 典型设备:磁盘阵列、硬盘,主要是将裸磁盘空间映射给主机使用
- 优点:通过raid与LVM等,对数据提供了保护;多块廉价的硬盘组合起来,提供容量;多块磁盘组合出来的逻辑盘,提高读写效率
- 缺点:采用SAN架构组网时,光纤交换机,造价成本高;主机之间无法共享数据
- 使用场景:docker容器、虚拟机磁盘存储分配、日志存储、文件存储
对象存储
- 典型设备:内置大容量硬盘的分布式服务器(swift、S3),多台服务器内置大容量硬盘,安装上对象存储管理软件,对外提供读写访问功能
- 优点:具备块存储的读写性能;具备文件存储的共享特性
- 使用场景:比较适合更新变动较少的数据,如图片存储、视频存储
二.实验环境介绍
openstack+ceph
| 角色 | 系统 | 内存 | 硬盘 | 源包 |
| control(ceph master,client) | centos7.7 | 6G | 150G系统盘+1T数据盘 | openstack_rocky.tar.gz |
| compute01(ceph standly) | centos7.7 | 6G | 150G系统盘+1T数据盘 | |
| compute02(ceph standly) | centos7.7. | 6G | 150G系统盘+1T数据盘 |
openstack+ceph的源包
链接:https://pan.baidu.com/s/1SBT9_QsdxHq7y3cbU4ykYw
提取码:3qqv注:由于笔者物理机资源不足,把ceph文件系统部署在openstack各个节点上
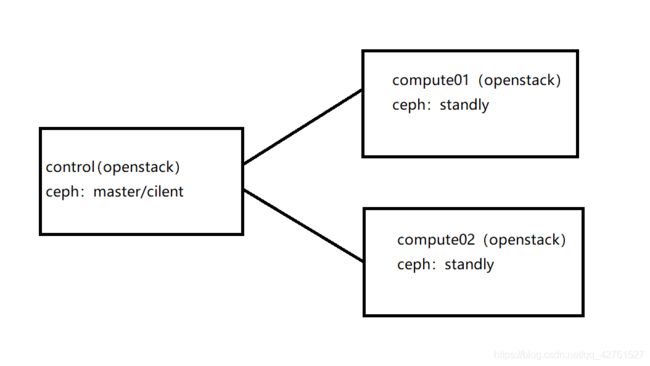
- 在此实验环境下,ceph的文件系统中为了节省资源把master和client都装在control节点上
- 至于安装多节点openstack,在上篇中已经有了详细步骤,https://blog.csdn.net/qq_42761527/article/details/104535078
●●●部署CEPH之前,必须把和存储有关系数据清理干净●●●
1、OpenStack安装了实例,必须删除----在控制台dashboard删除
2、OPenStack上产的镜像,必须删除----在控制台dashboard删除
3、OpenStack的cinder块,必须删除----在控制台dashboard删除
三.部署CEPH
部署CEPH群集(mon、osd、mgr)
- 三个节点分别安装python-setuptools(可能已经安装了)
yum -y install python-setuptools- 在控制节点安装ceph
##在控制节点,创建ceph配置文件目录
mkdir -p /etc/ceph
##在控制节点安装ceph-deploy
yum -y install ceph-deploy-
在三个节点都安装ceph软件
yum -y install ceph-
在控制节点,创建三个mon
##进入控制节点/etc/ceph的目录
cd /etc/ceph
ceph-deploy new control compute01 compute02
[root@control ceph(keystone_admin)]# ls
ceph.conf ceph-deploy-ceph.log ceph.mon.keyring rbdmap
[root@control ceph(keystone_admin)]# cat ceph.conf
[global]
fsid = cc79b9bf-7d16-4ebf-a9f6-5e66687718f7
mon_initial_members = control, compute1, compute2
mon_host = 192.168.100.10,192.168.100.11,192.168.100.12
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx-
在控制节点初始化mon,并且收集密钥
进入控制节点/etc/ceph的目录
cd /etc/ceph
[root@control ceph]# ceph-deploy mon create-initial
[root@control ceph(keystone_admin)]# ls
ceph.bootstrap-mds.keyring ceph.bootstrap-rgw.keyring ceph-deploy-ceph.log
ceph.bootstrap-mgr.keyring ceph.client.admin.keyring ceph.mon.keyring
ceph.bootstrap-osd.keyring ceph.conf rbdmap
[root@control ceph(keystone_admin)]# -
在控制节点创建OSD
##进入控制节点/etc/ceph的目录
cd /etc/ceph
##直接使用数据盘,数据盘不用挂载格式化
ceph-deploy osd create --data /dev/sdb control
ceph-deploy osd create --data /dev/sdb compute01
ceph-deploy osd create --data /dev/sdb compute02-
在控制节点中,使用ceph-deploy下发配置文件和admin密钥下发到control compute01 compute02
cd /etc/ceph
ceph-deploy admin control compute01 compute02-
在三个节点的keyring增加执行权限
chmod +x /etc/ceph/ceph.client.admin.keyring- 在控制节点创建mgr管理服务
##进入控制节点/etc/ceph的目录
cd /etc/ceph
ceph-deploy mgr create control compute01 compute02- 查看ceph的状态
[root@control ~(keystone_admin)]# ceph -s
cluster:
id: f1ad7652-ba45-46f1-881d-88ef9f080453
health: HEALTH_OK
services:
mon: 3 daemons, quorum control,compute01,compute02
mgr: control(active), standbys: compute02, compute01
osd: 3 osds: 3 up, 3 in
data:
pools: 3 pools, 192 pgs
objects: 406 objects, 1.8 GiB
usage: 8.3 GiB used, 3.0 TiB / 3.0 TiB avail ##这是笔者创建实例之后的状态
pgs: 192 active+clean
io:
client: 1.5 KiB/s rd, 1 op/s rd, 0 op/s wr
[root@control ~(keystone_admin)]#
-
在控制节点上创建三个与openstack对接的pool(volumes、vms、images)
ceph osd pool create volumes 64
ceph osd pool create vms 64
ceph osd pool create images 64- 查看mon、osd的状态,查看创建的pool池
[root@control ~(keystone_admin)]# ceph mon stat
e1: 3 mons at {compute01=192.168.100.11:6789/0,compute02=192.168.100.12:6789/0,control=192.168.100.10:6789/0}, election epoch 14, leader 0 control, quorum 0,1,2 control,compute01,compute02
[root@control ~(keystone_admin)]# ceph osd status
+----+-----------+-------+-------+--------+---------+--------+---------+-----------+
| id | host | used | avail | wr ops | wr data | rd ops | rd data | state |
+----+-----------+-------+-------+--------+---------+--------+---------+-----------+
| 0 | control | 2837M | 1021G | 0 | 0 | 0 | 0 | exists,up |
| 1 | compute02 | 2837M | 1021G | 0 | 0 | 0 | 0 | exists,up |
| 2 | compute01 | 2837M | 1021G | 0 | 0 | 0 | 0 | exists,up |
+----+-----------+-------+-------+--------+---------+--------+---------+-----------+
[root@control ~(keystone_admin)]# ceph osd lspools
1 volumes
2 vms
3 images
[root@control ~(keystone_admin)]#
安装CEPH群集web管理界面,在控制节点设置
- 启动dashboard模块
ceph mgr module enable dashboard- 创建https的证书
ceph dashboard create-self-signed-cert- 查看mgr服务
[root@control ~(keystone_admin)]# ceph mgr services
{
"dashboard": "https://control:8443/"
}
[root@control ~(keystone_admin)]#
- 设置ceph的web界面的账号密码
ceph dashboard set-login-credentials admin 123- 登录ceph网页https://192.168.100.10:8443/


CEPH与OpenStack的对接环境的部署
- 控制节点创建client.cinder并设置权限
ceph auth get-or-create client.cinder mon 'allow r' osd 'allow class-read object_prefix rbd_children,allow rwx pool=volumes,allow rwx pool=vms,allow rx pool=images'
- 控制节点创建client.glance并设置权限
ceph auth get-or-create client.glance mon 'allow r' osd 'allow class-read object_prefix rbd_children,allow rwx pool=images'
- 在控制节点上,传送秘钥到对接的节点,因为glance自身就装在控制节点所以不需要发送到其他的节点
ceph auth get-or-create client.glance |tee /etc/ceph/ceph.client.glance.keyring
##修改文件属性
chown glance.glance /etc/ceph/ceph.client.glance.keyring - 将client.cinder节点 因为这个默认也是安装在controller上 ,所以不需要传递到其他节点,如果在其他节点就执行第一条语句
ceph auth get-or-create client.cinder | tee /etc/ceph/ceph.client.cinder.keyring
chown cinder.cinder /etc/ceph/ceph.client.cinder.keyring- 在控制节点上,将client.cinder 传递到计算节点
ceph auth get-key client.cinder |ssh compute01 tee client.cinder.key
ceph auth get-key client.cinder |ssh compute02 tee client.cinder.key - 在compute01上生成UUID
[root@compute01 ~]# uuidgen
ae210c04-3d2e-41ca-ac8c-2d5840eb846c- 在compute01创建一个密钥文件
cd /root
cat >secret.xml <
ae210c04-3d2e-41ca-ac8c-2d5840eb846c
client.cinder secret
EOF
##定义秘钥,并将其保存
virsh secret-define --file secret.xml
##设置秘钥并删除临时文件
virsh secret-set-value --secret ae210c04-3d2e-41ca-ac8c-2d5840eb846c --base64 $(cat client.cinder.key) && rm -rf client.cinder.key secret.xml
-
在compute02创建密钥文件
cd /root
cat >secret.xml <
ae210c04-3d2e-41ca-ac8c-2d5840eb846c
client.cinder secret
EOF
##定义秘钥,并将其保存
virsh secret-define --file secret.xml
##设置秘钥并删除临时文件
virsh secret-set-value --secret ae210c04-3d2e-41ca-ac8c-2d5840eb846c --base64 $(cat client.cinder.key) && rm -rf client.cinder.key secret.xml
CEPH对接Glance
-
在控制节点,上备份glance配置文件
cp /etc/glance/glance-api.conf /etc/glance/glance-api.conf.bak- 修改glance配置文件
vi /etc/glance/glance-api.conf
[glance_store]
stores = rbd ###●2054行、存储的类型格式
default_store = rbd ###●2108行、修改默认的存储格式类型
#filesystem_store_datadir = /var/lib/glance/images/ ###●2442行、默认储存本地注销掉
rbd_store_chunk_size = 8 ###●2605行、去掉注释
rbd_store_pool = images ###●2626行、去掉注释
rbd_store_user = glance ###●2645行、去掉注释、指定glance用户,不知道可以查
rbd_store_ceph_conf = /etc/ceph/ceph.conf ###●2664行、去掉注释 指定CEPH的路径
-
重启glance-api服务
systemctl restart openstack-glance-api
- 直接在openstack界面上传镜像


-
查看镜像信息

- 保持三个池子的开启自启
ceph osd pool application enable vms mon
ceph osd pool application enable images mon
ceph osd pool application enable volumes monCEPH对接cinder
- 在控制节点上,备份cinder.conf配置文件
cp /etc/cinder/cinder.conf /etc/cinder/cinder.conf.bak-
在控制节点上,修改配置文件
vi /etc/cinder/cinder.conf
[DEFAULT]
glance_api_version = 2
enabled_backends = ceph,lvm
如果这边有2中类型的格式(ceph和lvmd) glance_api_version=2 就写在 default 选项中
如如果这边有1中类型的格式 如ceph中,那么glance_api_version=2 就写在 ceph 选项中
[ceph]
default_volume_type= ceph
glance_api_version = 2
volume_driver = cinder.volume.drivers.rbd.RBDDriver
volume_backend_name = ceph
rbd_pool = volumes
rbd_ceph_conf = /etc/ceph/ceph.conf
rbd_flatten_volume_from_snapshot = false
rbd_max_clone_depth = 5
rbd_store_chunk_size = 4
rados_connect_timeout = -1
rbd_user = cinder
rbd_secret_uuid = ae210c04-3d2e-41ca-ac8c-2d5840eb846c ####这个uuid 写在自己的计算节点上的
-
重启cinder服务
[root@ct ~(keystone_admin)]# systemctl restart openstack-cinder-volume-
命令行创建cinder 的ceph存储后端相应的type
cinder type-create ceph -
查看cinder卷的类型
[root@control ~(keystone_admin)]# cinder type-list
+--------------------------------------+-------+-------------+-----------+
| ID | Name | Description | Is_Public |
+--------------------------------------+-------+-------------+-----------+
| 7e82fbf4-a194-4874-875e-e0d641ea4095 | iscsi | - | True |
| b26ef37d-aeb2-4b9a-b7b9-af50e71a6ba9 | ceph | - | True |
+--------------------------------------+-------+-------------+-----------+
[root@control ~(keystone_admin)]#
-
设置后端的存储类型
cinder type-key ceph set volume_backend_name=ceph-
在openstack界面创建卷
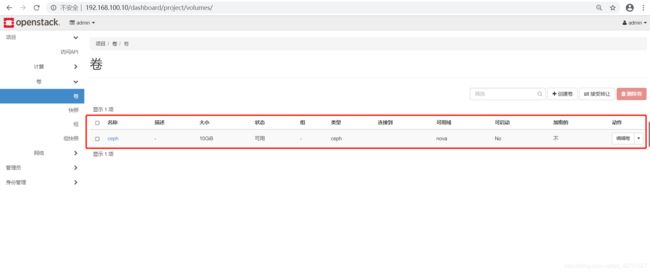
- 查看创建的卷
[root@control ~(keystone_admin)]# rbd ls volumes
volume-adfdc7aa-d018-4041-9c70-dd42fc412a5f
[root@control ~(keystone_admin)]#
- 开机自启cinder-api服务
systemctl enable openstack-cinder-api.service openstack-cinder-scheduler.service
systemctl start openstack-cinder-api.service openstack-cinder-scheduler.serviceCEPH对接Nova,分别在compute01和compute02节点操作
- 备份配置文件
cp /etc/nova/nova.conf /etc/nova/nova.conf.bak- 修改配置文件
vi /etc/nova/nova.conf 所有计算节点的配置文件
[libvirt]
images_type = rbd ####●7079行、去掉注释、修改类型RBD
images_rbd_pool = vms ####●7103行、去掉注释、改为VMS在CEPH中声明的
images_rbd_ceph_conf = /etc/ceph/ceph.conf ####●7106行、去掉注释、添加CEPH配置文件路径
rbd_user = cinder ####●7263行、去掉注释、添加cinder
rbd_secret_uuid =ae210c04-3d2e-41ca-ac8c-2d5840eb846c ####●7261行、去掉注释、添加UUID值
disk_cachemodes="network=writeback" ####●6938行、去掉注释、添加"network=writeback"硬盘缓存模式
inject_password=false ####6421行、不用更改
inject_key=false ####6446行、不用更改
inject_partition=-2 ####6484行、不用更改
live_migration_flag="VIR_MIGRATE_UNDEFINE_SOURCE,VIR_MIGRATE_PEER2PEER,VIR_MIGRATE_LIVE,VIR_MIGRATE_PERSIST_DEST,VIR_MIGRATE_TUNNELLED" ####●找到live_migration附近添加整行 是否启用热迁移
hw_disk_discard=unmap ####●7121行、去掉注释、添加unmap-
安装libvirt
yum -y install libvirt-
编辑ceph配置文件
vi /etc/ceph/ceph.conf
##添加文件
[client]
rbd cache=true
rbd cache writethrough until flush=true
admin socket = /var/run/ceph/guests/$cluster-$type.$id.$pid.$cctid.asok
log file = /var/log/qemu/qemu-guest-$pid.log
rbd concurrent management ops = 20-
创建日志目录
mkdir -p /var/run/ceph/guests/ /var/log/qemu/
chown 777 -R /var/run/ceph/guests/ /var/log/qemu/-
将控制节点/etc/ceph下的密钥下发到计算节点
cd /etc/ceph
scp ceph.client.cinder.keyring root@compute01:/etc/ceph
scp ceph.client.cinder.keyring root@compute02:/etc/ceph
-
在计算节点重启服务
systemctl restart libvirtd
systemctl enable libvirtd
systemctl restart openstack-nova-compute测试OpenStack+CEPH群集
- 创建实例,参考https://blog.csdn.net/qq_42761527/article/details/104616615
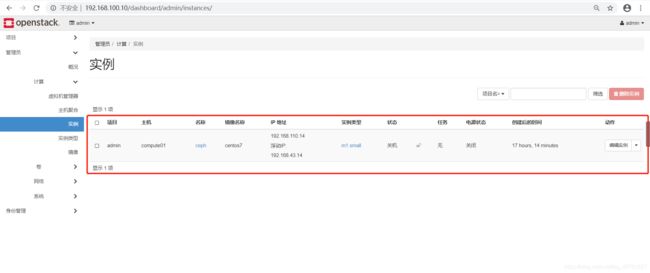
- 查看实例
[root@control ~(keystone_admin)]# rbd ls vms
fcb4a844-3dce-43ee-aeb3-5afc584f2794_disk
[root@control ~(keystone_admin)]#
- 对实例进行热迁移
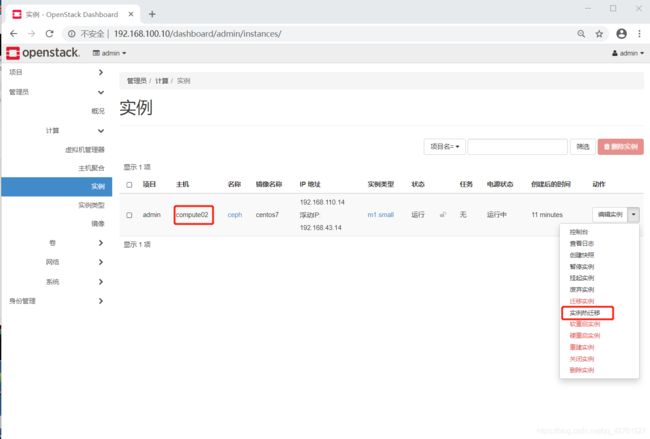


注:由于在热迁移当中,会有网络迁移,会导致一些数据包的丢失