openCV-python 入门笔记
前言
最近为了做人脸识别的比赛项目,自己学习了一下openCV的简单操作,
发几篇博文把学到的东西总结一下。慢慢码,不定期更新。
openCV简介

OpenCV(open指开源,CV是computer vision 计算机视觉的缩写)是一个基于BSD许可(开源)发行的跨平台计算机视觉和机器学习软件库,可以运行在Linux、Windows、Android和Mac OS操作系统上。
openCV的安装
在cmd中使用 pip install opencv-python 直接安装
入门操作
1.读取、展示图片
openCV对图片处理的大概流程是这样的:
- 使用cv2下的imread函数读入图片;
- 对图片进行处理(灰度转化、模糊、掩膜等);
- 使用imshow函数展示图片
接下来具体介绍一些每个函数及其参数。
cv2.imread(filename, flag=1) 读入图片
参数1:读入图片的路径;
参数2:标志量,如果flag=1,读入的为原图片;flag=0,读入灰度图;默认为1
返回值:返回值为一个矩阵,第一维是矩阵的长,第二维是矩阵的宽,第三维为图片的通道数。(如果flag=1则没有第三维)。
cv2.imshow(windowName, img) 显示图片
参数1:展示图片的窗口的名字;
参数2:需要展示的图片矩阵;
import cv2
# 导入图片
img = cv2.imread("../picture/01.jpg", 1)
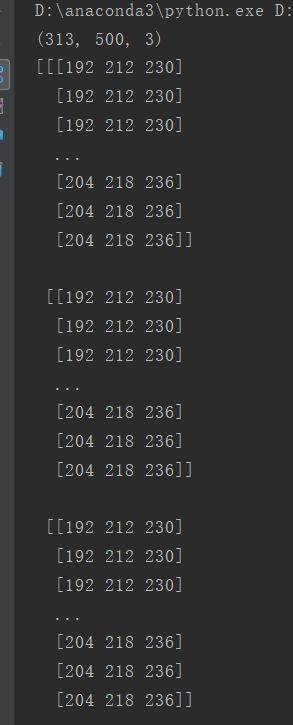
print(img.shape) # 查看图片矩阵形状
print(img) # 查看图片矩阵
cv2.imshow("Output", img) # imshow显示图片
# delay单位是毫秒,默认为0,waitkey函数意为窗口在delay秒后自动关闭,delay为0则无限等待
cv2.waitKey(0)
效果: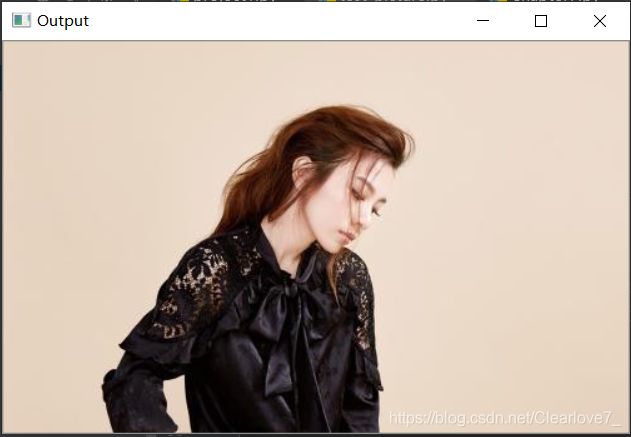
2.读取视频
openCV中提供了读取视频的方法VideoCapture()
方法本质是将视频拆分成一张张图片,然后送入while循环中逐次读取出来,然后imshow在窗口当中。
cv2.VideoCapture(filename/deviceID)
函数传入的参数为视频的路径或者是摄像头id编号(笔记本摄像头默认编号为0)
import cv2
# 调用摄像头只需更改视频路径为 0, 其他代码无需改动
cap = cv2.VideoCapture("./video/01.mp4")
while True:
# 第一个变量bool类型用来判断,read()函数是否成功执行,将捕获的信息存在img中
success, img = cap.read()
cv2.imshow("video", img)
# 设置每张图片等待一毫秒消失,并且设置键盘输入q则结束视频的读取
if cv2.waitKey(1) & 0xFF == ord('q'):
break
结果:
图片处理
在此板块中,会介绍一些基本的图片处理方法。
1.图片转化为灰度图
转化为灰度图的目的一般情况下是为了减少图片处理的计算量 。自然界中,颜色本身非常容易受到光照的影响,rgb变化很大,反而梯度信息能提供更本质的信息。三通道转为一通道后,运算量大大减少。
cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
参数1:原图片矩阵
参数2:openCV中提供了很多设定好的参数,BGR2GRAY参数意为BGR图片转化到灰度图,其他参数不一一赘述。
返回值:一个二维的灰度图数组。
2.高斯模糊
进行高斯模糊的目的主要是对图像进行去噪声(无用的干扰特征),同时能够更多的保留图像的总体灰度分布特征。
cv2.GaussianBlur(src, ksize, sigmaX, sigmaY)
src: 图片输入路径。
ksize:运算用滑动窗口大小,窗口矩阵必须为奇数(高斯操作原因)。
sigmaX:X方向上的高斯核标准偏差。
sigmaY:Y方向上的高斯核标准差;如果sigmaY为零,则将其设置为等于sigmaX;如果两个sigmas为零,则分别从ksize.width和ksize.height计算得出。
返回值:一个与src同规格的经模糊后图像。
3.边缘查找
使用cv2中提供的Canny函数进行图片的边缘查找
cv2.Canny(image, threshold1, threshold2[, edges[, apertureSize[, L2gradient[[[)
image:输入图像
threshold1:设置的低阈值
threshold2:设置的高阈值,一般高低阈值的比例为3:1或者2:1
(根据图片边缘寻找情况,自行调整高低闸值)
返回值:一个带有边缘显示的图像。
4.腐蚀&膨胀腐蚀:
- 腐蚀会把物体的边界腐蚀掉,卷积核沿着图象滑动,如果卷积核对应的原图的所有像素值为1,那么中心元素就保持原来的值,否则变为零。主要应用在去除白噪声,也可以断开连在一起的物体。
- 膨胀:卷积核所对应的原图像的像素值只要有一个是1,中心像素值就是1。一般在除噪是,先腐蚀再膨胀,因为腐蚀在去除白噪声的时候也会使图像缩小,所以我们之后要进行膨胀。当然也可以用来将两者物体分开。
扩展:
开运算和闭运算
1.开运算和闭运算就是将腐蚀和膨胀按照一定的次序进行处理。 但这两者并不是可逆的,即先开后闭并不能得到原先的图像。
2.为了获取图像中的主要对象:对一副二值图连续使用闭运算和开运算,或者消除图像中的噪声,也可以对图像先用开运算后用闭运算,不过这样也会消除一些破碎的对象。
开运算:先腐蚀后膨胀,用于移除由图像噪音形成的斑点。
闭运算:先膨胀后腐蚀,用来连接被误分为许多小块的对象;
腐蚀操作 cv2.erode(img,kernel)
img: 输入图片路径。
kernel:用来操作的卷积核的大小。
返回值:腐蚀后的图像矩阵
膨胀操作 cv2.dilate(img,kernel)
img: 输入图片路径。
kernel:用来操作的卷积核的大小。
返回值:膨胀后的图像矩阵。
import cv2
import numpy as np
img = cv2.imread("../picture/01.jpg")
# 腐蚀与膨胀的卷积核的定义
kernel = np.ones((5, 5), np.uint8)
# 转化为灰度图
imgGray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# ksize()内核大小,blur模糊图像
imgBlur = cv2.GaussianBlur(imgGray, (7, 7), 0)
# 边缘检测, 第二三参数为闸值1,2
imgCanny = cv2.Canny(img, 150, 200)
# 膨胀,在边缘线模糊的情况下,进行增强
# 第二个参数为内核,第三个为对一幅图像进行迭代膨胀的次数
imgDialation = cv2.dilate(imgCanny, kernel=kernel, iterations=1)
# 腐蚀操作,与膨胀操作相反
imgEroded = cv2.erode(imgDialation, kernel, iterations=1)
cv2.imshow("Gray Image", imgGray)
cv2.imshow("Blur Image", imgBlur)
cv2.imshow("Canny Image", imgCanny)
cv2.imshow("Dialation Image", imgDialation)
cv2.imshow("Eroded Image", imgEroded)
cv2.waitKey(0)
效果图:
灰度图:

高斯模糊后:
边缘检测:
膨胀:

腐蚀:

5.裁剪&更改图片尺寸
更改图片尺寸
在很多时候需要对imread的图片进行大小的修改(神经网络的输入、在同一窗口中展示多张图片),openCV中提供了cv2.resize()函数来对图片的尺寸大小进行修改,本质是改变图片矩阵中像素点的数量。
cv2.resize(src, dsize, fX, fY,interpolation)
src: 输入图片路径。
dsize:输出图片大小,为一个一维两元素的列表/元组,分别指定宽和高。
fX:如果dsize为(0, 0),则fX与fY生效,为X方向上缩放的倍率。
fY:y方向上缩放的倍率。
interpolation:表示插值方式,有以下几种:
- NTER_NEAREST - 最近邻插值
- INTER_LINEAR - 线性插值(默认)
- INTER_AREA - 区域插值
- INTER_CUBIC - 三次样条插值
- INTER_LANCZOS4 -Lanczos插值
返回值:经过大小变换的新图象。
# resize参数 : 路径,输出图片大小(如果设置缩放,输出图片为(0,0), x缩放,y缩放, 插入方式
imgResize = cv2.resize(img, (250, 150))
cv2.imshow("Resize", imgResize)
cv2.waitKey(0)
裁剪图片(通过切割图片矩阵实现)
在计算机中,图像是以矩阵的形式保存的(先行后列)。
比如一张宽度640像素、长度480像素的灰度图保存在一个480 * 640的矩阵中。
openCV中,默认的坐标系是从屏幕的左上方开始,向左为X,向右为Y。
虽然openCV中设置横方向为x坐标,但是在切割图片矩阵的时候是以img[height, weight]的方式进行切割的。
# 裁剪图像, 先写高度,再写宽度
imgCrope = img[0:200, 200:500]
cv2.imshow("Croppe", imgCrope)
cv2.waitKey(0)
本部分完整代码:
import cv2
# 导入图片
img = cv2.imread("../picture/01.jpg")
print(img.shape) # 高、宽、通道数、BGR
# 更改图片大小
# resize参数 : 路径,输出图片大小(如果设置缩放,输出图片为(0,0), x缩放,y缩放, 插入方式
imgResize = cv2.resize(img, (250, 150))
print(imgResize.shape)
# 裁剪图像, 先写高度,再写宽度
imgCrope = img[0:200, 200:500]
print(imgCrope.shape)
cv2.imshow("Output", img)
cv2.imshow("Resize", imgResize)
cv2.imshow("Croppe", imgCrope)
cv2.waitKey(0) # delay单位是毫秒
运行结果:
原图片:
调整大小后:
裁剪后:
三个图像的图片矩阵形状:

6.通过numpy创建空白图片&在图片上划线\写字
上文说过,计算机存储图像是以矩阵的形式存储,所以我们想创建图像可以通过创建符合图像存储规则的矩阵来实现。
img = np.zeros((512, 512, 3), np.uint8)
print(img.shape)

书写图片
cv2.中提供了相应的方法来绘图,添加文字,方便我们进行图像的标记(人练识别、目标跟踪)。
cv2.line(src, (pt1 , pt2), color, thickness) 画直线方法
src:图片路径。
pt1、pt2:直线的起点与终点。
color:直线颜色。
thickness:直线厚度。
cv2.rectangle(src, pt1, pt2, color, thickness)
与line方法基本一致,pt1与pt2输入为矩形的左上方点和右下方点;thickness中有cv2.FILLED选项,选择画出来的是填充的圆还是空心圆。
cv2.circle(img, center, radius, color, thickness)
img: 图片路径。
center:圆心坐标。
radius:半径长度。
color:颜色。
thickness:与rectangle方法一致。
cv2.putText(img, text, location, font, font_size, font_color, thickness)
img:图片路径。
text:要书写的文本。
location:位置。
font:字体。
font_size:字体大小。
font_color:字体颜色。
thickness:厚度/宽度。
import cv2
import numpy as np
# 创建空白图片
img = np.zeros((512, 512, 3), np.uint8)
print(img.shape)
# 改变颜色
# img[200:300] = 255, 0, 0
# 划线
# 第一个参数,src;第二个参数,起点终点坐标(宽,高),第三个参数颜色,第四个参数线段的厚度
cv2.line(img, (0, 0), (img.shape[1], img.shape[0]), (0, 255, 0), 3)
# 画矩形,同划线,最后一个参数设置填充
cv2.rectangle(img, (0, 0), (250, 350), (0, 0, 255), 2) # cv2.FILLED
cv2.circle(img, (400, 50), 30, (255, 255, 0), 5)
# 放置文本
# 参数:图片本身,文字内容,位置,字体,字体大小,字体颜色,厚度/宽度
cv2.putText(img, "OPENCV", (300, 100), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 150, 0), 1)
cv2.imshow("Image", img)
cv2.waitKey(0)
效果图:
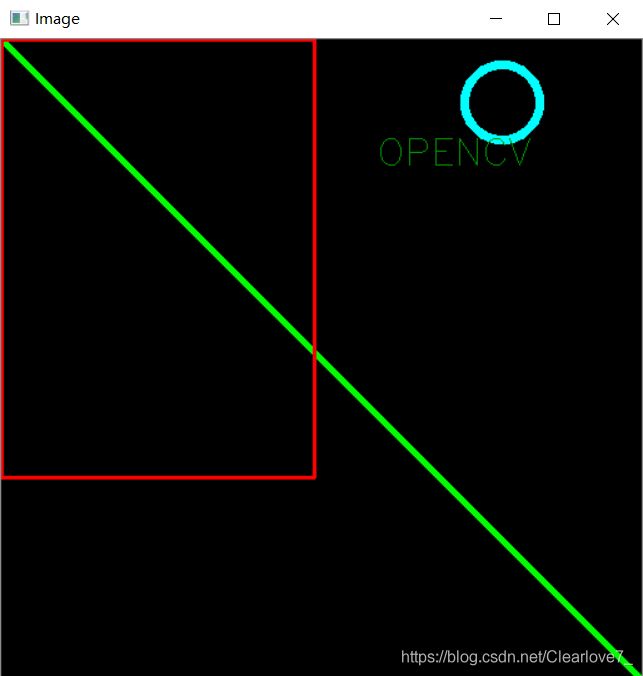
7.透视变换,投影操作
有的时候,我们希望提取图片的一部分,比如:

我们希望将这个图片的红桃Q部分单独显示出来,我们可以通过投影操作把其中一部分提取出来。
投影操作的原理如图:

把原图中的n个点(通过ps等工具测量),映射到新图片的对应n个点上,形成投影。
import cv2
import numpy as np
# 导入图片
img = cv2.imread("../picture/card.jpg")
# 透视变换,投影
# 设置宽高
width, height = 250, 350
# 设置原图片与新图片的投影对应坐标点
pts1 = np.float32([[273, 10],[400, 10], [273, 194], [400, 194]])
pts2 = np.float32([[0, 0], [width, 0], [0, height], [width, height]])
# 透视变换,构建规则矩阵
matrix = cv2.getPerspectiveTransform(pts1, pts2) # 返回的是一个矩阵
imgOutput = cv2.warpPerspective(img, matrix, (width, height)) # 返回的是一个图像
效果:
原图片:

投影结果:

8.单个窗口展示多张图片
在调试代码的过程中,很多时候要用到很多张图片同时进行比较,这种情况下如果将图片整和到同一个窗口内,对比起来比较方便。openCV中没有直接的提供相应的方法实现,但我们可以利用numpy中的横向堆栈和纵向堆栈来实现。
具体代码如下:
# coding:utf-8
import cv2
import numpy as np
img = cv2.imread("../picture/01.jpg")
# 调用横向堆栈
img_double = np.hstack((img, img))
cv2.imshow("result", img_double)
cv2.waitKey(0)
结果:

# 纵向堆栈
img_2double = np.vstack((img, img))
cv2.imshow("result2", img_2double)
cv2.waitKey(0)
结果

两种堆栈组合使用,可以同时显示多张图片:
img_2t = np.vstack((np.hstack((img, img)),(np.hstack((img, img)))))
cv2.imshow("result3", img_2t)
cv2.waitKey(0)
结果:

- 注:调用numpy的堆栈进行的图片展示,所选择的图片必须形状相同、维度相同,如果出现不一致的情况会抛出异常。
- 这里提供一个解决此问题的模块(摘自“三小时入门openCV”),逻辑很清晰,这里不多赘述,上代码:
def stackImages(scale,imgArray):
# 提取行和列
rows = len(imgArray)
cols = len(imgArray[0])
# 判断类型,考虑继承关系
rowsAvailable = isinstance(imgArray[0], list)
# 提取图片宽、高
width = imgArray[0][0].shape[1]
height = imgArray[0][0].shape[0]
if rowsAvailable:
for x in range(0, rows):
for y in range(0, cols):
if imgArray[x][y].shape[:2] == imgArray[0][0].shape[:2]:
imgArray[x][y] = cv2.resize(imgArray[x][y], (0, 0), None, scale, scale)
else:
imgArray[x][y] = cv2.resize(imgArray[x][y], (imgArray[0][0].shape[1], imgArray[0][0].shape[0]), None, scale, scale)
if len(imgArray[x][y].shape) == 2:
imgArray[x][y] = cv2.cvtColor(imgArray[x][y], cv2.COLOR_GRAY2BGR)
imageBlank = np.zeros((height, width, 3), np.uint8)
hor = [imageBlank]*rows
hor_con = [imageBlank]*rows
for x in range(0, rows):
hor[x] = np.hstack(imgArray[x])
ver = np.vstack(hor)
else:
for x in range(0, rows):
if imgArray[x].shape[:2] == imgArray[0].shape[:2]:
imgArray[x] = cv2.resize(imgArray[x], (0, 0), None, scale, scale)
else:
imgArray[x] = cv2.resize(imgArray[x], (imgArray[0].shape[1], imgArray[0].shape[0]), None,scale, scale)
if len(imgArray[x].shape) == 2: imgArray[x] = cv2.cvtColor(imgArray[x], cv2.COLOR_GRAY2BGR)
hor= np.hstack(imgArray)
ver = hor
return ver
9. 掩膜操作
所谓掩膜其实就是一个矩阵,然后根据这个矩阵重新计算图片中像素的值。
数字图像处理中,图像掩模主要用于:
-
提取感兴趣区,用预先制作的感兴趣区掩模与待处理图像相乘,得到感兴趣区图像,感兴趣区内图像值保持不变,而区外图像值都为0。
-
屏蔽作用,用掩模对图像上某些区域作屏蔽,使其不参加处理或不参加处理参数的计算,或仅对屏蔽区作处理或统计。
-
结构特征提取,用相似性变量或图像匹配方法检测和提取图像中与掩模相似的结构特征。 ④特殊形状图像的制作。
使用TrackBar进行调试
在进行掩膜操作时,要收集构成图片的三通道的上限值和下限值,用来构成掩膜矩阵。为了方便我们寻找三通道的上下限,我们引入TrackBar滑动条来方便我们寻找上下限。
直接上代码,没什么难度:
# 滑动条
# 创建一个新的窗口来存放滑动条
cv2.namedWindow("TrackBars")
cv2.resizeWindow("TrackBars", 640, 240)
# 这里以HSV为示例, 三通道一共六个参数,分别为三通道的最小值,最大值, empty为回调函数
# 第五个参数是回调函数,每次滑动条的滑动都会调用回调函数。回调函数通常会有一个默认参数,就是滑动条的位置。
cv2.createTrackbar("Hue Min", "TrackBars", 0, 179, empty)
cv2.createTrackbar("Hue Max", "TrackBars", 179, 179, empty)
cv2.createTrackbar("Sat Min", "TrackBars", 0, 255, empty)
cv2.createTrackbar("Sat Max", "TrackBars", 255, 255, empty)
cv2.createTrackbar("Val Min", "TrackBars", 0, 255, empty)
cv2.createTrackbar("Val Max", "TrackBars", 255, 255, empty)
while True:
h_min = cv2.getTrackbarPos("Hue Min", "TrackBars")
s_min = cv2.getTrackbarPos("Sat Min", "TrackBars")
s_max = cv2.getTrackbarPos("Sat Max", "TrackBars")
h_max = cv2.getTrackbarPos("Hue Max", "TrackBars")
v_min = cv2.getTrackbarPos("Val Min", "TrackBars")
v_max = cv2.getTrackbarPos("Val Max", "TrackBars")
结果:

cv2.inRange(src, lowerb, upperb)
此函数检查数组元素是否位于另外两个数组的元素之间,简单来说就是找出指定范围的图像,并返回一个二值图,指定范围内显示白色,其他区域为黑色。
src:图片路径。
lowerb:下限闸值。
upperb:上线闸值。
cv2.bitwise_and(src1,src2[,mask])
将图像1和图像2进行按位与操作(bitwise:按位)
- src1:输入图像1
- src2:输入图像2
- mask:可选参数, 掩膜操作,在src1与src2进行运算后,如果使用了此参数,则会与此参数执行按位与操作。
# 掩膜操作
import numpy as np
import cv2
# 0 179 41 255 41 255
def empty(a):
pass
print("Package Imported")
# 导入图片
path = "../picture/12.jpg"
# 滑动条
# 创建一个新的窗口来存放滑动条
cv2.namedWindow("TrackBars")
cv2.resizeWindow("TrackBars", 640, 240)
# 这里以HSV为示例, 三通道一共六个参数,分别为三通道的最小值,最大值, empty为回调函数
# 第五个参数是回调函数,每次滑动条的滑动都会调用回调函数。回调函数通常会有一个默认参数,就是滑动条的位置。
cv2.createTrackbar("Hue Min", "TrackBars", 0, 179, empty)
cv2.createTrackbar("Hue Max", "TrackBars", 179, 179, empty)
cv2.createTrackbar("Sat Min", "TrackBars", 0, 255, empty)
cv2.createTrackbar("Sat Max", "TrackBars", 255, 255, empty)
cv2.createTrackbar("Val Min", "TrackBars", 0, 255, empty)
cv2.createTrackbar("Val Max", "TrackBars", 255, 255, empty)
while True:
img = cv2.imread(path)
imgRe = cv2.resize(img, (0, 0), None, 0.5, 0.5)
imgHSV = cv2.cvtColor(imgRe, cv2.COLOR_BGR2HSV)
h_min = cv2.getTrackbarPos("Hue Min", "TrackBars")
s_min = cv2.getTrackbarPos("Sat Min", "TrackBars")
s_max = cv2.getTrackbarPos("Sat Max", "TrackBars")
h_max = cv2.getTrackbarPos("Hue Max", "TrackBars")
v_min = cv2.getTrackbarPos("Val Min", "TrackBars")
v_max = cv2.getTrackbarPos("Val Max", "TrackBars")
print(h_min, h_max, s_min, s_max, v_min, v_max)
lower = np.array([h_min, s_min, v_min])
upper = np.array([h_max, s_max, v_max])
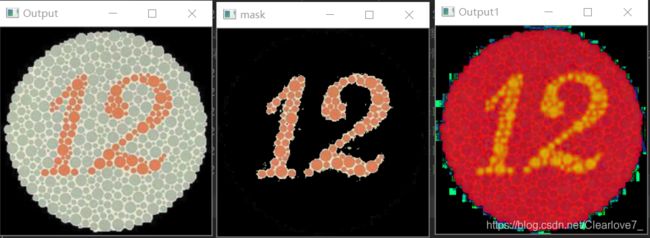
# 掩膜操作,设置区间,仅保留lower与upper之间的颜色
mask = cv2.inRange(imgHSV, lower, upper)
# 逻辑与
imgResult = cv2.bitwise_and(imgRe, imgRe, mask=mask)
cv2.imshow("Output", imgRe)
cv2.imshow("Output1", imgHSV)
cv2.imshow("mask",mask)
cv2.imshow("mask",imgResult)
cv2.waitKey(1)
通过调节参数,得到
结果:
10.寻找轮廓 & 多边形逼近
cv中提供了相应的寻找轮廓的方法,结合多边形逼近操作,可以实现物体的形状识别。
本质是先寻找出物体的轮廓,然后多边形逼近操作寻找拐点数,根据拐点数判别形状。
cv2.findContours(image, mode, method, contours=None, hierarchy=None, offset=None)
通过此方法可以进行图像的轮廓查找,返回一个具有所有轮廓合集的矩阵。输入必须为灰度图(二值图)
- image输入/输出的图像
- 第二个参数表示轮廓的检索模式有四种:
cv2.RETR_EXTERNAL:表示只检测外轮廓
cv2.RETR_LIST:检测的轮廓不建立等级关系
cv2.RETR_CCOMP:建立两个等级的轮廓,上面的一层为外边界,里面的一层为内孔的边界信息。如果内孔内还有一个连通物体,这个物体的边界也在顶层。
cv2.RETR_TREE:建立一个等级树结构的轮廓。
第三个参数method为轮廓的近似办法:
cv2.CHAIN_APPROX_NONE:存储所有的轮廓点,相邻的两个点的像素位置差不超过1,即max(abs(x1-x2),abs(y2-y1))==1
cv2.CHAIN_APPROX_SIMPLE:压缩水平方向,垂直方向,对角线方向的元素,只保留该方向的终点坐标,例如一个矩形轮廓只需4个点来保存轮廓信息
cv2.CHAIN_APPROX_TC89_L1,CV_CHAIN_APPROX_TC89_KCOS使用teh-Chinl chain 近似算法
多边形逼近
主要功能是把一个连续光滑曲线折线化,对图像轮廓点进行多边形拟合
cv2.approxPolyDP(src, epsilon, close)
第一个参数:单个形状矩阵
第二个参数:精度,一般为0.02*周长
第三个参数:是否封闭
11.形状识别在实际中的运用
# coding:utf-8
import cv2
import numpy as np
def stackImages(scale,imgArray):
# 提取行和列
rows = len(imgArray)
cols = len(imgArray[0])
# 判断类型,考虑继承关系
rowsAvailable = isinstance(imgArray[0], list)
# 提取图片宽、高
width = imgArray[0][0].shape[1]
height = imgArray[0][0].shape[0]
if rowsAvailable:
for x in range(0, rows):
for y in range(0, cols):
if imgArray[x][y].shape[:2] == imgArray[0][0].shape[:2]:
imgArray[x][y] = cv2.resize(imgArray[x][y], (0, 0), None, scale, scale)
else:
imgArray[x][y] = cv2.resize(imgArray[x][y], (imgArray[0][0].shape[1], imgArray[0][0].shape[0]), None, scale, scale)
if len(imgArray[x][y].shape) == 2:
imgArray[x][y] = cv2.cvtColor(imgArray[x][y], cv2.COLOR_GRAY2BGR)
imageBlank = np.zeros((height, width, 3), np.uint8)
hor = [imageBlank]*rows
hor_con = [imageBlank]*rows
for x in range(0, rows):
hor[x] = np.hstack(imgArray[x])
ver = np.vstack(hor)
else:
for x in range(0, rows):
if imgArray[x].shape[:2] == imgArray[0].shape[:2]:
imgArray[x] = cv2.resize(imgArray[x], (0, 0), None, scale, scale)
else:
imgArray[x] = cv2.resize(imgArray[x], (imgArray[0].shape[1], imgArray[0].shape[0]), None,scale, scale)
if len(imgArray[x].shape) == 2: imgArray[x] = cv2.cvtColor(imgArray[x], cv2.COLOR_GRAY2BGR)
hor= np.hstack(imgArray)
ver = hor
return ver
def getContours(img):
# 检测外部轮廓, 第二个参数选择使用的方法为:只检测最外围轮廓,包含在外围轮廓内的内围轮廓被忽略,第三个参数为检测所有轮廓
countours, hierarchy = cv2.findContours(img, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
for cnt in countours:
# 找到轮廓所包含的范围
area = cv2.contourArea(cnt)
if area >= 500:
# 画出形状, 第一个参数被画图片路径,第二个参数轮廓, 第三个参数-1为画所有轮廓, 第四个参数是线段颜色, 第五个参数是线段厚度
cv2.drawContours(imgContour, cnt, -1, (255, 0, 0), 3)
# 周长, 第一个参数是轮廓, 第二个参数是 是否为封闭图形
peri = cv2.arcLength(cnt, True)
# 找拐点坐标,第一个参数为轮廓,第二个参数是精度,第三个参数是 是否为封闭图形
approx = cv2.approxPolyDP(cnt, 0.02*peri, True)
print(len(approx))
# 拐点数量
objCor = len(approx)
# 根据拐点得到由拐点构成的 BoundingBox的坐标
x, y, w, h = cv2.boundingRect(approx)
# 根据拐点数确定图形的形状
if objCor == 3: objectType = "Tri"
elif objCor == 4:
aspRatio = w / float(h)
if aspRatio >= 0.95 and aspRatio < 1.05:
objectType = "squre"
else:
objectType = "rect"
elif objCor > 4:
objectType = "Circles"
else: objectType="None"
# 加入文本
cv2.rectangle(imgContour, (x, y), (x+w, y+h), (0, 255, 0), 2)
cv2.putText(imgContour, objectType, ((x + (w // 2)), y + (h // 2) - 10),
cv2.FONT_HERSHEY_COMPLEX, 0.5,
(0, 0, 0), 2)
# 导入图片
path = "../picture/shapes.jpg"
img = cv2.imread(path)
imgContour = img.copy()
# 转化为灰度图
imgGray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 模糊,参数,第一个为src, 第二个为核体积, 第三个为x方向的标准差
imgBlur = cv2.GaussianBlur(imgGray, (7, 7), 1)
# 边缘检测
imgCanny = cv2.Canny(imgBlur, 50, 50)
getContours(imgCanny)
# 占位
imgBlank = np.zeros_like(img)
imgStack = stackImages(0.6, [[img, imgGray, imgBlur],
[imgCanny, imgContour, imgBlank]])
cv2.imshow("Output", imgStack)
cv2.waitKey(0) # delay单位是毫秒
成功识别,结果如下:

openCV的基本操作就这些了。