最短路径经典算法其一Dijkstra
最短路径经典算法其一Dijkstra
- 前言
- 一、算法原理讲解
- 二、代码实现
-
- 代码细节讲解
- 时间复杂度
- 样例测试
- 三、BFS 实现 Dijkstra
-
- 实现思路
- 代码
- 测试样例
- 四、总结:
- Reference
前言
今天我们来讲讲图搜索最短路径,这里的最短路径包含了从一个节点到达另一个节点需要考虑之间的距离或者时间消耗,即从起点到达终点所需的时间(或者其他形式的消耗)最少,不同于我们之前提到的迷宫搜索类最短路径——通路上的节点数量更少(即假设节点间的距离都是1)
Ps: 原文章系博主的微信推文,有一些会有前后联系,现陆续搬运到CSDN~
一、算法原理讲解
实现语言:Python
对于上面的问题,我们看下面的这张图:

这个时候我们好像需要去遍历图上的节点,常规BFS搜索得到的最短路径不一定是耗时最少的。
这里我们介绍经典的单源最短路径搜索算法——狄克斯特拉算法(Dijkstra’s algorithm)。单源的意思是说它可以得到指定的一个起点到达其他所有节点的最短距离。
本质上它是一个循环优化算法,在每个循环里,它完成下面的几个步骤:
1. 找到当前已知距离起点最短的节点,即可以最快到达的点2. 通过与该点连接的其他节点更新周围节点的距离开销,即起点到达这些周围节点的距离
以上面的图为例,我们来用图表示一下简单的算法流程:
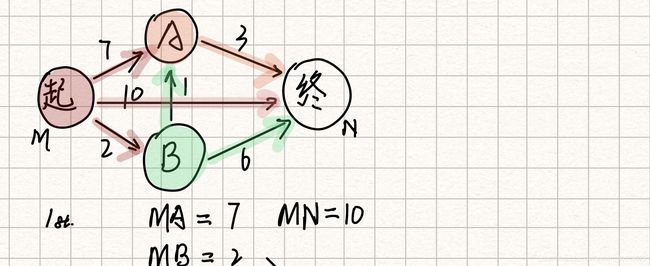
首先最先知道的最短节点是起点本身,一开始我们要设置所有点之间都是无穷远,然后用已知的边来更新这些值,不过这里我给到的图示所有的边权重都有给出。从起点M开始,找到了A,B,N,并更新权重。
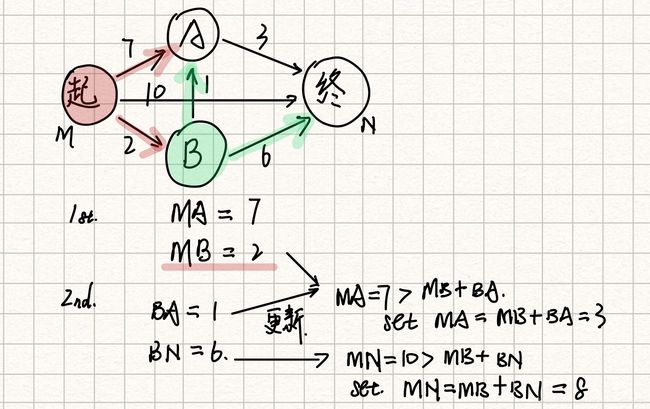
第二次循环开始,找到距离起点最近的点为B后,开始找和B相连的其他节点,记住这些节点不能是之前循环标记过的最近点,因为之前循环确定的最近点对这一轮更新其到起点的距离没有意义,它已经是最近的了。
我们可以看到符合条件的有A和N,接下来更新它们到起点的距离值。发现MB+BA< MA,即有更近的路可以从起点到达A点,所以更新MA的值,同样的更新MN的值。

第三次循环距离起点最近的点为A,找到与A相连的且还没被标记过的节点,只有N,但是MA+AN=10>MN=8,所以不更新MN的距离值。
下一次循环到达终点后即可退出,所以最终起点到达所有其他节点的最短距离都可以得到,也就包括起点到终点。

二、代码实现
def Dijkstra(directed=False):
"""
Functions: Implementation of Dijkstra using Python
Args:
directed: whether the graph is directed or not
return:
None
"""
# init distance
limit = 10000
# number of nodes, number of links, start_index, end_index
N, K, s, e = list(map(int, input().split()))
# graph mat
ad_mat = [[0 for i in range(N)] for j in range(N)]
# distance to start_node
Dis = [limit for i in range(N)]
# tags array
vis = [0 for i in range(N)]
# use links to fresh graph mat
for i in range(K):
u, v, w = list(map(int, input().split()))
ad_mat[u][v] = w
if directed == False:
ad_mat[v][u] = w
# init distance of start_node
Dis[s] = 0
# core logic
for i in range(N):
# select nodes with shortest distance to start from unchecked nodes
min_ind = Dis.index(min([Dis[k] for k in range(len(Dis)) if vis[k] == 0]))
# sign the node
vis[min_ind] = 1
for j in range(N):
# fresh distance from start_node to adjacent nodes
# unchecked, exist links, shorter then original dis
if vis[j] == 0 \
and ad_mat[min_ind][j] != 0 \
and Dis[j] > (Dis[min_ind]+ad_mat[min_ind][j]):
Dis[j] = Dis[min_ind]+ad_mat[min_ind][j]
print('Shortest distance from s to e: {}'.format(Dis[e]))
return
代码细节讲解
min_ind = Dis.index(min([Dis[k] for k in range(len(Dis)) if vis[k] == 0]))
这一句是从所以没有被之前的循环标记成最近点的节点中找到距离起点距离最近的一个节点的索引。
if vis[j] == 0 and ad_mat[min_ind][j] != 0 \
and Dis[j] > (Dis[min_ind]+ad_mat[min_ind][j]):
Dis[j] = Dis[min_ind]+ad_mat[min_ind][j]
这个是更新距离(也叫松弛过程)的核心步骤:找到本次循环的最近点A后,从其邻接节点中找到未被标记过的(如果已被标记过,说明已是最近点且更新过周围节点),存在与A的通路link,以及起点到A与A到该节点的距离和小于当前起点到达该节点的距离的节点,然后更新起点到该点的距离值。
时间复杂度
通过代码介绍,我们可以发现给出的实现的时间复杂度为O(n^2)
样例测试
我们来跑一下测试样例:

>>> Dijkstra(directed=False)
7 9 0 6
0 1 9
1 2 12
2 3 6
1 3 5
3 4 14
4 5 3
3 5 8
5 6 10
6 1 7
Shortest distance from s to e: 16
Time used: 0.01053s
>>> Dijkstra(directed=True)
7 9 0 6
0 1 9
1 2 12
2 3 6
1 3 5
3 4 14
4 5 3
3 5 8
5 6 10
6 1 7
Shortest distance from s to e: 32
Time used: 0.01255s
上述的Dijkstra算法是有向图和无向图均可适用的,接下来我们画出两种情况下的最短路径:

三、BFS 实现 Dijkstra
实现思路
接下来我们来利用BFS的思想结合优先队列来实现Dijkstra算法,通过我们上面的讲解,我们可以发现,每次循环都是要找出距离起点最近的且还没被标记的点,可以把这个过程抽象成BFS里的找最短路。
但是由于加入到队列里的节点无序,所以要借助优先队列来进行排序操作,定义一个可以进行比较的对象。
这样我们通过BFS每次到达的就是距离起点最近的点,然后再进行松弛操作,会减少很多比较过程,从整体上看,每条边都只被检查过一次。

首先我们要定义可比较队列对象:
# comparable object definition
class compare_obj:
def __init__(self, s, dis):
self.s = s # node_index
self.dis = dis # distance from start node to this
def __lt__(self, other):
return self.dis < other.dis
一些数组和临时变量的设置与之前保持一致,加入一个G数组,用来记录每个节点相邻节点的数量。
代码
# 使用BFS结合优先队列实现Dijkstra
def BFS_Dijkstra(directed=False):
"""
Functions: Implementation of Dijkstra using BFS and PriorityQueue
Args:
directed: whether the graph is directed or not
return:
None
"""
import time
from queue import PriorityQueue
# comparable object definition
class compare_obj:
def __init__(self, s, dis):
self.s = s
self.dis = dis
def __lt__(self, other):
return self.dis < other.dis
# init distance
limit = 10000
# number of nodes, number of links, start_index, end_index
N, K, s, e = list(map(int, input().split()))
start = time.time()
# graph mat
ad_mat = [[0 for i in range(N)] for j in range(N)]
# distance to start_node
Dis = [limit for i in range(N)]
# tags array
vis = [0 for i in range(N)]
# number of adjacent nodes of one node
G = [[] for i in range(N)]
# use links to fresh graph mat
for i in range(K):
u, v, w = list(map(int, input().split()))
ad_mat[u][v] = w
G[u].append(v)
if directed == False:
ad_mat[v][u] = w
G[v].append(u)
# init distance of start_node
Dis[s] = 0
# BFS with Priority Queue
Q = PriorityQueue()
Q.put(compare_obj(s, Dis[s]))
while Q.qsize() != 0:
node = Q.get_nowait()
s, dis = node.s, node.dis
# if check, continue
if vis[s]:
continue
# sign the node
vis[s] = True
# fresh distance
for i in range(len(G[s])):
ad_node = G[s][i]
if not vis[ad_node] and Dis[ad_node] > (ad_mat[s][ad_node]+Dis[s]):
Dis[ad_node] = ad_mat[s][ad_node]+Dis[s]
Q.put_nowait(compare_obj(ad_node, Dis[ad_node]))
print('Shortest distance from s to e: {}'.format(Dis[e]))
print('Time used: {:.5f}s'.format(time.time()-start))
return
测试样例
我们来看看测试结果:
>>> BFS_Dijkstra(True)
7 9 0 6
0 1 9
1 2 12
2 3 6
1 3 5
3 4 14
4 5 3
3 5 8
5 6 10
6 1 7
Shortest distance from s to e: 32
Time used: 0.00573s
可以看到BFS实现的Dijkstra算法的运行时间比for循环实现在所给例子上的时间快了一倍。
四、总结:
除了Dijkstra算法,还有其他经典的最短路径搜索算法,我后面也会继续填坑。
不同算法之间的松弛思路基本一致,就是找更短的路,更新距离值。但是搜索策略和适合解决的问题种类各有不同。


Reference
[1] 算法小专栏:Dijkstra最短路径搜素