苞米豆多数据源管理
网上关于动态数据源的切换的文档有很多,核心只有两种。1是构建多套环境,2是基于spring原生的AbstractRoutingDataSource切换。
如果你的数据源较少,场景不复杂,选择以上任意一种都可以。如果你需要更多特性,请试着尝试本数据源。
数据源分组,适用于多种场景,常见的场景如下。
纯粹多库,各个库甚至可以是不同的数据库。
读写分离,一主多从,多主多从。
混合模式,既有主从也有单库。
自动集成Druid数据源,方便监控管理。
自动集成Mybatis-Plus。
自定义数据源来源。(如从数据库的配置中加载数据源)
动态增减数据源。
使用spel从session,header和参数中获取数据源。
多层数据源嵌套切换。(一个业务ServiceA调用ServiceB,ServiceB调用ServiceC,每个Service都是不同的数据源)
不足在于不能使用事物,当然你在网上查的其他方案也都不能提供。
如果你需要使用到分布式事物,那么你的架构应该到了微服务化的时候了。
约定
本框架只做 切换数据源 这件核心的事情,并不限制你的具体操作,切换了数据源可以做任何CRUD。
配置文件所有以下划线 _ 分割的数据源 首部 即为组的名称,相同组名称的数据源会放在一个组下。
切换数据源即可是组名,也可是具体数据源名称,切换时默认采用负载均衡机制切换。
默认的数据源名称为 master ,你可以通过spring.datasource.dynamic.primary修改。
方法上的注解优先于类上注解。
1 引入dynamic-datasource-spring-boot-starter
com.baomidou
dynamic-datasource-spring-boot-starter
2.5.6
2.1 一主多从方案
spring:
datasource:
dynamic:
primary: master #设置默认的数据源或者数据源组,默认值即为master,如果你主从默认下主库的名称就是master可不定义此项。
datasource:
master:
username: root
password: 123456
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://47.xxx.xx.xxx:3306/dynamic?characterEncoding=utf8&useSSL=false
slave_1:
username: root
password: 123456
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://47.xxx.xx.xxx:3307/dynamic?characterEncoding=utf8&useSSL=false
slave_2:
username: root
password: 123456
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://47.xxx.xx.xxx:3308/dynamic?characterEncoding=utf8&useSSL=false
#......省略
#以上会配置一个默认库master,一个组slave下有两个子库slave_1,slave_2
2.2 多主多从方案
spring:
datasource:
dynamic:
datasource:
master_1:
master_2:
slave_1:
slave_2:
slave_3:
2.3 多数据库方案
spring:
datasource:
dynamic:
primary: mysql #记得设置一个默认数据源
datasource:
mysql:
oracle:
sqlserver:
h2:
3.1 注解介绍
@DS 可以注解在方法上和类上,同时存在方法注解优先于类上注解,强烈建议注解在service实现或mapper接口方法上。
注意从2.0.0 不再支持@DS空注解 ,您 必须 指明你所需要的数据库 组名 或者 具体某个数据库名称 。

注解可以使用在sevice 和 mapper 层, 可以用在方法个类上
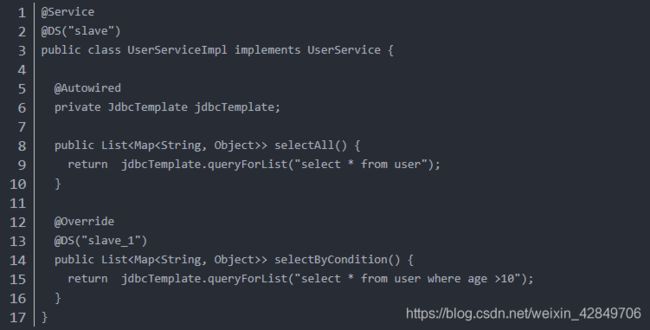
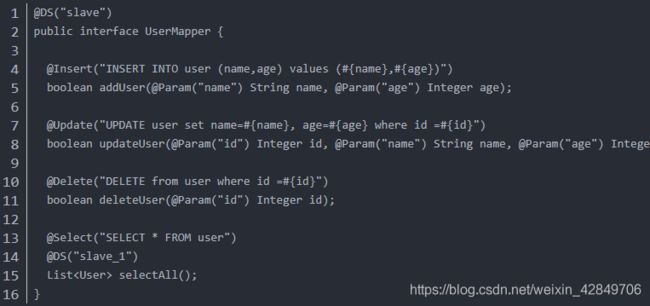
@DS(“slave_1”) 括号内即是application.properties中配置的数据源名称,不加注解默认是访问主库master,可加在service方法上,也可加在mapper方法上,但强烈不建议同时在service和mapper注解。 (可能会有问题)
@DS 可以注解在方法上和类上,同时存在方法注解优先于类上注解。
本文的application.properties中没有配置名为slave_1的数据源,代码里只做演示示例,可将slave_1改成对应的数据源名称。
4.继承druid
springBoot 2.x默认是使用HikariCP的, 所以觉得HikariCP的可以不需要换Druid,因为国内用多还是写一下
**注意:**主从可以使用不同的数据库连接池,如master使用Druid监控,从库使用HikariCP。 如果不配置连接池type类型,默认是Druid优先于HikariCP。
4.1排除原生的Druid配置
@SpringBootApplication(exclude = DruidDataSourceAutoConfigure.class)
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
4.2导入druid包之后配置yml
spring:
datasource:
druid:
stat-view-servlet:
loginUsername: root
loginPassword: root
dynamic:
datasource:
master:
username: root
password: root
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://120.xxx.xxx.xxx:3316/aaaa?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
druid: #以下均为默认值
initial-size: 3
max-active: 8
min-idle: 2
max-wait: -1
min-evictable-idle-time-millis: 30000
max-evictable-idle-time-millis: 30000
time-between-eviction-runs-millis: 0
validation-query: select 1
validation-query-timeout: -1
test-on-borrow: false
test-on-return: false
test-while-idle: true
pool-prepared-statements: true
max-open-prepared-statements: 100
filters: stat,wall
share-prepared-statements: true
slave_1:
username: root
password: root
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://120.xx.xx.xxx:3317/aaaa?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
druid: #以下均为默认值
initial-size: 3
max-active: 8
min-idle: 2
max-wait: -1
min-evictable-idle-time-millis: 30000
max-evictable-idle-time-millis: 30000
time-between-eviction-runs-millis: 0
validation-query: select 1
validation-query-timeout: -1
test-on-borrow: false
test-on-return: false
test-while-idle: true
pool-prepared-statements: true
max-open-prepared-statements: 100
filters: stat,wall
share-prepared-statements: true
小结
在项目不打的时候可以使用这个,但是一旦数据库多了,那么用dynamic-datasource 就会导致后期维护十分麻烦所以业务十分大建议使用 sharding-jdbc
一定要记得需要将原生的Druid的配置 隔离掉
数据库主从分离要做好。
事务的开启需在多数据的切换后。